从5秒到1秒,核心业务优化思考
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从5秒到1秒,核心业务优化思考相关的知识,希望对你有一定的参考价值。
大家好,我是王有志,欢迎和我聊技术,聊漂泊在外的生活。快来加入我们的Java提桶跑路群:共同富裕的Java人。
业务背景
先做个简单的介绍,目前我供职于某保险公司,负责核心业务契约链路。契约简单点解释就是用户购买保险与保司签订保险合同的过程。
本文是站在保险业务系统的角度思考我司现有系统的架构设计,因此不会涉及到诸如索引优化,代码优化等技术细节。
宏观背景
过往保险业务的特点是高额低频,实践中更加关注数据的准确和安全。但近年来,随着疫情对线下销售行为的冲击,各保司不断在互联网发力,加之依托于支付宝,微信的蚂蚁保和微保带来的流量,保司陈旧笨重的业务系统在海量流量的冲击中就显得脆弱不堪了。
为了适应互联网低额高频的特点,以及某安在线在互联网为各保司做出的榜样,我司也对核心系统,以及面向客户的应用提出了新的要求,第一个目标便是“全面提速”。
实际上是?
冠冕堂皇的理由说完了,说点接地气的,某天领导找到我说:保单详情页面响应也太慢了吧,将近5秒才能有结果。这样,你们明天出个优化方案,一天开发,一天测试和上线,没问题吧?
听完,我第一时间想到的是,今天的桶装不下我的手办,现在就跑路有点不赶趟了,再看了看花呗后,不得不咬牙应了下来。

发现问题
其实问题已经暴露了出来,但修改起来却很让人头疼。因为在整个保险业务中,看似简单的查询,可能需要很长的链路,比如,用户从APP开始查询保单详情,前后要涉及到6个服务。

确定了整体的链路,我们开始梳理服务间的调用关系(时序图是个不错的选择):

整体上并不算很离谱,但是我们注意到了两点:
- 查询服务调用保单管理得到的是单张保单的全部数据
- 保单管理需要下载电子保单后才能生成公网链接
初步断定是这两点拖慢了整体响应时间。为了验证这个想法,我们跑了一轮测试,统计了链路中各关键环节的响应时间(ms):

结果很明显了,1s的左右的保单数据查询,将近2.5秒的文件下载,占了响应时间的70%,它们两个正是罪魁祸首。
解决办法
看完上面的分析过程,解决办法也就浮出水面了,拆分查询服务中的数据查询和电子保单查询,能解决50%的问题。其余50%中,查询保单数据又占据了40%,可以继续拆分成按需提供数据的接口。
到这里我产生了疑问,为什么APP会调用这么”巨大“的保单查询接口?
正常来说,这个接口应该是Web和内部服务调用的。而且在保险业务中,这样的接口势必会有大量的关联查询,面向客户的APP不应该,也不能调用它。
在我咨询了其他小伙伴后,我终于悟了。

不同系统有不同查询要求,每次大家都在这个接口新增内容,才造就了这么“巨大”的查询。
实际上查询服务冗余了保单的部分数据,能够满足APP日常使用需求,只有客户在经过多次交互后,才需要查询保单管理的数据。
当下,我们制定了一个初步的解决方案:
- 新增查询接口,Ctrl+C和Ctrl+V后,再屏蔽掉部分查询内容;
- 新增电子保单查询接口,还是Ctrl+C和Ctrl+V即可。
好了,领导的要求算是达到了,打完收工。
就这样?
如果就这么结束了,我的职业成长也就止步于此了。毕竟上面的只能称为办法,都算不上是方案。
我们需要的是一个真正的方案,“根治”这些问题,以及应对未来可能出现的状况。在此之前,先来审视下我们现有的架构。
保险业务架构
以下就是我司的保险业务系统架构(简化版)。

大部分金融公司在早期阶段,采用外购业务系统以达到快速上线的目的。逐渐稳定后,开始思考重构业务系统,达到去外包,灵活响应,快速迭代的的目的。
重构阶段大家都会参考现有业务系统的架构,并借鉴友商在互联网金融的行业实践,因此从整体架构上看大家高度相似,况且各CTO们也都是几家互相跳。

