语音合成简介 Text-to-speech
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了语音合成简介 Text-to-speech相关的知识,希望对你有一定的参考价值。
参考技术A 这篇博客的主要内容是对语音合成 (text to speech)的背景知识进行介绍。 希望可以让读者通俗易懂的了解语音合成的工作原理, 并对为了理解state-of-the-art text to speech 的算法做基础。这个简介主要基于这篇论文 “Wavenet: a generative model for raw audio”的附录介绍的。 论文链接如下: https://arxiv.org/pdf/1609.03499.pdf , 以及stanford CS224S的课程, 链接如下 http://web.stanford.edu/class/cs224s/lectures/224s.17.lec14.pdf
语音合成是通过文字人工生成人类声音, 也可以说语音生成是给定一段文字去生成对应的人类读音。 这里声音是一个连续的模拟的信号。而合成过程是通过计算机, 数字信号去模拟。 这里就需要数字信号处理模拟信号信息,详细内容可参考 [1]。
图片1, 就是一个例子用来表示人类声音的信号图。 这里横轴是时间, 纵轴是声音幅度大小。声音有三个重要的指标, 振幅(amplitude) , 周期(period) 和 频率(frequency) 。 振幅指的是波的高低幅度,表示声音的强弱,周期和频率互为倒数的关系, 用来表示两个波之间的时间长度,或者每秒震动的次数。 而声音合成是根据声波的特点, 用数字的方式去生成类似人声的频率和振幅, 即音频的数字化。了解了音频的数字化,也就知道了我们要生成的目标函数。
音频的数字化主要有三个步骤。
取样(sampling) :在音频数字化的过程,采样是指一个固定的频率对音频信号进行采样, 采样的频率越高, 对应的音频数据的保真度就越好。 当然, 数据量越大,需要的内存也就越大。 如果想完全无损采样, 需要使用Nyquist sampling frequency, 就是原音频的频率2倍。
量化 (quantization) : 采样的信号都要进行量化, 把信号的幅度变成有限的离散数值。比如从0 到 1, 只有 四个量化值可以用0, 0.25, 0.5, 0.75的话, 量化就是选择最近的量化值来表示。
编码 (coding ):编码就是把每个数值用二进制的方式表示, 比如上面的例子, 就可以用2bit 二进制表示, 00, 01, 10, 11。 这样的数值用来保存在计算机上。
采样频率和采样量化级数是数字化声音的两个主要指标,直接影响声音的效果。 对于语音合成也是同样, 生成更高的采样频率和更多多的量化级数(比如16 bit), 会产生更真实的声音。 通常有三个采样频率标准
1. 44.1kHz 采样, 用于高品质CD 音乐
2. 22.05kHz 采样, 用于语音通话, 中品质音乐
3 . 11.025kHz 采样, 用于低品质声音。
而量化标准一般有8位字长(256阶)低品质量化 和16位字长(65536阶)高品质量化。
还有一个重要参数就是通道(channel), 一次只采样一个声音波形为单通道, 一次采样多个声音波形就是多通道。
所以在语音合成的时候,产生的数据量是 数据量=采样频率* 量化位数*声道数 , 单位是bit/s。 一般声道数都假设为1.。 采样率和量化位数都是语音合成里的重要指标,也就是设计好的神经网络1秒钟必须生成的数据量 。
文本分析就是把文字转成类似音标的东西。 比如下图就是一个文本分析,用来分析 “PG&E will file schedules on April 20. ” 文本分析主要有四个步骤, 文字的规范化, 语音分析, 还有韵律分析。 下面一一道来。
文本分析首先是要确认单词和句子的结束。 空格会被用来当做隔词符. 句子的结束一般用标点符号来确定, 比如问号和感叹号 (?!), 但是句号有的时候要特别处理。 因为有些单词的缩写也包含句号, 比如 str. "My place on Main Str. is around the corner". 这些特别情况一般都会采取规则(rule)的方式过滤掉。
接下来 是把非文字信息变成对应的文字, 比如句子中里有日期, 电话号码, 或者其他阿拉伯数字和符号。 这里就举个例子, 比如, I was born April 14. 就要变成, I was born April fourteen. 这个过程其实非常繁琐,现实文字中充满了 缩写,比如CS, 拼写错误, 网络用语, tmr --> tomorrow. 解决方式还是主要依靠rule based method, 建立各种各样的判断关系来转变。
语音分析就是把每个单词中的发音单词标出来, 比如Fig. 3 中的P, 就对应p和iy, 作为发音。 这个时候也很容易发现,发音的音标和对应的字母 不是一一对应的关系,反而需要音标去对齐 (allignment)。 这个对齐问题很经典, 可以用很多机器学习的方法去解决, 比如Expectation–maximization algorithm.
