MySQL面试常问问题(SQL 优化 ) —— 赶快收藏
Posted 南极找南
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL面试常问问题(SQL 优化 ) —— 赶快收藏相关的知识,希望对你有一定的参考价值。
目录
3.怎么看执行计划(explain),如何理解其中各个字段的含义?
1.慢SQL如何定位呢?
慢SQL的监控主要通过两个途径:
发现慢SQL
-
慢查询日志:开启mysql的慢查询日志,再通过一些工具比如mysqldumpslow去分析对应的慢查询日志,当然现在一般的云厂商都提供了可视化的平台。
-
服务监控:可以在业务的基建中加入对慢SQL的监控,常见的方案有字节码插桩、连接池扩展、ORM框架过程,对服务运行中的慢SQL进行监控和告警。
2.有哪些方式优化慢SQL?
慢SQL的优化,主要从两个方面考虑,SQL语句本身的优化,以及数据库设计的优化。
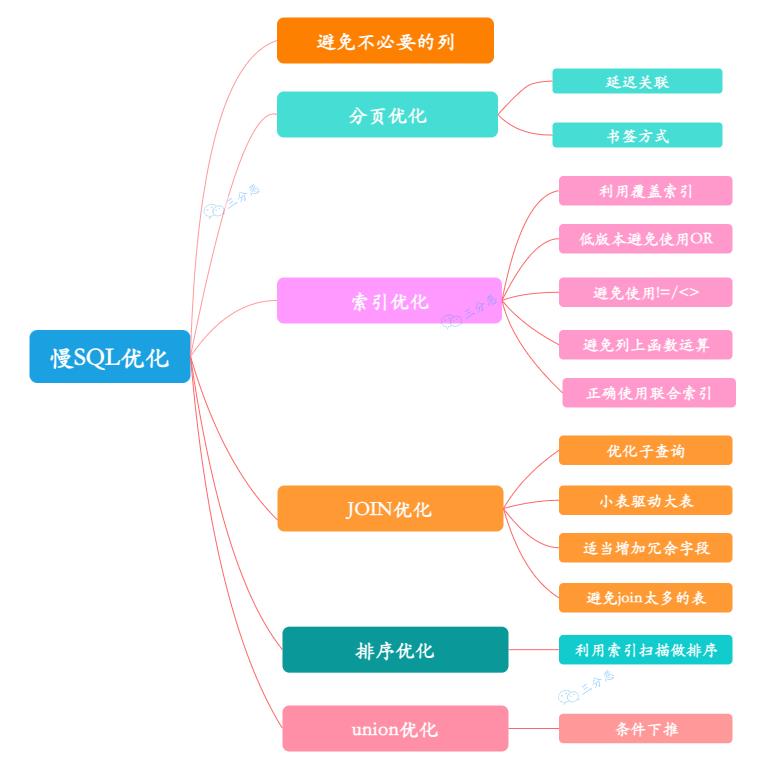
避免不必要的列
这个是老生常谈,但还是经常会出的情况,SQL查询的时候,应该只查询需要的列,而不要包含额外的列,像slect * 这种写法应该尽量避免。
分页优化
在数据量比较大,分页比较深的情况下,需要考虑分页的优化。
例如:
select * from table where type = 2 and level = 9 order by id asc limit 190289,10;优化方案:
- 延迟关联
先通过where条件提取出主键,在将该表与原数据表关联,通过主键id提取数据行,而不是通过原来的二级索引提取数据行
例如:
select a.* from table a,
(select id from table where type = 2 and level = 9 order by id asc limit 190289,10 ) b
where a.id = b.id- 书签方式
书签方式就是找到limit第一个参数对应的主键值,根据这个主键值再去过滤并limit
例如:
select * from table where id >
(select * from table where type = 2 and level = 9 order by id asc limit 190索引优化
合理地设计和使用索引,是优化慢SQL的利器。
利用覆盖索引
InnoDB使用非主键索引查询数据时会回表,但是如果索引的叶节点中已经包含要查询的字段,那它没有必要再回表查询了,这就叫覆盖索引
例如对于如下查询:
select name from test where city='上海'我们将被查询的字段建立到联合索引中,这样查询结果就可以直接从索引中获取
lter table test add index idx_city_name (city, name);低版本避免使用or查询
在 MySQL 5.0 之前的版本要尽量避免使用 or 查询,可以使用 union 或者子查询来替代,因为早期的 MySQL 版本使用 or 查询可能会导致索引失效,高版本引入了索引合并,解决了这个问题。
避免使用 != 或者 <> 操作符
SQL中,不等于操作符会导致查询引擎放弃查询索引,引起全表扫描,即使比较的字段上有索引
解决方法:通过把不等于操作符改成or,可以使用索引,避免全表扫描
