ChatGPT 拓展资料:BERT 带你见证预训练和微调的奇迹
Posted 段智华
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ChatGPT 拓展资料:BERT 带你见证预训练和微调的奇迹相关的知识,希望对你有一定的参考价值。
ChatGPT 拓展资料:BERT 带你见证预训练和微调的奇迹


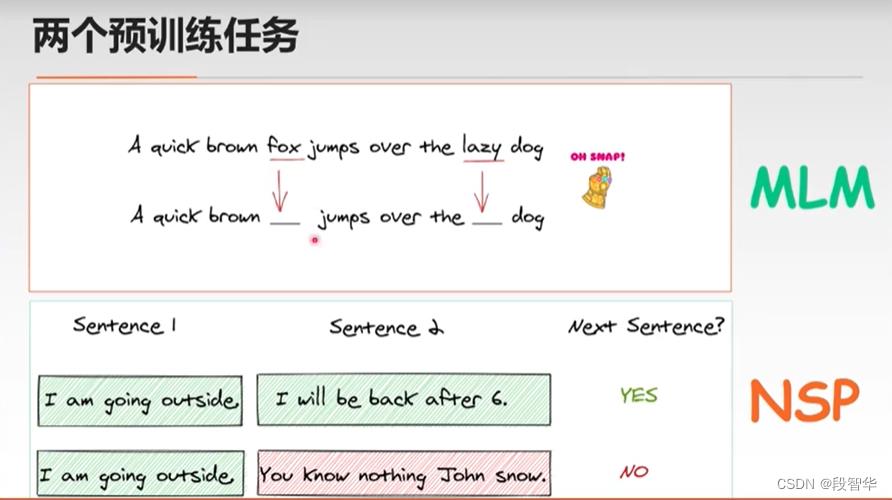
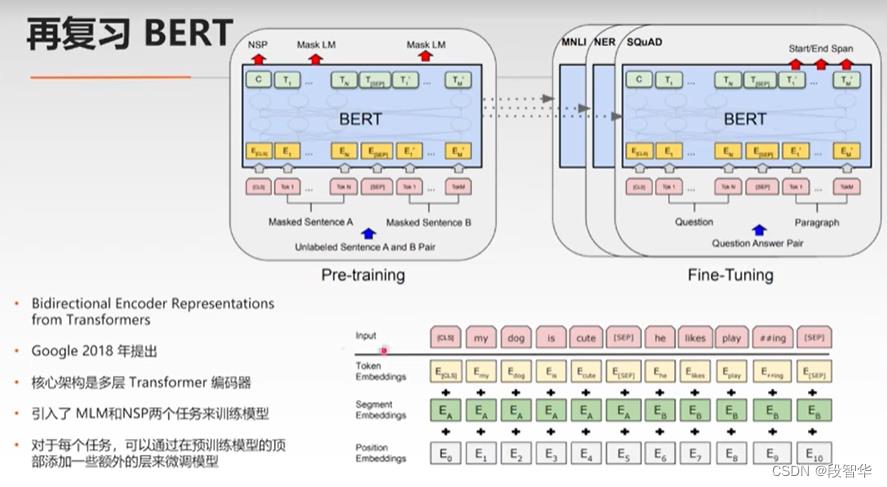
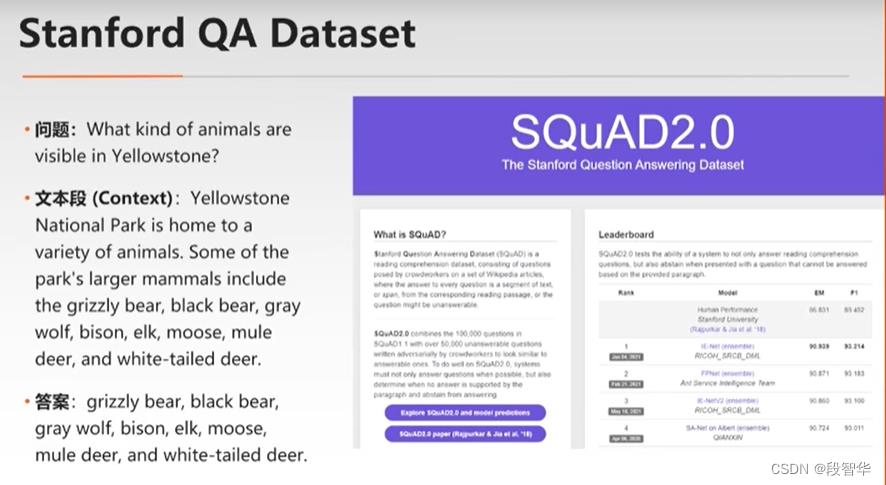
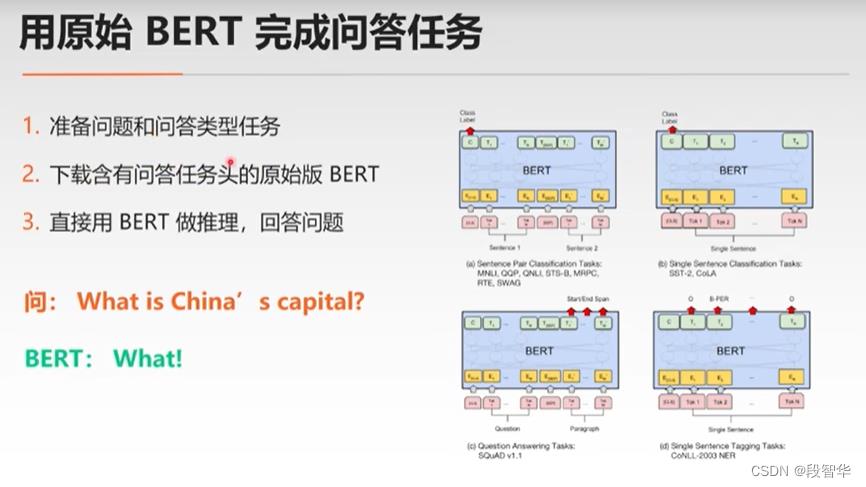
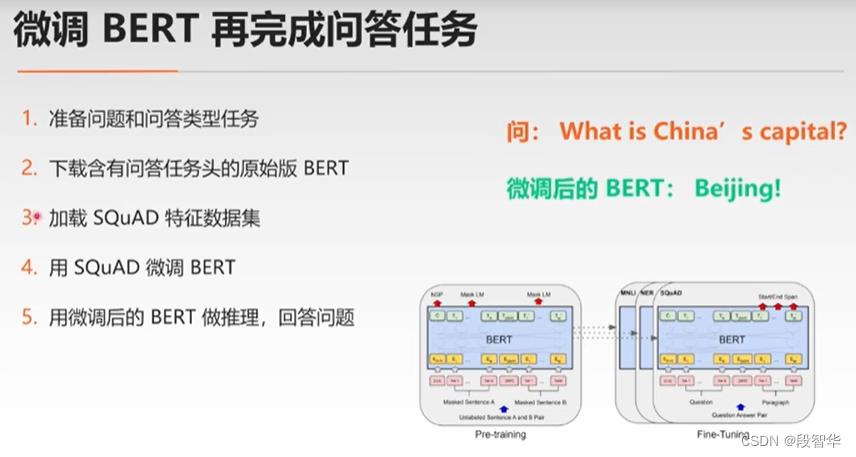
SQuAD数据集:
"version": 2021 第五届“达观杯” 基于大规模预训练模型的风险事件标签识别3 Bert和Nezha方案
相关链接
【2021 第五届“达观杯” 基于大规模预训练模型的风险事件标签识别】1 初赛Rank12的总结与分析
【2021 第五届“达观杯” 基于大规模预训练模型的风险事件标签识别】2 DPCNN、HAN、RCNN等传统深度学习方案
【2021 第五届“达观杯” 基于大规模预训练模型的风险事件标签识别】3 Bert和Nezha方案
1 引言
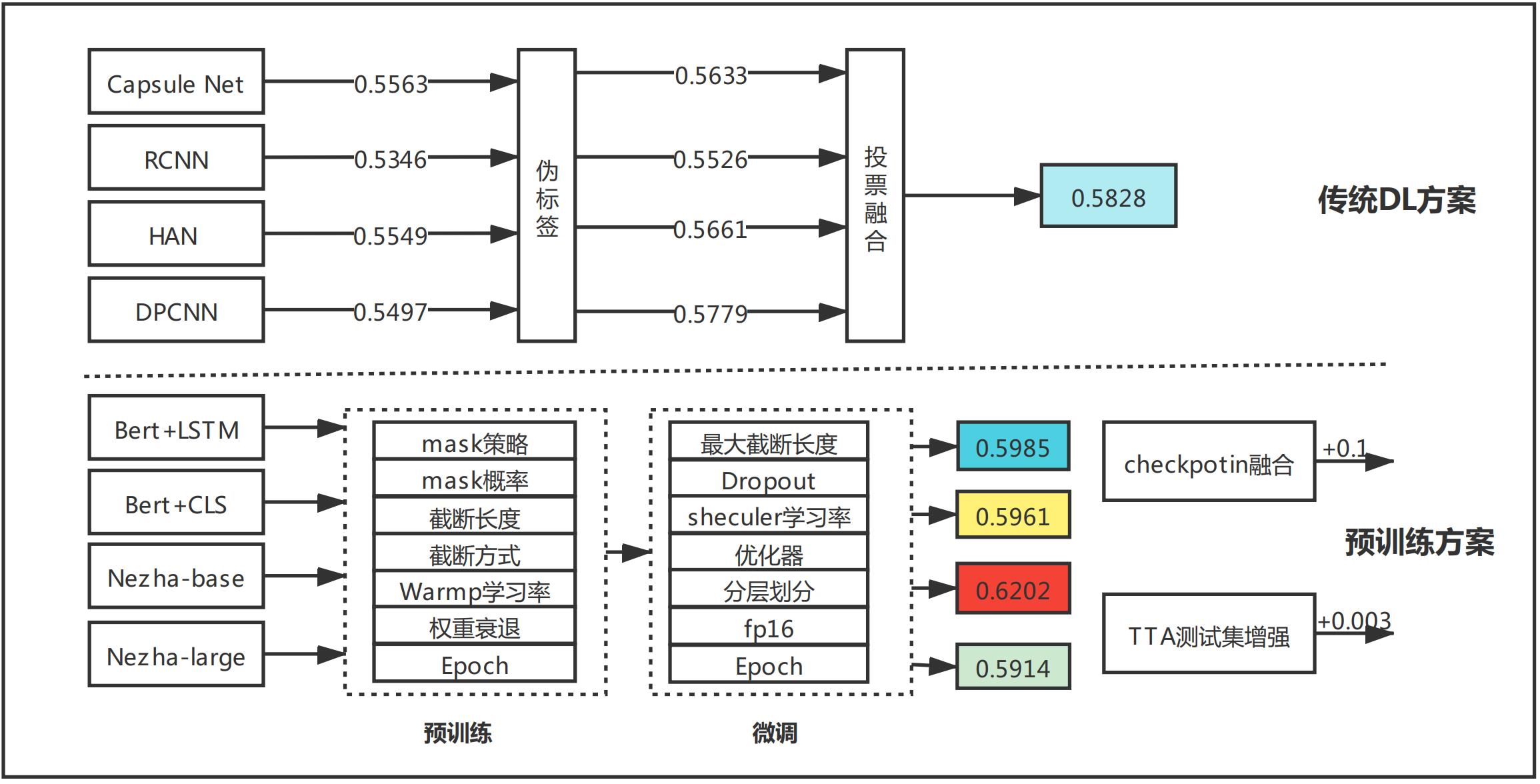
2 NEZHA方案
(1)代码结构
├── Bert_pytorch # Bert 方案
│ ├── bert-base-chinese # 初始权重,下载地址https://huggingface.co/bert-base-chinese#
│ ├── bert_finetuning # Bert微调
│ │ ├── Config.py # Bert配置文件
│ │ ├── ensemble_10fold.py # 10折checkpoint融合
│ │ ├── ensemble_single.py #每种模型不划分验证集只生成的一个模型,用这些模型进行checkpoint融合
│ │ ├── generate_pseudo_label.py # 利用做高分模型 给无标注数据做伪标签
│ │ ├── main_bert_10fold.py # 划分10折的Bert,这种会存储10个模型,每一个fold一个模型
│ │ ├── main_bert_all.py # 不划分验证集的Bert,这种只会存储一个模型
│ │ ├── model.py # 17种魔改Bert,和其他网络的具体实现部分
│ │ ├── models
│ │ ├── NEZHA # 网络结构实现文件,来源于官网
│ │ │ ├── configuration_nezha.py
│ │ │ └── modeling_nezha.py
│ │ ├── predict.py # 用模型模型进行预测测试集
│ │ ├── predict_tta.py # 用模型进行预测测试集,并使用TTA 测试集增强
│ │ ├── stacking.py # Stacking集成方法
│ │ └── utils.py # 工具函数
│ ├── bert_model_1000 # 存储预训练模型,下载地址https://drive.google.com/file/d/1rpWe5ec_buORvu8-ezvvAk9jrUZkOsIr/view?usp=sharing
│ ├── Data_analysis.ipynb # 数据分析
│ ├── Generate_TTA.ipynb # 生成TTA测试集增强的文件
