浅谈uf8mb4字符集
Posted 星光落入你灰蒙蒙的眼
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浅谈uf8mb4字符集相关的知识,希望对你有一定的参考价值。
要在 Mysql 中保存 4 字节长度的 UTF-8 字符,需要使用 utf8mb4 字符集(mb4就是most bytes 4的意思,专门用来兼容四字节的unicode),但只有 5.5.3 版本以后的才支持。
为了获取更好的兼容性,应该总是使用 utf8mb4 而非 utf8. 对于 CHAR 类型数据,utf8mb4 会多消耗一些空间,根据 mysql 官方建议,使用 VARCHAR 替代 CHAR。其实,utf8mb4是utf8的超集,理论上原来使用utf8,然后将字符集修改为utf8mb4,也会不会对已有的utf8编码读取产生任何问题。当然,为了节省空间一般情况下使用utf8也就够了!转换是否有影响
MySQL 可以设置数据库级别,表级别,列级别 字符集编码
优先级顺序为:
数据库字符集<表字符集<列字符集
也就是 上面三个级别 字符集不一致时,以 更小范围的配置 为准;
例如:数据库字符集为utf8,表字符集不设置的情况下会默认utf8。如果表主动设置了编码 utf8mb4,那么表的字符集编码就为utf8mb4。
MySQL数据库的"utf8"并不是真正概念里的UTF-8
转载链接
MySQL中的“utf8”编码只支持最大3字节每字符。真正的大家正在使用的UTF-8编码是应该能支持4字节每个字符。
MySQL的开发者没有修复这个bug。他们在2010年增加了一个变通的方法:一个新的字符集“utf8mb4”
当然,他们并没有对外公布(可能因为这个bug有点尴尬)。现在很多指南推荐用户使用“utf8”其实都错了!
简单的说:
MySQL中的 “utf8mb4” 才是 真正意义上的“UTF-8”。
MySQL的utf8是个“特殊的字符编码”。这种编码很多Unicode字符保存不了。
建议MySQL和MariaDB用户使用“utf8mb4”而不是“utf8”。
编码是什么?什么是UTF-8?
计算机使用0和1存储文字。比如第一段第一个字符存储为“01000011”表示“C”,计算机通过以下两个步骤选择用“C”表示:
计算机读取到“01000011”后计算出这是数字67。
计算机通过查找Unicode字符集来确认67代表的“C”。
同样的事情发生在我打字输入C的时候。
计算机通过Unicode字符集将“C” 映射为67。
计算机把67编码为“01000011”发送给web服务器。
几乎所有的程序和互联网应用使用Unicode字符集。
Unicode字符集里有超过100万个字符(“C” 和 “❤” 是两种不同的字符)。UTF-32是最简单的编码方式,它在表示每个字符的时候使用32个bits。这样编码简单,但是并不实用,明显浪费了太多的空间。
UTF-8相比UTF-32更加节约空间。在UTF-8中,像“C”这样的字符占用8bits,“❤”这样的占用32 bits。其他字符占用16或者24 bits。用UTF-8存储比用UTF-32节省4倍左右的空间。更小的空间占用也意味着加载速度会快上4倍。
而MySQL中的 “utf8”字符集则和其他应用行为不一样。比如根本没法表示“❤”。
MySQL从4.1版开始支持UTF-8。那是在比今天UTF-8 RFC 3629标准更早的2003年。
在此之前的UTF-8标准,RFC 2279中规定6个bytes表示一个字符。MySQL的开发者在2002.3.28编码实现了RFC 2279 。并发布了pre-pre-release 的 MySQL 4.1,然后在9月出现了一个神秘的字节调整。“UTF8 now works with up to3 byte sequences only.”