例如,把column<>’aaa’,改成column>’aaa’ or column<’aaa’,就可以使用索引了
适当使用前缀索引
适当地使用前缀所云,可以降低索引的空间占用,提高索引的查询效率。
比如,邮箱的后缀都是固定的“@xxx.com”,那么类似这种后面几位为固定值的字段就非常适合定义为前缀索引
alter table test add index index2(email(6));PS:需要注意的是,前缀索引也存在缺点,MySQL无法利用前缀索引做order by和group by 操作,也无法作为覆盖索引
避免列上函数运算
要避免在列字段上进行算术运算或其他表达式运算,否则可能会导致存储引擎无法正确使用索引,从而影响了查询的效率
select * from test where id + 1 = 50;
select * from test where month(updateTime) = 7;正确使用联合索引
使用联合索引的时候,注意最左匹配原则。
JOIN优化
优化子查询
尽量使用 Join 语句来替代子查询,因为子查询是嵌套查询,而嵌套查询会新创建一张临时表,而临时表的创建与销毁会占用一定的系统资源以及花费一定的时间,同时对于返回结果集比较大的子查询,其对查询性能的影响更大
小表驱动大表
关联查询的时候要拿小表去驱动大表,因为关联的时候,MySQL内部会遍历驱动表,再去连接被驱动表。
比如left join,左表就是驱动表,A表小于B表,建立连接的次数就少,查询速度就被加快了。
select name from A left join B ;适当增加冗余字段
增加冗余字段可以减少大量的连表查询,因为多张表的连表查询性能很低,所有可以适当的增加冗余字段,以减少多张表的关联查询,这是以空间换时间的优化策略
避免使用JOIN关联太多的表
《阿里巴巴Java开发手册》规定不要join超过三张表,第一join太多降低查询的速度,第二join的buffer会占用更多的内存。
如果不可避免要join多张表,可以考虑使用数据异构的方式异构到ES中查询。
排序优化
利用索引扫描做排序
MySQL有两种方式生成有序结果:其一是对结果集进行排序的操作,其二是按照索引顺序扫描得出的结果自然是有序的
但是如果索引不能覆盖查询所需列,就不得不每扫描一条记录回表查询一次,这个读操作是随机IO,通常会比顺序全表扫描还慢
因此,在设计索引时,尽可能使用同一个索引既满足排序又用于查找行
例如:
--建立索引(date,staff_id,customer_id)
select staff_id, customer_id from test where date = '2010-01-01' order by staff_id,customer_id;只有当索引的列顺序和ORDER BY子句的顺序完全一致,并且所有列的排序方向都一样时,才能够使用索引来对结果做排序
UNION优化
条件下推
MySQL处理union的策略是先创建临时表,然后将各个查询结果填充到临时表中最后再来做查询,很多优化策略在union查询中都会失效,因为它无法利用索引
最好手工将where、limit等子句下推到union的各个子查询中,以便优化器可以充分利用这些条件进行优化
此外,除非确实需要服务器去重,一定要使用union all,如果不加all关键字,MySQL会给临时表加上distinct选项,这会导致对整个临时表做唯一性检查,代价很高。
3.怎么看执行计划(explain),如何理解其中各个字段的含义?
