MySQL入门指南5(约束,索引,事务)
Posted 爱笑的钮布尼茨
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL入门指南5(约束,索引,事务)相关的知识,希望对你有一定的参考价值。
前期回顾:
目录
一、约束
约束用于确保数据库的数据满足特定的商业规则。在MySQL中,约束包括:NOT NULL、UNIQUE、PRIMARY KEY、FOREIGN KEY、CHECK。
1. PRINARY KEY
用于唯一的标示表行的数据,当定义主键约束后,该列不能重复。
-- 基本用法: 字段 数据类型 PRIMARY KEY;
使用细节:
1.primary key(主键)修饰的列中字段不能重复且不能为null。
2. 一张表最多只能有一个主键,可以是复合主键。
3. 主键的指定方式有两种
a. 创建表时直接在字段后加上 primary key
b. 在表定义最后写primary key(列)
4.使用desc可以看到 primary key 的情况
5. 实际开发中每个表往往都会设计一个主键。
代码演示:
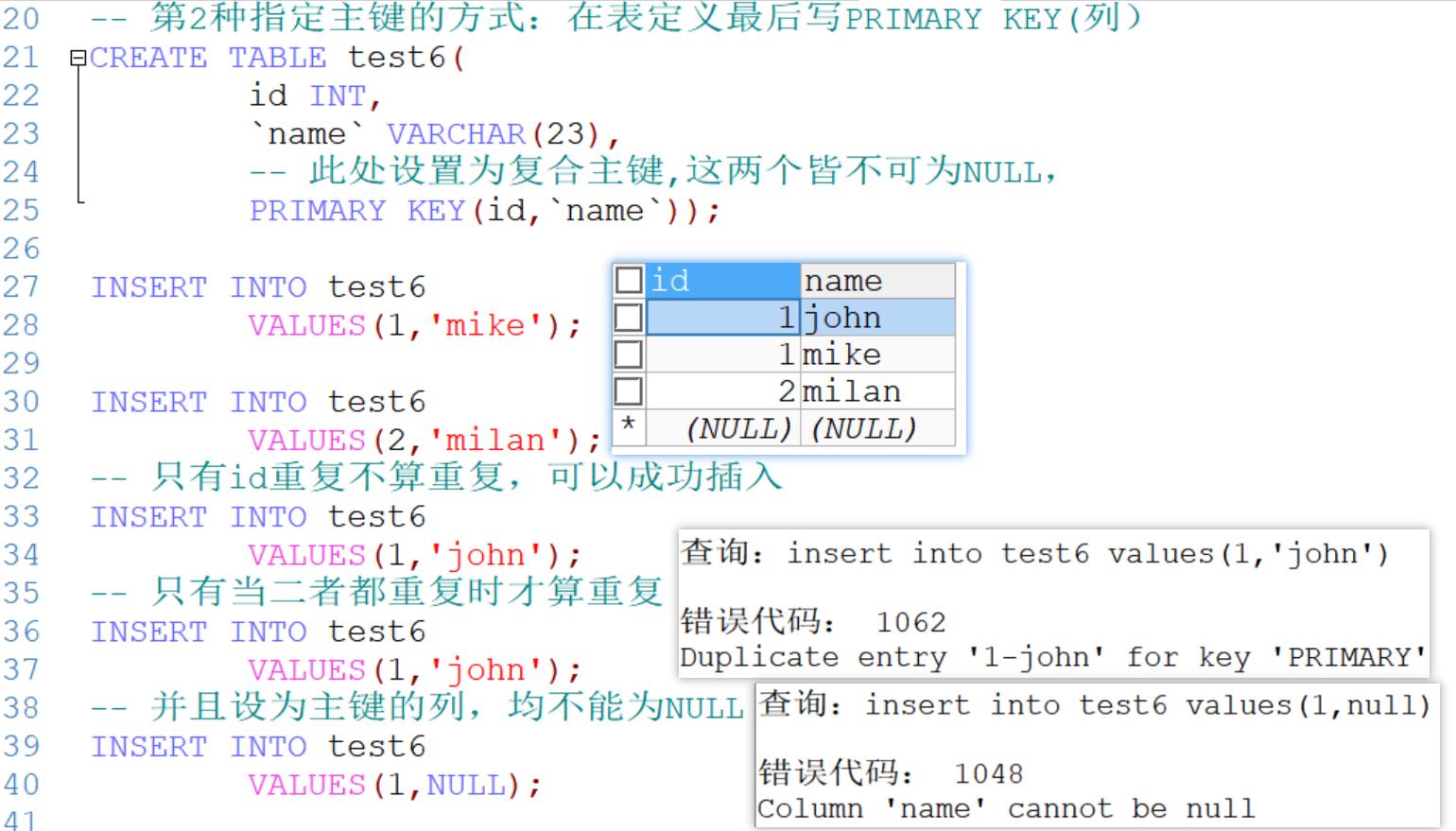
-- 第1种指定主键的方式:直接在字段后加上 PRIMARY KEY
CREATE TABLE test5(
id INT PRIMARY KEY, -- 指定为主键,其不可为NULL,不可重复
`name` VARCHAR(23));
INSERT INTO test5
VALUES(1,'mike');
INSERT INTO test5
VALUES(2,'milan');
-- id为主键不可重复
INSERT INTO test5
VALUES(1,'john');
-- id为主键不可为NULL
INSERT INTO test5
VALUES(NULL,'erson');
-- 第2种指定主键的方式:在表定义最后写PRIMARY KEY(列)
CREATE TABLE test6(
id INT,
`name` VARCHAR(23),
-- 此处设置为复合主键,这两个皆不可为NULL,
PRIMARY KEY(id,`name`));
INSERT INTO test6
VALUES(1,'mike');
INSERT INTO test6
VALUES(2,'milan');
-- 只有id重复不算重复,可以成功插入
INSERT INTO test6
VALUES(1,'john');
-- 只有当二者都重复时才算重复
INSERT INTO test6
VALUES(1,'john');
-- 并且设为主键的列,均不能为NULL
INSERT INTO test6
VALUES(1,NULL);
DESC test5;

2. NOT NULL
如果在列上定义了NOT NULL 那么当插入数据时,必须为列提供数据。
-- 基本用法: 字段 字段类型 NOT NULL;
3. UNIQUE
当定义了唯一约束后,该列值是不能重复的。
基本用法: 字段名 字段类型 UNIQUE;
使用细节:
1. 如果没有指定 NOT NULL,则UNIQUE字段可以有多个NULL
2.一张表中可以有多个UNIQUE
代码演示:
CREATE TABLE test7(
id INT UNIQUE,
`name` VARCHAR(23),
email VARCHAR(23) UNIQUE NOT NULL); -- UNIQUE NOT NULL 类似于 PRIMARY KEY
INSERT INTO test7
VALUES(1,'jack','jack@qq.com');
INSERT INTO test7
VALUES(2,'tom','tom@qq.com');
-- id重复无法插入进去
INSERT INTO test7
VALUES(2,'mumu','mumu@qq.com');
INSERT INTO test7
VALUES(NULL,'lalala','lalala@qq.com');
-- id 为空,可插入多个
INSERT INTO test7
VALUES(NULL,'lalala','lala@qq.com');

4. FOREIGN KEY
用于定义主表与从表之间的关系:外键约束要定义在从表上,主表则必须具有主键约束或者UNIQUE约束。当定义外键约束后,要求外键列数据必须在主表的主键列存在或者是为NULL。
-- 基本用法: FOREIGN KEY (本表字段名) REFERENCES 主表名(主表的主键名或UNIQUE字段名)
使用细节:
1. 外键指向的表的字段,要求是PRIMARY KEY或者是UNIQUE。
2. 表的存储引擎必须是INDODB ,这样的表才支持外键。
3. 外键字段的类型要与主键字段的类型保持一致(长度可不同)。
4. 外键字段的值,必须在主键字段中出现过,或者为NULL(未指定NOT NULL时)。
5. 一旦建立主外键关系,数据就不能随意删除。必须先删除从表才能再删除主表。
代码演示:
-- FOREIGN KEY 测试
-- 主表 班级表
CREATE TABLE test9(
id INT PRIMARY KEY,
nam VARCHAR(23),