│ └── pretrain # Bert预训练
│ ├── bert_model
│ │ ├── vocab_100w.txt # 100W未标注数据语料的词典,有18544个词
│ │ ├── vocab_3462.txt # 整个训练集和测试集的词典,不包括未标注数据
│ │ └── vocab.txt
│ ├── NLP_Utils.py
│ ├── train_bert.py # Bert预训练主函数
│ └── transformers1.zip # transformes较高的版本
├── data
│ ├── datagrand_2021_test.csv # 测试集
│ └── datagrand_2021_train.csv # 训练集
├── Nezha_pytorch #NEZHA预训练方案
│ ├── finetuning # Nezha微调
│ │ ├── Config.py
│ │ ├── model.py #模型实现文件
│ │ ├── models
│ │ ├── NEZHA
│ │ │ ├── configuration_nezha.py
│ │ │ └── modeling_nezha.py
│ │ ├── NEZHA_main.py #微调主函数
│ │ ├── predict.py # 10折模型预测
│ │ ├── submit
│ │ │ └── submit_bert_5epoch-10fold-first.csv
│ │ └── utils.py
│ ├── nezha-cn-base #nezha-base初始权重,下载地址https://github.com/lonePatient/NeZha_Chinese_PyTorch
│ ├── nezha_model #存放预训练生成的模型
│ ├── NEZHA_models
│ ├── nezha_output #预训练的checkpoint
│ ├── pretrain #nezha预训练
│ │ ├── __init__.py
│ │ ├── NEZHA
│ │ │ ├── configuration_nezha.py
│ │ │ ├── modeling_nezha.py
│ │ ├── nezha_model
│ │ │ └── vocab.txt # 预训练时,所需要的训练集的词典
│ │ ├── NLP_Utils.py
│ │ ├── train_nezha.py #预训练NEZHA的主函数
│ │ └── transformers1.zip # 更高版本的transformers
│ └── submit
2.1 预训练
nezha-large效果并不如nezha-base,区别只在于初始加载的权重不同以及预训练的网络层数不同。其他NEZHA-base和NEZHA-large一样。以下只针对NEZHA-base详解。
(1)重要方法
- Mask策略
动态mask:可以每次迭代都随机生成新的mask文本,增强模型泛化能力
N-gram Mask:以掩码概率mask_p的概率选中token,为增加训练难度,选中部分以70%、20%、10%的概率进行1-gram、2-gram、3-gram片段的mask(选中token使用[MASK]、随机词、自身替换的概率和原版Bert一致)
长度自适应:考虑到对短文本进行过较长gram的mask对语义有较大破坏,长度小于7的文本不进行3-gram mask,小于4的文本不进行2-gram mask(这一点在是参考原作者代码的,并没有进行修改,虽然已经在代码中已经实现,但是在该赛题中,并没有长度低于7的句子。所以并没有起任何作用,也没有任何影响)