韵律分析就是英语里的语音语调, 汉语中的抑扬顿挫。 我们还是以英语为例, 韵律分析主要包含了: 重音 (Accent),边界 (boundaries), 音长 (duration),主频率 (F0).
重音(Accent) 就是指哪个音节发生重一点。 对于一个句子或者一个单词都有重音。 单词的重音一般都会标出来,英语语法里面有学过, 比如banana 这个单词, 第二个音节就是重音。 而对于句子而言,一样有的单词会重音,有的单词会发轻音。 一般有新内容的名词, 动词, 或者形容词会做重音处理。 比如下面的英语句子, surprise 就会被重音了, 而句子的重音点也会落到单词的重音上, 第二个音节rised, 就被重音啦。 英语的重音规则是一套英语语法,读者可以自行百度搜索。
I’m a little sur prised to hear it cha racterized as up beat .
边界 (Boundaries) 就是用来判断声调的边界的。 一般都是一个短语结束后,有个语调的边界。 比如下面的句子, For language, 就有一个边界, 而I 后面也是一个边界.
For language, I , the author of the blog, like Chinese.
音长(Duration) 就是每个音节的发声长度。 这个通俗易懂。 NLP 里可以假定每个音节单词长度相同都是 100ms, 或者根据英语语法, 动词, 形容词之类的去确定。 也可以通过大量的数据集去寻找规律。
主频率 (F0 )就是声音的主频率。 应该说做傅里叶转换后, 值 (magnitude) 最大的那个。 也是人耳听到声音认定的频率。一个成年人的声音主频率在 100-300Hz 之间。 这个值可以用 线性回归来预测, 机器学习的方法预测也可以。一般会认为,人的声音频率是连续变化的,而且一个短语说完频率是下降趋势。
文本分析就介绍完了,这个方向比较偏语言学, 传统上是语言学家的研究方向,但是随着人工智能的兴起,这些feature 已经不用人为设计了,可以用端到端学习的方法来解决。 比如谷歌的文章 TACOTRON: TOWARDS END-TO-END SPEECH SYNTHESIS 就解救了我们。
https://arxiv.org/pdf/1703.10135.pdf
这个部分就比较像我们算法工程师的工作内容了。 在未来的博客里, 会详细介绍如何用Wavenet 和WaveRNN 来实现这一步骤的。 今天这个博客就是简介一下算法。
这里说所谓的waveform synthesis 就是用这些 语言特征值(text features)去生成对应的声波,也就是生成前文所说的采样频率 和 振幅大小(对应的数字信号)。 这里面主要有两个算法。
串接合成(concatenative speech synthesis) : 这个方法呢, 就是把记录下来的音节拼在一起来组成一句话,在通过调整语音语调让它听起来自然些。 比较有名的有双音节拼接(Diphone Synthesis) 和单音节拼接(Unit Selection Synthesis)。这个方法比较繁琐, 需要对音节进行对齐(alignment), 调整音节的长短之类的。
参数合成 (Parametric Synthesis) : 这个方法呢, 需要的内存比较小,是通过统计的方法来生成对应的声音。 模型一般有隐马尔科夫模型 (HMM),还有最近提出的神经网络算法Wavenet, WaveRNN.
