Linux怎样计算一个目录下一部分文件的总大小
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux怎样计算一个目录下一部分文件的总大小相关的知识,希望对你有一定的参考价值。
例如:匹配*20130606*的文件大小怎样计算?
用du -sk *20130606* 命令返回Argument list too long
1、首先我们要知道怎么查看目录下文件,ls 这个命令就可以;但是在虚拟机中无法直接通过 ls 这个命令直接看出 文件 是 目录还是 问价(linux 的文件 系统划分 需要掌握)。
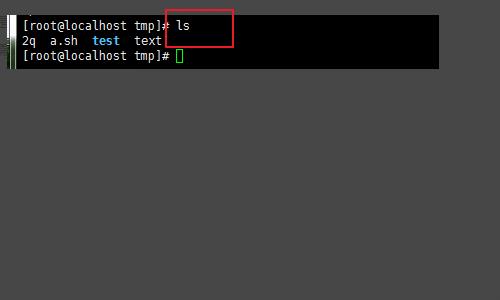
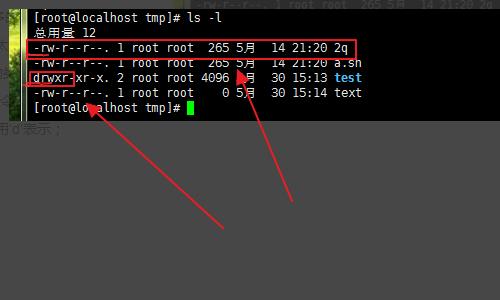
2、我们就需要 ls 的拓展命令 ls-l (可以直接用 ll 这样的简化命令,更多的可以自己查相关资料,命令的相关资料太多了...);这里我们就可直接看出 文件 的类型; 标出的信息开头 ‘-’就是 文件命令中用 f 表示; ‘d’就是目录,命令中就用‘d’表示。
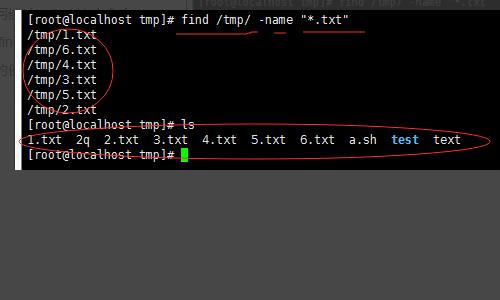
3、然后我们开始进行如何统计;find 这个命令可以查找文件;通过 find /tmp/ -name 文件名,找出来。
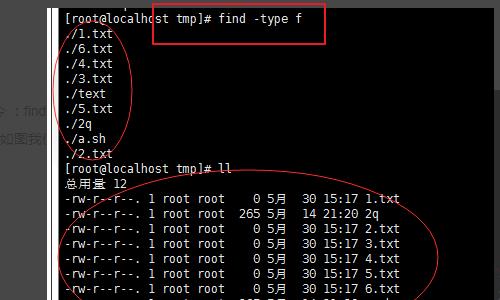
4、然后我们通过扩展 命令 :find -type f(找出 文件类型是 f 的文件)我们可以看出 这个命令效果。
5、然后我们 通过 wc -l 这个命名进行统计;但两个命令需要一起使用, 这个时候通过管道符 “ | ”链接;命令就是:find -type f |wc -l;我们就可以实现 统计文件个数。
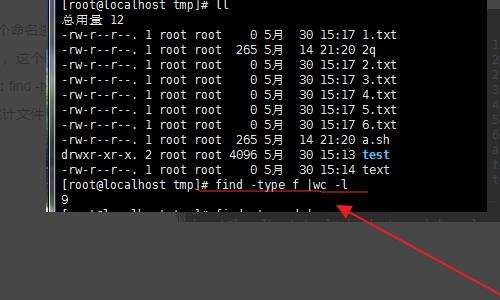
6、同理如果想要统计 目录 ,使用如图命令:find -type d|wc -l;默认会统计 隐藏的 文件或者 目录;所以显示的是 3。
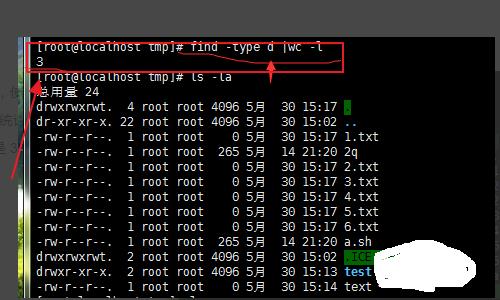
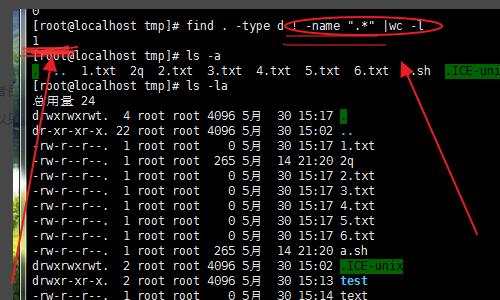
7、隐藏文件或者目录是 ‘.’开头的,所以我们排除它,就可以只统计出显示的文件。
du -h xxx 可以查看单个文件夹的大小
du -h xxx xxx xxx 可以分别查看多个文件的大小
du -h /xxxx 分别列出整个文件夹下 所有文件的大小
du -sh /xxxx 统计整个文件夹的大小 参考技术B Argument list too long 是因为*20130606*匹配到的文件数量太多了
可以使用管道
ls -l | grep 20130606 | awk 'c += $5ENDprint c/1024/1024 "MB"'
如果文件数量不那么多可以使用
du -m *20130606* | awk 'c+=$1ENDprint c'
