#yyds干货盘点# 内鬼消息:串联高频面试问题,值得一看!
Posted 掘金安东尼
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了#yyds干货盘点# 内鬼消息:串联高频面试问题,值得一看!相关的知识,希望对你有一定的参考价值。
前言
开宗明义,本瓜深知汝之痛点:前端面试知识点太杂,卿总为了面试而面试,忘了记,记了又忘,循环往复,为此叫苦不迭。
来,让本瓜带领各位都稍稍回顾一下,自己曾经在学生时代记忆元素周期表的光辉岁月。
氢、氦、锂、铍、硼、碳、氮、氧、氟、氖、钠、镁、铝、硅、磷、硫、氯、氩、钾、钙、钪、钛、钒、铬、猛、铁、钴、镍、铜、锌......
咱当初记这前三十位元素,是死记硬背的吗?答案是否定的,机智的我们用到了 串联记忆法 。
一定是像这样或类似这样去记:
第一周期:氢 氦 ———— 轻嗨:轻轻的打个了招呼:嗨!
第二周期:锂 铍 硼 碳 氮 氧 氟 氖 ———— 你皮捧碳 蛋养福奶:你很皮,手里捧了一把碳。鸡蛋能够滋养福气的奶妈
第三周期:钠 镁 铝 硅 磷 硫 氯 氩 ———— 那美女桂林留绿牙:那美女在桂林留绿色的牙齿
第四周期:钾 钙 钪 钛 钒 铬 猛 铁 钴 镍 铜 锌 ———— 贾盖坑太凡哥 猛铁骨裂痛心:“贾盖”坑了“太凡哥”,导致猛男铁汉骨头碎裂很痛心
串联联想与二元链式联想记忆的方法有相似之处,就是都要通过想象、创造和编故事来帮助我们达到双脑学习和记忆的目的。—— 出处
有木有?本瓜记得尤为清楚,以上串联起来的谐音故事简直可以写出一个狗血剧本了。尤其是“那美女(钠镁铝)”简单三字仿佛就能激起青春期的荷尔蒙。如此,学习能不有兴趣吗?兴趣是最好的老师!想忘掉都难啊!
于是乎,本瓜类比归化,将自己遇到过的高频面试问题运用串联联想法进行了“串联”整理,以期形成系统,与各位同好分享。
上图!

撰文不易✍ 点赞鼓励? 您的反馈? 我的动力?
串联一:从输入URL到页面加载发生了什么?
此题是经典中的经典,可挖掘的点非常之多,亦非常之深。
一图胜万言

- 原创脑图,转载请说明出处
串联知识点:URL解析、DNS查询、TCP握手、HTTP请求、浏览器处理返回报文、页面渲染
串联记忆:共计六步,归并为一句话来记忆:UDTH,处理返回加渲染。
“UDTH” 即URL解析、DNS查询、TCP握手、HTTP请求,
“处理返回加渲染”,即浏览器处理返回报文,和页面渲染。
同时,本瓜倾情在脑图上标注了每个步骤可能考察的知识点“关键词”,真的是个个重点,不容错过!
一、URL 解析
URL(Uniform Resource Locator),统一资源定位符,用于定位互联网上资源,俗称网址。
// 示例引自 wikipedia
hierarchical part
┌───────────────────┴─────────────────────┐
authority path
┌───────────────┴───────────────┐┌───┴────┐
abc://username:password@example.com:123/path/data?key=value&key2=value2#fragid1
└┬┘ └───────┬───────┘ └────┬────┘ └┬┘ └─────────┬─────────┘ └──┬──┘
scheme user information host port query fragment
scheme - 定义因特网服务的类型。常见的协议有 http、https、ftp、file,
其中最常见的类型是 http,而 https 则是进行加密的网络传输。
host - 定义域主机(http 的默认主机是 www)
domain - 定义因特网域名,比如 baidu.com
port - 定义主机上的端口号(http 的默认端口号是 80)
path - 定义服务器上的路径(如果省略,则文档必须位于网站的根目录中)。
filename - 定义文档/资源的名称
query - 即查询参数
fragment - 即 # 后的hash值,一般用来定位到某个位置
更多可见:
URL 编码
一般来说,URL 只能使用英文字母、阿拉伯数字和某些标点符号,不能使用其他文字和符号。此在 URL RFC 已做硬性规定。
这意味着,如果URL中有汉字,就必须编码后使用。但是麻烦的是,RFC 1738没有规定具体的编码方法,而是交给应用程序(浏览器)自己决定。这导致"URL编码"成为了一个混乱的领域。
阮老师早在 2010 年已解释了:关于URL编码- 阮一峰
这里可直接看结论:浏览器对 URL 编码会出现差异从而造成混乱,所以假设我们使用 javascript 预先对 URL 编码,然后再向服务器提交。因为Javascript 的输出总是一致的,这样就保证了服务器得到的数据是格式统一的。
我们常使用到:encodeURI()、encodeURIComponent();前者对整个 URL 进行 utf-8 编码,后者是对 URL 部分进行编码。
本瓜请问:你能清楚的解释 ASCII、Unicode、UTF-8、GBK 含义和关系吗?