回到2002年,如果用户可以保证表中的每一行具有相同的字节数,MySQL就可以提高用户的速度。为了得到这个提升,用户就需要定义保存文字的列为“CHAR”。一个“CHAR”列总是拥有相同的字符数。如果存入的字符较少则会在最后补齐空白。如果存入的数据过多则会被抛弃多余的字符。
当MySQL的开发者第一次尝试以6字节每字符实现UTF-8时,他们意识到CHAR(1)的列会占用6字节,CHAR(2)会占用12字节,以此类推。
显而易见的是,这个没有被使用的实现方式是正确的,任何一个理解UTF-8的开发者将会认同这一点。
我的猜测是:MySQL的开发者违背了“utf8”编码去帮助那些1)试图去优化空间和速度的人,2)尝试优化空间和速度失败的人。
这是个无人获益的改动。那些想要更快性能,更小空间的得到的依然是比他们曾经使用版本更大更慢的实现,而那些想要正确的“utf8”的人得到的是个“❤”都存储不了的实现。
MySQL发布了这个错误的版本后,在也没有修复它:因为那样很多使用者将被迫重建他们的数据库。MySQL最终在2010年更新了一个以“utf8mb4”命名的UTF-8实现。
如果你使用MySQL或者 MariaDB,不要使用“utf8”,应该总是使用“utf8mb4”,否则总有一天会遇到头疼的事情。
字节和字符
varchar(255)所表示的单位是字符,而一个汉字一个字母都是一字符。所以这里可以存储255个汉字或者255个字母。
utf-8下 1字符=3字节。 (uft-8也称之为utf-8mb3)
utf-8mb4下 1字符=4字节。
存储上限
varchar的存储上限是65535字节
utf-8 varchar(21845)是上限(65535/3)
utf-8mb4 varchar(16383)是上限(65535/4)
表情☺️
一个表情是占用4个字节,所以utf-8下,表情会乱码,1字符装不下,需要额外的空间。
utf-8mb4下,一个表情正好是一字符,能够完美显示。
varchar(255) 即表示能存放255个汉字,或255个字母,或255个表情。
为什么要使用utf8mb4字符集
低版本的MySQL支持的utf8编码,最大字符长度为 3 字节,如果遇到 4 字节的字符就会出现错误了。三个字节的 UTF-8 最大能编码的 Unicode 字符是 0xFFFF,也就是 Unicode 中的基本多文平面(BMP)。也就是说,任何不在基本多文平面的 Unicode字符,都无法使用MySQL原有的 utf8 字符集存储。这些不在BMP中的字符包括哪些呢?最常见的就是Emoji 表情(Emoji 是一种特殊的 Unicode 编码,常见于 ios 和 android 手机上)和一些不常用的汉字,以及任何新增的 Unicode 字符等等。
那么utf8mb4比utf8多了什么的呢?
✔ 多了emoji编码支持
如果实际用途上来看,可以给要用到emoji的库或者说表,设置utf8mb4,比如评论要支持emoji可以用到。
新建mysql库的排序规则
utf8_unicode_ci比较准确,utf8_general_ci速度比较快。通常情况下 utf8_general_ci的准确性就够我们用的了。
如果是utf8mb4那么对应的就是 utf8mb4_general_ci utf8mb4_unicode_ci
索引长度限制
1、对于 myisam 引擎, utf8mb4字符的字段, 允许单索引字段的最大字节为1000, 即最大允许 1000/4=250 个字符, varchar(255)。
2、对于 innodb 引擎, utf8mb4字符的字段, 允许单索引字段的最大字节为765, 即最大允许 765/4=191 个字符, varchar(191)。
如果有启用 innodb_large_prefix 选项,设置 mysql innodb_large_prefix=on, 可将允许索引字段的最大字节约束项扩展至 3072 字节, 即最大允许 3072/4=768个字符, varchar(768)。具体可查阅《mysql 索引长度限制》
You must be more handsome when you work hard!
浅谈javascript和java中的字符串
javascript字符串操作
一、字符串的创建
创建一个字符串有几种方法。
1、最简单的是用引号将一组字符包含起来 var myStr = "Hello, String!";// 在js中单双引号没有区别
2、可使用如下语句:var myStr1 = new String("Hello, String!");
|
1
2
|
console.log(typeof myStr);//"string"console.log(typeof myStr1);//"object" |
以上输出结果表明:myStr是一个简单类型变量,myStr1是一个对象
二、字符串"长度“方法
1、字符串的拼接
concat()或者“+”
2、字符串的截取
1、string.substring(from, to) 返回截取的字符串
参数分别是截取的首尾索引位置。注意:参数to的索引可以大于、小于、等于from的位置,也可以省略,不支持负数!