这两个命令显示的单位是MB,如果要显示GB可以print c 的c再除以一个1024 参考技术C du -ch*20130606* 这个试试,再不行就du -kc*20130606* 之后最后一个行的sum值转换一下,再在不行就du+awk 参考技术D 不用这么麻烦,需要计算的文件放入到一个单独的目录,就可以直接计算了
目录中所有文件内容的总大小[关闭]
【中文标题】目录中所有文件内容的总大小[关闭]【英文标题】:Total size of the contents of all the files in a directory [closed] 【发布时间】:2010-11-17 12:39:53 【问题描述】:当我使用ls 或du 时,我会得到每个文件占用的磁盘空间量。
如果我打开每个文件并计算字节数,我需要文件和子目录中所有数据的总和。如果我能在不打开每个文件并计数的情况下获得此奖励积分。
【问题讨论】:
ls 实际上显示的是每个文件中的字节数,而不是磁盘空间量。这足以满足您的需求吗?
请注意,du 不能用于回答此问题。它显示了目录在磁盘上占用的磁盘空间量(文件数据加上辅助文件系统元信息的大小)。 du 输出甚至可以小于所有文件的总大小。如果文件系统可以存储压缩在磁盘上的数据或使用硬链接,则可能会发生这种情况。正确答案基于ls 和find。请在此处查看 Nelson 和 bytepan 的答案,或此答案:unix.stackexchange.com/a/471061/152606
【参考方案1】:
如果您想要“表观大小”(即每个文件中的字节数),而不是磁盘上文件占用的大小,请使用 -b 或 --bytes 选项(如果您有 Linux 系统使用 GNU coreutils):
% du -sbh <directory>
【讨论】:
适用于我较新的红帽盒子,不幸的是不适用于我的嵌入式开发盒子。 有没有一种简单的方法可以以人类可读的格式显示“表观大小”?使用du -shb 时(如this answer所建议),-b 设置似乎覆盖了-h 设置。
@MathiasBynens 反转标志的顺序(即 du -sbh du -sh --apparent-size /dir/
@Arkady 我已经在 CentOS 和 Ubuntu 上尝试过您的解决方案,但出现了一个小错误。你想要“du -sbh”。 “-h”标志必须放在最后。【参考方案2】:
使用du -sb:
du -sb DIR
(可选)添加h 选项以获得更加用户友好的输出:
du -sbh DIR
【讨论】:
-b 似乎是 MacOS 的 du 的非法选项 @lynxoid:您可以使用 brew 安装 GNU 版本:brew install coreutils。它将以命令gdu 的形式提供。
不起作用。 ls -> file.gz hardlink-to-file.gz。 stat -c %s file.gz -> 9657212。 stat -c %s hardlink-to-file.gz -> 9657212。 du -sb -> 9661308。这绝对不是内容的总大小,而是目录在磁盘上占用的大小。【参考方案3】:
cd 到目录,然后:
du -sh
ftw!