也许我们并不太了解我们常见、常用的东西。
类型 | 含义 |
ASCII | 8位一个字节,1个字节表示一个字符.即: 2 ** 8 = 256,所以ASCII码最多只能表示256个字符。 |
Unicode | 俗称万国码,把所有的语言统一到一个编码里.解决了ASCII码的限制以及乱码的问题。unicode码一般是用两个字节表示一个字符,特别生僻的用四个字节表示一个字符。 |
UTF-8 | "可变长的编码方式",如果是英文字符,则采用ASCII编码,占用一个字节。如果是常用汉字,就占用三个字节,如果是生僻的字就占用4~6个字节。 |
GBK | 国内版本,一个中文字符 == 两个字节 英文是一个字节 |
强缓存、协商缓存
言外之音:本瓜起初是将强缓存、协商缓存放在第三步 “HTTP 请求”中,后来了解到:如果命中了强缓存则可不再走DNS解析这步。遂将其归到此处。浏览器强缓存是按照ip还是域名缓存的?
强缓存、协商缓存是必考题。具体流程如下:
- 浏览器在加载资源时,根据请求头的 expires和 cache-control判断是否命中强缓存,是则直接从缓存读取资源,不会发请求到服务器。
- 如果没有命中强缓存,浏览器一定会发送一个请求到服务器,通过Etag和Last-Modified-If验证资源是否命中协商缓存,如果命中,服务器会将这个请求返回(304),告诉浏览器从缓存中读取数据。
- 如果前面两者都没有命中,直接从服务器加载资源。
expires:HTTP/1.0 时期,根据对比本地时间和服务器时间来判断。
cache-control:HTTP/1.1 时期,根据相对时间来判断,如设置max-age,单位为秒。
【ETag、If-None-Match】成对:Etag 是服务器返回给浏览器的,If-None-Match 是浏览器请求服务器的。通过对比二者来判断,它们记录的是:文件生成的唯一标识。
【Last-Modified,If-Modified-Since】成对:Modified-Since 是服务器返回给浏览器的,If-Modified-Since 是浏览器请求服务器的。通过对比二者来判断,它们记录的是:最后修改时间。
注:ETag 的优先级比 Last-Modified 更高。大部分 web 服务器都默认开启协商缓存,而且是同时启用【ETag、If-None-Match】和 【Last-Modified,If-Modified-Since】。
综上,强缓存和协商缓存如果命中,都是从客户端缓存中加载资源,而不是从服务器加载资源数据;不同的是:强缓存不会发请求到服务器,协商缓存会发请求到服务器进行对比判断得出是否命中。
- 借一个流程图,暂未找到真实出处,保留引用说明坑位。

以上还有另一个重点,就是cache-control的值的分类:如“no-cache”、“no-store”、“private”等,需要细扣。此处仅暂列二三、作初步释义。
- no-cache: 跳过当前的强缓存,发送HTTP请求,即直接进入协商缓存阶段。
- no-store:不进行任何形式的缓存。
- private: 这种情况就是只有浏览器能缓存了,中间的代理服务器不能缓存。
更多可见:
二、DNS查询
递归查询
DNS 解析 URL(自右向左) 找到对应的 ip
// 例如:查找www.google.com的IP地址过程(真正的网址是www.google.com.):
// 根域名服务器 -> com顶级域名服务器 -> google.com域名服务器 -> www.google.com对应的ip
. -> .com -> google.com. -> www.google.com.
这是一个递归查询的过程。

关于根域名的更多知识,可见 根域名的知识-阮一峰。
DNS 缓存
请记住:有 DNS 的地方,就有 DNS 缓存。
DNS存在着多级缓存,从距离浏览器的距离排序的话,有以下几种:
1.浏览器缓存 2.系统缓存 3.路由器缓存 4.IPS 服务器缓存 5.根域名服务器缓存 6.顶级域名服务器缓存 7.主域名服务器缓存。
查看缓存:
- 浏览器查看 DNS 缓存:chrome://net-internals/#dns
- win10 系统查看 DNS 缓存:win+R => cmd => ipconfig /displaydns
DNS 负载均衡
DNS负载均衡技术的实现原理是在DNS服务器中为同一个主机名配置多个IP地址,在应答DNS查询时,DNS服务器对每个查询将以DNS文件中主机记录的IP地址按顺序返回不同的解析结果,将客户端的访问引导到不同的机器上去,使得不同的客户端访问不同的服务器,从而达到负载均衡的目的。—— 百科
三、TCP握手
DNS解析返回域名的IP之后,接下来就是浏览器要和该IP建立TCP连接了。
言外之音:TCP 的相关知识在大学基础课程《计算机网络》都有,本瓜内心苦:出来混的迟早是要还的......
