redis八种淘汰策略是啥?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了redis八种淘汰策略是啥?相关的知识,希望对你有一定的参考价值。
redis八种淘汰策略如下:
Redis(Remote Dictionary Server ),即远程字典服务,是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。从2010年3月15日起,Redis的开发工作由VMware主持。从2013年5月开始,Redis的开发由Pivotal赞助。
特点:
Redis 是一个高性能的key-value数据库。 redis的出现,很大程度补偿了memcached这类key/value存储的不足,在部 分场合可以对关系数据库起到很好的补充作用。它提供了Java,C/C++,C#,php,javascript,Perl,Object-C,Python,Ruby,Erlang等客户端,使用很方便。
Redis支持主从同步。数据可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层树复制。存盘可以有意无意的对数据进行写操作。由于完全实现了发布/订阅机制,使得从数据库在任何地方同步树时,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和数据冗余很有帮助。
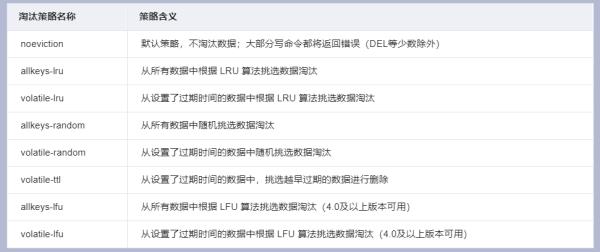
参考技术A1、noeviction:默认策略,不淘汰数据;大部分写命令都将返回错误(DEL等少数除外)。
2、allkeys-lru:从所有数据中根据 LRU 算法挑选数据淘汰。
3、volatile-lru:从设置了过期时间的数据中根据 LRU 算法挑选数据淘汰 。
4、allkeys-random:从所有数据中随机挑选数据淘汰。
5、volatile-random:从设置了过期时间的数据中随机挑选数据淘汰。
6、volatile-ttl:从设置了过期时间的数据中,挑选越早过期的数据进行删除。
7、allkeys-lfu:从所有数据中根据 LFU 算法挑选数据淘汰(4.0及以上版本可用)。
8、volatile-lfu:从设置了过期时间的数据中根据 LFU 算法挑选数据淘汰(4.0及以上版本可用)。

LRU算法:
LRU(Least Recently Used)最近最少使用。优先淘汰最近未被使用的数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。
LRU底层结构是 hash 表 + 双向链表。hash 表用于保证查询操作的时间复杂度是O(1),双向链表用于保证节点插入、节点删除的时间复杂度是O(1)。
单链表可以实现头部插入新节点、尾部删除旧节点的时间复杂度都是O(1),但是对于中间节点时间复杂度是O(n),因为对于中间节点c,我们需要将该节点c移动到头部,此时只知道他的下一个节点,要知道其上一个节点需要遍历整个链表,时间复杂度为O(n)。
LRU GET操作:如果节点存在,则将该节点移动到链表头部,并返回节点值。
LRU PUT操作:
1、节点不存在,则新增节点,并将该节点放到链表头部。
2、节点存在,则更新节点,并将该节点放到链表头部。
聊聊 Redis 内存淘汰策略
文章首发于公众号 “蘑菇睡不着”
前情回顾
《源码级别了解Redis持久化》
《聊聊Redis过期键删除策略》
《Redis数据结构详解》
《超详细Redis五种数据结构底层实现》
这一期咱们一起来看看 Redis 的内存淘汰策略~
为什么要有内存淘汰机制
大家都知道 Redis 中的键会设置过期时间,当到达过期时间时会通过一定策略清除对应 key,但是 redis 内存是由上限的,当达到内存上限时,就要通过一定策略淘汰掉相应 kv 键值对。
Redis 内存上限
maxmemory 配置选项使用来配置 Redis 的存储数据所能使用的最大内存限制。可以通过在内置文件redis.conf中配置,也可在Redis运行时通过命令CONFIG SET来配置。例如,我们要配置内存上限是100M的Redis缓存,那么我们可以在 redis.conf 配置如下:
maxmemory 100mb设置 maxmemory 为 0 表示没有内存限制。在 64-bit 系统中,默认是 0 无限制,但是在 32-bit 系统中默认是 3GB。
当存储数据达到限制时,Redis 会根据情形选择不同策略,或者返回errors(这样会导致浪费更多的内存),或者清除一些旧数据回收内存来添加新数据。
Redis 内存淘汰策略
- noenviction:不清除数据,只是返回错误,这样会导致浪费掉更多的内存,对大多数写命令(DEL 命令和其他的少数命令例外)
