产品日志我们所谈的 “数据埋点” 到底是什么?
Posted BudingCode
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了产品日志我们所谈的 “数据埋点” 到底是什么?相关的知识,希望对你有一定的参考价值。
在产品规划的过程中,产品经理的工作往往需要使用数据来进行辅助,而我们 获取数据 最快捷的核心途径便是 “埋点”
首先我们来了解埋点的定义,所谓的埋点便是 事件追踪 Event Tracking,也就是针对特定用户行为或事件进行捕获,之后并通过SDK上报埋点的数据,当用户的行为满足某种条件后,比如进入某个界面,点击某个button,会自动触发记录和存储,然后这些数据会被实时或延迟传递到终端服务器,或者通过后端采集用户使用服务过程中的请求数据。
埋点的应用场景
| 埋点的应用场景 | 用户行为分析 | 产品功能分析 | 发短信和PUSH | 精准化推荐 |
|---|---|---|---|---|
| 实例 | 用户的点击、浏览页面停留、试听音频玩游戏、领取优惠券等一系列的行为均要通过数据采集存到数据库里然后对用户进行 漏斗转化行为路径 等分析 | 迭代功能使用情况对比、功能带来的转化统计、产品A/B测试效果 | 精准用户分群发短信 a.如浏览了某个产品详情页次数大于3次但是没有购买转化的用户 b.未购买某个产品的新注册用户 | 通过数据采集上来的用户行为对用户做分群处理并贴上标签,然后精准化推荐首页内容 |
4种采集场景开启埋点之路
| 代码埋点(自定义埋点) | 全埋点 | 可视化埋点 | 服务端埋点 | |
|---|---|---|---|---|
| 采集说明 | 嵌入SDK,定义事件并添加好事件代码 | 嵌入SDK | 嵌入SDK,可视化圈选定义 事件 | 接口调用、数据结构化 |
| 场景 | 以业务为导向通过采集用户定位进行分析 | 无需采集时间,适用于活动页、着陆页、关键页 | 用户在页面的行为与业务信息关联较少,页面较多且页面元素较少对行为数据的分析比较浅 | 前后端数据整合,如订单数据 |
| 优势 | 按需采集,业务信息更完善;对数据分析更聚焦 | 简单、快捷;与代码埋点相比开发人员工作量较少 | 与代码埋点相比,开发人员工作量较少 | 更灵活、更准确、无需发版,数据上传更加及时 |