对于隐马尔科夫模型的算法, 一般都会生成梅尔频率倒谱系数 (MFCC),这个是声音的特征值。 感兴趣的可以参考这篇博客 去了解 MFCC。
https://www.cnblogs.com/BaroC/p/4283380.html
对于神经网络的算法来说, 一般都是生成256 个 quantized values 基于softmax 的分类器, 对应 声音的 256 个量化值。 WaveRNN 和wavenet 就是用这种方法生成的。
下面是我学习语音合成的一些资料, 其中stanford cs224s 是强力推荐的,但是这个讲义讲的逻辑不是很清楚, 要反复看才会懂。
UCSB Digital Speech Processing Course 课程, 声音信号处理的基础。 建议读一遍, 链接如下, https://www.ece.ucsb.edu/Faculty/Rabiner/ece259/
Stanford CS224S http://web.stanford.edu/class/cs224s/
WaveRNN, https://arxiv.org/pdf/1609.03499.pdf
音频的数字化, https://wenku.baidu.com/view/68fbf1a4f61fb7360b4c658b.html
统计参数语音合成的初学者指南
原文地址链接:https://shartoo.github.io/texttospeech/
译自:A beginners’ guide to statistical parametric speech synthesis
一 语音合成(Text-To-Speech)TTS 概述
TTS系统的输入是文本,输出为语音waveform。TTS一般分为两部分。第一部分将文本转换为语言规范,第二部分使用此规范来生成waveform。这种划分带来的好处是,系统前端基本是语言规范相关的,而waveform生成可以独立于语言。
文本转换为语言规范一般使用序列的分离处理和多种内部中间表征来完成。
本文主要讨论的是使用统计参数方法来合成语音。
二 从声码到合成
关于语音合成的描述一般是以一种程序式的眼光:通常将文本转换为语音转化为简单的pipeline结构。但是,其他方法认为语音合成是从声码器开始的,语音信号被转换为某些可以被传递的表征。声码器如下图
我们可以将语音合成看做类似的架构,但是其中的参数化的语音的传递应该替换为存储。如下图:

后面再解释参数化和生成对应语音waveform。
此系统包含训练和合成两个阶段。训练阶段,存储的form由语音库(训练数据)获得。通过以语言规范索引这些存储的form,可以实现仅以语言规范作为输入,语音waveform为输出的合成系统。
存储的form可以是语音数据本身或者从数据中得到的统计模型。
2.1 语言规范
由上文可知,输入为语言规范。这可以很简单,比如音素序列,但是为了更好的结果,它需要包含超分段信息,比如产生语音的韵律模式。换句话说,语言规范包含了全部的影响声学模型实现的音素。
如何理解语言规范,我们可以以单词speech为例。语言规范需要涵盖可能影响这个原因声音的所有信息。即,它要包含出现此元音的全部上下文信息。此例子中,重要的情景因素包括前面的双边清音爆破(着会影响元音的共振峰轨迹)和此元音位于单音节词内(影响元音的存续时间)等等。
情景自然会包含相同单词相同发音内的因素,比如周围音素,单词和韵律模式,但是可能会拓展到周围发声,并进一步到协同因素如讲话者的心情或者听者的身份。对话语料中,上下文可能需要包含与其他讲话者的因素。实际上,大部分系统只考虑发声内部的因素。下表列出了在典型系统中会考虑的上下文因素:
| 上下文因素 |
|---|