- allkeys-lru:从所有的数据集中挑选最近最少使用的数据淘汰,以供新数据使用
- volatile-lru:从已设置过期时间的数据集中挑选最近最少使用的数据淘汰,以供新数据使用
- allkeys-random:从所有数据集中任意选择数据淘汰,以供新数据使用
- volatile-random:从已设置过期时间的数据集中任意选择数据淘汰,以供新数据使用
- volatile-ttl:从已设置过期时间的数据集中挑选将要过期的数据淘汰,以供新数据使用
- volatile-lfu:从所有配置了过期时间的键中淘汰使用频率最少的键
- allkeys-lfu:从所有键中淘汰使用频率最少的键
回收的过程
理解回收过程是运作流程非常的重要,回收过程如下:
- 一个客户端运行一个新命令,添加了新数据。
- Redis检查内存使用情况,如果大于maxmemory限制,根据策略来回收键。
- 一个新的命令被执行,如此等等。
我们添加数据时通过检查,然后回收键以返回到限制以下,来连续不断的穿越内存限制的边界。
如果一个命令导致大量的内存被占用(比如一个很大的集合保存到一个新的键),那么内存限制很快就会被这个明显的内存量所超越。
近似LRU算法
Redis的LRU算法不是一个严格的LRU实现。这意味着Redis不能选择最佳候选键来回收,也就是最久未被访问的那些键。相反,Redis 会尝试执行一个近似的LRU算法,通过采样一小部分键,然后在采样键中回收最适合(拥有最久访问时间)的那个。
然而,从Redis3.0开始,算法被改进为维护一个回收候选键池。这改善了算法的性能,使得更接近于真实的LRU算法的行为。Redis的LRU算法有一点很重要,你可以调整算法的精度,通过改变每次回收时检查的采样数量。
这个参数可以通过如下配置指令:
maxmemory-samples 5Redis没有使用真实的LRU实现的原因,是因为这会消耗更多的内存。然而,近似值对使用Redis的应用来说基本上也是等价的。
LFU
LFU (Least frequently used) 最不经常使用算法。而 LRU 是最近最少使用算法。
从 Redis 4.0 开始,可以使用 LFU 过期策略。这种模式在某些情况下可能会更好(提供更好的命中率/未命中率),因为使用 LFU Redis 会尝试跟踪项目的访问频率,因此很少使用的项目会被淘汰,而经常使用的项目有更高的机会留在内存中。
那为什么会出现 LFU 算法那?大家请看下面的场景:
A - A - A - - - A - A -A - - -
B - - - - B - - B - - - - - - B如果是 LRU 算法 那么会淘汰 A,因为 B 是最近使用的,但是很明显 A 的使用频率是最高的,理应留下 A,所以 LFU 算法应运而生。(淘汰最少使用的 key)
LFU 把原来的 key 对象的内部时钟的24位分成两部分,前16位还代表时钟,后8位代表一个计数器, 称为Morris 计数器。后8位表示当前key对象的访问频率,8位只能代表255,但是 redis 并没有采用线性上升的方式,而是通过一个复杂的公式,通过配置两个参数来调整数据的递增速度。
下图从左到右表示key的命中次数,从上到下表示影响因子,在影响因子为100的条件下,经过10M次命中才能把后8位值加满到255.
| factor | 100 hits | 1000 hits | 100K hits | 1M hits | 10M hits |
|---|---|---|---|---|---|
| 0 | 104 | 255 | 255 | 255 | 255 |
| 1 | 18 | 49 | 255 | 255 | 255 |
| 10 | 10 | 18 | 142 | 255 | 255 |
| 100 | 8 | 11 | 49 | 143 | 255 |
这个参数是可配置的的,通过这个:
lfu-log-factor 10上说的是计数器的增长,那么什么情况削减那?
默认是 如果一个 key 每一分钟没使用,Morris 计数器 就削减 1. 这个也可以通过下面进行配置:
lfu-decay-time 1有个问题就是,新的 key 怎么办,岂不是上来就被淘汰?
为了避免这种问题 Redis 默认情况下新分配的key的后8位计数器的值为5,防止因为访问频率过低而直接被删除。
总结
Redis 为了避免内存超出容量,使用特定的内存淘汰策略来释放内存,主要思想是 LRU 和 Redis 4.0 推出的 LFU 算法。LRU 是最近最少使用算法,LFU 是最少使用算法。
更多精彩内容,微信搜索 “蘑菇睡不着”
如果觉得对您有帮助,麻烦帮忙点个赞,你的支持是我创作最大的动力
你越主动就越主动,我们下期见~
以上是关于redis八种淘汰策略是啥?的主要内容,如果未能解决你的问题,请参考以下文章