address VARCHAR(23));
INSERT INTO test9
VALUES(100,'java','北京'),(200,'web','上海');
-- 从表 学生表
CREATE TABLE test10(
id INT PRIMARY KEY,
`name` VARCHAR(23) NOT NULL DEFAULT '',
class_id INT,
-- 此处指向主键或UNIQUE
FOREIGN KEY (class_id) REFERENCES test9(id));
INSERT INTO test10
VALUES(1,'tom',100),(2,'jack',200);
INSERT INTO test10
VALUES(3,'milan',300);
INSERT INTO test10
VALUES(4,'erson',NULL);
SELECT * FROM test10;
SELECT * FROM test9;
CREATE TABLE test11(
id INT PRIMARY KEY,
`name` VARCHAR(23) NOT NULL DEFAULT '',
class_id INT,
-- 此处指向的不是主键因此执行不成功
FOREIGN KEY (`name`) REFERENCES test9(`name`));
-- 删除时需要先删除从表
DROP TABLE test10;
-- 才能把删除主表
DROP TABLE test9;

5. CHECK
用于强制行数据必须满足的条件,若未满足条件则会提示出错。
MySQL5.7目前还不支持CHECK,只做语法校验。
在ORACLE和SQL SERVER 中均支持CHECK。
在MySQL实现CHECK的功能,一般时在程序中控制,或者通过触发器完成。
-- 基本用法: 字段 字段类型 CHECK (检查条件)
代码演示:
-- CHECK 测试
CREATE TABLE test8(
id INT UNIQUE NOT NULL DEFAULT 0,
`name` VARCHAR(23),
sex CHAR(1) CHECK(sex IN('男','女')),
age INT CHECK(age>18&&age<60));
INSERT INTO test8
VALUES(1,'Lihua','中',78);
二、索引
说起提高数据库性能,索引是最物美价廉的东西了。不用加内存,不用改程序,不用调sql,查询速度就可能提高千倍百倍。
1.索引的原理
MySQL表进行查询时在没有索引的情况下,是进行全表扫描来查找。
如果使用了索引,则会形成一个索引的数据结构,比如二叉树。这样在查询时,效率就会大大提升。
但在查询效率提升的同时,也需要付出一些代价:
比如:
1. 会占用更多的磁盘空间
2. 会影响 dml ( update , delete , insert ) 语句的效率(因为每次在执行这些操作时都要重建索引)
2. 索引的类型
a. 主键索引,主键自动的为主索引(类型 PRIMARY KEY)
b. 唯一索引(UNIQUE)
c. 全文索引(FULLTEXT)[适用于MyISAM存储引擎]
一般开发,不适应MySQL自带的全文索引,而是使用:全文搜索Solr和ElasticSearch(ES)
3. 索引的使用

4. 适合使用索引的列

代码演示:
-- 首先我们创建了一个有八百万条数据的emp表,代码省略
-- 查询索引(三种方式)
-- 方式一
SHOW INDEX FROM emp;
SHOW INDEXES FROM emp;
-- 方式二
SHOW KEYS FROM emp;
-- 方式三
DESC emp;
-- 测试查询速度(未设置索引时)
SELECT * FROM emp
WHERE ename = 'tZOXxv'; -- 此时用时3秒
SELECT * FROM emp
WHERE empno = 100676; -- 此时用时3秒
-- 添加索引
-- 1.添加普通索引INDEX
-- 方式一
CREATE INDEX index_empno ON emp(empno);
-- 方式二
ALTER TABLE emp ADD INDEX index_empno(empno);
-- 测试查询速度(添加索引列)
SELECT * FROM emp
WHERE empno = 100676; -- 此时用时0.008秒
-- 测试查询速度(未添加索引列)
SELECT * FROM emp
WHERE ename = 'tZOXxv'; -- 此时用时3秒
-- 删除索引方式一
DROP INDEX index_empno ON emp; -- 用于删除索引
-- 删除索引方式二
ALTER TABLE emp DROP INDEX index_empno; -- 用于删除索引
-- 2.添加唯一索引(UNIQUE)
CREATE INDEX index_empno ON emp(empno);
ALTER TABLE emp ADD UNIQUE INDEX index_empno(empno);
-- 3.添加主键索引(比较特殊)
ALTER TABLE emp ADD PRIMARY KEY (empno);