| Preceding and following phonemes |
| Position of segment in syllable |
| Position of syllable in word & phrase |
| Position of word in phrase |
| Stress/accent/length features of current/preceding/following syllables |
| Distance from stressed/accented syllable |
| POS of current/preceding/following word |
| Length of current/preceding/following phrase |
| End tone of phrase |
| Length of utterance measured in syllables/words/phrases |
列出的因素对每个语音声音有潜在的影响。考虑到每个因素可能的取值数量(比如preceding phoneme可能有多达50个不同取值)以及排序的数量,很明显,即便只考虑语言学成立的组合,不同情景的数量巨大。但不是所有因素在所有时刻都有影响。实际上,我们希望少量因素在任意时刻都有显著影响。这可以显著减少情景。关键问题,我们会在第四节再看,它来决定哪个因素在何时比较重要。
对每个将要合成的句子,前端需要做的是从文本预测语言规范。需要任务都需要由前端完成(比如,从拼写来预测发音),这些都是与特定语言相关的。
2.2 基于示例的模型
基于示例的语音合成系统简单的存储语音库,整个语料库或选择的一部分。使用语言规范来索引此类存储的form即给存储的语音数据打标签,使得其合适的部分得以被知晓,在合成阶段抽取、连接即可。 在典型的单元选取系统,打标签包含了对齐语音和韵律信息。恢复过程不是不重要,由于合成时所需的抽取规范在语料中不存在,所以需要在众多轻微的不匹配单元中做出选择。语音应该被存储为waveform或者其他适合拼接的表征形式,比如残差激活的LPC。
2.3 基于模型的系统
基于模型的系统并不存储任何语音。相反,它在训练期间将模型适配语音库,并存储模型。模型将按照独立的语音单元构建,比如情景依赖的音素:这样模型就能被语言规范索引。在合成阶段,合适的情景依赖模型序列被检索到并用来生成语音。由于只有有限数量的训练数据,某些模型的缺失,这可能没法检索到。因而有可能对任意所需语言规范创建on-the-fly(直接使用的)模型。这可以通过在足够多的相似模型间共享参数完成。
2.4 索引存储的form
为了让存储的form,无论是语音或模型,能够被语言规范索引到,有必要为语音语料库中的每个发声产生语言规范。人工标签可以,但是不现实,也太费钱。常见的方法是,使用与合成句子语音时相同的前端,基于文本对应的语音语料库来预测语言规范。这可能与讲话者不是最佳匹配。
然而,一些从自动语音识别方法借鉴过来的基于强制对齐的技术,可以用来提高打标签的准确率,包括自动识别真的停顿位置和一些发音变化。
三 语音合成的统计参数模型
我们谈及基于模型的语音合成时,尤其指从数据中学习模型时,我们通常指的是统计参数模型。模型的参数化是因为它使用参数来描述语音,而不是存储的模板。称为统计是因为使用统计项来描述这些参数(比如,概率密度函数的均值和方差),这些统计项是从训练数据中的参数值分布习得的。
