聊一聊rabbitMQ和kafka的应用场景
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了聊一聊rabbitMQ和kafka的应用场景相关的知识,希望对你有一定的参考价值。
参考技术A 我们知道常用的2款消息中间件是rabbitmq和kafka,他们2者都有什么各自的特点和应用场景呢?我们下面就聊一聊。rabbitmq消息的发送,首先经过exchange,然后由exchange根据路由把消息投递到绑定的队列中,exchange有3中类型:
fanout:完全模式,消息会投递到和exchange绑定的所以队列中,使用于多个消费者应用的场景。
direct:直接模式,消息投递根据发送的routingkey和bindingkey完全匹配的队列中,使用单消费者场景。
topic:topic模式,消息投递模糊匹配路由规则,可以投递到多个匹配的队列中。
rabbitmq的消息可以持久化,也可以不持久化,消息消费完就被删除,不能重复消费。
rabbitmq cluster消息的存储,一个队列只能在一台机器上存储,无法实现分片存储。
kafka消息发送topic,topic可以多个分区,同一个topic的消息可以分片保存在不同的机器上,消息持久化存储在磁盘上,一个消息可以重复消费,不用像rabbitmq一样,有几个消费者来消费这个消息,就需要几个消息队列来存储这个消息。
面试官:聊一聊 kafka 线上会遇到哪些问题?
点击关注公众号,Java干货及时送达
1、哪些环节会造成消息丢失?
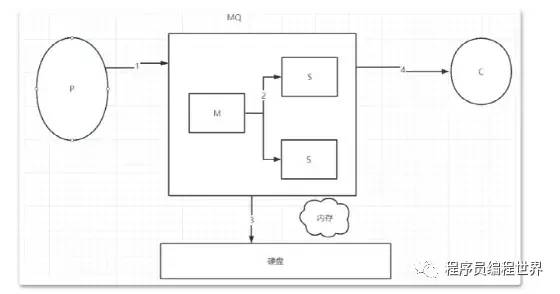
首先说说哪些环节会丢消息
消息生产者:
(1)acks=0:表示producer不需要等待任何broker确认收到消息的回复,就可以继续发送下一条消息。性能最高,但是最容易丢消 息。大数据统计报表场景,对性能要求很高,对数据丢失不敏感的情况可以用这种。
(2)acks=1:至少要等待leader已经成功将数据写入本地log,但是不需要等待所有follower是否成功写入。就可以继续发送下一条消 息。这种情况下,如果follower没有成功备份数据,而此时leader又挂掉,则消息会丢失。
(3)acks=-1或all:这意味着leader需要等待所有备份(min.insync.replicas配置的备份个数)都成功写入日志,这种策略会保证只要有一 个备份存活就不会丢失数据。这是最强的数据保证。一般除非是金融级别,或跟钱打交道的场景才会使用这种配置。当然如果 min.insync.replicas配置的是1则也可能丢消息,跟acks=1情况类似。
消息消费端:
如果消费这边配置的是自动提交,万一消费到数据还没处理完,就自动提交offset了,但是此时你consumer直接宕机了,未处理完的数据 丢失了,下次也消费不到了。
怎么保证消息不丢失?