explain是sql优化的利器,除了优化慢sql,平时的sql编写,也应该先explain,查看一下执行计划,看看是否还有优化的空间。
直接在 select 语句之前增加explain 关键字,就会返回执行计划的信息。

explain
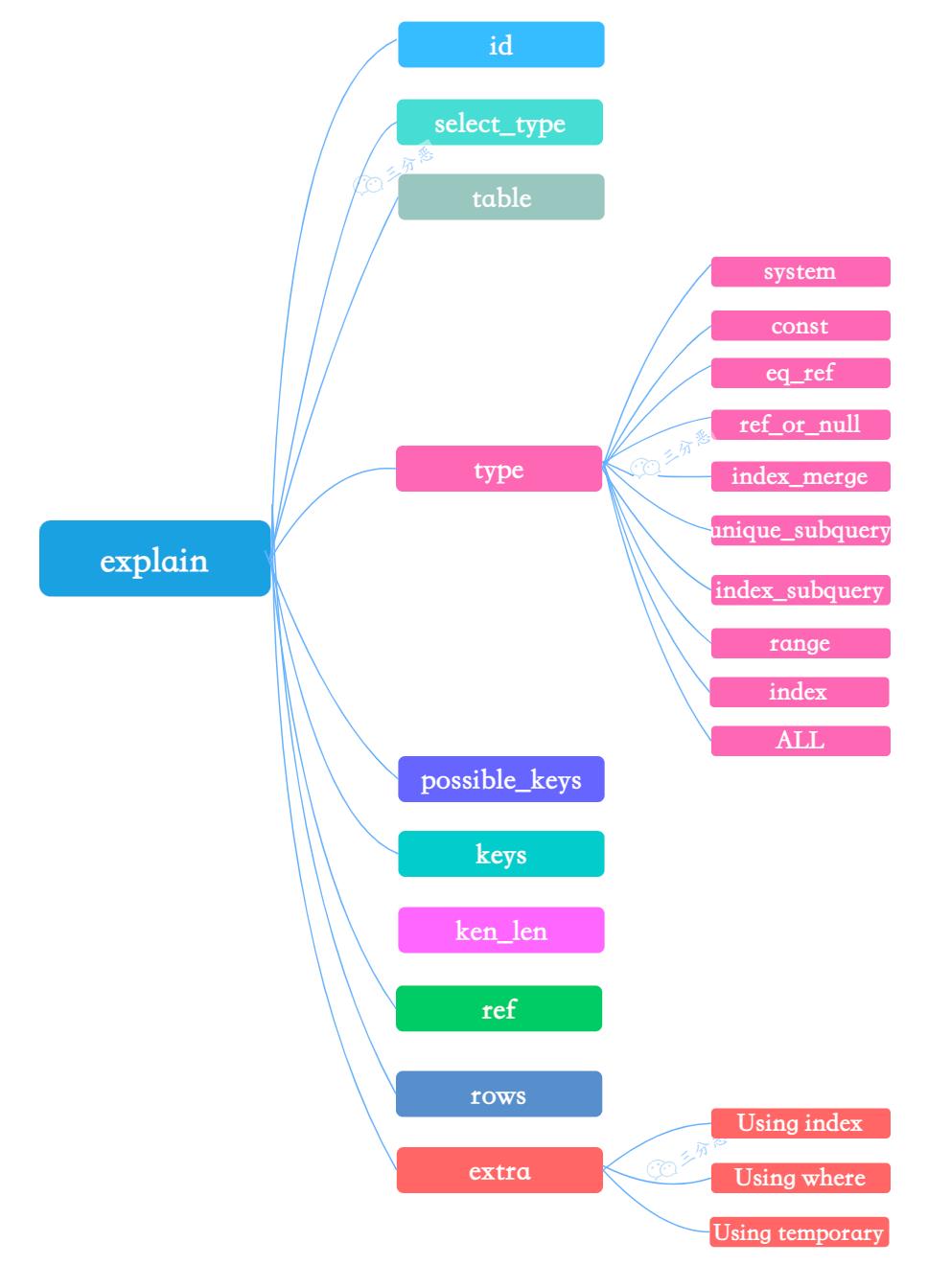
explain
-
id 列:MySQL会为每个select语句分配一个唯一的id值
-
select_type 列,查询的类型,根据关联、union、子查询等等分类,常见的查询类型有SIMPLE、PRIMARY。
-
table 列:表示 explain 的一行正在访问哪个表。
-
type 列:最重要的列之一。表示关联类型或访问类型,即 MySQL 决定如何查找表中的行。
性能从最优到最差分别为:system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
-
system
system:当表仅有一行记录时(系统表),数据量很少,往往不需要进行磁盘IO,速度非常快 -
const
const:表示查询时命中primary key主键或者unique唯一索引,或者被连接的部分是一个常量(const)值。这类扫描效率极高,返回数据量少,速度非常快。 -
eq_ref
eq_ref:查询时命中主键primary key或者unique key索引,type就是eq_ref。 -
ref_or_null
ref_or_null:这种连接类型类似于 ref,区别在于MySQL会额外搜索包含NULL值的行。 -
index_merge
index_merge:使用了索引合并优化方法,查询使用了两个以上的索引。 -
unique_subquery
unique_subquery:替换下面的IN子查询,子查询返回不重复的集合。 -
index_subquery
index_subquery:区别于unique_subquery,用于非唯一索引,可以返回重复值。 -
range
range:使用索引选择行,仅检索给定范围内的行。简单点说就是针对一个有索引的字段,给定范围检索数据。在where语句中使用bettween...and、<、>、<=、in等条件查询type都是range。 -
index
index:Index与ALL其实都是读全表,区别在于index是遍历索引树读取,而ALL是从硬盘中读取。 -
ALL
就不用多说了,全表扫描。
-
-
possible_keys 列:显示查询可能使用哪些索引来查找,使用索引优化sql的时候比较重要。
-
key 列:这一列显示 mysql 实际采用哪个索引来优化对该表的访问,判断索引是否失效的时候常用。