防止小概率的连续Mask:已经mask了的文本片段,强制跳过下一个token的mask,防止一长串连续的mask - 掩码概率: mask_p,原本是0.15,我们通过增加了掩码概率为0.5增大预训练的难度,能够一定程度防止微调过拟合。
- 截断长度: 根据数据分析,发现句子的平均词数是54左右,随机选择了100的截断长度,这一点并没有进行调参
- 截断方式: 首尾截断,还有首部截断和尾部截断并没有进行对比,一直使用的首尾截断。实现过程就是计算大于截断长度的数,首部截断一半,尾部截断一半。
- Epoch: 设置为480时,NEZHA单模效果最佳。
- 只训练word_embedding和position_emebedding
加快训练。在打印查看model的position_embedding的时候,并没有找到,实现时就只训练了word_embedding。能缩短两倍的训练时间
model = NeZhaForMaskedLM.from_pretrained("./nezha-cn-base/")
model.resize_token_embeddings(len(tokenizer))
# 只训练word_embedding。能缩短两倍的训练时间
for name, p in model.named_parameters():
if name != 'bert.embeddings.word_embeddings.weight':
p.requires_grad = False
- Warmup学习率和权重衰退: 采用transformers的有预训练函数,参数设置如下
from transformers import Trainer, TrainingArguments,BertTokenizer
training_args = TrainingArguments(
output_dir='Nezha_pytorch/pretrain/nezha_output',# 此处必须是绝对路径
overwrite_output_dir=True,
num_train_epochs=1000,
per_device_train_batch_size=32,
save_steps=10000,#每10000step就 save一次
save_total_limit=3,
logging_steps=len(dl),#每个epoch log一次
seed=2021,
learning_rate=5e-5,
weight_decay=0.01,#权重衰退
warmup_steps=int(450000*150/batch_size*0.03)# warmup
)
- 分块shuffle: 原源代码作者实现,我们并未修改这块
分块shuffle将长度差不多的样本组成batch快,块间shuffle,减少padding部分运算量,预训练耗时减少了约40%
#sortBsNum:原序列按多少个bs块为单位排序,可用来增强随机性
#比如如果每次打乱后都全体一起排序,那每次都是一样的
def blockShuffle(data:list,bs:int,sortBsNum,key):
random.shuffle(data)#先打乱
tail=len(data)%bs#计算碎片长度
tail=[] if tail==0 else data[-tail:]
data=data[:len(data)-len(tail)]
assert len(data)%bs==0#剩下的一定能被bs整除
sortBsNum=len(data)//bs if sortBsNum is None else sortBsNum#为None就是整体排序
data=splitList(data,sortBsNum*bs)
data=[sorted(i,key=key,reverse=True) for i in data]#每个大块进行降排序