生产端:消息发送+回调
伪代码
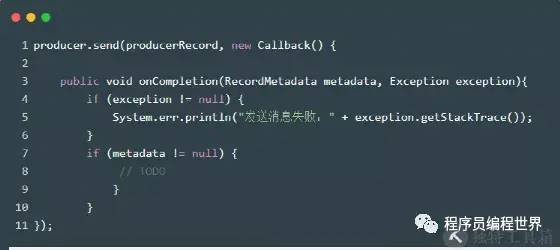
消费端:业务处理完后手动提交事务
最新 Kafka 面试题整理好了,点击Java面试库小程序在线刷题。
2、消息重复消费
消息发送端:
发送消息如果配置了重试机制,比如网络抖动时间过长导致发送端发送超时,实际broker可能已经接收到消息,但发送方会重新发送消息
消息消费端:
如果消费这边配置的是自动提交,刚拉取了一批数据处理了一部分,但还没来得及提交,服务挂了,下次重启又会拉取相同的一批数据重 复处理
一般消费端都是要做消费幂等处理的。
3、消息顺序
如果发送端配置了重试机制,kafka不会等之前那条消息完全发送成功才去发送下一条消息,这样可能会出现,发送了1,2,3条消息,第 一条超时了,后面两条发送成功,再重试发送第1条消息,这时消息在broker端的顺序就是2,3,1了 所以,是否一定要配置重试要根据业务情况而定。也可以用同步发送的模式去发消息,当然acks不能设置为0,这样也能保证消息从发送 端到消费端全链路有序。
kafka保证全链路消息顺序消费,需要从发送端开始,将所有有序消息发送到同一个分区,然后用一个消费者去消费,但是这种性能比较 低,可以在消费者端接收到消息后将需要保证顺序消费的几条消费发到内存队列(可以搞多个),一个内存队列开启一个线程顺序处理消 息。
4、消息积压
1)线上有时因为发送方发送消息速度过快,或者消费方处理消息过慢,可能会导致broker积压大量未消费消息。此种情况如果积压了上百万未消费消息需要紧急处理,可以修改消费端程序,让其将收到的消息快速转发到其他topic(可以设置很多分 区),然后再启动多个消费者同时消费新主题的不同分区。
2)由于消息数据格式变动或消费者程序有bug,导致消费者一直消费不成功,也可能导致broker积压大量未消费消息。此种情况可以将这些消费不成功的消息转发到其它队列里去(类似死信队列),后面再慢慢分析死信队列里的消息处理问题。
最新 Kafka 面试题整理好了,点击Java面试库小程序在线刷题。
5、kafka高性能原因:
•磁盘顺序读写:kafka消息不能修改以及不会从文件中间删除保证了磁盘顺序读,kafka的消息写入文件都是追加在文件末尾, 不会写入文件中的某个位置(随机写)保证了磁盘顺序写。
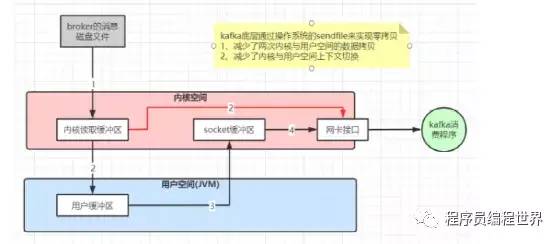
•数据传输的零拷贝
•读写数据的批量batch处理以及压缩传输
传统文件复制方式:需要对文件在内存中进行四次拷贝。
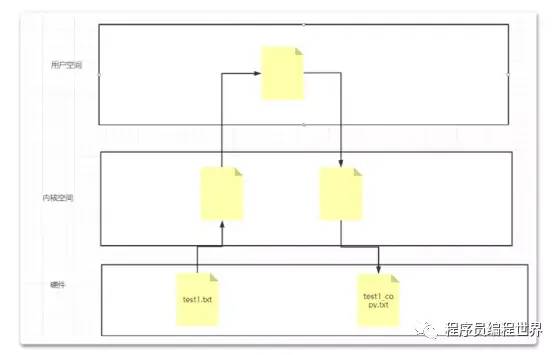
零拷贝:有两种方式, mmap和transfile
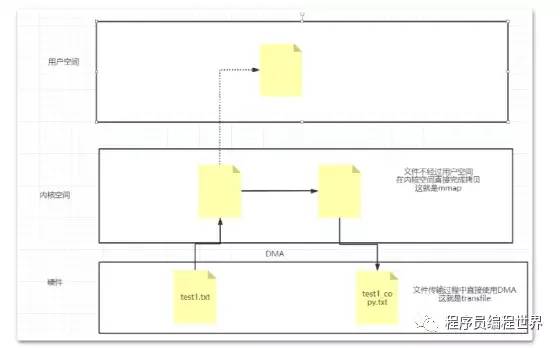
Java当中对零拷贝进行了封装, Mmap方式通过MappedByteBuffer对象进行操作,而transfile通过FileChannel来进行操作。
Mmap 适合比较小的文件,通常文件大小不要超过1.5G ~2G 之间。
Transfile没有文件大小限制
在kafka当中,他的index日志文件也是通过mmap的方式来读写的。在其他日志文件当中,并没有使用零拷贝的方式。
kafka使用transfile方式将硬盘数据加载到网卡。








关注Java技术栈看更多干货


获取 Spring Boot 实战笔记!
以上是关于聊一聊rabbitMQ和kafka的应用场景的主要内容,如果未能解决你的问题,请参考以下文章