-
key_len 列:显示了 MySQL使用
-
ref 列:ref 列展示的就是与索引列作等值匹配的值,常见的有:const(常量),func,NULL,字段名。
-
rows 列:这也是一个重要的字段,MySQL查询优化器根据统计信息,估算SQL要查到结果集需要扫描读取的数据行数,这个值非常直观显示SQL的效率好坏,原则上rows越少越好。
-
Extra 列:显示不适合在其它列的额外信息,虽然叫额外,但是也有一些重要的信息:
-
Using index:表示MySQL将使用覆盖索引,以避免回表
-
Using where:表示会在存储引擎检索之后再进行过滤
-
Using temporary :表示对查询结果排序时会使用一个临时表。
互联网JAVA面试常问问题
前几篇文章,都介绍了JAVA面试中锁相关的知识。其实关于JAVA锁/多线程,你还需要知道了解关于ReentrantLock的知识,本文将从源码入手,介绍可重入锁的相关知识。
ReentrantLock
先来看看ReentrantLock的源码,部分代码块用省略号代替,后面会详细展开介绍:
public class ReentrantLock implements Lock, java.io.Serializable {
private static final long serialVersionUID = 7373984872572414699L;
/** Synchronizer providing all implementation mechanics */
private final Sync sync;
abstract static class Sync extends AbstractQueuedSynchronizer {
private static final long serialVersionUID = -5179523762034025860L; /** * Performs {@link Lock#lock}. The main reason for subclassing * is to allow fast path for nonfair version. */
abstract void lock(); /** * Performs non-fair tryLock. tryAcquire is implemented in * subclasses, but both need nonfair try for trylock method. */
final boolean nonfairTryAcquire(int acquires) {
.......