站在历史的角度上看,统计参数语音合成源于HMM在语音识别中的成功。没人可以说HMM就是语音的真实模型。但是其有效的学习算法(EM),模型复杂度控制(parameter tying)的自动方法和高效计算的搜索算法(Viterbi search)使得HMM称为一个非常强力的算法。至于评估模型的性能,语音识别使用的是单词错误率,而在语音合成通过听力测试,这非常依赖于合适的配置。这个配置中两个重要的方面是语音信号的参数化(HMM术语中的模型的观察值)和建模单元的选取。由于建模单元基本是上下文依赖的音素,此选取即将哪些上下文因素考虑在内。下表概述了自动语音识别和语音合成的参数配置的差异:
Comparison of Hidden (Semi) Markov Model configurations for recognition vs. synthesis
| recognition | synthesis | |
|---|---|---|
| observations | spectral envelope represented using around 12 parameters | spectral envelope represented using 40-60 parameters, plus source features |
| modelling unit | triphone, considering preceding and following phoneme | full context, considering preceding two and succeeding two phonemes plus all other context features listed in Table 1 |
| duration model | state self-transitions | explicit parametric model of state duration |
| parameter estimation | Baum-Welch | Baum-Welch, or Trajectory Training |
| decoding | Viterbi search | not usually required |
| generation | not required | Maximum-likelihood parameter generation |
3.1 信号表征
语音信号由在固定帧率(frame rate)的声码器参数集表征。典型的表征可能对每个帧使用40-60个参数来代表频谱包装(envelope),F0(基准频率)的值和5个描述非周期激发的频谱包装的参数。训练模型之前,声码器的编码阶段用来抽取向量,该向量包含了语音信号中的声码参数,5秒的帧率。在合成阶段,整个向量由模型生成,然后用于驱动声码器的输出。
从原理上讲,任何声码器都可以用于基于HMM的语音合成,只需要它能提供的参数足以高质量的重建语音信号并且这些参数可以在训练阶段自动抽取。这可能类似于一个共振峰。然而,由于参数可以被统计建模,一些声码器可以比其他的声码器表现的更好。出现在统计建模中的基本操作是平均训练阶段的声码器参数以及生成的新值(我们可以将其类比于在训练数据中获取的插值和外推法的值)。因此,在这种操作下声码器的参数值必须是表现较好并且不会导致不稳定的值。例如,线谱对可能比现行预测参数更好的表征,因为前者在插值下表现较好,而后者可能会导致不稳定的过滤。
一种流行的广泛应用于HMM合成的声码器是STRAIGHT (Speech Transformation and Representation using Adaptive Interpolation of weiGHTed spectrum)。我们可以说,STRAIGHT可以处理上述所需属性并且在实际应用中表现较好。
3.2 术语
3.2.1 HSMMs而非HMMs
