mysql特殊语法insert into .. on duplicate key update ..使用详解
Posted 秃秃爱健身
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mysql特殊语法insert into .. on duplicate key update ..使用详解相关的知识,希望对你有一定的参考价值。
文章目录
一、前言
在日常开发中,经常会遇到这样的需求:查看某条记录是否存在,不存在的话创建一条新记录,存在的话更新某些字段。
比如下列伪代码:
$row = mysql_query($result);
if($row)
mysql_execute('update ...');
else
mysql_execute('insert ...');
二、insert into … on duplicate key update …
MySql针对此,提供了insert into … on duplicate key update …的语法:
- 在insert的时候,如果insert的数据会引起唯一索引(包括主键索引)的冲突,即唯一值重复了,则不会执行insert操作,而执行后面的update操作。
注意:这个是MYSQL特有的,不是SQL标准语法;
1、处理逻辑
insert into … on duplicate key update …语句是根据唯一索引判断记录是否重复的;
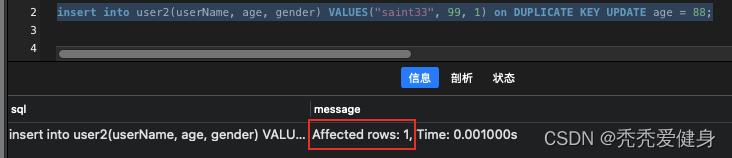
- 如果不存在记录,插入,则影响的行数为1;
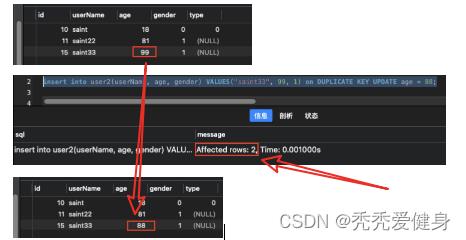
- 如果存在记录,可以更新字段,则影响的行数为2;
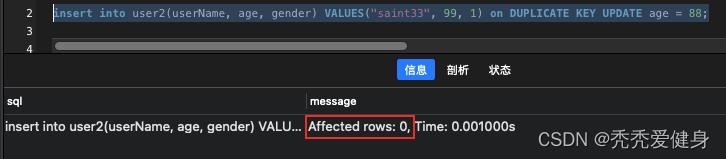
- 如果存在记录,并且更新的值和原有的值相同,则影响的行数为0。
如果表同时存在多个唯一索引,只会根据第一个在数据库中存在相应value的唯一索引做duplicate判断:
2、示例:
表结构
CREATE TABLE `user2` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`userName` varchar(94) NOT NULL,
`age` int(11) DEFAULT NULL,
`gender` int(1) DEFAULT NULL,
`type` int(1) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `idex_name` (`userName`) USING BTREE,
KEY `idx_type` (`type`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=13 DEFAULT CHARSET=utf8;
user2表中有一个主键id、一个唯一索引idx_userName;
1> 不存在记录,插入的情况
insert into user2(userName, age, gender) VALUES("saint33", 99, 1) on DUPLICATE KEY UPDATE age = 88;
2> 存在记录,可以更新字段的情况
insert into user2(userName, age, gender) VALUES("saint33", 99, 1) on DUPLICATE KEY UPDATE age = 88;
3> 存在记录,不可以更新字段的情况
insert into user2(userName, age, gender) VALUES("saint33", 99, 1) on DUPLICATE KEY UPDATE age = 88;
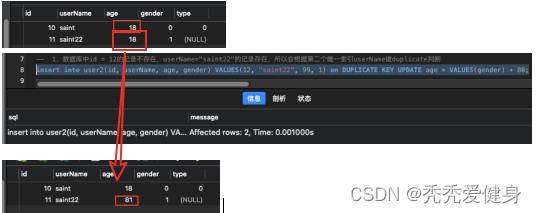
4> 存在多个唯一索引时
如果表同时存在多个唯一索引,只会根据第一个在数据库中存在相应value的唯一索引做duplicate判断:
1)数据库中id = 12的记录不存在,userName="saint22"的记录存在,所以会根据第二个唯一索引userName做duplicate判断;
insert into user2(id, userName, age, gender) VALUES(12, "saint22", 99, 1) on DUPLICATE KEY UPDATE age = VALUES(gender) + 80;
2)数据库中id = 10的记录存在,userName="saint22"的记录存在,所以会根据第一个唯一索引id做duplicate判断;
