NGBoost美国斯坦福大学团队算法介绍-作者亲测性能对比LightGBM,XGBoost,catboost
Posted 公众号_python风控模型
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NGBoost美国斯坦福大学团队算法介绍-作者亲测性能对比LightGBM,XGBoost,catboost相关的知识,希望对你有一定的参考价值。
美国斯坦福大学 ML Group最近在他们的论文 Duan et al., 2019 中发表了一种新算法,其实现称为 NGBoost。该算法通过使用自然梯度将不确定性估计包括在梯度提升中。这篇文章试图理解这个新算法,并与其他流行的增强算法 LightGBM 和 XGboost 进行比较,看看它在实践中是如何工作的。
斯坦福ngboost官网如下
https://stanfordmlgroup.github.io/projects/ngboost/

现实世界中的预测不确定性估计
估计机器学习模型预测中的不确定性对于现实世界中的生产部署至关重要。我们不仅希望我们的模型做出准确的预测,而且我们还希望对每个预测的不确定性进行正确的估计。当模型预测是自动化决策工作流程或生产线的一部分时,预测不确定性估计对于确定手动备用方案或人工检查和干预非常重要。
概率预测(或概率预测)是模型在整个结果空间上输出完整概率分布的方法,是量化这些不确定性的自然方法。
比较以下示例中的点预测与概率预测。

NGBoost 为 Gradient Boosting 带来了预测不确定性估计

梯度提升方法通常在结构化或表格输入数据的预测准确性方面表现最佳。
NGBoost 通过概率预测(包括实值输出)使用 Gradient Boosting 实现预测不确定性估计。通过使用自然梯度,NGBoost 克服了通过梯度提升使通用概率预测变得困难的技术挑战。梯度提升方法通常在结构化或表格输入数据的预测准确性方面表现最佳。
NGBoost 通过概率预测(包括实值输出)使用 Gradient Boosting 实现预测不确定性估计。通过使用自然梯度,NGBoost 克服了通过梯度提升使通用概率预测变得困难的技术挑战。
简单和模块化的方法

- 基础模型(学习群)
该算法使用基础(弱)学习器。它需要输入x和输出用于形成条件概率。这些基础学习器使用 scikit-learn 的决策树作为树学习器,使用 Ridge 回归作为线性学习器。
- 参数概率分布
参数概率分布是一种条件分布。这是由基础学习器输出的加法组合形成的。
- 计分规则
评分规则采用预测的概率分布和对目标特征的一次观察来产生预测分数,其中结果的真实分布在预期中获得最佳分数。该算法使用 MLE(最大似然估计)或 CRPS(连续排序概率分数)。
自然梯度使学习高效且有效
什么是自然梯度提升?
正如我在介绍中所写,NGBoost 是一种新的提升算法,它使用自然梯度提升,一种用于概率预测的模块化提升算法。该算法由基学习器、参数概率分布和评分规则组成。
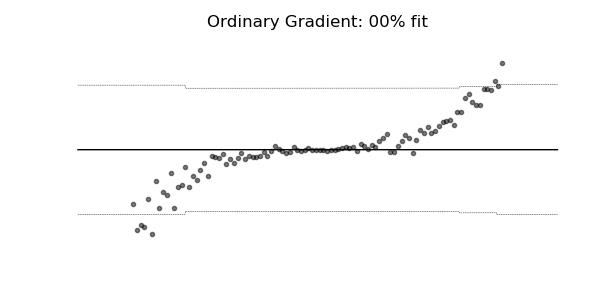
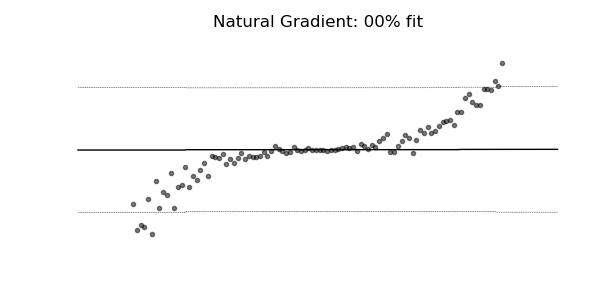
普通梯度可能非常不适合学习多参数概率分布(例如正态分布)。如上面的概率回归示例所示,使用自然梯度的训练动态往往更加稳定并产生更好的拟合。
在不确定性估计和传统指标方面的竞争表现
与竞争方法相比,NGBoost 所需的专业知识要少得多,并且在常见的基准测试中表现同样出色。NGBoost 在较小的数据集上具有特别强的性能。

NGboost——与 LightGBM 和 XGBoost 的比较
让我们实现 NGBoost,看看它的性能如何。原论文还对各种数据集做了一些实验。他们比较了回归问题中的 MC dropout、Deep Ensembles 和 NGBoost,NGBoost 显示出其相当有竞争力的性能。在这篇博文中,我想展示模型在 Kaggle上著名的房价预测数据集上的表现。该数据集由 81 个特征、1460 行组成,目标特征是销售价格。让我们看看 NGBoost 可以处理这些情况。