| 劣势 | 与后两种采集方式相比,开发人员工作量较多 | 嵌数据准确性不高,上传数据多,消耗流量高,数据维度单一(仅点击、加载、刷新) | 业务人员工作量较大、改版后需要重新定义事件、缺乏基于业务的解读 | 仅服务端采集缺少前端的环境信息,前端交互数据缺失 |
| 采集工具 | 友盟、百度统计 | GA | WMDA |
5W2H事件定义搞定埋点方案
5W2H分析法又叫做七何分析法,顾名思义5w就是:why、what、where、when、who,2h就是how、how much。
事件的核心:行为+行为的对象(做+什么)
事件的定义
事件的定义是: 在时间和空间中,信息的变动所产生的增益 – 谁在什么时候做了什么
为什么要以事件的方式进行埋点
- 埋点的目标是要做分析,分析主要包 含:产品功能分析、漏斗分析、用户 分析、留存分析等
- 所有的分析主题都可以拆分到一个一 个的事件
- ev=click_banner,然后count一下uid 就是人数,count一下条数就是次数

四大基础埋点事件
| 基础埋点事件 | 行为+行为对象 |
|---|---|
| 元素点击 | Click_Btn |
| 页面浏览 | View_Page |
| APP激活 | AppInstall |
| APP启动 | AppStart |
事件设计的核心要素
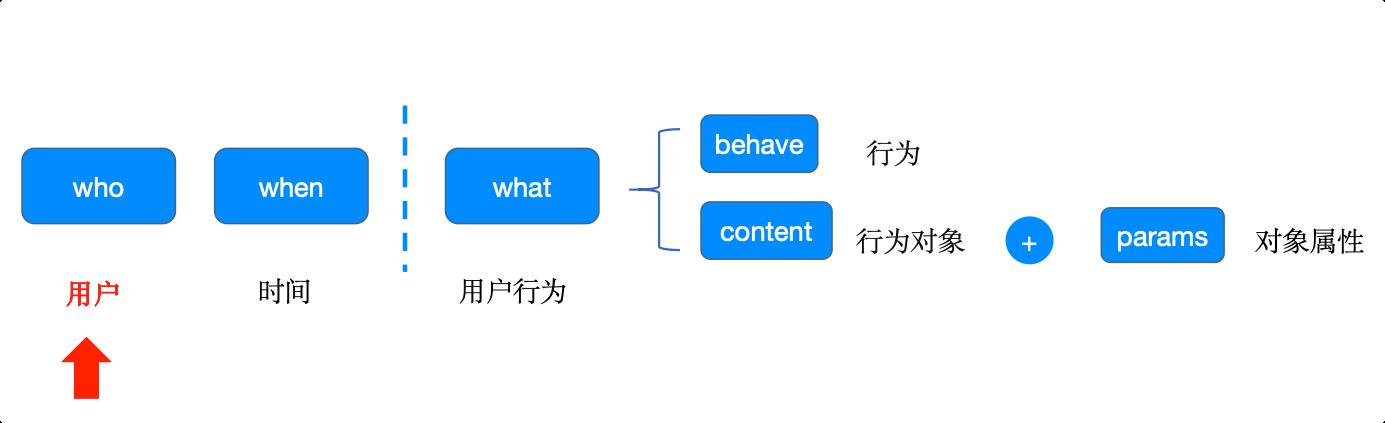
用户属性:基础属性+动态标签
| 基础属性 | 动态标签(用的最多) |
|---|---|
| 年龄 | 是否购买过某个商品 |
| 性别 | 过去7天内的活跃用户 |
| 城市 | 累计消费金额大于1000的用户 |
| 职业 | 每月消费次数大于2次的用户 |
| 年级 | 是否是VIP用户 |
| … | 按事件及事件属性进行标签的标注 |
埋点事件是基于全量用户,用户的动态属性一般做用户细分,而用户属性在后续的数据分析中影响并不大。
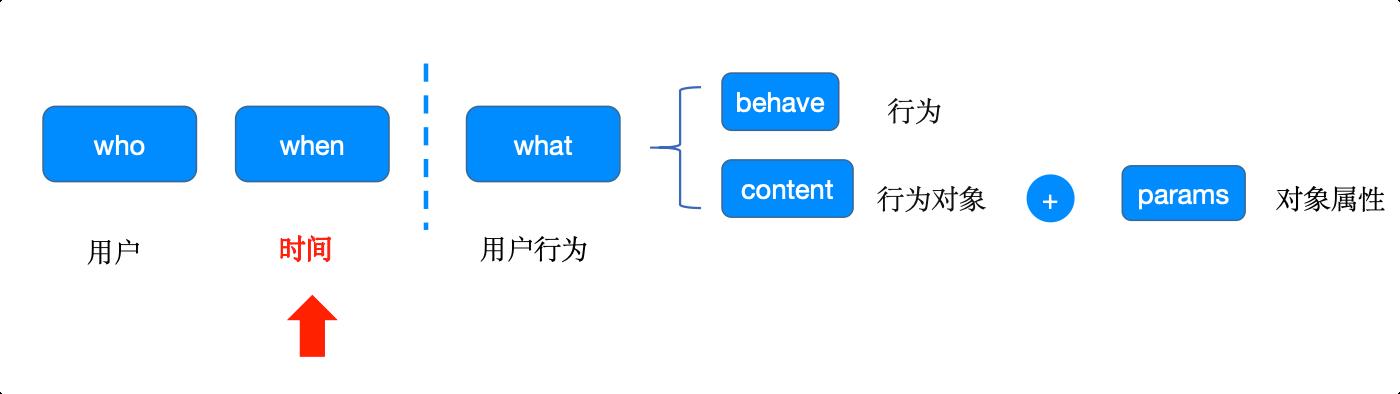
时间:用户行为发生的时间–事件被触发的时间 + 埋点的上报时间
【触发时间】:事件开始记录的时间
【上报时间 】:事件上报到服务器的时间
时间:不同上报时间对页面浏览事件的数据统计有什么影响呢?