-- 删除主键索引(比较特殊)
ALTER TABLE emp DROP PRIMARY KEY;
三、事务
1. 事务介绍
事务用于保证数据的一致性,它由一组相关的DML语句(INSERT ,DELETE ,UPDATE )组成,该组的DML语句要么全部成功,要么全部失败。如:转账就要用事务来处理,以保证数据的一致性。
当执行事务操作时(DML语句),MySQL会在表上加锁,防止其他用户更改表的数据。这对用户来讲非常重要。
MySQL数据库控制台事务的几个重要操作
1. start transaction -- 开始一个事务
2. savepoint 保存点名 -- 设置保存点
3. rollback to 保存点名 -- 回退事务
4. rollback -- 回退全部事务
5. commit -- 提交事务,所有的操作生效,不能回退
事务操作代码演示:
-- 事务测试
-- 开始事务
START TRANSACTION;
-- 执行DML语句
INSERT INTO test
VALUES(5,'乐乐',18);
-- 设置保存点
SAVEPOINT a;
-- 执行DML语句
UPDATE test
SET age = 23
WHERE NAME ='浩浩';
-- 设置保存点
SAVEPOINT b;
-- 执行DML语句
DELETE FROM test
WHERE id=3;
-- 设置保存点
SAVEPOINT c;
-- 回退到指定保存点
ROLLBACK TO a;
-- 回退全部事务:回到事务开始时的状态
ROLLBACK;
-- 提交事务,所有操作生效,保存点失效
COMMIT;回退事务:
在介绍回退事务前,先介绍一下保存点(savepoint)。保存点是事务中的点,用于取消部分事务,当结束事务时(commit),会自动的删除该事务所定义的所有保存点。当执行回退事务时,通过指定保存点可以回退到指定的状态。
提交事务:
使用 commit 语句可以提交事务。当执行了 commit 语句后,会确认事务的变化、结束事务、删除保存点、释放锁、数据生效。当使用 commit 语句结束事务后,其它会话(其他连接)将可以查看到事务变化的新数据(所有数据就此生效)。

事务细节讨论:
1. 如果不开始事务,默认情况下,DML操作是自动提交的,不能回滚。
2. 如果开始一个事务,但没有创建保存点,可以执行 rollback,默认就是回退到你事务你开始的状态。
3. 可以在事务中创建多个保存点(提交事务前)。
4. 可以选择回退到你设置的保存点(提交事务前且未回到比该保存点更早的保存点前)
5. mysql的事务机制需要INNODB存储引擎才可以使用。
2. 事务隔离级别
多个连接开启各自事务 操作数据库中数据时,数据库系统要负责隔离操作,以保证各个连接在获取数据时的准确性。
如果不考虑隔离性,可能会引发如下问题:
1. 脏读:一个事务读取到另一个事务尚未提交的改变(DML操作),此时发生脏读。
2. 不可重复读:一个事务多次查询操作,由于其他事务提交所做的修改或删除,每次查询到不同的结果,此时发生不可重复读。
3. 幻读:一个事务多次查询操作,由于其他事务提交所作的插入操作,每次查询到不同的结果,此时发生幻读。
在多连接事务操作中,一般我们期望的是:当前事务只能读取到当前事务开始时的事务状态,而不能读取到其他操作产生的影响。
四种隔离级别
概念:MySQL隔离级别定义了事务与事务之间的隔离程度。
MySQL隔离级别 脏读 不可重复读 幻读 加锁读 读未提交(Read uncommitted) 是 是 是 不加锁 读已提交(Read committed) 否 是 是 不加锁 可重复读(Repeatable read) 否 否 否 不加锁 可串行化(Serializable) 否 否 否 加锁
设置事务隔离级别
1. 查看当前会话隔离级别
SELECT @@tx_isolation;2. 查看系统当前隔离级别
SELECT @@global.tx_isolation;3. 设置当前对话隔离级别
SET SESSION TRANSACTION ISOLATION LEVEL 指定隔离级别;4. 设置系统当前隔离级别
SET GLOBAL TRANSACTION ISOLATION LEVEL 指定隔离级别;5. 全局修改,修改 my.ini 配置文件,在最后加上
transaction-isolation = 指定隔离级别6. MySQL默认的事务隔离级别是Repeatable read,一般情况下,没有特殊要求,没有必要修改,因为该级别可以满足绝大部分项目需求。
温馨提示:可以试着多开几个mysql对话然后设置成不同的隔离级别,去做一些DML操作,看看四种隔离级别的差别,体会体会脏读,不可重复读,幻读的发生造成的困扰,理解理解 可串行化(Serializable)加锁操作的利与弊(设置为可串行化时,一个事务未提交,另一个事务将无法开始)。
3. 事务ACID
1. 原子性(Atomicity)
原子性是指事务时一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
2. 一致性(Consistency)
事务必须使数据库从一个一致性状态变换到另外一个一致性状态。
3. 隔离性(Isolation)