最初是在这里写的: https://ao.ms/get-the-total-size-of-all-the-files-in-a-directory/
【讨论】:
这很简单而且有效!谢谢。有时,我喜欢添加-L 选项,以便 du 遵循符号链接。
为我工作(在 OS X 上)
这很简单,行不通。它打印目录在磁盘上占用的空间,而不是可以通过打开每个文件并计算字节数来计算的内容的总大小。【参考方案4】:
只是另一种选择:
ls -lAR | grep -v '^d' | awk 'total += $5 END print "Total:", total'
grep -v '^d' 将排除目录。
【讨论】:
完美,还添加了 -a 参数以获取“隐藏文件”(任何以句点开头的文件) 隔离到特定文件类型(在本例中为 PNG)并以 MB 表示以提高可读性:ls -lR | grep '.png$' | awk 'total += $5 END print "Total:", total/1024/1024, "MB"'
这是一个正确的答案。与du 不同,此解决方案真正计算文件中所有数据的总大小,就好像它们被一个一个打开并计算它们的字节一样。但是是的,添加-A 参数也是计算隐藏文件所必需的。【参考方案5】:
stat 的“%s”格式为您提供文件中的实际字节数。
find . -type f |
xargs stat --format=%s |
awk 's+=$1 END print s'
请随意替换您的favourite method for summing numbers。
【讨论】:
最好使用“find . -type f -print0 | xargs -0 ...”来避免某些文件名出现问题(包含空格等)。 是的,好点。如果它不在 bsd 4.2 中,我不记得使用它:-(find -print0 和 xargs -0 需要用于带有空格的文件名。 OS X 想要stat -f %z。
(请注意,stat 适用于稀疏文件,报告文件的大标称大小,而不是像du 报告那样在磁盘上使用的较小块。)
与此处错误使用du 实用程序的许多其他答案不同,此答案是正确的。在这里回答非常相似:unix.stackexchange.com/a/471061/152606。但我也会使用! -type d 而不是-type f 来计算符号链接(符号链接本身的大小(通常是几个字节),而不是它指向的文件的大小)。【参考方案6】:
如果你在嵌入式系统中使用busybox的“du”,你不能用du得到精确的字节,只能得到Kbytes。
BusyBox v1.4.1 (2007-11-30 20:37:49 EST) multi-call binary
Usage: du [-aHLdclsxhmk] [FILE]...
Summarize disk space used for each FILE and/or directory.
Disk space is printed in units of 1024 bytes.
Options:
-a Show sizes of files in addition to directories
-H Follow symbolic links that are FILE command line args
-L Follow all symbolic links encountered
-d N Limit output to directories (and files with -a) of depth < N
-c Output a grand total
-l Count sizes many times if hard linked
-s Display only a total for each argument
-x Skip directories on different filesystems
-h Print sizes in human readable format (e.g., 1K 243M 2G )
-m Print sizes in megabytes
-k Print sizes in kilobytes(default)
【讨论】:
【参考方案7】:创建文件夹时,许多 Linux 文件系统分配 4096 字节来存储有关目录本身的一些元数据。 随着目录的增长,这个空间会增加 4096 字节的倍数。
du 命令(带或不带 -b 选项)计算这个空间,如您所见,输入:
mkdir test && du -b test
对于空目录,您将得到 4096 字节的结果。 所以,如果你把 2 个 10000 字节的文件放在 dir 中,那么 du -sb 给出的总量将是 24096 字节。
如果您仔细阅读问题,这不是所问的。提问者问:
如果我打开每个文件并计算字节数,我会得到文件和子目录中所有数据的总和
在上面的例子中应该是 20000 字节,而不是 24096。
因此,恕我直言,正确的答案可能是 Nelson 答案和 hlovdal 建议的混合,以处理包含空格的文件名:
find . -type f -print0 | xargs -0 stat --format=%s | awk 's+=$1 END print s'
【讨论】:
【参考方案8】:对于 Win32 DOS,您可以:
c:> dir /s c:\directory\you\want
倒数第二行会告诉你文件占用了多少字节。
我知道这会读取所有文件和目录,但在某些情况下会更快。
【讨论】:
【参考方案9】:至少有三种方法可以获得“文件和子目录中所有数据的总和”,以字节为单位,在 Linux/Unix 和 Windows 的 Git Bash 中都可以使用,下面按平均从最快到最慢的顺序列出。供您参考,它们是在一个相当深的文件系统的根目录下执行的(在 Magento 2 Enterprise 安装中,docroot 包含 30,027 个目录中的 71,158 个文件)。
1.