1.时间点(可单独作为上报时间)
-
打开页面时间
页面打开即上报,打开后 瞬间关闭的次数也被统计 上了 -
页面加载完成时间
去掉了误点的情况,但加 载成功与失败不管 -
页面关闭时间
页面打开即上报,打开后 瞬间关闭的次数也被统计 上了
2.时间段(需要触发时间+上报时间)
-
页面停留时长
用户打开页面后,在该页面停留 超过3s后触发计时器,在退出页 面时上报 -
区域浏览时长
用户在页面某个区域停留 的累计时长
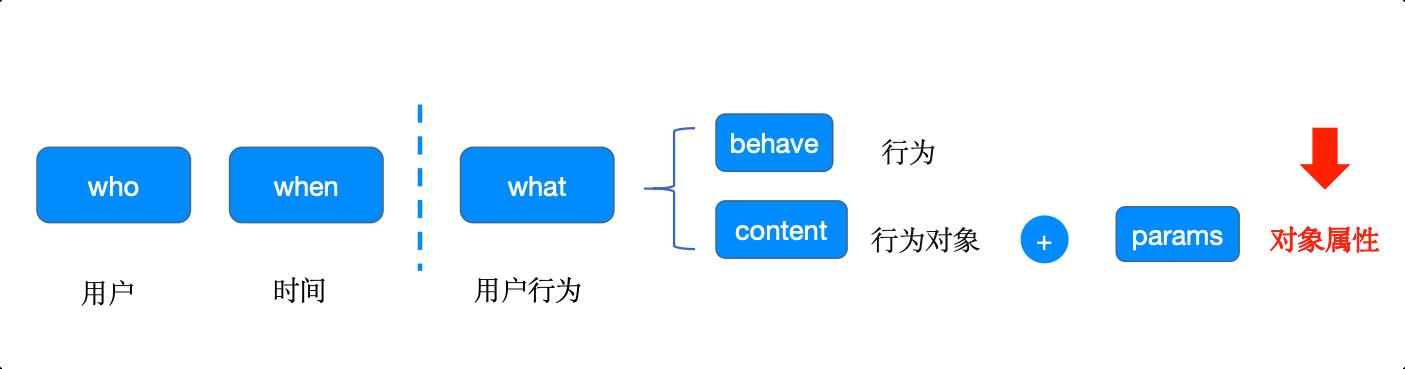
事件分析:【浏览了】+【考研】-【产品详情页】的PV和UV

5大技术利器避开埋点深坑
埋点要理解的数据知识-SDK
SDK是指一种软件开发工具包,是数据采集的必备工具,英文为“Software Development Kit”。本质上它其实是一些接口API的文件集合,为某个应用程序提供服务。也可以理解为应用开发者通过接入这些文件,并调用里面的相关接口,即可采集相应数据。因为SDK的大小一定程度上会影响应用程序性能,所以尽量轻 量处理,占内存大多在几百K和几兆之间。
SDK类型
主要分为客户端SDK、服务端SDK、前端SDK
- 客户端SDK
是指这类SDK接入在应用的终端,比如ios、安卓等 - 服务端SDK
是指接入在后端,更多的在后台底层 - 前端SDK
是指接入在web网页端、H5页面、小程序等
不同类型的业务数据需要分配给不同的开发终端,一般用户浏览点击等流量行为由前端或客户端采集,其余业务数据
由服务端采集,如订单、优惠券领取、听课等客户端采集上报容易出现问题的数据均要通过服务端采集
SDK采集数据的类型
主要分为设备数据、应用数据、埋点数据
- 设备数据
终端硬件设备,如电脑设备、手机设备等, 如果是手机可以具体到手机类型、品牌、网络环境等。如果是电脑,则是电脑型号、浏览器 类型等; - 应用数据