data=unionList(data)
data=splitList(data,bs)#最后,按bs分块
random.shuffle(data)#块间打乱
data=unionList(data)+tail
return data
from torch.utils.data.dataloader import _SingleProcessDataLoaderIter,_MultiProcessingDataLoaderIter
#每轮迭代重新分块shuffle数据的DataLoader
class blockShuffleDataLoader(DataLoader):
def __init__(self, dataset: Dataset,sortBsNum,key,**kwargs):
assert isinstance(dataset.data,list)#需要有list类型的data属性
super().__init__(dataset,**kwargs)#父类的参数传过去
self.sortBsNum=sortBsNum
self.key=key
def __iter__(self):
#分块shuffle
self.dataset.data=blockShuffle(self.dataset.data,self.batch_size,self.sortBsNum,self.key)
if self.num_workers == 0:
return _SingleProcessDataLoaderIter(self)
else:
return _MultiProcessingDataLoaderIter(self)
(2)掩码策略实现
class MLM_Data(Dataset):
def __init__(self,textLs:list,maxLen:int,tk:BertTokenizer):
super().__init__()
self.data=textLs
self.maxLen=maxLen
self.tk=tk
self.spNum=len(tk.all_special_tokens)
self.tkNum=tk.vocab_size
def __len__(self):
return len(self.data)
def random_mask(self,text_ids):
input_ids, output_ids = [], []
rands = np.random.random(len(text_ids))
idx=0
mask_p = 0.5 # 原始是0.15,加大mask_p就会加大预训练难度
while idx<len(rands):
if rands[idx]<mask_p:#需要mask
# n-gram 动态mask策略
ngram=np.random.choice([1,2,3], p=[0.7,0.2,0.1])#若要mask,进行x_gram mask的概率
if ngram==3 and len(rands)<7:#太大的gram不要应用于过短文本
ngram=2
if ngram==2 and len(rands)<4:
ngram=1
L=idx+1
R=idx+ngram#最终需要mask的右边界(开)
while L<R and L<len(rands):
rands[L]=np.random.random()*0.15#强制mask
L+=1
idx=R
if idx<len(rands):
rands[idx]=1#禁止mask片段的下一个token被mask,防止一大片连续mask
idx+=1
for r, i in zip(rands, text_ids):
