Redis 存储压缩实战
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis 存储压缩实战相关的知识,希望对你有一定的参考价值。
参考技术Axx的模型分计算,由于客户对响应要求比较高,要求在20ms内就需要返回, 同时QPS要求为60W .
所以存储这一块的选则就是使用的Redis的集群(无主从,更多资源用来存储,同时高可用要求不高)
一开始使用最直接使用了String的Key-Value入库 ; 结果,才入了八亿的数据,内存就去到了140g .对单点分析之后得出对象数量3000w, 数据内存消耗:2.72g,大约一条记录数据大小是97字节,但实际节点占用内存:5.13g . 运维给出来的答复是 :
数据量: 50亿+
数据格式: MD5(imei) :Score1(double),Score2(double)
单条纯数据量: 32字节
首先ZipList是作为Redis的一种底层数据结构, 在一定条件下可作用于HashTable,List,Set的底层实现,
由于其设定是使用一整块的连续内存 (可看似数组结构) ,减少了内存碎片的产生,同时在提供了较高的效率 .
由于ZipList的初始是申请一个连续的长度为zlbytes的内存 , 所以正常情况下对ZipList的修改都会触发内存的重分配, 同时有可能发生数据的复制开销比较大.
这也是ZipList不适合用于存放过大量数据.
以下是HashTable底层使用ZipList的相关配置:
要使用ZipList作为存储结构,所以使用HashTable的时候要将entry的数量控制在ZipList的hash-max-ziplist-entries阈值内 ( 极光这里配置的是256 先不做修改,按这个条件来 )
根据上面的需要将entry数量控制再256以内 , 所以按照50亿的总数量计算的话那么, Redis Key 的KeyNum应该是:
这里的KeyNum根据实际情况可以预估大一点以备数据量增加
通过上一步我们确定了KeyNum的范围 ,那么这一步就要考虑如何将要做的就是找到一个确定的数量使得我们50亿的数据可以均匀的分布再这 KeyNum 个HashTable里
如下图所示,我们的Key是32位的MD5(imei), 为了达到更好的内存合理使用,所以这里考虑将这32位的十六进制拆分成两部分, 一部分作为Redis的Key,一部分作为HashTable的field.
如果 使用六位的 十六进制作为Redis Key那么他的KeyNum为:
2^24 = 16,777,216
同理 七位 :
2^28 = 268,435,456
同理 八位 :
2^32 = 4,294,967,296
与上面 计算出来的 19,531,250比较, 使用七位的十六进制作为Key 的话,那么理论上他的每个HashTable的Entries数量就是大概20个左右. 所以直接选择了7位的十六进制
这里六位的十六进制也可以选择的,只需要将上述的hash-max-ziplist-entries 配置的稍微大一点,但是带来的就是hget的时候会比七位十六进制的慢. 由于没有做过hget差异实验 ,所以就保险的先选择7位.
如下图所示,进行拆分,由于七位的十六进制 只有3.5个字节,所以这里需要补一个十六进制的 \'0\' 凑整4个字节.
