必读!信息抽取(Information Extraction)【关系抽取】
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了必读!信息抽取(Information Extraction)【关系抽取】相关的知识,希望对你有一定的参考价值。
参考技术A信息抽取(information extraction),简称IE,即从自然语言文本中,抽取出特定的事件或事实信息,帮助我们将海量内容自动分类、提取和重构。这些信息通常包括实体(entity)、关系(relation)、事件(event)。 例如从新闻中抽取时间、地点、关键人物,或者从技术文档中抽取产品名称、开发时间、性能指标等。能从自然语言中抽取用户感兴趣的事实信息,无论是在知识图谱、信息检索、问答系统还是在情感分析、文本挖掘中,信息抽取都有广泛应用。
信息抽取主要包括三个子任务 :
关系抽取 :通常我们说的三元组(triple)抽取,主要用于抽取实体间的关系。
实体抽取与链指 :也就是命名实体识别。
事件抽取 :相当于一种多元关系的抽取。
关系抽取(RE)是为了抽取文本中包含的关系,是信息抽取(IE)的重要组成部分 。主要负责从无结构文本中识别出实体,并抽取实体之间的语义关系,被广泛用在信息检索、问答系统中。本文从关系抽取的 基本概念 出发,依据不同的视角对 关系抽取方法进行了类别划分 ;最后分享了基于深度学习的关系抽取方法常用的数据集,并总结出基于深度学习的关系抽取框架。
完整的关系抽取包括实体抽取和关系分类两个子过程。实体抽取子过程也就是命名实体识别,对句子中的实体进行检测和分类; 关系分类子过程对给定句子中两个实体之间的语义关系进行判断,属于多类别分类问题 。
例如,对于句子“青岛坐落于山东省的东部”,实体抽取子过程检测出这句话具有“青岛”和“山东”两个实体。关系分类子过程检测出这句话中“青岛”和“山东”两个实体具有“坐落于”关系而不是“出生于”关系。在关系抽取过程中,多数方法默认实体信息是给定的,那么关系抽取就可以看作是分类问题。
目前, 常用的关系抽取方法有5类,分别是基于模式匹配、基于词典驱动、基于机器学习、基于本体和混合的方法 。基于模式匹配和词典驱动的方法依靠人工制定规则,耗时耗力,而且可移植性较差,基于本体的方法构造比较复杂,理论尚不成熟。 基于机器学习的方法以自然语言处理技术为基础,结合统计语言模型进行关系抽取,方法相对简单,并具有不错的性能,成为当下关系抽取的主流方法,下文提到的关系抽取方法均为机器学习的方法 。
关于信息关系抽取,可以 从训练数据的标记程度 、 使用的机器学习方法 、 是否同时进行实体抽取 和 关系分类子过程以及是否限定关系抽取领域和关系专制 四个角度对机器学习的关系抽取方法进行分类。
根据训练数据的标记程度可以将关系抽取方法分为 有监督、半监督和无监督三类 。
有监督学习 ,处理的基本单位是包含特定实体对的句子,每一个句子都有类别标注。 优点 :取能够有效利用样本的标记信息,准确率和召回率都比较高。 缺点 :需要大量的人工标记训练语料,代价较高。
半监督学习 ,句子作为训练数据的基本单位,只有部分是有类别标注的。此类方法让学习器不依赖外界交互,自动地利用未标记样本来提升学习性能。
无监督学习 ,完全不需要对训练数据进行标注,此类方法包含实体对标记、关系聚类和关系词选择三个过程。
根据使用机器学习方法不同,可以将关系抽取划分为三类: 基于特征向量的方法 、 基于核函数的方法 以及 基于神经网络的方法 。
基于特征向量的方法 ,通过从包含特定实体对的句子中提取出语义特征,构造特征向量,然后通过使用支持向量机、最大熵、条件随机场等模型进行关系抽取。
基于核函数的方法 ,其重点是巧妙地设计核函数来计算不同关系实例特定表示之间的相似度。 缺点 :而如何设计核函数需要大量的人类工作,不适用于大规模语料上的关系抽取任务。
基于神经网络的方法 ,通过构造不同的神经网络模型来自动学习句子的特征,减少了复杂的特征工程以及领域专家知识,具有很强的泛化能力。
根据是否在同一个模型里开展实体抽取和关系分类,可以将关系抽取方法分为 流水线(pipeline)学习 和 联合(joint)学习两种 。
流水线学习 是指先对输入的句子进行实体抽取,将识别出的实体分别组合,然后再进行关系分类,这两个子过程是前后串联的,完全分离。
联合学习 是指在一个模型中实现实体抽取和关系分类子过程。该方法通过使两个子过程共享网络底层参数以及设计特定的标记策略来解决上述问题,其中使用特定的标记策略可以看作是一种序列标注问题。