if r < mask_p * 0.8:
input_ids.append(self.tk.mask_token_id)
output_ids.append(i)#mask预测自己
elif r < mask_p * 0.9:
input_ids.append(i)
output_ids.append(i)#自己预测自己
elif r < mask_p:
input_ids.append(np.random.randint(self.spNum,self.tkNum))
output_ids.append(i)#随机的一个词预测自己,随机词不会从特殊符号中选取,有小概率抽到自己
else:
input_ids.append(i)
output_ids.append(-100)#保持原样不预测
return input_ids, output_ids
#耗时操作在此进行,可用上多进程
def __getitem__(self, item):
text1,_=self.data[item]#预处理,mask等操作
text1=truncate(text1,self.maxLen)
text1_ids = self.tk.convert_tokens_to_ids(text1)
text1_ids, out1_ids = self.random_mask(text1_ids)#添加mask预测
input_ids = [self.tk.cls_token_id] + text1_ids + [self.tk.sep_token_id]#拼接
token_type_ids=[0]*(len(text1_ids)+2)
labels = [-100] + out1_ids + [-100]
assert len(input_ids)==len(token_type_ids)==len(labels)
return {'input_ids':input_ids,'token_type_ids':token_type_ids,'labels':labels}
@classmethod
def collate(cls,batch):
input_ids=[i['input_ids'] for i in batch]
token_type_ids=[i['token_type_ids'] for i in batch]
labels=[i['labels'] for i in batch]
input_ids=paddingList(input_ids,0,returnTensor=True)
token_type_ids=paddingList(token_type_ids,0,returnTensor=True)
labels=paddingList(labels,-100,returnTensor=True)
attention_mask=(input_ids!=0)
return {'input_ids':input_ids,'token_type_ids':token_type_ids
,'attention_mask':attention_mask,'labels':labels}
(3)预训练好的模型下载
2.2 微调
(1)重要方法
- 最大截断长度: 根据数据分析,训练集和测试集的平均每个句子的词的个数是54,在传统DL上进行过调参,100最佳,在这里就选择100
- Dropout: 调参决定0.2和0.1接近,最终选择0.2
- scheduler学习率: 对比过多种学习率,最终选择余弦退火学习率
- get_constant_schedule:保持固定学习率不变
- get_constant_schedule_with_warmup:在每一个 step 中线性调整学习率