事务的隔离性是多个用户并发访问数据库时,数据库为每个用户开启的事务,不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离。
4. 持久性(Durability)
持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响。
四、最后的话
✨ 原创不易,还希望各位大佬支持一下
👍 点赞,你的认可是我创作的动力!
⭐️ 收藏,你的青睐是我努力的方向!
✏️ 评论,你的意见是我进步的财富!
总结: MySQL(基础,字段约束,索引,外键,存储过程,事务)操作语法
1. 显示数据库列表
show databases; # 查看当前所有数据库
show databases \G #以行的方式显示
2. 在命令行中,执行sql语句
mysql -e ‘show databases‘ -uroot -p123456
mysqlshow -uroot -p123456 # 不常用,记住上面那个就行了
3.创建数据库语法
create database 数据库名;
例如: create database `HA-test`;
4. 切换数据库
use HA-test;
5. 登陆时,直接切换到指定数据库
mysql -uroot -p123456 <数据库名>
6. 查看数据库当前时间,用户,和当前数据库
select now(),user(),database();
7.删除数据库
Way 1:
drop database <数据库名>;
Way 2: 直接从数据库数据目录中,将对应文件删除
cd /usr/local/mysql/data
# 切换到数据库存放目录, /etc/my.cnf 可以查到
mv [email protected] /tmp
8. if (not) exists
# 创建和删除时,检查是否存在,在shell编程中,可用到
drop database if exists `HA-test`;
create database if not exists HA;
9. 创建表
create table student(
id int(20),
name char(40),
age int);
10. 切换数据库后,查看当前数据库中的所有表
use HA;
show tables;
11. 查看表结构 desc # 还有一层意思,在order by 后面,表示降序排列
desc student;
mysql> explain mysql.user; # 类似 desc mysql.user;
mysql> show columns from mysql.user;
mysql> show fields from mysql.user;
mysql> show columns from mysql.user like ‘%user‘;
12. 查看表创建语句 # \G 按行显示
show create table student \G
13. 创建表时,使用指定存储引擎和字符集
CREATE TABLE `student` (
`id` int(20) DEFAULT NULL,
`name` char(40) DEFAULT NULL,
`age` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8
## ---> 可在创建表时,指定存储引擎和字符集
13. 删除表
drop table student2;
14. 禁止预读表信息
mysql> use performance_schema;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
mysql -uroot –p123456 -A # 禁止预读表信息
# 在登录mysql时,添加-A选项
14. 修改表的属性信息
alter table 表名
add 字段名
列类型
[not null|null][primary key][unique][auto_increment][default value]
14.1 修改表名称
alter table 表名 rename 新表名;
14.2 修改表中字段类型
alter table 表名 modify 要修改的字段名 要修改的类型;
14.3 修改表中字段的名称 ---> 此时必须指定类型,即使不改变类型
alter table 表名 change 原字段名 新字段名 新字段类型;
14.4 向表中添加新的字段
alter table 表名 add 字段名 字段类型;
14.5 指定添加的字段位置
# 字段位于第一行
alter table students add uid int(10) first;
# 字段位于age后
alter table students add address char(40) after age;
14.6 删除表中字段
alter table 表名 drop 字段名 ;
15.1 向表中插入信息
Way 1:
insert [into] 数据表名称 [(字段列表)] values|value
(表达式|null|default,...),
(表达式|null|default,...)