根据是否限定抽取领域和关系类别,关系抽取方法可以划分为 预定义抽取 和 开放域抽取 两类。
预定义关系抽取 是指在一个或者多个固定领域内对实体间关系进行抽取,语料结构单一,这些领域内的目标关系类型也是预先定义的。
开放域关系抽取 不限定领域的范围和关系的类别。现阶段,基于深度学习的关系抽取研究集中于预定义关系抽取。
基于深度学习的关系抽取方法常用的数据集有 ACE关系抽取任务数据集 、 SemEval2010 Task 8数据集 、 NYT2010数据集 等.
ACE关系抽取任务数据集 :ACE2005关系抽取数据集包含599篇与新闻和邮件相关的文档,其数据集内包含7大类25小类关系。
SemEval2010 Task 8数据集 :该数据集包含9种关系类型,分别是Compoent-Whole、Instrument-Agency、Member-Collection、Cause-Effect、Entity-Destination、Content-Container、Message-Topic、Product-Producer和Entity-Origin。 考虑到实体之间关系的方向以及不属于前面9种关系的“Other”关系,共生成19类实体关系。其中训练数据 8000个,测试数据2717个。
NYT2010数据集 是Riedel等人在2010年将Freebase知识库中的知识“三元组”对齐到“纽约时报”新闻中得到的训练数据。该数据集中,数据的单位是句包,一个句包由包含该实体对的若干句子构成。其中,训练数据集从《纽约时报》2005—2006年语料库中获取,测试集从2007年语料库中获取。
基于深度学习的关系抽取方法模型构建的重点在于利用不同神经网络的特点来抽取样本的特征,以学习样本的向量表示。在学习过程中,根据所用的神经网络基本结构的不同,可将基于深度学习的关系抽取方法分为 基于递归神经网络(recursive neural network,Rec-NN)的方法 、 基于卷积神经网络的方法 、 基于循环神经网络(recurrent net neural net-work,RNN)的方法 和 基于混合网络模型的方法 四类。
基于递归神经网络的关系抽取方法 首先利用自然语言处理工具对句子进行处理,构建特定的二叉树,然后解析树上所有的相邻子节点,以特定的语义顺序将其组合成一个父节点,如下图3所示。这个过程递归进行,最终计算出整个句子的向量表示。向量计算过程可以看作是将句子进行一个特征抽取过程,该方法对所有的邻接点采用相同的操作。
由于句子含义跟单词出现的顺序是相关的,因此关系抽取可以看作是一个时序学习任务,可以使用循环神经网络来建模。
基于循环神经网络的方法 在模型设计上使用不同的循环神经网络来获取句子信息,然后对每个时刻的隐状态输出进行组合,在句子层级学习有效特征。在关系抽取问题中,对每一个输入,关系的标记一般只在序列的最后得到。Zhang等首次使用双向循环神经网络来进行关系抽取,提出了BRNN模型。如下图7 所示,在双向循环神经网络中某一时刻的输出不仅依赖序列中之前的输入,也依赖于后续的输入。
为了更好地抽取句子中的特征,研究人员 使用递归神经网络、卷积神经网络与循环神经网络3种网络及其他机器学习方法进行组合建模来进行关系抽取 。
Vu等提 出 了 基 于 文 本 扩 展 表 示 的ECNN和基于链接的UniBRNN模型 ,将每个神经网络得到的多个结果根据投票机制得到关系的最终抽取结果。
Xiao等将 注意力机制引入一个多级的循环神经网络 ,该方法使用文本序列作为输入,根据标记实体的位置将句子分为5部分,使用同一个双 向LSTM网络在3个子序列上独立学习,然后引入词层级的注意力机制关注重要的单词表示,分别得到子序列的向量表示;随后,使用双向RNN网络进一步抽取子序列和实体的特征,并再次使用注意力机制将其转换成句子的最终向量表示,并送入到分类器中。
Nguyen等将 传统基于特征的方法(log-linear模型)、卷积神经网络方法和循环神经网络方法使用集成、投票等机制进行组合 。
zhang等提出 在双向LSTM 的基础上叠加注意力机制 ,以及使用卷积神经网络层获取句子的表示,再送入到一个全连接层和softmax层进行分类。
在联合学习问题上,Zheng等 使用递归神经网络和卷积神经网络组合来进行联合学习 ,也是一种共享底层网络参数的方法。
[1]庄传志,靳小龙,基于深度学习的关系抽取研究综述[J].中文信息学报,2019,33(12):1-18.