- get_linear_schedule_with_warmup:两段式调整学习率
- get_cosine_schedule_with_warmup:和两段式调整类似,只不过采用的是三角函数式的曲线调整
- get_cosine_with_hard_restarts_schedule_with_warmup:训练中将上面get_cosine_schedule_with_warmup 的调整重复 n 次
- get_polynomial_decay_schedule_with_warmup:按指数曲线进行两段式调整
使用schduler的作用是:在训练初期使用较小的学习率(从 0 开始),在一定步数(比如 1000 步)内逐渐提高到正常大小(比如上面的 2e-5),避免模型过早进入局部最优而过拟合;在训练后期再慢慢将学习率降低到 0,避免后期训练还出现较大的参数变化
- 数据预处理: 在类似情感分析这种文本分类任务中,标点符号是很重要的标志,在此的数据处理就并没有采用删除的方法,而是替换为不在数据集中的词。
def preprocess_text(document):
# 将符号替换为不在脱敏文本的词典中的词
# 删除逗号, 脱敏数据中最大值为30357
text = str(document)
text = text.replace(',', '35001')
text = text.replace('!', '35002')
text = text.replace('?', '35003')
text = text.replace('。', '35004')
# text = text.replace('17281', '')
# 用单个空格替换多个空格
text = re.sub(r'\\s+', ' ', text, flags=re.I)
return text
- 优化器: 对比Lookahead和 AdamW两种,AdamW最佳。 Lookahead需要源码使用,具体代码见utils.py
from transformers import AdamW
if config.optimizer == "AdamW":
optimizer = AdamW(optimizer_parameters, lr=config.learn_rate)
elif config.optimizer == "lookahead":
optimizer = AdamW(optimizer_parameters,lr=config.learn_rate, eps=adam_epsilon)
optimizer = Lookahead(optimizer=optimizer, la_steps=5, la_alpha=0.6)
- 交叉验证分层划分: 对比过使用 Kfold和StratifiedKFold。后者更加
- 混合精度训练: 虽然NEZHA模型本身就是加入了混合精度训练的,但是我们在跑模型的时候,还是去配置了使用FP16,未对比我们加入自定义的FP16是否会与NEZHA本身FP16冲突以及是否会影响精度。
- Epoch: 加大Epoch能够训练充分,考虑到训练时间和预训练的数据集只有1W多的数据,在微调就加大了Epoch,选择了50Epoch。但是一般情况下,如果预训练语料足够大,微调的Epoch设置为个位数即可。
- 对抗训练: 对比了FGM和PGD 的两种方法,FGM较快,且加入对抗能提高两个点。
- 训练时间: 显卡3090,大概13个小时
- 占用显存: 大约7G
(2)NEZHA模型实现
class NEZHA(nn.Module):
def __init__(self, config):
super(NEZHA, self).__init__()
