最新论文笔记(+19):TrustFed: A Framework for Fair and Trustworthy Cross-Device Federated Learning in IIoT
Posted crypto_cxf
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了最新论文笔记(+19):TrustFed: A Framework for Fair and Trustworthy Cross-Device Federated Learning in IIoT相关的知识,希望对你有一定的参考价值。
TrustFed: A Framework for Fair and Trustworthy Cross-Device Federated Learning in IIoT "译为“TurstFed:在工业物联网中一种公平可信的跨设备联邦学习框架”
这篇文章是IEEE Transactions on Industrial Informatics 21上的一篇联邦学习和区块链相结合应用到物联网中的文章。总体来看,本文内容还不错,明确指出了现存的主要问题,并针对这几个问题进行了解答,对读者的帮助还是很大的,但是一个框架型方案,对具体的细节解释还不够深入!以下是个人根据自身读后的感悟,并整理的一些学习笔记,随性记录,并不一定按照文章结构顺序。
文章目录预览
一、背景及贡献
1.1 写作背景
随着国家数据安全法规的日益完善、各方组织之间的数据孤岛问题愈发严重,以及数据泄露风险的不断增加,人们对数据隐私保护的需求也越来越强。如何做到不泄露数据的情况下,达到完成机器学习的目的呢?联邦学习技术孕育而生,它使数据不出本地的情况下,有效地利用交互模型中间参数进行模型训练,从而得到较好的模型,主要是解决了不同参与方之间的数据孤岛问题,和数据安全与隐私保护问题。联邦学习也是一种隐私保护的分布式机器学习协议。
联邦学习训练主要采用两种配置方法,一种是跨数据集(Cross-dataset)联邦学习系统CDSFL(其他文章也叫跨孤岛),该系统将数据集垂直划分到训练网络中的多个参与者,另一种是跨设备(Cross-device)系统CDFL,通过该系统数据集被水平划分到训练网络中的所有设备上。下面是这两种类型的对比:

但是CDSFL系统总是依赖集中式服务器来协调参与者之间的训练服务,聚合模型更新,并维护集中式模型的不同版本。这种类型的FL设置总需要一个稳定的通信网络,以确保FL参与者的高可用性。而在CDFL系统中,设备可以加入或离开训练网络,CDFL去中心化特性也增加了潜在的网络通信成本,进而增加了模型中毒和对抗性攻击的概率。训练网络的解耦增加了底层点对点网络的通信成本,同样这些设备可以通过发起对抗性攻击来串通和污染某些设备上的训练模型,导致不公平地训练出低质量的FL模型。另一方面,跨设备(Cross-device)联邦学习系统CDFL实现了完全去中心化的训练网络,每个参与者可以作为模型所有者和生产者。CDFL系统需要确保网络中所有参与者的公平性、可信度和高质量的模型可用性。
1.2 主要贡献
综上,考虑到数据集的去中心化性质,设备的FL系统中的分布,以及训练高质量和人群代表性模型的要求,公平和可信赖性的问题需要特别的关注。本文旨在实现一个完全去中心化的CDFL系统,该系统使用IIOT设备作为FL参与者,考虑CDFL训练模型中参与者的分散化、训练配置 以及公平性和信任度的要求,本文目标是将区块链作为CDFL训练网络中分散的信任实体。主要贡献如下:
- 1)提出了一个区块链支持的框架——TrustFed,用于一个完全去中心化的CDFL系统,提议框架使用以太坊区块链和智能合约技术来实现去中心化,并在CDFL系统中维护参与者的声誉。
- 2)提出了一个新的CDFL公平协议,该协议检测出训练分布中的异常值,并在聚合模型更新之前去除它们。
- 3)作者使用了一个真实的 IIoT数据集来实现和测试TrustFed提议的协议。
- 4)与其他最先进的标准方法进行了比较与评估。(实则没有比较,只是自己实验了)
二、系统框架
2.1 联邦学习信誉系统
- 1)中心化联邦学习系统:服务器根据所有设备的性能评估来选择下一轮FL设备集合。在集中式的联邦学习系统中,无需共享信誉系统。但一个集中式的实体控制所有设备的信誉变得不可取,成为了严重的信任问题。
- 2)去中心化联邦学习系统:需要一个公开共享的记录来显示每个设备的声誉。区块链可提供去中心化的公开分类账,用于存储所有设备的信誉。本方案的区块链主要动机是实现公平和可信的跨设备联邦学习系统。
- 3)联邦学习和区块链的关系:区块链可以多种方式与联邦学习应用集成,而本方案的目标是提供一个松耦合,与区块链无关的CDFL系统。这种方法有助于将所建议的框架与任何允许或不允许的可编程区块链系统集成。
根据自身的理解,本文的方案实则是以下的图例:
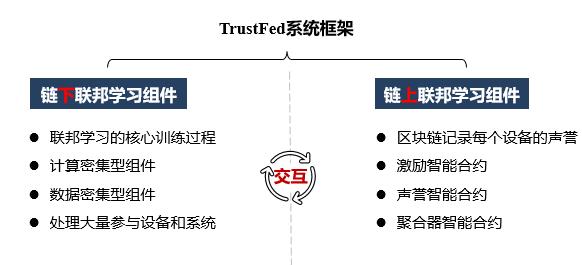
2.2 链下联邦学习系统
S
i
:
S_i:
Si: 代表服务器
W
i
:
W_i:
Wi: 代表设备工作者
P
i
:
P_i:
Pi: 代表参与者
W
i
:
W^i:
Wi: 代表权重
C
:
C:
C: 代表信誉好的设备
h
t
:
h_t:
ht: 代表全局模型超参数
- (1)QoS(Quality of Service)管理者:去中心化系统中过多的异构设备和系统引起了质量问题,如一些设备的延迟报告可能导致一些重要的模型更新或某些设备上NON-IID数据集的丢失,从而导致模型过度拟合。同样,异步设置也会导致梯度优化延迟,导致模型收敛性差。QoS管理器发布每个 P t P_t Pt的质量需求和激励承诺,并根据它们在区块链网络上的声誉选择最有前途的设备。
- (2)训练管理者:随机选取一些
C
=
p
:
p
∈
P
i
,
R
e
p
(
p
)
>
λ
C=\\p: p\\in P_i ,Rep(p) >\\lambda\\
C=p:p∈Pi,Rep(p)>λ,其中
λ
\\lambda
λ是平均信誉分,在每轮训练结束时生成模型性能统计数据。并分为两个子轮训练。(根据自身的理解,画了如下流程图)
- 发送参数 h t h_t ht和权值 W 0 W^0 W0分配给每个C,C对模型进行训练后生成新的权值 W 1 W^1 W1和 E n c ( W 1 ) Enc(W^1) Enc(W1),并发回给训练管理者。
- 将C划分为两组,收敛贡献度小于等于平均值的被归类为 C 1 C^1 C1,其余为 C 2 C^2 C2。对模型更新进行交叉验证,即 W C 2 1 → C 1 , W C 1 1 → C 2 W^1_C^2\\to C^1, W^1_C^1\\to C^2 WC21→C1,WC11→C2 , C i C_i Ci再次训练产生新的 W 2 W^2 W2。

- (3)模型统计解释器:维护模型统计数据分布,以检测 C i C_i Ci模型的性能,并根据每次训练子轮的变化,将新的声誉分数分配给每个 C i C_i Ci。
- (4)模型版本管理者:交叉检测模型性能,并与初始模型性能相比较。将模型存储在去中心化的IPFS系统中,并将模型更新给所有FL参与者。