更多自然语言处理相关知识,还请关注 AINLPer公众号 ,极品干货即刻送达。
第十七篇:信息抽取Information Extraction
目录
信息抽取
• 根据下面这句话:
‣ “Brasilia, the Brazilian capital, was founded in 1960.”
• 得到:
‣ capital(Brazil, Brasilia)
‣ founded(Brasilia, 1960)
• 主要目标:将文本转化为结构化数据
应用
• 股票分析
‣ 从新闻和社交媒体中收集信息
‣ 将文本汇总为结构化格式
‣ 决定是否以当前股价买入/卖出
• 医学研究
‣ 从有关疾病和治疗的文章中获取信息
‣ 决定为新患者申请哪种治疗
如何?
• 两个步骤:
‣ 命名实体识别 (NER):找出“Brasilia”和“1960”等实体
‣ 关系抽取:使用上下文查找“Brasilia”和“1960”(“founded”)之间的关系
IE 中的机器学习
• 命名实体识别(NER):序列模型,例如RNN、HMM 或CRF。
• 关系提取:主要是分类器,二元或多类。
• 本讲座:如何构建这两个任务以应用序列标记器和分类器。
大纲
• 命名实体识别
• 关系抽取
• 其他 IE 任务
命名实体识别
典型实体标签
• PER:人物、人物
• ORG:公司、运动队
• LOC:地区、山脉、海洋
• GPE:国家、州、省(在某些标签集中,这被标记为 LOC)
• FAC:桥梁、建筑物、机场
• VEH:飞机、火车、汽车
• 标签集依赖于应用程序:一些域处理特定实体,例如 蛋白质和基因
NER作为序列标记
• NE 标签可能不明确:
‣ “Washington” 可以是个人、地点或政治实体
• 做 POS 标记时的类似问题
‣ 合并上下文
• 我们可以为此使用序列标记器吗(例如 HMM)?
‣ 否,因为实体可以跨越多个标记
‣ 解决方法:修改标签集
IO 标记
• “I-ORG”代表一个实体(在本例中为 ORG)内部的令牌。
• 所有不是实体的令牌都获得“O”令牌(用于外部)。
• 无法区分:
‣ 具有多个标记的单个实体
‣ 具有单个标记的多个实体
IOB 标签
• B-ORG 代表 ORG 实体的开始。
• 如果实体具有多个单词,则后续标签表示为 I-ORG。
NER作为序列标记,继续
• 给定这样的标记方案,我们可以训练任何序列标记模型
• 理论上,可以使用 HMM,但首选 CRF 等判别模型
NER:特征
• POS 标签/句法块:许多实体是名词或名词短语。
• 地名录中的存在:实体列表,例如地名、人名和姓氏等。
NER 的深度学习
• 最先进的方法使用带有字符和单词嵌入的 LSTM(Lample 等人,2016 年)
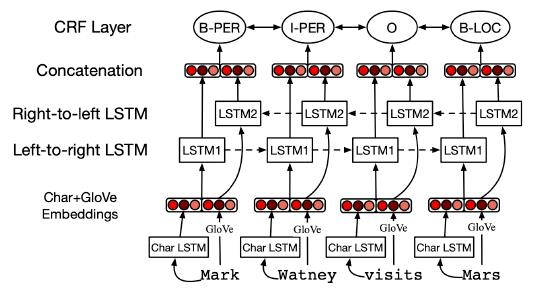
关系抽取
• 传统上被定义为三元组提取:
‣ 单位(美国航空、AMR Corp.)