TCP/IP 模型:链路层-网络层-传输层-应用层。
与之对应,OSI(开放式系统互联模型)也不能忘。通常认为 OSI 模型的最上面三层(应用层、表示层和会话层)对应 TCP/IP 模型中的应用层。wiki
在 TCP/IP 模型中,像常用的 HTTP/HTTPS/SSH 等协议都在应用层上。

三次握手、四次挥手
所谓三次握手(Three-way Handshake),是指建立一个 TCP 连接时,需要客户端和服务器总共发送3个包。
三次握手就跟早期打电话时的情况一样:1、A:听得到吗?2、B:听得到,你呢?3、A:我也听到了。然后才开始真正对话。
1. 第一次握手(SYN=1, seq=x):
客户端发送一个 TCP 的 SYN 标志位置1的包,指明客户端打算连接的服务器的端口,以及初始序号 X,保存在包头的序列号(Sequence Number)字段里。
发送完毕后,客户端进入 SYN_SEND 状态。
2. 第二次握手(SYN=1, ACK=1, seq=y, ACKnum=x+1):
服务器发回确认包(ACK)应答。即 SYN 标志位和 ACK 标志位均为1。服务器端选择自己 ISN 序列号,放到 Seq 域里,同时将确认序号(Acknowledgement Number)设置为客户的 ISN 加1,即X+1。 发送完毕后,服务器端进入 SYN_RCVD 状态。
3. 第三次握手(ACK=1,ACKnum=y+1)
客户端再次发送确认包(ACK),SYN 标志位为0,ACK 标志位为1,并且把服务器发来 ACK 的序号字段+1,放在确定字段中发送给对方,并且在数据段放写ISN的+1
发送完毕后,客户端进入 ESTABLISHED 状态,当服务器端接收到这个包时,也进入 ESTABLISHED 状态,TCP 握手结束。
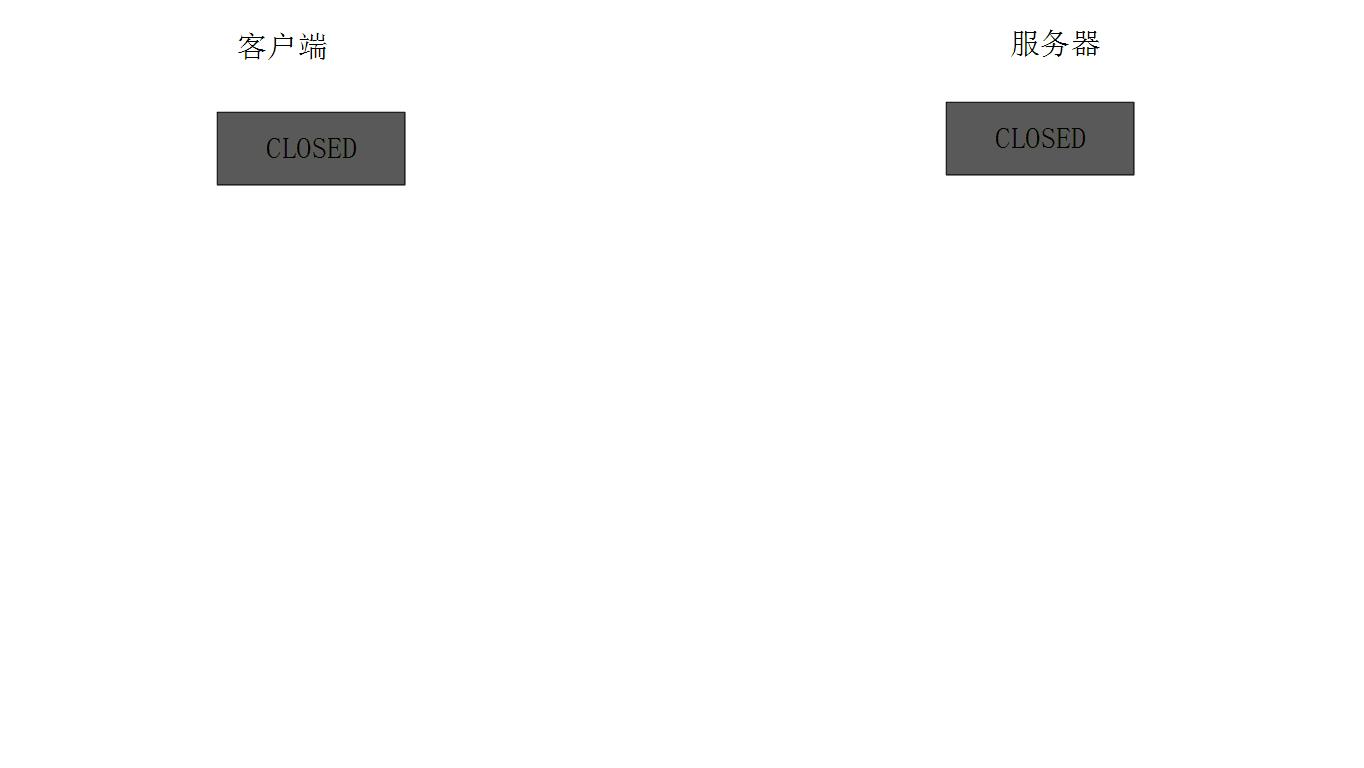
所谓四次挥手(Four-way handshake),是指 TCP 的连接的拆除需要发送四个包。
四次挥手像老师拖堂的场景:1、学生说:老师,下课了。2、老师:好,我知道了,我说完这点。3、老师:好了,说完了,下课吧。4、学生:谢谢老师,老师再见。
1. 第一次挥手(FIN=1,seq=x)
假设客户端想要关闭连接,客户端发送一个 FIN 标志位置为1的包,表示自己已经没有数据可以发送了,但是仍然可以接受数据。
发送完毕后,客户端进入 FIN_WAIT_1 状态。
2. 第二次挥手(ACK=1,ACKnum=x+1)
服务器端确认客户端的 FIN 包,发送一个确认包,表明自己接受到了客户端关闭连接的请求,但还没有准备好关闭连接。