- (5)FL核心组件:主要包括模型聚合器和Peers。
- 模型聚合器:聚合收到的 W 2 W^2 W2,将更新后的模型权值存储在IPFS上。通过智能合约发起新的区块链交易,以更新网络上所有的FL参与者。
- Peers:进行本地训练,与P2P网络上的参与者 P i P_i Pi通信,并为模型聚合器收集权重 W i W^i Wi。
2.3 链上联邦学习系统
主要包括三个智能合约,分别为信誉智能合约、聚合器智能合约和激励机制智能合约。
- (1)信誉智能合约:设备需要信誉分数来找更信任的服务器,而服务器也需要根据信誉分找潜在的模型贡献者。
- 委托人 T u T_u Tu:为可信用户和可信来源,受托人的信誉分公开给所有者。
- 受托人 T p T_p Tp:为可信提供者或可信destination与系统交互,只有参与设备才能更新 T p T_p Tp的destination信任值。
- 链下操作:由多个 T u T_u Tu执行计算复杂的迭代函数的信任值积累,链下计算包括统计方法、AI模型、预测方案、处理信任值等。
- 链上声誉聚合:每个 T p T_p Tp基于共识的信任值聚合,并执行算法1(主要分三步,计算信誉设备数量、找出信誉分高的设备和输出相应的信誉分;咨询原作者得知算法1中的EA表示以太坊地址)。合约归 T p T_p Tp所有,执行算法2中的公平FL协议后,再计算设备的信誉。
- (2)聚合器智能合约:
- 对模型权重进行链上聚合,并更新模型的新版本。
- 生成更新后的权重矩阵和相应模型的统一哈希值,并在链上聚合,以及更新权重链。
- (3)激励机制智能合约:
- 所有设备被认为自愿参与训练过程。
- 使得所有参与设备公布其QoS参数(如最低可接受精度、训练预算、训练时间和其他参数等)
- 并使用加密货币进行支付奖励。(如以太坊的ERC-20)
- (4)公平FL协议算法:
- 每个 S I S_I SI输入QoS参数,将设备划分为两类,trainers(即 C 1 C^1 C1)和validators(即 C 2 C^2 C2)。
- trainers逐个训练模型。
- trainers发送模型给validators验证。
- 互换角色,重复前面的训练和验证过程。
- 计算异常值和平均精度。
- 判断平均精度是否满足QoS参数中的精度要求。
三、性能分析
实验环境:Python语言、PyTorch框架、涡扇发动机退化仿真数据集NASA。

结论:无论设备数量如何,本方案在损失较低方面表现出更好的结果。
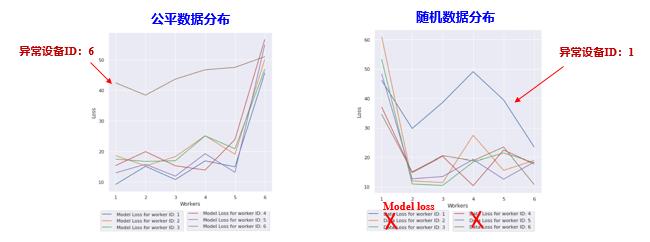
(图中的Data loss应该是打错了,我觉得是Model loss,并未得到原作者证实,个人猜想)
结论:根据损失值的异常,可以检测出恶意设备。
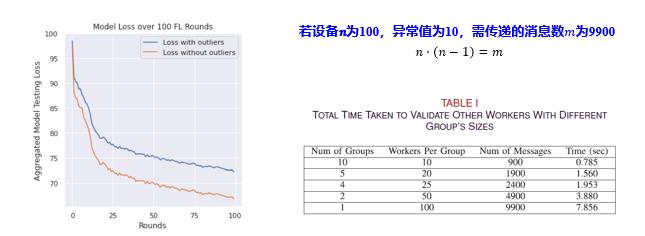
结论:无异常值比有异常值模型聚合时的损失更小;与异常值的预期数量相比,分组数量不应太小。
四、总结与思考
本文主要有以下四个贡献:
- 1)使用勒以太坊区块链和智能合约实现去中心化的CDFL系统——TrustFed。
- 2)提出了一个新的CDFL协议,该协议检测出训练分布中的异常值。(一次异常就剔除,有点牵强吧?)
- 3)使用了一个真实的IIoT数据集实现和测试TrustFed(感觉训练的设备数量不够,仅仅100个?)
- 4)将结果与最新的标准方法进行了比较与评估。(好像并没有比较)
CVPR2021最全整理 | CVPR2021最新论文
持续更新Github:
https://github.com/Sophia-11/...