应用程序的数据,比如是APP,则是此APP应用程序内的基础数据,包括APP版本、渠道、安装时间等等 - 埋点数据
用户在某应用程序触发产生的行为数据,比如点击哪个页面、停留时长、页面曝光、启动时间等等。主要是基于业务考虑进行埋点 设计。
埋点要理解的数据知识-ID标识
主要分为两种 用户ID、设备ID
用户ID
在 android 10 版本中,广告渠道商们作为非厂商系统应用将无法获取 IMEI、MAC 等设备信息。旧版本的手机系统在用户手动升级前将保持不变,但是搭载 Android 10 系统的手机系统将不支持获取 IMEI。
在一段时间内,将处于新旧版手机系统共存的状态,但是新版手机系统的用户占比将会逐渐提高,会造成新版系统用户无法进行推广渠道的匹配。 近日移动安全联盟针对该问题联合国内手机厂商推出补充设备标准体系方案,选择 OAID 字段作为 IMEI等的替代字段 。广告渠道商选择 OAID 作为 IMEI 的替代字段。OAID 字段是由中国信通院联合华为、小米、OPPO、VIVO 等厂商共同推出的设备识别字段,具有一定的权威性。 OAID 的准确性和覆盖率均满足广告场景的使用需求。
设备ID
- 在做渠道推广投放时,如果投放的 是APP下载,第三方平台会需要回 调API来评估具体的投放效果,下 载的数量是通过设备ID进行计算的
- 用户在APP上未登录时的行为一部 分也是通过设备ID进行识别,然后 登陆后和内部系统的UID进行映射
埋点要理解的数据知识-大数据架构
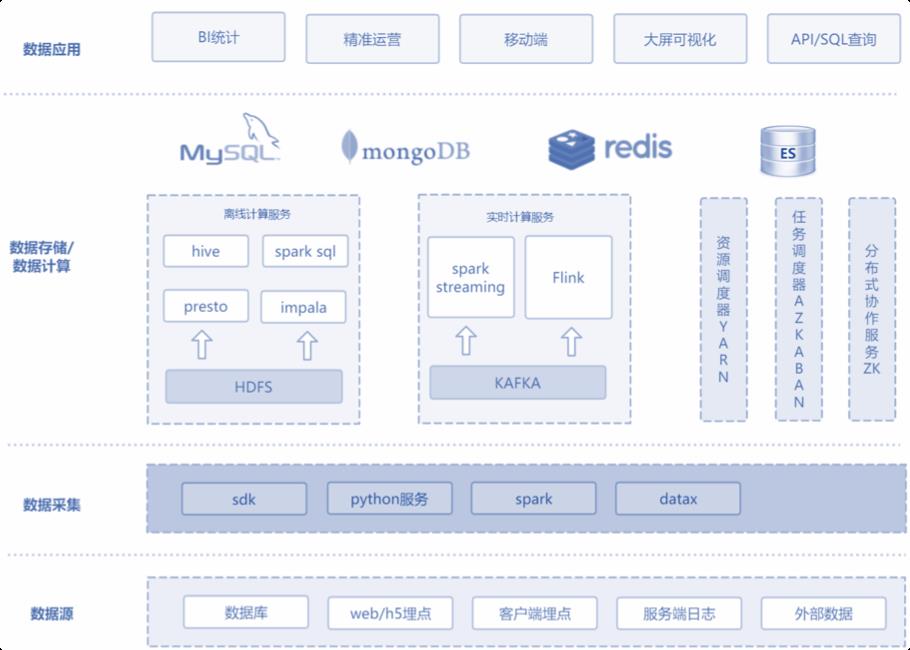
用户的行为日志通过数据处理后最终大部分会落到数仓中去,但 是数仓是T+1的数据更新频率, 如果需要实时的则需要从kafka 消费数据,然后后端通过接口的方式提供给前端
埋点要理解的数据知识-计算引擎