在统计参数合成语音中所使用的模型大部分其实完全不是HMMs。HMM中的持续时间模型(duration model,比如说自转换)相当简单,而且高质量的语音合成需要更好的持续时间模型。一旦加入一个明确的持续时间模型加入到HMM,它不再是一个马尔科夫模型了。模型现在是半马尔科夫–状态之间的转换依然存在,但是每个状态的明确的持续时间模型不是马尔科夫。此时模型为半隐马尔可夫模型(Hidden Semi-Markov Model),或者说是HSMM。不过我们言及HMM语音合成时,一般实际指的是HSMM语音合成。
3.2.2 标签和上下文
前面描述的语言规范是一个复杂的、结构化的表征;它可能包含列表、树、和其他有用于语言学的结构。基于HMM的语音合成即从模型的线性序列中生成语音,其中每个模型对应了一个指定的语言单元类型。 因此,有必要将结构化的语言规范flatten到线性序列的标签。可以通过附加其他所有的语言信息(关于音节结构,韵律等)到语言规范中的音素上,其结果是线性的上下文依赖的音素序列。根据这些全上下文标签,可以挖掘对应的HMMs序列,从这里可以生成语音。
3.2.3 Statics, deltas and delta-deltas
声码器的输出阶段和产生语音仅需要声码器参数。然而,使用HMMs合成听起来自然的语音的关键取决于,不仅是给这些参数的统计分布建模,而且还有建模其变化频率,比如速度,声码器参数即static coefficients(静态系数)以及它们的一阶导数即delta系数。实际上,通过建模加速度(modelling acceleration),可以获得delta-delta系数。
这三种类型的参数被堆叠在一个观察向量中。训练期间,模型学习这些参数的分布。合成阶段,模型生成有合适统计属性的参数的轨迹。
3.3 训练
如语音识别一样,HMMs合成必须在标签数据上训练。标签必须是如上文描述的全上下文标签,它们由2.4节所描述的方法产生。
3.4 合成
合成阶段只给文本作为输入,如下处理。
首先,输入文本被分析并产生全上下文标签的序列。模型的序列对应了此标签序列,然后连接成一个长的状态链。从这个模型,声码器参数使用下文算法生成。最终,生成的声码器参数被用来驱动声码器的输出阶段来产生语音waveform。
从模型中生成参数:最大似然概率被用作从模型中生成观测值序列。首先,我们考虑使用直白的方法来做这个,然后看到这会产生不自然的参数轨迹。然后,再使用实际所使用的方法。注意到参数项被指为模型的输出,而不是模型的参数(高斯分布的均值和方差)。
持续时间:在直白的方法和下文描述的 MLPG算法,其持续时间(比如,由模型的每个状态生成的参数的帧的数目)都是提前决定的,它们是简化的确定状态持续时间分布的均值。
直白方法的参数生成:此方法生成每个状态的最可能的观测值,它只考虑统计参数。最可能的观测值当然是那个状态的高斯均值。因此这个方法生成分段的常量参数轨迹,它会突兀的改变每个状态转换处的值。显然,当用做驱动声码器时,这听起来会不自然。这个问题将由MLPG算法解决。
MLP最大似然参数生成算法:上述方法忽略了自然语音中参数轨迹的非常重要的一个方面。它只考虑了静态(static)参数的统计属性。但是在自然语音中,它不仅是声码器参数以固定方式呈现的绝对值,它还包含了改变值的速度。我们需要将delta系数的统计属性也考虑在内。实际上,我们还可以考虑delta-delta系数的统计属性。下图演示了MLPG算法:
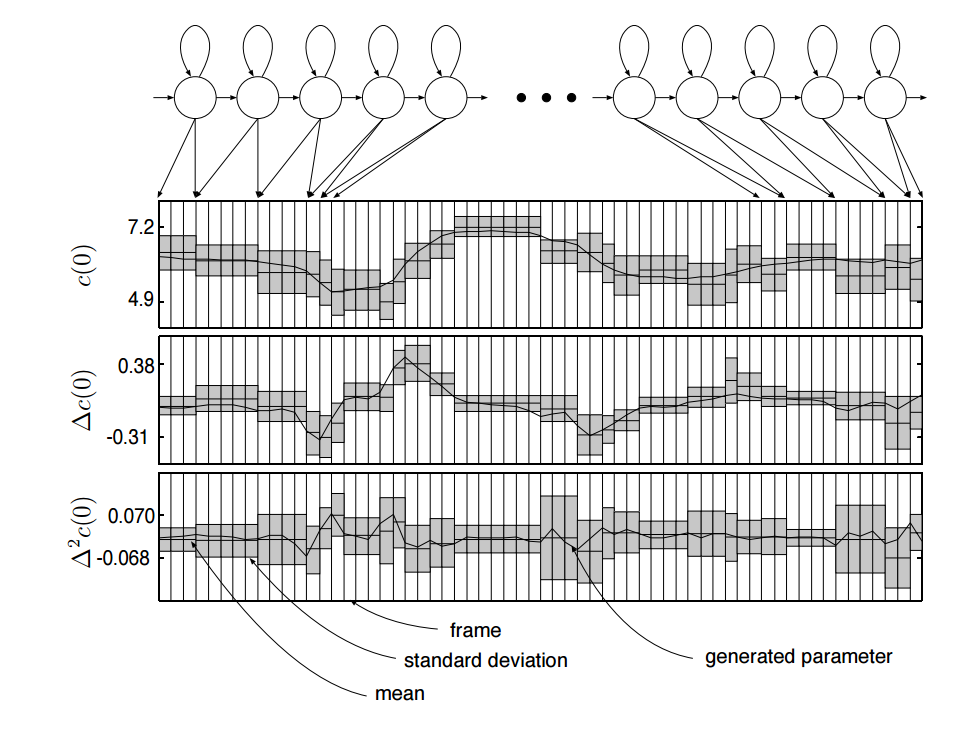
最大似然参数生成:从离散的分布序列,将delta系数和delta-delta系数统计属性考虑在内,来生成平滑的轨迹