insert into user2(id, userName, age, gender) VALUES(10, "saint22", 99, 1) on DUPLICATE KEY UPDATE age = VALUES(gender) + 90;
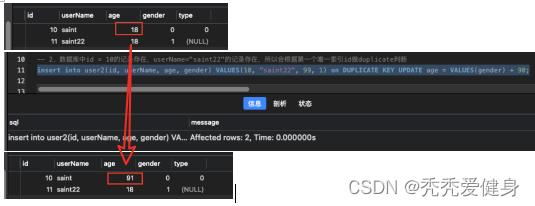
3、Update子句获取inset部分的值
Update子句可以使用values(col_name)获取insert部分的值:
insert into user2(userName, age, gender) VALUES("saint22", 99, 1) on DUPLICATE KEY UPDATE age = VALUES(age) + 100;
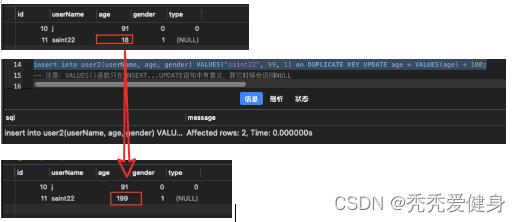
注意:VALUES()函数只在INSERT…UPDATE语句中有意义,其它时候会返回NULL;
4、last_insert_id()
如果表含有auto_increment字段,使用insert … on duplicate key update插入或更新后,last_insert_id()返回auto_increment字段的值。
MySQL的insert ignore与replace into不同
以前从来没有接触过replace into这个语法,但是却看到很多人都在使用这个语法,并且应用在很多生产环境中,于是我也去学习了一下repalce into的用法。
关于replace
一句话:正常情况下表中有PRIMARY KEY或UNIQUE索引,新数据会替换老的数据。没有老数据则insert该数据。
REPLACE的运行与INSERT很相像。只有一点除外,如果表中的一个旧记录与一个用于PRIMARY KEY或一个UNIQUE索引的新记录具有相同的值,则在新记录被插入之前,旧记录被删除。使用REPLACE相当于对原有的数据(在PRIMARY KEY或UNIQUE索引下有值的数据)进行delete操作,然后再insert操作。为了能够使用REPLACE,您必须同时拥有表的INSERT和DELETE权限。
除非表有一个PRIMARY KEY或UNIQUE索引,否则,使用一个REPLACE语句没有意义。该语句会与INSERT相同,因为没有索引被用于确定是否新行复制了其它的行。
replace的使用一般是:只想对数据在数据库中保存一份,不想出现重复的数据(重复的主键、唯一索引),因为重复的数据不是我们想要的,会给业务逻辑带来麻烦。但是又要更新一些字段为最新的值,比如最后的检查时间、任务的结果。
REPLACE语句会返回一个数,来指示受影响的行的数目。该数是被删除和被插入的行数的和
受影响的行数可以容易地确定是否REPLACE只添加了一行,或者是否REPLACE也替换了其它行:检查该数是否为1(添加)或更大(替换)。
关于insert ignore
一句话:忽略执行insert语句出现的错误,不会忽略语法问题,但是忽略主键存在的情况。
如果没有ignore关键字,那么在insert数据到一个表(在UNIQUE索引或PRIMARY KEY有相同值)中,这时会出现错误,语句执行失败。但是使用了ignore关键字后,不会出现这个错误,并且新数据不会被插入到数据表中。
使用场景:比如一个多线程的插入数据表,为了不让多个线程向表中插入相同的数据,可以使用insert ignore来忽略重复的数据。有比如,你的程序down了,需要重新运行,那么会重新拉取数据再insert到数据库中,这个时候可能会存在重复的数据导致错误,ignore就可以解决这个问题。
两者的一些联系区别
联系:
不想向数据表中插入相同的主键、unique索引时,可以使用replace或insert ignore,来避免重复的数据。
区别:
- replace相当于delete然后insert,会有对数据进行写的过程。
- insert ignore会忽略已经存在主键或unique索引的数据,而不会有数据的修改。
使用场景:
- 如果不需要对数据进行更新值,那么推荐使用
insert ignore,比如:多线程的插入相同的数据。 - 如果需要对数据进行更新最新的值,那么使用
replace,比如:任务的结果,最后的更新时间。
后话:自从知道了有insert ignore,我再也不会一股劲的使用replace了,妈妈再也不用担心数据库的频繁删写操作。
参考资料
以上是关于mysql特殊语法insert into .. on duplicate key update ..使用详解的主要内容,如果未能解决你的问题,请参考以下文章