|
1
2
3
4
5
6
|
var str = "colin is a desinger";section = str .substring(0, 4); // "coli"section = str .substring(4, 0); // "coli"section = str .substring(1, 1); // ""section = str .substring(-2, 4); // "coli"str .substring(0, 4);// "coli"<br>console.log(str) //"colin is a desinger"; |
2、string.slice(start, end) 返回截取的字符串
参数start表示子串的起始位置,如果为负数,那么可以理解为倒数第几个开始,例如-3表示从倒数第三个开始;参数end表示结束位置,与start一 样, 它也可以为负数,其含义也表示到倒数第几个结束。slice()的参数可以为负数,所以要比substring()更加灵活,但没那么宽容了,如果 start比end要大,它将返回一个空字符串
var str = "colin is a desinger"; section = str .slice(0, 4); // "coli" section = str .slice(4, -1); // "n is a desinge" section = str .slice(1, 1); // "" str .slice(0, 4);// "" console.log(str);//"colin is a desinger"
3、substr(start,len) 返回截取的字符串
参数start为开始的位置,len为子字符串的长度 注:不提倡用该函数(我暂时也不知道原因)
三、字符串的“位置”函数
1、str.indexOf(searchvalue,fromindex) 返回字符串中一个子串第一处出现的索引(从左到右搜索)。如果没有匹配项,返回 -1 。
2、str.charAt(index) 返回指定位置的字符
3、str.charCodeAt(index) 返回指定位置的字符的 Unicode 编码。这个返回值是 0 - 65535 之间的整数。
4、str.fromCharCode(numX,numX,...,numX) 可接受一个指定的 Unicode 值,然后返回一个字符串。
四、字符串的“正则”函数
1、威力最强的js字符串函数--> str.replace(regexp/substr,replacement)
改方法用于在字符串中用一些字符替换另一些字符,或替换一个与正则表达式匹配的子串。
参数 replacement是字符串:对于正则replace约定了一个特殊标记符$:
- $i (i:1-99) : 表示从左到右正则子表达式所匹配的文本。
- $&:表示与正则表达式匹配的全文本。
- $`(`:切换技能键):表示匹配字符串的左边文本。
- $’(‘:单引号):表示匹配字符串的右边文本。
- $$:表示$转移。
|
1
2
3
4
5
6
7
|
"boy & girl".replace(/(\w+)\s*&\s*(\w+)/g,"$2 & $1") //girl & boy "boy".replace(/\w+/g,"$&-$&") // boy-boy "javascript".replace(/script/,"$& != $`") //javascript != java "javascript".replace(/java/,"$&$‘ is ") // javascript is script |
第二个参数为函数:
在ECMAScript3推荐使用函数方式,实现于JavaScript1.2.当replace方法执行的时候每次都会调用该函数,返回值作为替换的新值。
函数参数的规定:
- 第一个参数为每次匹配的全文本($&)。
- 中间参数为子表达式匹配字符串,个数不限.( $i (i:1-99))
- 倒数第二个参数为匹配文本字符串的匹配下标位置。
- 最后一个参数表示字符串本身。
|
1
2
3
4
5
6
7
|
String.prototype.capitalize = function(){ return this.replace( /(^|\s)([a-z])/g , function(m,p1,p2){ return p1+p2.toUpperCase(); } ); }; |
2、str.match(rgExp)
如果 match 方法没有找到匹配,将返回 null。 如果找到匹配,则 match 方法返回一个数组,并将更新全局 RegExp 对象的属性以反映匹配结果。如果没有设置全局标志 (g),数组元素 0 包含整个匹配,而元素 1 到 n 包含任何一个子匹配。 此行为与未设置全局标志时 exec 方法(正则表达式)(JavaScript) 的行为相同。如果设置了全局标志,则元素 0 到元素 n 包含所有出现的匹配。如果未设置全局标志,则 match 方法返回的数组有两个特性:input 和 index。 input 属性包含整个被搜索的字符串。 index 属性包含了在整个被搜索字符串中匹配的子字符串的位置。如果设置了标志 i,则搜索不区分大小写。
五、其他常用方法
1、stringObj.trim() 从字符串中移除前导空格、尾随空格和行终止符。
2、str.toLowerCase() 小写
3、str.toUpperCase() 大写
。。。。。。。
六、字符串属性
1、string.constructor 指定创建一个字符串的函数。
|
1
2
3
4
5
6
7
8
|
var x = new String();if (x.constructor == String) document.write("Object is a String.");else document.write("Object is not a String.");// Output:// Object is a String. |
2. string.prototype 为字符串的类返回原型的引用。
用 prototype 属性为对象的类提供一组基本功能。 对象的新的实例“继承”了赋予该对象的原型的行为。
例如,若要将方法添加到返回字符串的最后一个元素的值的 String 对象,请声明函数、将它添加到 String.prototype 并使用它。
|
1
2
3
4
5
6
7
8
|
function string_last( ){ return this.charAt(this.length - 1);}String.prototype.last = string_last;var myString = new String("every good boy does fine");document.write(myString.last());// Ou |
七、JavaScript 字符串是不可变的 --》无法修改字符串的长度。
首先请看以下代码:
|
1
2
3
|
var a="java"a=a+"script"console.log(a);//"javascript" |
变量a对应的字符串内容从”java“ 变为”javascript“,不是证明js字符串是可变的吗?(我开始学js的时候也这么认为)
切记:你要理解内存中那块区域不能改变。即第一样的变量a所指的内存地址,不是二行变量a所指的内存地址
最后请看下面代码:
|
1
2
3
4
5
6
7
8
|
var lang = ‘Java‘;lang[lang.length-1] = ‘S‘;lang[lang.length-1] = ‘c‘;console.log(lang);//"java"var arr = [‘J‘, ‘a‘, ‘v‘, ‘a‘];arr[arr.length-1] = ‘S‘;console.log(arr);// [‘J‘, ‘a‘, ‘v‘, ‘S‘]; |
八、巧用数组实现js数组高效拼接
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
var start = new Date();var str = ""; for (var i = 0; i < 1000000; i++) { str += "test";}var end = new Date();document.writeln("+拼接字符串,耗时:" + (end.getMilliseconds() - start.getMilliseconds()));document.writeln("<br/>");var begin = new Date();var arry = new Array();for (var i = 0; i < 1000000; i++) { arry.push("test");}arry.join("");var stop = new Date();document.writeln("数组方式拼接字符串,耗时:" + (stop.getMilliseconds() - begin.getMilliseconds())); |
九、回归字符串创建
先看以下代码:
|
1
2
3
4
|
var str="colin";var str1=new String("colin");str.substring(0,2); //str基本类型数据 ,为什么可以调用substring方法?str1.substring(0,2); //str1对象 |
这里为什么str变量有substring方法,我暂时也不是很明白。我姑且认为在执行“str.substring()"代码的一瞬间,str变成了一个对象???!!