HMM已经被构建:是对全上下文标签序列的所对应的模型的拼接,其本身已经被前端工具从文本中预测。在生成参数之前,使用持续时间模型选取了状态序列。这会决定模型中每个状态将会生成多少帧。上图展示了每个状态的一帧一帧的输出分布的序列。MLPG根据静态参数、delta、delta-delta分布找到最大可能的生成的参数的序列。此图只给第0个倒谱系数(c(0)c(0) ),但是对所有由模型生成的参数使用相同的规律,比如F0。
理解MLPG算法生成的东西的最简单的方法是,考虑一个例子:在图中找到一个δc(0)δc(0)为正的区域:静态参数 c(0)c(0)在该点处于上升,它有正的斜率。因此,静态系数的统计属性是分段常量,最可能的参数轨迹是以一种合适的方式平滑变动的。
四 生成新语音:未预见的上下文
生成语音的关键问题在于生成我们没有在自然状态下录制的语音。这就需要从更小单元(从模型拼接或生成)来构建语音。由于我们未曾预见一模一样的上下文环境的此类单元,此问题可以被描述为,从由训练集数据观察到的有限上下文集合泛化为几乎无限的未出现的上下文。
是否语料库够大就可以覆盖所有经常出现的上下文,不幸的是并不是这样。
显而易见的原因是,从表1可以知道有极其丰富的上下文,这会导致两个问题。首先,由于上下文横跨整个语音,语音语料库中每个上下文依赖的单元的出现几乎是唯一的:它只会出现一次(假设不存在重复的句子)。其二,海量的大多数可能的上下文依赖的单元将永不会在语音语料库中出现:语料库对语言只有很稀疏的覆盖。
即便暂时不考虑这种海量的上下文依赖,语料库中任意语言单元(比如,音素,音节,单词)分布远不能正态化。它有低频或0频率的长尾。换句话说,有很多类型的单元将会仅仅出现一次或者完全不在语料库中。此现象即大量稀有事件。尽管每种类型稀少,但是有太多的类型,这会导致还是很可能碰上。对于任意将要合成的语音,有很高的概率需要一些很稀有的单元类型(比如,上下文依赖的音素)。没有有限的语料库可以覆盖我们所需的全部的稀有类型,因此简单的增加语料库于事无补。
我们可以将此问题看做 从有限训练数据中泛化的问题,这就形成了一种模型复杂度控制形式的方法。
4.1 泛化
常用方法,尤其是自然语言,是一个上文提到的长尾分布(类似Zipf分布)。即,数据中少量类型有较多实例,而大量类型仅有很少或者没有实例。这使得直接给稀有或者未观测到的类型建模不可能,因为实例太少无法学到任何东西。这在语音合成中必然会遇到,其中的类型是上下文中的音素。
给数据打标签可以减少类型的数目进而转移这个问题,在语音合成中即减少考虑的情景因素的数目。但是,我们并没有先验知识知道哪些情景因素可以被移除,哪些应该被保留,因为它们对问题中的音素的实现有很大影响。更进一步说,哪些情景因素比较重要是随着复杂的交互结合变化的。
一种较好的解决办法是继续使用大量的类型来给数据打标签并控制模型的复杂度,而不是控制标签的复杂度。 在常见的基于HMM的合成方法的控制模型复杂度的方法是借鉴自自动语音识别,并有关在相似模型中共享(或者tying)参数,以达到:
-
合适的模型复杂度(例如,数据里合适数量的自由参数)
-
对那些仅有较少实例的更好的参数评估
3.对于完全没有的实例的参数评估方法。
为了决定哪些模型足够相似(可用共享参数),再次考虑这些情景因素。由于(我们也这么期望)在任意时刻都只需要考虑少量因素,我们可以专注于一个情景依赖模型的集合,其中每个模型,只需要考虑相关情景。情景依赖的数量可能不同的模型也不一样。结果便是,只有被训练数据所支撑的上下文差异可以被建模。没有影响的上下文因素被丢弃,根据模型的偏差。一个简单示例,想象前音素的identity对于实现[S ]没有显著影响,但是接下来的音素的identity对其有影响。这种情况,模型组可以按照下述方式共享相同参数:对于所有上下文[…aft..],[…Ift…],[…eft..]来说是一个模型,对其他所有上下文如[..afe…],[…ife…],[…efe…]…来说是另外一个模型。