Way 2:
insert [into] 数据表名称 set
字段名称=值,
...
区别:insert与insert...set的区别--->insert...set可以带有子查询.
15.2 向表中插入信息的其他方式
Way 1:字段值的顺序与建表时顺序相同
insert into 表名 values (字段值1,字段值2, 字段值3);
Way 2: 字段名=字段值,此方式不用纠结顺序
insert into 表名 values ( 字段名=字段值,...);
Way 3: 按照前面指定的字段名顺序
insert into 表名 (字段名,字段名...) values (字段值,字段值...);
Way 4: 插入多条数据
insert into 表名 values
(字段值,字段值...),
(字段值,字段值...)...;
16. 查看表中信息 select语句
查看表中所有信息 * 代表表中所有字段
select * from 表名称;
查看指定一个或多个字段信息
select 字段名,字段名... from 表名称;
跨数据库查看
SELECT 字段 FROM 数据库名.表名;
17. 删除表中信息
delete from 数据表名称 [where 条件]
如果省略where条件,将删除全部记录
delete from students where id=3;
delete from students where age is null;
delete from students; # 删除表中所有记录
18. 修改 更新表中信息
update 数据表名称 set 字段名称=值,... [where 条件]
如果省略WHERE条件将更新全部记录.
update students set sex=‘M‘ where id=2;
update students set id=2; 所有的都变为2
update students set stname=‘zhangsan‘,age=21 where uid=1;
19. where子句
select 字段名1,字段名2 from 表名 [where 条件];
20. 查询结果去重
select distinct name,age from students;
select distinct id,name,age from students where id=3;
distinct 只针对查询语句 直接处理查询出的记过,不对数据库中的实际数据产生影响
21. and or多条件查询
# and优先级高于or,同时出现,没有括号的情况下,先and后or
使用and和or进行多条件查询
or和and 同时存在时,先算and的两边值,逻辑与先执行
select id,name,age from students where id>3 and age>25;
22. binary 类型转换运算符
# 解决查询中大小写不区分的问题
mysql查询中不区分大小写,可加修饰符 binary解决
select * from students where binary name=‘jk‘;
BINARY是类型转换运算符
它用来强制它后面的字符串为一个二进制字符串,可以理解为在字符串比较的时候区分大小写.
select 字段列表 from 数据表 [[as] 别名] [where 条件]
23. 别名的使用
别名:
数据表 [[as] 别名]
select AA.money,BB.name from
product_offer_instance_object_xxx as AA ,
product_offer_instance_object_ZZZ BB
where AA.id = BB.id
字段名称 [[as]别名]
例如:
select product_offer_instance_object_id as ID,
product_offer_instance_object_name name,
coumn33 ‘金额’ from tablename;
24. 对查询结果进行排序处理
# 按照指定的一个或多个字段排序
# 可使用去重复字段
select distinct 字段1,字段2 from 表名order by 字段名;
asc 升序 默认
desc 降序
select distinct id from students order by id desc;
排序:
升序:order by “排序的字段” asc 默认
降序:oredr by “排序的字段” desc
多个字段排序
select bName,price from books where price in (50,60,70) order by price desc,bName desc;
表中数据增删改查总结
select语句返回零条或多条记录;属于记录读操作
insert、update、delete只返回此次操作影响的记录数;属于写操作
25. mysql数据库中的函数
select now(); -- 打印当前的日期和时间
select curdate(); -- 打印当前的日期
select curtime(); -- 打印当前的时间
select database();-- 打印当前数据库
select version(); -- 打印MySQL版本
select user(); -- 打印当前用户
26. mysql数据库的一些信息查询方式
show variables;--查看系统信息
show global variables; --查看全局变量
show global variables like ‘%version%‘; --查看版本信息
show variables like ‘%storage_engine%‘; --默认的存储引擎
show engines;--查看支持哪些存储引擎
show status;--查看系统运行状态信息
show global status like ‘Thread%‘; --查看当前运行状态
27. 帮助
help show;
? show;
28. 数据库导入
导入数据库前必须创建一个空数据库
Way 1:
create database book;
mysql -uroot -p123456 book < book.sql
Way 2:
create database book;
mysql> use book;
mysql> source /root/book.sql #sql脚本的路径 此路径可为当前路径相对路径
29. 数据库导出
导出数据库:
Usage:
mysqldump -u 用户名 -p 数据库名 > 导出的文件名
30. 查询结果导出 outfile # mysql用户需要对导出的路径有访问权限
例如:
select * into outfile ‘/tmp/123.txt‘ from books;
select name,ctfid,birthday,mobile,tel,email from info where ctfid like ‘130000%‘ into outfile ‘/tmp/fuping-of-rujia‘;
select bName,publishing,price from books where price=30 or price=40 or price=50 or price=60;
31.
in 运算符
IN 运算符用于 WHERE 表达式中,以列表项的形式支持多个选择,语法如下:
WHERE column IN (value1,value2,...)