java字符串操作
一、字符串的创建
1、直接赋值 String str=”hello“;//这里必须要双引号
2、使用new关键字 String str=new String("hello")
两种创建方式的异同:
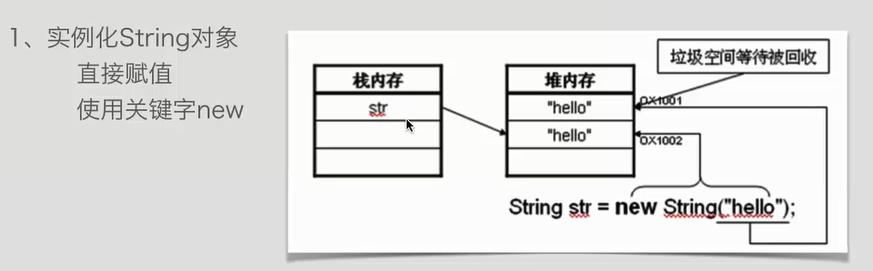
结论:采用第二种方式创建字符串时:系统会在堆内存中创建两个”hello“,但是其中一个”hello“没有的对应的栈内存指引,消耗多余内存,垃圾空间等待被回收。
所以推荐使用第一种方式创建字符串
二、字符串的常用方法
java的很多字符串方法的名字和用法都和js字符串方法类似。
1、public char charAt(int index) 返回指定索引处的 char 值
2、public String concat(String str) 将指定字符串连接到此字符串的结尾。
3、public int indexOf(String str,int fromIndex) 返回指定子字符串在此字符串中第一次出现处的索引,
。。。。
我觉得应该注意的几个好玩方法:
1、public int length() 返回此字符串的长度 这里和js有着细微的区别
2、public boolean startsWith(String prefix, int toffset) 测试此字符串从指定索引开始的子字符串是否以指定前缀开始。
3、public boolean endsWith(String suffix) 测试此字符串是否以指定的后缀结束。
4、public char[] toCharArray() 将此字符串转换为一个新的字符数组。
5、public void getChars(int srcBegin, int srcEnd,char[] dst,int dstBegin) 将字符从此字符串复制到目标字符数组。
三、字符串打的不可变性
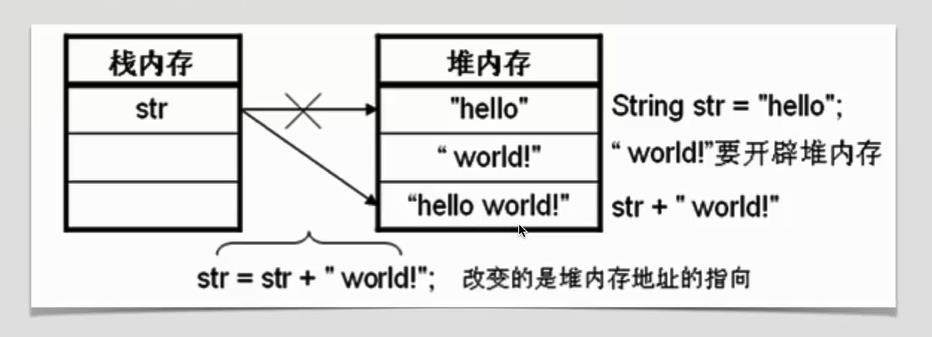
看图就可以,不多解释
四、”另类字符串“
1、StringBuffer sb=new StringBuffer("df");//长度可变,
常用方法:
append()
insert()
replace()
indexOf()
2、StringBuilder sb =new StringBuilder("dsf")
特别适用在单个线程 速度比StringBuffer快
考虑线程安全时,用Stringbuffer比较好
以上是关于浅谈uf8mb4字符集的主要内容,如果未能解决你的问题,请参考以下文章
使用 NSPredicate 过滤以数字或符号开头的字符串到 NSArray