决定不同上下文之间哪些模型可以共享参数的机制是由数据驱动的。模型的复杂度(或者说,有多么多或多么少的参数绑定)是自动选择以适应可用的训练数据的数量的:越多的数据模型越复杂。
4.2 使用参数绑定来控制模型复杂度
模型复杂度控制即给模型选取合适数量的自由参数。在基于HMM的语音合成中,这意味着选取哪种情景分布值得去选取而哪些不重要。换句话说,对于两个不同的 情景,我们何时应该使用独立的模型,合适使用相同的模型。
一种在自动语音识别中广泛应用的模型复杂度控制的技术牵连到相似模型的聚类。情景因素中指定了哪种模型可以聚为一类,并且实际被选取的聚类是那种可以最好的将训练数据和模型拟合的。此方法被基于HMM的语音合成方法采用,这其实在语音识别中更重要,仅仅因为有更多的大量的不同情景需要应对。有一种聚类用的决策树方法(Martin 2009)。
模型被聚类之后,不同模型的数量远远小于不同情景的数量。对于指定数据,聚类过程会自动发现最优的情景差异。训练数据集越大,我们可以使用更多的模型并做出更多精细的差异。
注意:实际上状态绑定和参数绑定是独立的,但是规律是一样的。
4.3 单元选取的关系
在单元选取合成中,情景因素在单元选取上的影响是由目标代价来衡量的。目标损失函数的最常见形式是简单的对每个不匹配的情景因素惩罚项加权求和。目标损失函数旨在在数据库中识别最不差的单元候选。一种可选形式的目标损失称为clunits,使用类似于上文描述的模型聚类方法的情景聚类树,但是树中的叶子节点代表的不是模型参数而是从数据库中获得的语音单元聚类。
目标是一致的:从数据中已知的来泛化出未知的。这是通过自动发现哪些情景在效力上是可互换的达到的。在单元选取中即找到一组足够相似的候选单元来用在不在语音语料库中的目标情景中;在语音合成中意味着将一组情景均值化来训练单一模型。
五常见问题
ASK1: 如何预测韵律
ANS2:这里分两部分。首先,韵律的符号表征是由前端预测的,与拼接合成中类似 。其二,此符号表征用作在生成语音的全情景模型的情景因素的一部分。假设(a)每个韵律有足够的训练样本(b)训练数据的真实韵律和韵律标签有一些一致性,然后每个不同的韵律情景有不同的模型并且在语音合成时模型会 生成合适的韵律。如果(a)或(b)有一个不满足,那么参数聚类将无法形成指定韵律情景模型。
ASK2什么导致了语音合成中的“嗡嗡”的问题
ANS2:因为语音时声码。“嗡嗡”主要源于声源的过度简化的模型。使用混合激发(韵律和非周期性源的混合)的声码而不是在二者之间切换,可以减少“嗡嗡”。
ASK3 什么导致了语音合成中的闷声
ANS3:均值化,这是统计模型的训练过程中不可避免的步骤,可能导致语音听起来闷闷的。多帧语音的均值,每个帧都有轻微不同的频谱属性,这会有拓宽共振峰带宽并减少频谱包装的动态范围的影响。类似的,均值化可能导致过度平滑的频谱包装(envelopes)和过度平滑的轨迹。一种常用的以抵消这种影响的方法是,调整生成的参数使得它们有在自然语音中相同的偏差。此方法称为Global Variance(GV,全局偏差)。
ASK4为什么持续时间要分开建模
ANS4:标准HMM中的持续时间模型源自每个状态的自转移。此模型下,大部分可能的持续时间总是一个状态一帧,在自然状态下显然不对。因而,明确的持续时间模型就很有必要。持续时间模型并不是真的从频谱包络(envelop)和源分离的。它们在模型结构上交互。然而,影响持续时间的情景因素在不同的频谱和源特征下不同,所以这些各种各样的模型参数组是分开聚类的。
以上是关于语音合成简介 Text-to-speech的主要内容,如果未能解决你的问题,请参考以下文章