| 计算引擎 | 定义 |
|---|---|
| Hive | 基于Hadoop的数据仓库工具,可以将结构化的数据文件映射 为一张张数据库表,并提供简单的SQL查询功能,可以将SQL 语句转换为MapReduce任务运行。更多支持离线任务 |
| Spark | 一个快速通用的Hadoop数据计算引擎,适用于实时任务。 同时也应用于机器学习、流处理等 |
| Flink | 是最近流行的第4代查询引擎,主要是同时支持流数据和批量式数据处理,相较于Spark有较大的提升。但目前技术相 对新一些,应用得还不算多 |
| Druid | 一种高效实时、迅速的分布式数据查询系统,它采用不是 前3者依赖的hadoop框架。主要支持聚合查询、实时查询, 且灵活。但有些数据分析指标不一定能支持 |
| Impala | 一种数据查询引擎,优点在于高性能、低延迟(准实时)。 相比hive绕过底层MapReduce,所以更快。同时也支持复杂 的交互式查询 |
埋点要理解的数据知识-数据组件
| 计算引擎 | 定义 |
|---|---|
| HDFS | 能够提供高吞吐量的分布式文件系统 |
| YARN | 用于任务调度和集群资源管理。就好比是一个项目的PMO,产品提需求,根据现有的资源、时间、成本等快速分配任 务,调动机器资源来支持 |
| MapReduce | 基于YARN之上,用于大型数据集并行处理的系统。也是初代的计算引擎。Hive就是基于这个系统之上 |
| Flume | 一个日志收集系统,作用在于将大量日志数据从各数据源进行收集、聚合,并最终存储 |
| Sqoop | 用于底层数据传输的工具 |
| Kafka | 一种高吞吐量的分布式消息队列系统 |
| Hbase | 一个可伸缩的分布式数据库,支持大型表的结构化数据存储,底层使用HDFS存储数据 |