发送完毕后,服务器端进入 CLOSE_WAIT 状态,客户端接收到这个确认包之后,进入 FIN_WAIT_2 状态,等待服务器端关闭连接。
3. 第三次挥手(FIN=1,seq=y)
服务器端准备好关闭连接时,向客户端发送结束连接请求,FIN 置为1。
发送完毕后,服务器端进入 LAST_ACK 状态,等待来自客户端的最后一个ACK。
4. 第四次挥手(ACK=1,ACKnum=y+1)
客户端接收到来自服务器端的关闭请求,发送一个确认包,并进入 TIME_WAIT状态,等待可能出现的要求重传的 ACK 包。
服务器端接收到这个确认包之后,关闭连接,进入 CLOSED 状态。
客户端等待了某个固定时间(两个最大段生命周期,2MSL,2 Maximum Segment Lifetime)之后,没有收到服务器端的 ACK ,认为服务器端已经正常关闭连接,于是自己也关闭连接,进入 CLOSED 状态。
你若问我:三次握手、四次挥手的详细内容太难记了,还记不记?本瓜答:进大厂是必要的。
流量控制(滑动窗口)
为了增加网络的吞吐量,想将数据包一起发送过去,实现“流量控制”,这时候便产生了“滑动窗口”这种协议。
滑动窗口允许发送方在收到接收方的确认之前发送多个数据段。窗口大小决定了在收到目的地确认之前,一次可以传送的数据段的最大数目。窗口大小越大,主机一次可以传输的数据段就越多。当主机传输窗口大小数目的数据段后,就必须等收到确认,才可以再传下面的数据段。
窗口的大小在通信双方连接期间是可变的,通信双方可以通过协商动态地修改窗口大小。改变窗口大小的唯一根据,就是接收端缓冲区的大小。
拥塞控制
需求>供给 就会产生拥塞
通过“拥塞窗口”、“慢启动”、“快速重传”、“快速恢复”动态解决。
TCP 使用多种拥塞控制策略来避免雪崩式拥塞。TCP会为每条连接维护一个“拥塞窗口”来限制可能在端对端间传输的未确认分组总数量。这类似 TCP 流量控制机制中使用的滑动窗口。TCP在一个连接初始化或超时后使用一种“慢启动”机制来增加拥塞窗口的大小。它的起始值一般为最大分段大小(Maximum segment size,MSS)的两倍,虽然名为“慢启动”,初始值也相当低,但其增长极快:当每个分段得到确认时,拥塞窗口会增加一个MSS,使得在每次往返时间(round-trip time,RTT)内拥塞窗口能高效地双倍增长。—— TCP拥塞控制-wikipedia
滑动窗口(流量控制)和拥塞控制里的原理性的东西太多,本瓜表示无力,暂时要求尽力去理解去记忆。
四、HTTP请求
HTTP是万维网的数据通信的基础 —— 维基百科
HTTP请求报文是由三部分组成: 请求行, 请求报头和请求正文。
HTTP响应报文也是由三部分组成: 状态码, 响应报头和响应报文。
HTTP、HTTPS
HTTP 和 HTTPS 的区别?