$ time find -type f -printf '%s\n' | awk ' total += $1 ; END print total" bytes" '
748660546 bytes
real 0m0.221s
user 0m0.068s
sys 0m0.160s
2.
$ time echo `find -type f -print0 | xargs -0 stat --format=%s | awk 'total+=$1 END print total'` bytes
748660546 bytes
real 0m0.256s
user 0m0.164s
sys 0m0.196s
3.
$ time echo `find -type f -exec du -bc + | grep -P "\ttotal$" | cut -f1 | awk ' total += $1 ; END print total '` bytes
748660546 bytes
real 0m0.553s
user 0m0.308s
sys 0m0.416s
这两个也可以,但它们依赖于 Windows 版 Git Bash 上不存在的命令:
1.
$ time echo `find -type f -printf "%s + " | dc -e0 -f- -ep` bytes
748660546 bytes
real 0m0.233s
user 0m0.116s
sys 0m0.176s
2.
$ time echo `find -type f -printf '%s\n' | paste -sd+ | bc` bytes
748660546 bytes
real 0m0.242s
user 0m0.104s
sys 0m0.152s
如果您只想要当前目录的总数,请将-maxdepth 1 添加到find。
请注意,某些建议的解决方案不会返回准确的结果,因此我会坚持使用上述解决方案。
$ du -sbh
832M .
$ ls -lR | grep -v '^d' | awk 'total += $5 END print "Total:", total'
Total: 583772525
$ find . -type f | xargs stat --format=%s | awk 's+=$1 END print s'
xargs: unmatched single quote; by default quotes are special to xargs unless you use the -0 option
4390471
$ ls -l| grep -v '^d'| awk 'total = total + $5 END print "Total" , total'
Total 968133
【讨论】:
关于Windows的Git Bash,——如果是Cygwin,dc是bc包的一部分,所以to get dc需要安装bc。【参考方案10】:
du 很方便,但如果您只想计算某些文件的大小(例如,使用按扩展名过滤),find 很有用。另请注意,find 本身可以打印每个文件的大小(以字节为单位)。要计算总大小,我们可以通过以下方式连接dc 命令:
find . -type f -printf "%s + " | dc -e0 -f- -ep
这里find 为dc 生成命令序列,例如123 + 456 + 11 +。
虽然,完成的程序应该像0 123 + 456 + 11 + p(记住后缀符号)。
所以,为了得到完整的程序,我们需要在从标准输入执行序列之前将0放入堆栈,并在执行后打印顶部数字(最后的p命令)。
我们通过dc 选项实现它:
-e0 只是将0 放入堆栈的-e '0' 的快捷方式,
-f- 用于从标准输入读取和执行命令(此处由find 生成),
-ep 用于打印结果 (-e 'p')。
要像 284.06 MiB 这样以 MiB 为单位打印大小,我们可以在第 3 点中使用 -e '2 k 1024 / 1024 / n [ MiB] p'(大多数空格是可选的)。
【讨论】:
【参考方案11】:用途:
$ du -ckx <DIR> | grep total | awk 'print $1'
“-c”为您提供使用命令的“grep total”部分提取的总计数据,并使用 awk 命令提取以千字节为单位的计数。
这里唯一需要注意的是,如果您有一个包含文本“total”的子目录,它也会被吐出。
【讨论】:
【参考方案12】:这可能会有所帮助:
ls -l| grep -v '^d'| awk 'total = total + $5 END print "Total" , total'
上面的命令将对离开目录大小的所有文件求和。
【讨论】:
请注意,此解决方案与 Barun 的 answer 非常相似。但此解决方案不会汇总子目录中的文件。 @ruvim,它也不会对隐藏文件求和。要汇总隐藏文件,必须将-A 选项添加到 ls。以上是关于Linux怎样计算一个目录下一部分文件的总大小的主要内容,如果未能解决你的问题,请参考以下文章