self.n_classes = config.num_class
config_json = 'bert_config.json' if os.path.exists(
config.model_path + 'bert_config.json') else 'config.json'
self.bert_config = CONFIGS[config.model].from_pretrained(
config.model_path + config_json)
#self.bert_model = MODELS[config.model](config=self.bert_config)
self.bert_model = MODELS[config.model].from_pretrained(
config.model_path, config=self.bert_config)
# NEZHA init
#torch_init_model(self.bert_model, os.path.join(config.model_path, 'pytorch_model.bin'))
self.isDropout = True if 0 < config.dropout < 1 else False
self.dropout = nn.Dropout(p=config.dropout)
self.classifier = nn.Linear(
self.bert_config.hidden_size * 2, self.n_classes)
def forward(self, input_ids, input_masks, segment_ids):
sequence_output, pooler_output = self.bert_model(input_ids=input_ids, token_type_ids=segment_ids,
attention_mask=input_masks)
seq_avg = torch.mean(sequence_output, dim=1)
concat_out = torch.cat((seq_avg, pooler_output), dim=1)
if self.isDropout:
concat_out = self.dropout(concat_out)
logit = self.classifier(concat_out)
return logit
3 Bert 方案
3.1 预训练
预训练和NEZHA不同的有三个地方
- 掩码概率mask_p为0.15:因为把NEZHA的预训练方案应用在Bert 上的预训练后,实验对比发现,效果不佳。
- 预训练模型全部层都训练了,并没有冻结word_embedding以外的所有层去训练。
- 预处理是删除掉标点符号,但是未来得及做其他的预处理预训练,本应该与NEZHA的预处理保持一致的
def preprocess_text(document):
# 删除逗号
text = str(document)
text = text.replace(',', '')
text = text.replace('!', '')
text = text.replace('17281', '')
# 用单个空格替换多个空格
text = re.sub(r'\\s+', ' ', text, flags=re.I)
return text
(2)预训练好的模型下载
3.2 微调
(1)注意
除了以下四个不同的点,其他与NEZHA一致
- 对抗训练:FGM和PGD效果都不佳,就没有加入对抗训练
- Dropout:设置为0.1 调参选择出来的