WHERE column NOT IN (value1,value2,...)
Not in 与in相反
当 IN 前面加上 NOT 运算符时,表示与 IN 相反的意思,即不在这些列表项内选择.
32. 算术运算符
= 等于,<> 不等于 !=,> 大于,< 小于,>= 大于等于,<= 小于等于
33. 范围运算
[not] between ....and....
Between and 可以使用大于小于的方式来代替,并且使用大于小于意义表述更明确
查询范围总结 :
这里的查询条件有三种:between...and,or 和 in
(30,60) >30 and <60
[30,60] >=30 and <=60
模糊匹配查询:
字段名 [not]like ‘通配符‘ ----》% 任意多个字符
例如
select * from students where stname like ‘%l%1%2%3%‘;
34. MySQL子查询:
概念:在select 的where条件中又出现了select
查询中嵌套着查询
select * from book where price=(select max(price) from book);
35. Limit限定显示的条目:
Usage:
SELECT * FROM table LIMIT [offset,] rows
offset 偏移量,rows行数
比如select * from table limit m,n语句
表示其中m是指记录开始的index,从0开始,表示第一条记录
n是指从第m+1条开始,取n条.
36. 多行子查询: all表示小于子查询中返回全部值中的最小值
mysql> select bName,price from books where price<(select price from books where publishing="电子工业出版社" order by price asc limit 0,1);
mysql> select bName,price from books where price<all(select price from books where publishing="电子工业出版社");
37. 连接查询:
内连接Usage:
select 字段 from 表1 inner join 表2 on 表1.字段=表2.字段
外连接
左连接: select 字段 from a表 left join b表 on 连接条件
右连接: select 字段 from a表 right join b表 on 条件
右连接,可以多表连接
38. 聚合函数 --> 函数:执行特定功能的代码块.
算数运算函数:
38.1 求和: Sum() --显示所有图书单价的总合
select sum(price) from books;
38.2 平均值:avg()
例如:求书籍Id小于3的所有书籍的平均价格
mysql> select avg(price) from books where bId<=3;
例如:查询书籍的价格小于所有数据平均价格的数目 (嵌套子查询)
select bName,price from books
where price< (
select avg(price) from books );
38.3 最大值:max()
求所有图书中价格最贵的书籍
mysql> select bName,max(price) from books; # 这种方法是错误的
mysql> select bName,price from books where price=(select max(price) from books);
38.4 最小值:min()
求所有图书中价格便宜的书籍
mysql> select bName,price from books where price=(select min(price) from books);
38.5 count()统计记录数:
统计价格大于40的书籍数量
mysql> select count(*) from books where price>40;
Count()中还可以增加你需要的内容,比如增加distinct来配合使用
38.6 字符串函数 substr(string ,start,len)
截取:从start开始,截取len长.
# start 从1开始算起.
mysql> select substr(bTypeName,1,6)from category where bTypeId=10;
例如: 截取汉字
mysql> select substr(bTypeName,8,10)from category where bTypeId=1;
+------------------------+
| substr(bTypeName,8,10) |
+------------------------+
| 应用 | windows应用
+------------------------+
38.7 大小写转换 # 大小写转换,不能针对中文,会出现乱码
大写: upper()
mysql> select upper(bname) from books where bId=9; # 有中文会出现
小写: lower()
mysql> select lower(bName) from books where bId=10;
38.8 日期
当前日期: curdate():
当前时间: curtime();
当前日期和时间: now();
39. 算数运算: + - * / # 注意,mysql中没有自加自减 ++ +=
给所有价格小于40元的书籍,涨价5元
mysql> update books set price=price+5 where price<40;
给所有价格高于70元的书籍打8折
mysql> update books set price=price*0.8 where price>70;
40. 字段修饰符
[not null|null][primary key][unique][auto_increment][default value]
40.1 null和not null修饰符
40.2 default 设定字段的默认值
总结 :
如果字段没有设定default ,mysql依据这个字段是null还是not null,如果为可以为null,则为null.如果不可以为null,报错..
如果时间字段,默认为当前时间 ,插入0时,默认为当前时间.
如果是enum 类型,默认为第一个元素.
40.3 auto_increment字段约束 自动增长 只能修饰 int字段.
对于主键,这是非常 有用的. 可以为每条记录创建一个惟一的标识符
41. 清空表中所有记录
方法一:delete 不加where条件,清空所有表记录.
但是delete不会清零auto_increment 值
方法二:truncate
作用: 删除表的所有记录,并清零auto_increment 值.新插入的记录从1开始.
Usage: truncate table name;
42. 索引 好比是一本书前面的目录
42.1 最基本的索引,不具备唯一性,就是加快查询速度
方法一:创建表时添加索引
create table 表名(
列定义
index 索引名称 (字段)
index 索引名称 (字段);
注:可以使用key,也可以使用index .index 索引名称 (字段) ,索引名称,可以加也可以不加,不加使用字段名作为索引名.