‣ 发言人(Tim Wagner,美国航空公司)
• 关键问题:我们是否知道所有可能的关系?
方法
• 如果我们可以访问固定关系数据库:
‣ 基于规则
‣ 监督
‣ 半监督
‣ 远程监管
• 如果对关系没有限制:
‣ 无监督
‣ 有时称为“OpenIE”
基于规则的关系抽取
• NP0 比如 NP1 → 下义词(NP1, NP0)
• 词汇句法模式:高精度、低召回率、需要人工
有监督的关系抽取
• 假设一个带有注释关系的语料库
• 两个步骤。 首先,查找实体对是否相关(二元分类)
‣ 对于每个句子,收集所有可能的实体对
‣ 注释对被视为正例
‣ 未标注的对作为反例
• 其次,对于预测为正的对,使用多类分类器(例如 SVM)获得关系
半监督关系抽取
• 带注释的语料库的创建成本非常高
• 使用种子元组引导分类器
1. 给定种子元组: hub(Ryanair, Charleroi)
2. 在种子元组中查找包含术语的句子
• 以沙勒罗瓦为枢纽的廉价航空公司瑞安航空取消了所有周末离开机场的航班。
3.提取一般模式
• [ORG],使用 [LOC] 作为中心
4. 用这些模式寻找新的元组
• 枢纽(捷星、阿瓦隆)
5. 将这些新元组添加到现有元组并重复步骤 2
语义漂移
• Pattern: [NP] has a {NP}* hub at [LOC]
• Sydney has a ferry hub at Circular Quay
‣ hub(Sydney, Circular Quay)
• 从此元组中提取出更多错误模式……
• 应该只接受具有高置信度的模式
远程监管
• 半监督方法假设存在种子元组以挖掘新元组
• 我们可以直接挖掘新元组吗?
• 远程监督从范围中获取新元组
来源:
‣ DBpedia
‣ Freebase
• 生成海量训练集,可以使用更丰富的特征,并且没有语义漂移的风险
无监督关系提取(“OpenIE”)
• 没有固定或封闭的关系集
• 关系是子句; 通常有一个动词
• “United has a hub in Chicago, which is the headquarters of United Continental Holdings.”
‣“has a hub in”(United, Chicago)
‣ “is the headquarters of”(芝加哥,联合大陆控股)
• 主要问题:将关系映射到规范形式
评估
• NER:F1-实体级别的度量。
• 已知关系集的关系抽取:F1-measure
• 未知关系的关系抽取:更难评估
‣ 通常需要一些人工评估
‣ 这些设置中使用的海量数据集无法手动评估(使用样本)
‣ 只能获得(近似)精度,不能获得召回率。
其他 IE 任务
时间表达提取
• 锚定:“上周”是什么时候?
‣ “last week” → 2007−W26
• 规范化:将表达式映射到规范形式。
‣ July 2, 2007 → 2007-07-02
• 主要基于规则的方法
事件提取
• 与NER 非常相似,包括注释和学习方法。
• 事件排序:检测一组事件在时间线中是如何发生的。
‣ 涉及事件提取和时间表达式提取。
最后
• 信息提取是一个包含许多不同任务和应用的广阔领域
‣ 命名实体识别
‣ 关系抽取
‣ 事件提取
• 机器学习方法涉及分类器和序列标记模型。
今天就到这里了,感谢小伙伴们的观看,谢谢!有问题评论区交流!
以上是关于必读!信息抽取(Information Extraction)【关系抽取】的主要内容,如果未能解决你的问题,请参考以下文章