- 不划分验证集:全部训练集都作为训练集,不验证,当然这是在对不部分调参完毕后,做的实验,比交叉验证效果更佳
- 数据预处理:和预训练的一样
(2)网络结构
并不是使用的传统Bert,而是使用的魔改Bert
- Bert+LSTM
class BertLstm(nn.Module):
def __init__(self, config):
super(BertLstm, self).__init__()
self.n_classes = config.num_class
config_json = 'bert_config.json' if os.path.exists(
config.model_path + 'bert_config.json') else 'config.json'
self.bert_config = CONFIGS[config.model].from_pretrained(config.model_path + config_json,
output_hidden_states=True)
self.bert_model = MODELS[config.model].from_pretrained(
config.model_path, config=self.bert_config)
self.isDropout = True if 0 < config.dropout < 1 else False
self.dropout = nn.Dropout(p=config.dropout)
self.classifier = nn.Linear(
self.bert_config.hidden_size * 2, self.n_classes)
self.bilstm = nn.LSTM(input_size=self.bert_config.hidden_size,
hidden_size=self.bert_config.hidden_size, batch_first=True, bidirectional=True)
def forward(self, input_ids, input_masks, segment_ids):
output = self.bert_model(input_ids=input_ids, token_type_ids=segment_ids, attention_mask=input_masks)
sequence_output = output[0]
pooler_output = output[1]
output_hidden, _ = self.bilstm(sequence_output) # [10, 300, 768]
concat_out = torch.mean(output_hidden, dim=1)
if self.isDropout:
concat_out = self.dropout(concat_out)
logit = self.classifier(concat_out)
return logit
- Bert+CLS
最后一层向量取平均后与最后一层cls拼接
class BertForClass(nn.Module):
def __init__(self, config):
super(BertForClass, self).__init__()
self.n_classes = config.num_class
config_json = 'bert_config.json' if os以上是关于ChatGPT 拓展资料:BERT 带你见证预训练和微调的奇迹的主要内容,如果未能解决你的问题,请参考以下文章
2021 第五届“达观杯” 基于大规模预训练模型的风险事件标签识别3 Bert和Nezha方案