方法二: 当表创建完成后,使用alter为表添加索引:
alter table 表名 add index 索引名称 (字段1,字段2.....);
42.2 查看索引 desc
desc demo; # 查看表的描述信息,在Key那一列可以看到
42.3 删除索引
alter table demo drop key pwd; 注意此处的pwd指的是索引的名称,而不是表中pwd的那个字段
42.4 添加索引
mysql> alter table demo add key(pwd);
42.5 唯一索引 索引列的所有值都只能出现一次,即必须唯一
唯一性允许有NULL值<允许为空>
创建唯一索引:
方法一:创建表时加唯一索引
create table 表名(
列定义:
unique key 索引名 (字段);
);
方法二:修改表时加唯一索引
alter table 表名 add unique 索引名 (字段);
42.6 主键索引 按主键查询是最快的,每个表只能有一个主键列
方法一:创建表创建主键索引
create table demo4 (
id int(4) not null auto_increment primary key,
name varchar(4) not null );
create table demo5(
id int(4) not null auto_increment,
name varchar(20) default null,
primary key(id));
show index from demo5 \G --查看表中索引
方法二:创建表后添加<不推荐>
mysql> alter table demo5 change id id int(4) not null primary key auto_increment;
42.7 删除主键索引测试 auto_increment
删除遇到这种情况是auto_increment的原因
mysql> alter table demo5 change id id int(4) not null;
mysql> alter table demo5 drop primary key;
总结:主键索引,唯一性索引区别:主键索引不能有NULL,唯一性索引可以有空值
复合索引
索引可以包含一个、两个或更多个列.两个或更多个列上的索引被称作复合索引
43. 联合主键 创建举例
create table firewall (
host varchar(15) not null ,
port smallint(4) not null ,
access enum(‘deny‘,‘allow‘) not null,
primary key (host,port)); # 联合主键只能在最后面弄
44. 总结:建表的时候如果加各种索引,顺序如下:
create table 表名(
字段定义,
PRIMARYKEY (`bId`),
UNIQUE KEY `bi` (`bImg`),
KEY `bn` (`bName`),
KEY `ba` (`author`));
45. 全文索引只能用在 varchar text
创建全文索引:
方法一:创建表时创建
create table 表名(
列定义,
fulltext key 索引名 (字段));
方法二:修改表时添加
alter table 表名 add fulltext 索引名 (字段);
强烈注意:MySQL自带的全文索引只能用于数据库引擎为MyISAM的数据表,如果是其他数据引擎,则全文索引不会生效
MySQL自带的全文索引只能对英文进行全文检索,目前无法对中文进行全文检索.
一般交给第三方软件进行全文索引
http://sphinxsearch.com/
46. 外键约束 foreign key
创建外键约束:
方法一:通过create table创建外键
Usage:
create table 数据表名称(
...,
[CONSTRAINT [约束名称]]
FOREIGN KEY [外键字段] REFERENCES
[外键表名](外键字段,外键字段2…..)
[ON DELETE [ CASCADE | RESTRICT] ]
[ON UPDATE [ CASCADE | RESTRICT] ]);
Usage:(精简版)
foreign key 当前表的字段 references
外部表名 (关联的字段)
type=innodb
注:创建成功,必须满足以下4个条件:
1、确保参照的表和字段存在.
2、组成外键的字段被索引.
3、必须使用type指定存储引擎为:innodb.
4、外键字段和关联字段,数据类型必须一致.
#创建时,如果表名是sql关键字,使用时,需要使用反引号``
方法二:通过alter table 创建外键和级联更新,级联删除
Usage:
alter table 数据表名称 add
[constraint [约束名称] ] foreign key (外键字段,..) references
数据表(参照字段,...)
[on update cascade|set null|no action]
[on delete cascade|set null|no action]) type=innodb;
46.1 查看外键信息
mysql> show create table order1;
46.2 删除外键:
Usage:
alter table 数据表名称 drop foreign key 约束(外键)名称
47. 视图
47.1 创建视图
Usage:
create view视图名称(即虚拟的表名) as select 语句
47.2 查看创建视图的语句
show create view bc \G
47.3 更新或修改视图
Usage:
alter view视图名称(即虚拟的表名) as select 语句.
update view视图名称(即虚拟的表名)set
# 一般数据库中视图是不支持更新和修改的
update bc set bName=‘HA‘ where price=34;
47.4 删除视图
drop view 视图名;
48. 修改sql执行符号
# 注意,在定义存储过程前,最好使用 delimiter 来修改执行符号
# 不然在写存储过程的时候,会提前终止
Usage:
delimiter 新执行符号
49. 定义存储过程
Usage:
create procedure 过程名(参数1,参数2....)
begin
sql语句;
end
*). 查看存储过程
A). 查看存储过程内容:
show create procedure [存储过程名称] \G
B). 查看存储过程状态:
show procedure status \G 查看所有存储过程
*). 修改存储过程:
使用alter语句修改
ALTER {PROCEDURE | FUNCTION} sp_name [characteristic ...]
characteristic:
{ CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA }
| SQL SECURITY { DEFINER | INVOKER }
| COMMENT ‘string‘
sp_name参数表示存储过程或函数的名称
characteristic参数指定存储函数的特性
CONTAINS SQL表示子程序包含SQL语句,但不包含读或写数据的语句;
NO SQL表示子程序中不包含SQL语句
READS SQL DATA表示子程序中包含读数据的语句
MODIFIES SQL DATA表示子程序中包含写数据的语句
SQL SECURITY { DEFINER | INVOKER }指明谁有权限来执行
DEFINER表示只有定义者自己才能够执行
INVOKER表示调用者可以执行
COMMENT ‘string‘是注释信息.