HTTP报文是包裹在TCP报文中发送的,服务器端收到TCP报文时会解包提取出HTTP报文。但是这个过程中存在一定的风险,HTTP报文是明文,如果中间被截取的话会存在一些信息泄露的风险。
如果在进入TCP报文之前对HTTP做一次加密就可以解决这个问题了。HTTPS协议的本质就是HTTP + SSL(or TLS)。在HTTP报文进入TCP报文之前,先使用SSL对HTTP报文进行加密。从网络的层级结构看它位于HTTP协议与TCP协议之间。

HTTP2
http2 是完全兼容 http/1.x 的,并在此基础上添加了 4 个主要新特性:
- 二进制分帧:http/1.x 是一个文本协议,而 http2 是一个二进制协议。
- 头部压缩:http/1.x 中请求头基本不变,http2 中提出了一个 HPACK 的压缩方式,用于减少 http header 在每次请求中消耗的流量。
- 服务端推送:服务端主动向客户端推送数据。
- 多路复用:http/1.x,每个 http 请求都会建立一个 TCP 连接;http2,所有的请求都会共用一个TCP连接。
更多了解,可见 HTTP2 详解
GET、POST
直观区别:
- GET 用来获取数据,POST 用来提交数据。
- GET 参数有长度限制(受限于url长度,具体的数值取决于浏览器和服务器的限制,最长2M),而 POST 无限制。
- GET 请求的数据会附加在 URL 上,以"?"分割,多个参数用"&"连接,而 POST 请求会把请求的数据放在 HTTP 请求体中。都可被抓包。
- GET 请求会保存在浏览器历史记录中,还可能保存在 WEB 服务器的日志中。
隐藏区别(存在浏览器差异):
- GET 产生一个 TCP 数据包;POST 产生两个 TCP 数据包。
更多了解:
Keep-Alive
我们都知道使用 Keep-Alive 是为了避免重新建立连接。
目前大部分浏览器都是用 http1.1 协议,默认都会发起 Keep-Alive 的连接请求了,所以是否能完成一个完整的 Keep-Alive 连接就看服务器设置情况。
HTTP 长连接不可能一直保持,它有两个参数,例如 Keep-Alive: timeout=5, max=100,表示这个TCP通道可以保持5秒,max=100,表示这个长连接最多接收100次请求就断开。
Keep-Alive 模式发送数据 HTTP 服务器不会自动断开连接,所有不能使用返回EOF(-1)来判断。
基于此,抛问题:当 HTTP 采用 keepalive 模式,当客户端向服务器发生请求之后,客户端如何判断服务器的数据已经发生完成?
- 使用消息首部字段 Conent-Length:Conent-Length表示实体内容长度,客户端可以根据这个值来判断数据是否接收完成。
- 使用消息首部字段 Transfer-Encoding:如果是动态页面,服务器不可能预先知道内容大小,这时就可以使用Transfer-Encoding:chunk 模式来传输数据了。即如果要一边产生数据,一边发给客户端,服务器就需要使用"Transfer-Encoding: chunked"这样的方式来代替Content-Length。chunked 编码的数据在最后有一个空 chunked 块,表明本次传输数据结束
本瓜之前面试腾讯 PCG 就被问到 Transfer-Encoding:chunk 这个,请大家格外注意。
参考:
五、浏览器处理返回报文
状态码
1xx:指示信息–表示请求已接收,继续处理。
2xx:成功–表示请求已被成功接收、理解、接受。
3xx:重定向–要完成请求必须进行更进一步的操作。
4xx:客户端错误–请求有语法错误或请求无法实现。
5xx:服务器端错误–服务器未能实现合法的请求。
平时遇到比较常见的状态码有:200, 204, 301, 302, 304, 400, 401, 403, 404, 422, 500。
切分返回头和返回体(腾讯 PCG 考点)
这里的考点其实和 http keep-alive 中的问题重合,但是还是想着重强调,因为本瓜掉过这个坑,再三点出,以示后人。
最终归为这个问题:Detect end of HTTP request body - stackoverflow
解答:
1. If the client sends a message with Transfer-Encoding: Chunked, you will need to parse the somewhat complicated chunked transfer encoding syntax. You don not really have much choice in the matter -- if the client is sending in this format, you have to receive it. When the client is using this approach, you can detect the end of the body by a chunk with a length of 0.