}
protected final boolean tryRelease(int releases) {
int c = getState() - releases;
if (Thread.currentThread() != getExclusiveOwnerThread())
throw new IllegalMonitorStateException();
boolean free = false;
if (c == 0) {
free = true;
setExclusiveOwnerThread(null);
}
setState(c);
return free;
}
protected final boolean isHeldExclusively() {
// While we must in general read state before owner,
// we don't need to do so to check if current thread is owner
return getExclusiveOwnerThread() == Thread.currentThread();
}
........
} /** * Sync object for non-fair locks */
static final class NonfairSync extends Sync {
.......
} /** * Sync object for fair locks */
static final class FairSync extends Sync {
...........
}
..........
}可以看出可重入锁的源码中,其实实现了公平锁和非公平锁。
ReentrantLock中有一个静态内部抽象类Sync,然后有NonfairSync和FairSync两个静态类继承了Sync。
其中Sync继承了AQS(AbstractQueuedSynchronizer),接下来的文章中会介绍详细AQS。
我们在使用可重入锁的时候,需要明显的加锁和释放锁的过程。一般在finally代码中实现锁释放的过程。
Lock lock = new ReentrantLock();
Condition condition = lock.newCondition();
lock.lock();
try { while(条件判断表达式) {
condition.wait();
}
// 处理逻辑
}
finally
{
lock.unlock();
}非公平锁的实现
static final class NonfairSync extends Sync {
private static final long serialVersionUID = 7316153563782823691L;
/** * Performs lock. Try immediate barge, backing up to normal * acquire on failure. */
final void lock() {
if (compareAndSetState(0, 1))
setExclusiveOwnerThread(Thread.currentThread());
else
acquire(1);
}
protected final boolean tryAcquire(int acquires) {
return nonfairTryAcquire(acquires);
}
}可以看出,非公平锁在执行lock的时候,会用CAS来尝试将锁状态改成1,如果修改成功,则直接获取锁,用setExclusiveOwnerThread方法讲当前线程设置为自己。如果没有修改成功,则会执行acquire方法来尝试获取锁。其中,nonfairTryAcquire实现如下:
final boolean nonfairTryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0) // overflow
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}可以看出这个方法,其实也是在用CAS尝试将线程状态置为1。其实也是一个多次尝试获取的过程。
所以,对于非公平锁,当一线程空闲时候,其他所有等待线程拥有相同的优先级,谁先争抢到资源即可以获取到锁。
公平锁的实现
static final class FairSync extends Sync {
private static final long serialVersionUID = -3000897897090466540L;
final void lock() {
acquire(1);
} /** * Fair version of tryAcquire. Don't grant access unless * recursive call or no waiters or is first. */
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (!hasQueuedPredecessors() &&
compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
}主要看当公平锁执行lock方法的时候,会调用 acquire方法, acquire方法首先尝试获取锁并且尝试将当前线程加入到一个队列中,所以公平锁其实是维护了一个队列,谁等待的时间最长,当线程空闲时候,就会最先获取资源:
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}如果想了解acquireQueued的话,可以参照一下代码:
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node); p.next = null; // help GC
failed = false;
return interrupted;
}
if (shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node); } }综上,可重入锁利用CAS原理实现了公平锁和非公平锁,为什么叫做可重入锁呢?其实在代码方法tryAcquire中可以看到,线程可以重复获取已经持有的锁。
if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0) // overflow
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}今天小强从源码的角度分析了ReentrantLock,希望对正在学习JAVA的你有所帮助。
以上是关于MySQL面试常问问题(SQL 优化 ) —— 赶快收藏的主要内容,如果未能解决你的问题,请参考以下文章