为了使切分七位十六进制后的数据更均匀分布,应该对选择的目标七位十六进制进行groupBy,然后看看,数据分布的是不是足够的均匀. 假设,如果有大量MD5(imei) 的前七位都是零,那么就会造成 key为00000000的这个HashTable 过于庞大,而没法使用ZipList . 经过对玖富的数据进行分析,最终选取后七位
1.可以通过减少RedisKey的数量, 达到增加每个HashTable的Entry的数量,达到内存缩减
Redis 内存压缩实战
在讨论Redis内存压缩的时候,我们需要了解一下几个Redis的相关知识。
压缩列表 ziplist
Redis的ziplist是用一段连续的内存来存储列表数据的一个数据结构,它的结构示例如下图

压缩列表组成示例--截图来自《Redis设计与实现》
-
zlbytes: 记录整个压缩列表使用的内存大小
-
zltail: 记录压缩列表表尾距离起始位置有多少字节
-
zllen: 记录压缩列表节点数量,值得注意的一点是,因为它只占了2个字节,所以最大值只能到65535,这意味着压缩列表长度大于65535的时候,就只能通过遍历整个列表来计算长度了
-
zleng: 压缩列表末端标志位,固定值为
OxFF -
entry1-N: 压缩列表节点, 具体结构如下图
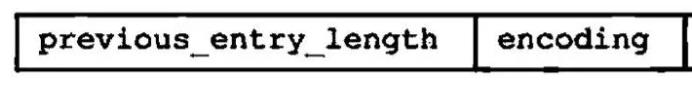
压缩列表节点组成示例--截图来自《Redis设计与实现》
其中
-
previous_entry_length: 上一个节点的长度
-
encoding: content的编码以及长度
-
content: 节点数据
当我们查找一个节点的时候,主要进行一下操作:
-
根据zltail获取最后一个节点的位置
-
判断当前节点是否是目标节点
-
如果是,则返回数据
-
如果不是,则根据previous_entry_length计算上一个节点的起始位置,然后重新进行步骤2判断
通过上述的描述,我们可以知道,ziplist每次数据更新的复杂度大约是O(N),因为它需要对N个节点进行内存重分配,查找一个数据的时候,复杂度是O(N),最坏情况下需要遍历整个列表。
什么情况下会使用到ziplist呢?
Redis会使用到ziplist的数据结构是Hash与List。
Hash结构使用ziplist作为底层存储的两个条件是:
-
所有的键与值的字符串长度都小于64字节的时候
-
键与值对数据小于512个
只要上述条件任何一个不满足,Redis就会自动将这个Hash对象从ziplist转换成hashtable。但这两个阈值可以通过修改配置文件中的hash-max-ziplist-value与hash-max-ziplist-entries来变更。
List结构使用ziplist的条件与Hash结构一样,当条件不满足的时候,会从ziplist转换成linkedlist,同样我们可以修改list-max-ziplist-value与hash-max-ziplist-entries来使用不同的阈值。
为什么Hash与List会使用ziplist来存储数据呢?
因为
-
ziplist会比hashtable与ziplist节省跟多的内存
-
内存中以连续块方式保存的数据比起hashtable与linkedlist使用的链表可以更快的载入缓存中
-
当ziplist的长度比较小的时候,从ziplist读写数据的效率比hashtable或者linkedlist的差异并不大。
本质上,使用ziplist就是以时间换空间的一种优化,但是他的时间损坏小到几乎可以忽略不计,但却能带来可观的内存减少,所以满足条件时,Redis会使用ziplist作为Hash与List的存储结构。
实战
我们先抛出问题,在广告程序化交易的过程中,我们经常需要为一个广告投放计划定制人群包,其存储的形式如下:
人群包ID => [设备ID_1, 设备ID_2 ... 设备ID_N]
其中,人群包ID是Long型整数,设备ID是经过MD5处理,长度为32。在业务场景中,我们需要判断一个设备ID是否在一个人群包中,来决定是否投放广告。另外,Redis 系列面试题和答案全部整理好了,微信搜索Java技术栈,在后台发送:面试,可以在线阅读。
在传统的使用Redis的场景, 我们可以使用标准的KV结构来存储定向包数据,则存储方式如下:
人群包ID_设备ID_1 => true
人群包ID_设备ID_2 => true
如果我们想使用ziplist来继续内存压缩的话,我们必须保证Hash对象的长度小于512,并且键值的长度小于64字节。我们可以将KV结构的数据,存储到预先分配好的bucket中。