2. If the client instead sends a Content-Length, you must use that.
即:如何获取 HTTP 返回体?
- 先把 header 直到 \\r\\n\\r\\n(两个换行)整个读取,即整个请求头;
- 如果返回 Transfer-Encoding: Chunked,则读取,直到遇到空 chunked 块,则结束。
- 如果返回 Content-Length,则读从请求头的末尾开始计算 Content-Length 长度的字节。
- 其他情况,等待返回。
本地数据存储
- cookie:4K,可以手动设置失效期。
- localStorage:5M,除非手动清除,否则一直存在。
- sessionStorage:5M,不可以跨标签访问,页面关闭就清理。
- indexedDB:浏览器端数据库,无限容量,除非手动清除,否则一直存在。
- Web SQL:关系数据库,通过SQL语句访问(已经被抛弃)。
浏览器缓存位置
按优先级从高到低:
- Service Worker:本质是一个web worker,是独立于网页运行的脚本。
- Memory Cache:Memory Cache指的是内存缓存,从效率上讲它是最快的。
- Disk Cache:Disk Cache就是存储在磁盘中的缓存,从存取效率上讲是比内存缓存慢的,但是他的优势在于存储容量和存储时长。
- Push Cache:即推送缓存,是 HTTP/2 的内容。
更多:
离线缓存:
<html lang="en" manifest="offline.appcache">
HTML5-离线缓存(Application Cache)
注:“浏览器缓存位置”和“离线缓存”了解相关,有个概念/印象即可。
六、页面渲染
CssTree+DomTree
本瓜知道你知道过程是这样的:
dom tree + css tree = render tree => layout =>painting?
但是你真的吃透了吗?
HTML → DOM树 转化过程:
- 解码:浏览器从磁盘或网络读取HTML的原始字节,然后根据指定的文件编码格式(例如 UTF-8)将其转换为相应字符
- 令牌化:浏览器把字符转化成W3C HTML5 标准指定的各种确切的令牌,比如""、""以及其他在尖括号内的字符串。每个令牌都有特殊的含义以及它自己的一套规则
- 词法分析:生成的令牌转化为对象,这个对象定义了它们的属性及规则
- DOM树构建:最后,由于HTML标记定义了不同标签之间的关系(某些标签嵌套在其他标签中),创建的对象在树状的数据结构中互相链接,树状数据结构也捕获了原始标签定义的父子关系:HTML对象是body对象的父对象,body是p对象的父对象等等

CSS → CSSOM树 转化过程类同以上
CSSOM只输出包含有样式的节点,最终输出为: 
Render Tree (生成渲染树,计算可见节点和样式)
- 不包括Header 、 script 、meta 等不可见的节点
- 某些通过 CSS 隐藏的节点在渲染树中也会被忽略,比如应用了 display:none 规则的节点,而visibility: hidden只是视觉不可见,仍占据空间,不会被忽略。
layout:依照盒子模型,计算出每个节点在屏幕中的位置及尺寸
painting:按照算出来的规则,通过显卡,把内容画到屏幕上。
回流、重绘
回流:
当可见节点位置及尺寸发生变化时会发生回流
重绘:
改变某个元素的背景色、文字颜色、边框颜色等等不影响它周围或内部布局的属性时,屏幕的一部分要重画,但是元素的几何尺寸没有变。
这里本瓜再抛两个问题。
Q1:浏览器在什么时候向服务器发送获取css、js外部文件的请求?
A1:解析DOM时碰到外部链接,如果还有connection,则立刻触发下载请求。
Q2:CSSOM DOM JavaScript 三者阻塞关系?
A2:CSSOM DOM互不影响,JavaScript会阻塞DOM树的构建但JS前的HTML可以正常解析成DOM树,CSSOM的构建会阻塞JavaScript的执行。对此句存疑?
- css 加载的阻塞情况:
- css加载不会阻塞DOM树的解析
// DOM解析和CSS解析是两个并行的进程,所以这也解释了为什么CSS加载不会阻塞DOM的解析。
- css加载会阻塞DOM树的渲染
// 由于Render Tree是依赖于DOM Tree和CSSOM Tree的,所以他必须等待到CSSOM Tree构建完成,也就是CSS资源加载完成(或者CSS资源加载失败)后,才能开始渲染。因此,CSS加载是会阻塞Dom的渲染的。
- css加载会阻塞后面js语句的执行
// 由于js可能会操作之前的Dom节点和css样式,因此浏览器会维持html中css和js的顺序。因此,样式表会在后面的js执行前先加载执行完毕。所以css会阻塞后面js的执行。
参考阅读:
综合补充
web 性能优化
串联二:老生常谈,请你谈一下闭包?