目标特征分布
由于测试算法的性能是本文的目的,我们将跳过整个特征工程部分并使用 Nanashi 的解决方案。
导入包;
# import packages
import pandas as pd
from ngboost.ngboost import NGBoost
from ngboost.learners import default_tree_learner
from ngboost.distns import Normal
from ngboost.scores import MLE
import lightgbm as lgb
import xgboost as xgb
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from math import sqrt
在这里,我将使用上面的默认学习器、分布和评分规则。玩这些并看看结果如何变化会很有趣。
# read the dataset
df = pd.read_csv(~/train.csv)
# feature engineering
tr, te = Nanashi_solution(df)
现在使用 NGBoost 算法进行预测。
# NGBoost
ngb = NGBoost(Base=default_tree_learner, Dist=Normal, Score=MLE(), natural_gradient=True,verbose=False)
ngboost = ngb.fit(np.asarray(tr.drop([SalePrice],1)), np.asarray(tr.SalePrice))
y_pred_ngb = pd.DataFrame(ngb.predict(te.drop([SalePrice],1)))
对 LightGBM 和 XGBoost 执行相同的操作。
# LightGBM
ltr = lgb.Dataset(tr.drop([SalePrice],1),label=tr[SalePrice])
param =
bagging_freq: 5,
bagging_fraction: 0.6,
bagging_seed: 123,
boost_from_average:false,
boost: gbdt,
feature_fraction: 0.3,
learning_rate: .01,
max_depth: 3,
metric:rmse,
min_data_in_leaf: 128,
min_sum_hessian_in_leaf: 8,
num_leaves: 128,
num_threads: 8,
tree_learner: serial,
objective: regression,
verbosity: -1,
random_state:123,
max_bin: 8,
early_stopping_round:100
lgbm = lgb.train(param,ltr,num_boost_round=10000,valid_sets=[(ltr)],verbose_eval=1000)
y_pred_lgb = lgbm.predict(te.drop([SalePrice],1))
y_pred_lgb = np.where(y_pred>=.25,1,0)
# XGBoost
params = max_depth: 4, eta: 0.01, objective:reg:squarederror, eval_metric:[rmse],booster:gbtree, verbosity:0,sample_type:weighted,max_delta_step:4, subsample:.5, min_child_weight:100,early_stopping_round:50
dtr, dte = xgb.DMatrix(tr.drop([SalePrice],1),label=tr.SalePrice), xgb.DMatrix(te.drop([SalePrice],1),label=te.SalePrice)
num_round = 5000
xgbst = xgb.train(params,dtr,num_round,verbose_eval=500)
y_pred_xgb = xgbst.predict(dte)
现在我们有了所有算法的预测。让我们检查一下准确性。我们将使用与本次 Kaggle 比赛相同的指标 RMSE。
# Check the results
print(RMSE: NGBoost, round(sqrt(mean_squared_error(X_val.SalePrice,y_pred_ngb)),4))
print(RMSE: LGBM, round(sqrt(mean_squared_error(X_val.SalePrice,y_pred_lgbm)),4))
print(RMSE: XGBoost, round(sqrt(mean_squared_error(X_val.SalePrice,y_pred_xgb)),4))
以下是预测结果的摘要。

NGBoost 似乎优于其他著名的增强算法。如果我调整 NBGBoost 的参数,模型性能会更好。
NGBoost 与其他 boosting 算法的最大区别之一是可以返回每个预测的概率分布。这可以通过使用pred_dist函数来可视化。此功能可以显示概率预测的结果。
# see the probability distributions by visualising
Y_dists = ngb.pred_dist(X_val.drop([SalePrice],1))
y_range = np.linspace(min(X_val.SalePrice), max(X_val.SalePrice), 200)
dist_values = Y_dists.pdf(y_range).transpose()
# plot index 0 and 114
idx = 114
plt.plot(y_range,dist_values[idx])
plt.title(f"idx: idx")
plt.tight_layout()
plt.show()

上图是每个预测的概率分布。X 轴显示销售价格的对数值(目标特征)。我们可以观察到索引 0 的概率分布比索引 114 更宽。
四、结论与思考
从这个实验的结果,我们可以得出结论,NGBoost 与其他著名的 boosting 算法一样好。但是,计算时间比其他两种算法要长得多。这可以通过使用二次采样方法来改善。另外我的印象是 NGBoost 包仍在进行中,例如没有提前停止选项,没有显示中间结果的选项,选择基学习器的灵活性(目前我们只能在决策树和 Ridge 回归之间进行选择) ,设置随机状态种子,等等。相信这些点很快就会落实。或者您可以为该项目做出贡献:)
总结
- NGBoost 是一种返回概率分布的新提升算法。
- 自然梯度提升,一种用于概率预测的模块化提升算法。这由基础学习器、参数概率分布和 评分规则组成。
- NGBoost 与其他知名算法相比具有相当的竞争力。
作者亲测NGboost在多算法比较中有优异的表现,可谓kaggle竞赛爱好者又一利器。斯坦福算法团队果然名不虚传。
美国NGboost算法就为大家介绍到这里了,欢迎各位同学了解
<python金融风控评分卡模型和数据分析(加强版)>,学习更多相关知识。

版权声明:文章来自公众号(python风控模型),未经许可,不得抄袭。遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
以上是关于NGBoost美国斯坦福大学团队算法介绍-作者亲测性能对比LightGBM,XGBoost,catboost的主要内容,如果未能解决你的问题,请参考以下文章