| Hive | 基于Hadoop的数据仓库工具,可以将结构化的数据文件映射为一张张数据库表,并提供简单的SQL查询功能,可以将 SQL语句转换为MapReduce任务运行。更多支持离线任务 |
| Spark | 一个快速通用的Hadoop数据计算引擎,适用于实时任务。同时也应用于机器学习、流处理等 |
手把手带你搭建数据埋点平台
什么是数据埋点平台
一切需求可溯源、需求按照规范输入、直接生成埋点文档、埋点数据直接出图、可增加各种分析模型、省时省力、自助式服务、作为平台可进行产品迭代、可提供API接口服务
埋点案例
来自开课吧
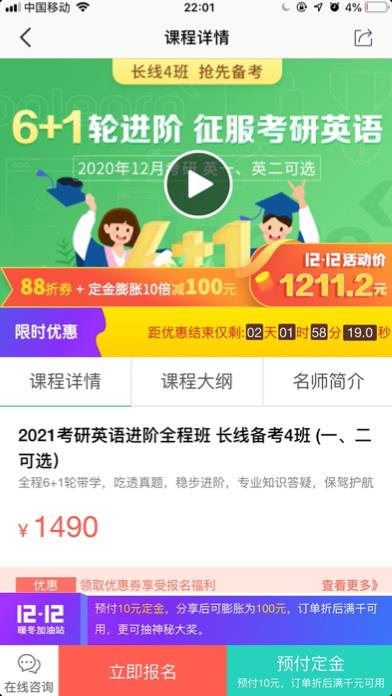
需求:产品上线新功能,需要统计如下指标,请提供埋点文档
- 产品详情页的PV、UV,
- 点击立即报名按钮的PV、UV、
- 购买考研课程的用户数量、购买时间
埋点思路
- 产品详情页的PV、UV(浏览)
- 点击立即报名按钮的PV、UV(点击)
- 购买考研课程的用户数量、购买时间(购买)
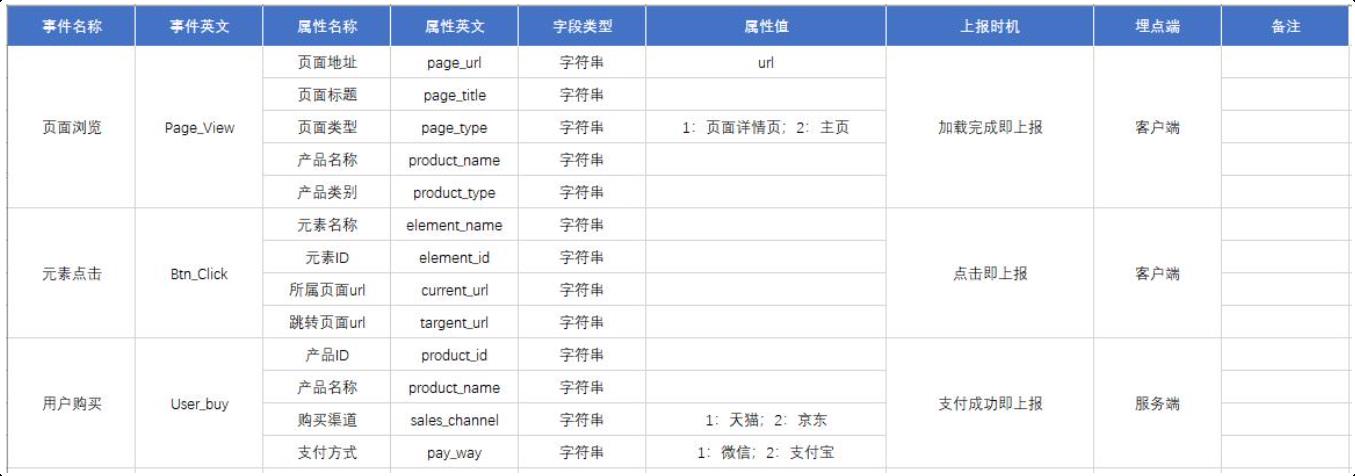
| 事件命名 | 事件属性 | 上报时机 |
|---|---|---|
| Page_View | 页面标题、页面地址、产品名称、产品类别、页面类别 | 加载完成即上报 |
| Btn_Click | 元素名称、元素ID、所属页面url、跳转页面url | 点击即上报 |
| User_Buy | 产品id、产品名称、购买渠道、支付方式等 | 支付成功即上报 |
埋点设计
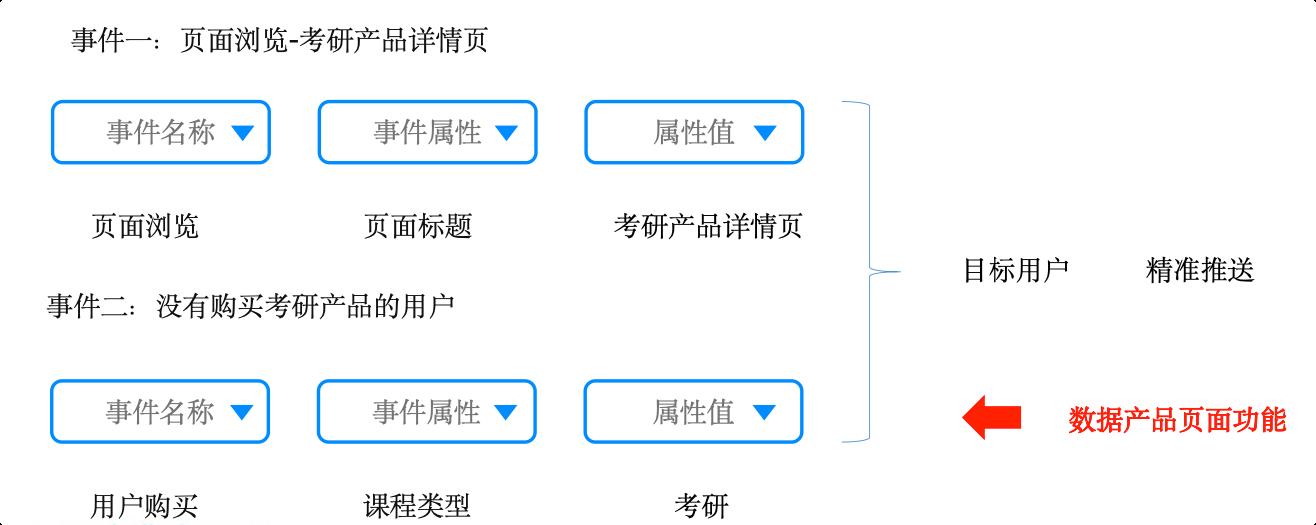
事件分析

目标:浏览过考研详情页且没有购买的用户,发push促进转化
以上是关于产品日志我们所谈的 “数据埋点” 到底是什么?的主要内容,如果未能解决你的问题,请参考以下文章