假若你认为此题简单,一两句话就能说完?那当真浮于表面。此题实则一两天都说不完!它可以牵扯出 js 原理的大部分知识。是真正意义上的“母题”。
一图胜万言

- 原创脑图,转载请说明出处
串联知识点:闭包、作用域、原型链、js继承。
串联记忆:此题并非像上文题“从输入URL到页面加载发生了什么?”,后者“串联点”是按解答步骤来递进的。而这里的“串联点”,更多是你中有我,我中有你,前后互相补充,互相完善。当你领略完的时候,一定会有一种“万物归宗”的感觉。
归并为一五言诗来记忆:
闭包作用域
原型多考虑
继承八大法
基础好好叙
一、闭包
闭包含义
一言以蔽之。
在一个函数内有另外一个函数可以访问它的内部变量,并且另外一个函数在外部被调用,这样的词法环境叫闭包。
- 作用:
- 读取函数内部的变量;(私有变量、不污染全局)
- 让变量始终保存在内存中。
闭包应用
- 最经典试题
for(var i = 0; i < 5; i++)
(function(j)
setTimeout(function()
console.log(j);
,1000);
)(i);
console.log(i);
垃圾回收机制
- js 垃圾回收机制:标记清除和引用计数。
标记清除简单讲就是变量存储在内存中,当变量进入执行环境的时候,垃圾回收器会给它加上标记,这个变量离开执行环境,将其标记为“清除”,不可追踪,不被其他对象引用,或者是两个对象互相引用,不被第三个对象引用,然后由垃圾回收器收回,释放内存空间。
防抖、节流函数
- 防抖
function debounce(fn, delay)
var timer; // 维护一个 timer
return function ()
var _this = this; // 取debounce执行作用域的this
var args = arguments;
if (timer)
clearTimeout(timer);
timer = setTimeout(function ()
fn.apply(_this, args); // 用apply指向调用debounce的对象,相当于_this.fn(args);
, delay);
;
- 节流
function throttle(fn, delay)
var timer;
return function ()
var _this = this;
var args = arguments;
if (timer)
return;
timer = setTimeout(function ()
fn.apply(_this, args);
timer = null; // 在delay后执行完fn之后清空timer,此时timer为假,throttle触发可以进入计时器
, delay)
二、作用域
全局作用域
- 直接编写在script标签中的JS代码,都在全局作用域;
- 全局作用域在页面打开时创建,在页面关闭时销毁;
- 在全局作用域中有一个全局对象window,它代表的是一个浏览器的窗口,它由浏览器创建我们可以直接使用;
- 全局作用域中,创建变量都会作为window对象的属性保存;
- 创建的函数都会作为window对象的方法保存;
- 全局作用域中的变量都是全局变量,在页面的任何部分都可以访问的到;
我们可以在控制台直接打印试试看,正如以上所说: 
函数作用域(局部作用域)
- 变量在函数内声明,变量属于局部作用域。
- 局部变量:只能在函数内部访问。
- 局部变量只作用于函数内,所以不同的函数可以使用相同名称的变量。
- 局部变量在函数开始执行时创建,函数执行完后局部变量会自动销毁。
块级作用域
块级作用域 : 块级作用域指的就是使用 if () ; while ( ) ......这些语句所形成的语句块 , 并且其中变量必须使用 let 或 const 声明,保证了外部不可以访问语句块中的变量。
注:函数作用域和块级作用域没有直接关系。
- const、let、var 区别
- const 声明则不能改变,块级作用域,不允许变量提升。
- let 块级作用域,不允许变量提升。
- var 非块级作用域,允许变量提升。
作用域链
出现函数嵌套函数,则就会出现作用域链 scope chain。
- 遍历嵌套作用域链的规则很简单:引擎从当前的执行作用域开始查找变量,如果找不到, 就向上一级继续查找。当抵达最外层的全局作用域时,无论找到还是没找到,查找过程都会停止。
- 局部作用域(如函数作用域)可以访问到全局作用域中的变量和方法,而全局作用域不能访问局部作用域的变量和方法。
用作用域链来解释闭包:
function outter()
var private= "I am private";
function show()
console.log(private);
// [[scope]]已经确定:[outter上下文的变量对象,全局上下文变量对象]
return show;
var ref = outter();
console.log(private); // outter执行完以后,private不会被销毁,并且只能被show方法所访问,
//直接访问它会出现报错:private is not defined
ref(); // 打印I am private
其实,我们要明白的是函数的声明和调用是分开的,如果不搞清楚这一点,很多基础面试题就容易出错。
- 深究:
JavaScript深入之词法作用域和动态作用域 #3
变量生命周期
一个变量的声明意味着就是我们在内存当中申请了一个空间用来存储。这个内存也就是我们电脑的运行内存,如果我们一直的声明变量,不释放的话。会占用很大的内存。
在 c/c++ 当中是需要程序员在合适的地方手动的去释放变量内存,而 javascript 和 java 拥有垃圾回收机制(咱们在上文已说明)。
js 变量分为两种类型:全局变量和局部变量
- 全局变量的生命周期:从程序开始执行创建,到整个页面关闭时,变量收回。
- 局部变量的生命周期:从函数开始调用开始,一直到函数调用结束。
但有的时候我们需要让局部变量的生命周期长一点,此时就用到了闭包。
三、原型链
实例与原型
一个原型对象的隐形属性指向构造它的构造函数的显示属性。
当一个对象去查找它的属性,找不到就去找他的构造函数的属性,一直向上找,直到找到 Object()。
判断数据类型
- typeof
- instanceof
- constructor
- Object.prototype.toString.call()
new 一个对象
步骤:
- 创建一个新对象
- 将构造函数的作用域赋给新对象(因此this指向了这个新对象)
- 执行构造函数中的代码(为这个新对象添加属性)
- 返回新对象
this 指向
this 指向 5 大规则:
- 如果 new 关键词出现在被调用函数的前面,那么JavaScript引擎会创建一个新的对象,被调用函数中的this指向的就是这个新创建的函数。
- 如果通过apply、call或者bind的方式触发函数,那么函数中的this指向传入函数的第一个参数。
- 如果一个函数是某个对象的方法,并且对象使用句点符号触发函数,那么this指向的就是该函数作为那个对象的属性的对象,也就是,this指向句点左边的对象
- 如果一个函数作为FFI被调用,意味着这个函数不符合以上任意一种调用方式,this指向全局对象,在浏览器中,即是window。
- 如果出现上面对条规则的累加情况,则优先级自1至4递减,this的指向按照优先级最高的规则判断。
参考:this指向记忆5大原则
- 箭头函数中的 this 指向:箭头函数中的this是在定义函数的时候绑定,而不是在执行函数的时候绑定。
更多:JS中的箭头函数与this
bind、call、apply
- call
call()方法接收的第一个参数和apply()方法接收的一样,变化的是其余的参数直接传递给函数。换句话说,在使用call()方法时,传递给函数的参数必须逐个列举出来。
function sum(num1 , num2)
return num1 + num2;
function callSum(num1 , num2)
return sum.call(this , sum1 , sum2);
console.log(callSum(10 , 10)); // 20
- apply
apply()方法接收两个参数:一个是在其中运行函数的作用域,另一个是参数数组,这里的参数数组可以是Array的实例,也可以是arguments对象(类数组对象)。
function sum(num1 , num2)
return num1 + num2;
function callSum1(num1,num2)
return sum.apply(this,arguments); // 传入arguments类数组对象
function callSum2(num1,num2)
return sum.apply(this,[num1 , num2]); // 传入数组
console.log(callSum1(10 , 10)); // 20
console.log(callSum2(10 , 10)); // 20
call和apply的区别在于二者传参的时候,前者是一个一个的传,后者是传数组或类数组arguments
- bind
bind()方法创建一个新的函数, 当被调用时,将其this关键字设置为提供的值,在调用新函数时,在任何提供之前提供一个给定的参数序列。
手写深浅拷贝
浅:
function clone(target)
let cloneTarget = ;
for (const key in target)
cloneTarget[key] = target[key];
return cloneTarget;
;
深(递归):
function clone(target)
if (typeof target === object)
let cloneTarget = Array.isArray(target) ? [] : ;
for (const key in target)
cloneTarget[key] = clone(target[key]);
return cloneTarget;
else
return target;
;
了解更多,推荐阅读:如何写出一个惊艳面试官的深拷贝?
四、js 继承
八种继承方式,详细请看此篇:JavaScript常用八种继承方案。
本瓜不做赘述,可列二三关键必记。
串联三:请你谈谈 Vue 原理?
本瓜不装了,摊牌了。其实本文的目录结构编写时间线在 #yyds干货盘点# LeetCode面试题:串联所有单词的子串
高频面试java高级进阶之锁?与CAS详解#yyds干货盘点#
#yyds干货盘点#2021年度Java并发编程面试真题&高频知识点汇总