我们先预估下,整个Redis集群预计容纳的数据条数为10亿,那么Bucket的数量的计算公式如下:
bucket_count = 10亿 / 512 = 195W
那么我们大概需要200W个Bucket(预估Bucket数量需要多预估一点,以防触发临界值问题) 我们先以下公式计算BucketID:
bucket_id = CRC32(人群包ID + "_" + 设备ID) % 200W
那么数据在Redis的存储结构就变成
bucket_id =>
人群包ID_设备ID_1 => true
人群包ID_设备ID_2 => true
这样我们保证每个bucket中的数据项都小于512,并且长度均小于64字节。
我们以2000W数据进行测试,前后两者的内存使用情况如下:
| 数据集大小 | 存储模式 | Bucket数量 | 所用内存 | 碎片率 | Redis占用的内存 |
|---|---|---|---|---|---|
| 2000W | 压缩列表 | 200W | 928M | 1.38 | 1.25G |
| 2000W | 压缩列表 | 5W | 785M | 1.48 | 1.14G |
| 2000W | 直接存储 | - | 1.44G | 1.03 | 1.48G |
在这里需要额外引入一个概念 – 内存碎片率。
内存碎片率 = 操作系统给Redis分配的内存 / Redis存储对象占用的内存
因为压缩列表在更新节点的时候,经常需要进行内存重分配,所以导致比较高的内存碎片率。我们在做技术方案比较的时候,内存碎片率也是非常需要关注的指标之一。
但有很多手段可以减少内存碎片率,比如内存对其,甚至更极端的直接重做整个Redis内存(利用快照或者从节点来重做内存)都能有效的减低内存碎片率。
我们在本次实验中,因为存储的数值比较大(单个KEY约34个字节),所以实际节省内存不是很多,但依然能节约35%-50%的内存使用。
在实际的生产环境中,我们根据应用场景合理的设计压缩存储结构,部分业务甚至能达到节约70%的内存使用的效果。
压缩列表能节省多少内存?
我们现在知道压缩列表是通过将节点紧凑的排列在内存中,从而节省掉内存的。但他究竟节省了哪些内存从而能达到惊人的压缩率呢?
首先为了明白这个细节,我们需要知道普通Key-Value结构在Redis中是如何存储的。
typedef struct redisObject
unsigned type:4; // 对象的类型
unsigned encoding:4; // 对象的编码
unsigned lru:LRU_BITS; // LRU类型
int refcount; // 引用计数
void *ptr; // 指向底层数据结构的指针
robj;
Redis所有的对象都是通过上述结构来存储, 假设我存储Hello=>World这样一个健值对到Redis中,除了存储本身键值的数据外,还需要额外的24个字节来存储redisObject对象。
而Redis存储字符串使用的SDS数据结构
struct sdshdr8
uint8_t len; // 所保存字符串的长度
uint8_t alloc; // 分配的内存数量
unsigned char flags;// 标志位,用于判断sdshdr类型
char buf[]; // 字节数组,用户保存字符串
;
假如字符串的长度无法用unsigned int8来表示的话,Redis会使用能表达更大长度的sdshdr16结构来存储字符串。
并且,为了减少修改字符串带来的内存重分类问题,Redis会进行内存预分配,所以可能你仅仅为了保存五个字符,但Redis会为你预分配10 bytes的内存。
这意味着当我们存储Hello这个字符串的时候,你需要额外的3个以上的字节。
Oh~~~,我只想保存Hello=>World这十个字符的数据,竟然需要的30~40个字节的数据来存储额外的信息,比存储数据本身的大小还多一些。这还没包括Redis维护字典表所需要的额外的内存空间。
那么假设我们用ziplist来存储这个数据,我们仅仅需要额外的2个字节用于存储previous_entry_length与encoding。具体的计算方式可以参考Redis源码或者《Redis设计与实现》第一部分第7章压缩列表。
总结
从以上对比,我们可以看出,在存储越小的数据的时候,使用ziplist来进行数据压缩能得到更好的压缩率。但副作用也很明显,ziplist的更新效率远远低于普通K-V模式,并且会造成额外的内存碎片率。
在Redis中存储大量数据的实践过程中,我们经常会做一些小技巧来尽可能压榨Redis的存储能力。
以上是关于Redis 存储压缩实战的主要内容,如果未能解决你的问题,请参考以下文章