CVPR 2021
致力于计算机视觉和模式识别包括颜色检测、跟踪、运动、物体识别、音响和目标检测。
Image-to-image Translation via Hierarchical Style Disentanglement Xinyang Li, Shengchuan Zhang, Jie Hu, Liujuan Cao, Xiaopeng Hong, Xudong Mao, Feiyue Huang, Yongjian Wu, Rongrong Ji https://arxiv.org/abs/2103.01456 https://github.com/imlixinyang/HiSD
FLAVR: Flow-Agnostic Video Representations for Fast Frame Interpolation https://arxiv.org/pdf/2012.08512.pdf https://tarun005.github.io/FLAVR/Code https://tarun005.github.io/FLAVR/
Patch-NetVLAD: Multi-Scale Fusion of Locally-Global Descriptors for Place Recognition Stephen Hausler, Sourav Garg, Ming Xu, Michael Milford, Tobias Fischer https://arxiv.org/abs/2103.01486
Depth from Camera Motion and Object Detection Brent A. Griffin, Jason J. Corso https://arxiv.org/abs/2103.01468
UP-DETR: Unsupervised Pre-training for Object Detection with Transformers https://arxiv.org/pdf/2011.09094.pdf
Multi-Stage Progressive Image Restoration https://arxiv.org/abs/2102.02808 https://github.com/swz30/MPRNet
Weakly Supervised Learning of Rigid 3D Scene Flow https://arxiv.org/pdf/2102.08945.pdf https://arxiv.org/pdf/2102.08945.pdf https://3dsceneflow.github.io/
Exploring Complementary Strengths of Invariant and Equivariant Representations for Few-Shot Learning Mamshad Nayeem Rizve, Salman Khan, Fahad Shahbaz Khan, Mubarak Shah https://arxiv.org/abs/2103.01315
Re-labeling ImageNet: from Single to Multi-Labels, from Global to Localized Labels https://arxiv.org/abs/2101.05022 https://github.com/naver-ai/relabel_imagenet
Rethinking Channel Dimensions for Efficient Model Design https://arxiv.org/abs/2007.00992 https://github.com/clovaai/rexnet
Coarse-Fine Networks for Temporal Activity Detection in Videos Kumara Kahatapitiya, Michael S. Ryoo https://arxiv.org/abs/2103.01302
A Deep Emulator for Secondary Motion of 3D Characters Mianlun Zheng, Yi Zhou, Duygu Ceylan, Jernej Barbic https://arxiv.org/abs/2103.01261
Fair Attribute Classification through Latent Space De-biasing https://arxiv.org/abs/2012.01469 https://github.com/princetonvisualai/gan-debiasing https://princetonvisualai.github.io/gan-debiasing/
Auto-Exposure Fusion for Single-Image Shadow Removal Lan Fu, Changqing Zhou, Qing Guo, Felix Juefei-Xu, Hongkai Yu, Wei Feng, Yang Liu, Song Wang https://arxiv.org/abs/2103.01255
Less is More: CLIPBERT for Video-and-Language Learning via Sparse Sampling https://arxiv.org/pdf/2102.06183.pdf https://github.com/jayleicn/ClipBERT
MetaSCI: Scalable and Adaptive Reconstruction for Video Compressive Sensing Zhengjue Wang, Hao Zhang, Ziheng Cheng, Bo Chen, Xin Yuan https://arxiv.org/abs/2103.01786
AttentiveNAS: Improving Neural Architecture Search via Attentive https://arxiv.org/pdf/2011.09011.pdf
Diffusion Probabilistic Models for 3D Point Cloud Generation Shitong Luo, Wei Hu https://arxiv.org/abs/2103.01458
There is More than Meets the Eye: Self-Supervised Multi-Object Detection and Tracking with Sound by Distilling Multimodal Knowledge Francisco Rivera Valverde, Juana Valeria Hurtado, Abhinav Valada https://arxiv.org/abs/2103.01353 http://rl.uni-freiburg.de/research/multimodal-distill
Encoding in Style: a StyleGAN Encoder for Image-to-Image Translation https://arxiv.org/abs/2008.00951 https://github.com/eladrich/pixel2style2pixel https://eladrich.github.io/pixel2style2pixel/
Hierarchical and Partially Observable Goal-driven Policy Learning with Goals Relational Graph Xin Ye, Yezhou Yang https://arxiv.org/abs/2103.01350
RepVGG: Making VGG-style ConvNets Great Again https://arxiv.org/abs/2101.03697 https://github.com/megvii-model/RepVGG
Transformer Interpretability Beyond Attention Visualization https://arxiv.org/pdf/2012.09838.pdf https://github.com/hila-chefer/Transformer-Explainability
PREDATOR: Registration of 3D Point Clouds with Low Overlap https://arxiv.org/pdf/2011.13005.pdf https://github.com/ShengyuH/OverlapPredator https://overlappredator.github.io/
以上是关于最新论文笔记(+19):TrustFed: A Framework for Fair and Trustworthy Cross-Device Federated Learning in IIoT的主要内容,如果未能解决你的问题,请参考以下文章