--
/**/
*). 删除存储过程
Usage:
方法一:DROP PROCEDURE 过程名
mysql> drop procedure p_inout;
方法二:DROP PROCEDURE IF EXISTS存储过程名
这个语句被用来移除一个存储程序.不能在一个存储过程中删除另一个存储过程,只能调用另一个存储过程
49.1 调用存储过程
Usage:
call 过程名(参数1,参数2);
49.2 存储过程参数类型
In参数 特点:读取外部变量值,且有效范围仅限存储过程内部
Out参数 特点:不读取外部变量值,在存储过程执行完毕后保留新值
set @p_out=1; # 定义变量时建议加个@ 编译辨认,一眼就看出来了
Inout参数 特点:读取外部变量,在存储过程执行完后保留新值<类似银行存款>
49.3 存储过程变量的使用
变量定义:
DECLARE variable_name [,variable_name...] datatype [DEFAULT value];
datatype为MySQL的数据类型,如:int, float, date, varchar(length)
变量赋值: SET 变量名 = 表达式值 [,variable_name = expression ...]
变量赋值可以在不同的存储过程中继承
49.4 存储过程语句的注释
“--“:单行注释
“/*…..*/”:一般用于多行注释
50. 变量作用域 参考编程语言中的作用域
51. 存储过程流程控制语句
51.1 条件语句
Usage:
*1). 单分支:
if [判断条件] then
...
end if
*2). 双分支:
if [判断条件] then
...
else
...
end if
51.2 case分支语句:
Usage:
case [变量名]
when [变量值] then
...
when [变量值] then
...
else
...
end case;
51.3 循环控制语句
*1). while循环
whlie [判断条件] do
...
end while;
*2). repeat循环
set v=0; --设置循环变量
repeat --标记循环开始
... -- 循环语句
set v=v+1; --循环值改变
until v>=5 --循环判断条件
end repeat; --循环结束标记
*3). loop循环
# loop循环不需要初始条件,
# leave 的意思是结束循环
LOOP_LABLE: loop
...
set v=v+1;
if v>=5 then
leave LOOP_LABLE;
end if;
end loop;
*4). LABLES 标号
标号可以用在 begin repeat while loop 语句前
只能在合法的语句前使用 (不推荐,容易乱)
*5). ITERATE 迭代
通过引用复合语句的标号,来从新开始复合语句
52. 触发器:
52.1 创建触发器:
Usage:
create trigger 触发器名称
触发的时机 触发的动作 on 表名 for each row
触发器状态.
参数说明:
触发器名称:自己定义
触发的时机:before /after 在执行动作之前还是之后
触发的动作:指的激发触发程序的语句类型<insert ,update,delete>
触发器创建语法四要素:
1.监视地点(table)
2.监视事件(insert/update/delete)
3.触发时间(after/before)
4.触发事件(insert/update/delete)
例如:
mysql> delimiter //
mysql> create trigger delCategory after delete on category for each row
-> delete from books where bTypeId=3;
-> //
52.2 查看触发器:
1). 查看创建过程
mysql> show create trigger delCategory\G
2). 查看触发器详细信息
mysql> show triggers\G 这个查看所有的
52.3 删除触发器:
Usage:
drop trigger 触发器名称;
mysql> drop trigger delCategory;
触发器是不是永久保留?
53. 事务
MySQL事务处理的方法:
1、用BEGIN,ROLLBACK,COMMIT来实现
START TRANSACTION | BEGIN [WORK] 开启事务
COMMIT [WORK] [AND [NO] CHAIN] [[NO] RELEASE] 提交当前事务,执行永久操作.
ROLLBACK [WORK] [AND [NO] CHAIN] [[NO] RELEASE] 回滚当前事务到开始点,取消上一次开始点后的所有操作.
SAVEPOINT 名称 折返点
2、直接用set来改变mysql的自动提交模式
MYSQL默认是自动提交的,也就是你提交一个QUERY,它就直接执行!
SET AUTOCOMMIT = {0 | 1}
# 设置事务是否自动提交,默认是自动提交的.
0:禁止自动提交
1:开启自动提交.
※ MYSQL中只有INNODB和BDB类型的数据表才能支持事务处理!其他的类型是不支持!
事务只要没有提交,就能回滚,提交了的事务,是回滚不回来的!
以上是关于MySQL入门指南5(约束,索引,事务)的主要内容,如果未能解决你的问题,请参考以下文章
MySQL笔记--- 创建表;插入,修改,删除数据;主键,外键约束;事务;索引;视图;三范式;