架构上的问题
首先和大家解释下我司的电商系统并不像某宝那样,除了基础的交易功能(真的很基础),它更多承载的是为前端提供聚合数据和适配的功能。
正是因为它承载的这些,目前电商有些让人头疼的问题:
- 电商中强耦合了各条业务线的逻辑,后端稍有风吹草动,电商就山洪爆发
- 为不同前端提供不同的适配接口,大量重复工作
电商的小伙伴对此早就苦不堪言了,他们也想尽早解脱,可是该怎么解脱呢?
新的方案
在分析完问题的当天,我们紧接着就开始讨论“一劳永逸”的方案了。
康威定律中提到了一点:
大的系统组织总是比小系统更倾向于分解。
单从架构上看,核心业务能拆也拆得差不多了,下一步的规划应该是利用领域驱动设计,由边缘服务开始重构,逐步完成整个核心的重构(农村包围城市,YYDS),厘清每个服务的职责,达到拥有清晰边界,合理设计的目的。
那么谁能拆?电商系统!
电商系统承载了本不属于它的工作,为前端聚合数据,提供接口,要拆分的话非它莫属。但是该怎么拆呢?
引入BFF
讨论中我们想到引入BFF为前端进行聚合,适配数据,降低电商系统与各后端服务的耦合,为电商系统瘦身。
BFF(Backends For Frontends,服务于前端的后端)是Sam Newman在2015年的文章《Backends For Frontends 》中提出的概念,Sam Newman也是《微服务设计》的作者。
说句题外话,近些年较火的领域驱动设计,是2003年Eric Evans提出的,思想都是远远领先于应用的。
言归正传,BFF简单来说就是为每个前端提供独立的“后端”服务,以适配不同的业务场景,降低系统间的耦合。
为什么做BFF?
Sam Newman文中提到:
For organisations using a large number of services however they can be essential, as the need to aggregate multiple downstream calls to deliver user functionality increases drastically.
大致意思是,对于使用大量微服务的系统来说,BFF是必不可少的,因为聚合多个服务调用,会导致需求开发的工作量急剧增加。
微软也有一篇关于BFF的文章《Backends for Frontends pattern》,文章中提到了4种使用BFF的情况:
A shared or general purpose backend service must be maintained with significant development overhead.
You want to optimize the backend for the requirements of specific client interfaces.
Customizations are made to a general-purpose backend to accommodate multiple interfaces.
An alternative language is better suited for the backend of a different user interface.
浅翻一下:
- 当你们需要大量工作来维护一个通用服务的后端时
- 需要针对不同的客户端进行定制功能开发时
- 为了适用于不同的接口,对通用后端进行定制时
- 某个客户端更适合使用另一种编程语言开发后端时
我司的电商系统,恰好踩中了前3条,看起来引入BFF非常有搞头。
做几个BFF?
摆在眼前的一个问题是,要为每个前端都做BFF吗?
这样虽然解决了电商系统的问题,但是也增加了运维,开发的工作量,同时还需要申请更多的服务器,成本也是不得不考虑的一个方面。
首先我们想到的是,ios和android的功能几乎一致,支付宝程序,微信小程序的功能也和它们大致相同,它们是不是可以共用BFF?
想法也得到了理论支持,Sam Newman文章中提到了Stewart Gleadow的建议:
One guideline that I really like from Stewart Gleadow (who in turn credited Phil Calçado and Mustafa Sezgin) was one experience, one BFF. So if the iOS and Android experiences are very similar, then it is easier to justify having a single BFF. If however they diverge greatly, then having separate BFFs makes more sense.
Stewart Gleadow建议,如果iOS和Android的使用体验非常相似,它们使用共同的BFF是合理的。那么我们初步的规划是,将电商系统的功能拆分出3个BFF,并为它们添加独立的网关:

这么规划的理由是:
- APP(iOS和Android),支付宝小程序和微信小程序有着几乎一致的功能;
- Web和H5的功能较为简单,大部分都是独立的变更,避免各系统的需求耦合;
- 开放平台的功能较为特殊,需要独立的BFF。
至于添加独立网关,是因为对鉴权,路由,数据统计等功能有不同的要求。
BFF真的解决了我们的问题吗?
我们再来回顾最初的问题--系统太慢了,造成这些的问题的原因是什么?
- 查询单张保单全量的数据,就好比你只需要看文章的摘要却给了你整本书;
- 查询数据的同时,连带查询了电子保单,进行文件IO的操作。
往小了说就是开发偷懒了,为了方便将所有数据都融合到同一个接口中。查询保障信息?调用保单查询接口;查询被保人信息?调用保单查询接口;查询受益人信息?全都可以调用保单查询接口。
往大了说就是随着保险行业不断深入互联网,传统保险行业的架构已经尽显疲态。
而BFF的引入可以为我们解决以下几点问题:
- 降低电商系统强耦合后端服务带来的系统复杂度,降低了变更风险
- 更加纯粹的电商系统,便于后期探索更多的保险自营业务的可能性
- 后端服务提供单一功能通用接口,BFF按需使用,避免了大而全带来的性能问题
- BFF完成聚合,适配,屏蔽前后端变化,实现快速响应功能迭代
特别是,引入BFF后前后端互为黑盒,对于部分前端的交互改版,后端完全可以不参与。
那么,Sam Newman,代价是什么?
世界上没有完美的的架构设计方案,每次新架构设计的引入都会带来新的问题,那么BFF带来了什么问题?
显而易见的问题是,BFF的引入并没有解决业务的复杂度,只是转移到了BFF层。
其次,引入新的服务,会降低全链路的可靠性,同时也带来了更高的网络延迟风险。
最后就是,开发成本,运维成本和硬件成本的增加。
到底做不做BFF?
在这点上,我们并没有太多的疑虑,BFF是肯定要做的,因为对我们来说,收益远高于成本。
开发成本,运维成本以及硬件成本,说白了就是Money。可靠性的话,我们有一套较为成熟的异地多活和同城灾备方案,也无需过多担心。
最后就是复杂度的问题,实际上对我们来说,引入BFF确确实实降低了电商的复杂度。至于BFF的复杂度,我们会结合这些年的实践经验,尽可能避免之前由业务需求带来的复杂度。
结语
好了,到这里我们已经初步拟定了后续的优化方案,至于技术实现就是另外一件事了,里面还牵扯到前后端谁来做BFF的问题,不过这些是后话了。
最后就是写PPT汇报了,领导听完非常高兴,当即要求我们修改OKR,争取年底能上线。并说道,你们好好干,明年我换辆新车。
推荐阅读
- Sam Newman - Backends For Frontends
- Backends for Frontends pattern - Azure Architecture Center | Microsoft Learn
- 微服务设计 (豆瓣)
- 人月神话(40周年中文纪念版) (豆瓣)
性能优化从30秒到0.6秒,百万级数据存储优化
“性能优化就像挤出海绵中的水,能挤出多少,主要取决于海绵中的水分有多少”

@图片:2022年9月拍摄于北京中关村 @摄影师:刘先生
01
—
背景介绍
有这样一种业务场景,业务计算完成之后,会产生上百万的数据,而这百万级的数据如何入库保存,成了让人头疼的问题。
数据库是MySql,由于数据库超时时间限制和单次提交的数据量的限制,百万级数据不可能一次性入库,于是采用分批提交的方式,尽管数据能够成功入库保存,但时间慢的有些让人难以接受。本地开发主机由于程序和数据库在同一台电脑,硬盘是固态硬盘,保存耗时30秒,服务器由于网络及硬盘速度的影响,百万数据保存耗时在2分钟左右。
下面分享一下在不改变硬件及现有基础技术框架的前提下,仅靠修改代码逻辑,如何将百万数据保存耗时降到0.6秒,速度提升50倍,内存减少50%。
02
—
处理逻辑
第一步:合并数据
这个问题的本质是:数据量大,而优化的首个出发点是,如何减少数据量。按照这个思路,将数据按照数据主体进行汇总合并,多条数据合并成一条,以JSON形式,存储在一个字段中,减少入库数据量,最终,数据条数降低了100倍,现在需要处理的就是万级数据的入库问题,问题难度一下子降低了。
如下图所示,进行数据合并之后,BenchmarkDotNet测试结果,平均耗时从27.6秒降到4.6秒。

第二步:压缩数据,减少数据大小
经过上一步数据合并之后,数据的数量减少了,但数据空间大小并没有改善,这百万数据占用空间在100M左右,这一步从减小数据空间的角度,采用GZip压缩JSON数据,减少网络传输,及数据磁盘写入压力。
从下图的测试结果看,执行效率略有提升,重要的是数据大小从100M减低到30M,减少70%空间占用。
第三步:自定义序列化
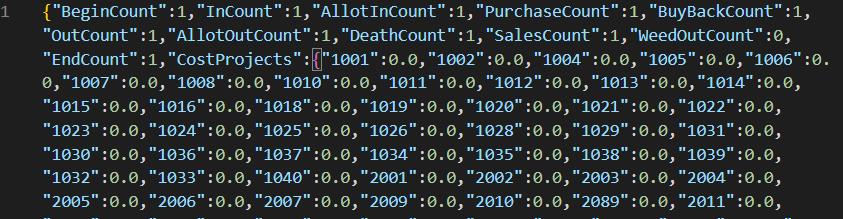
JSON格式是最常用的一种序列化格式,但是否是最好的,考虑到具体的业务场景,是否可以用一种更简单的序列化格式进行取代呢,在这一步中,便进行了一次尝试,由于数据都是key-value形式,而value都是值类型,自定义序列化也变得非常简单。
JSON序列化后的数据
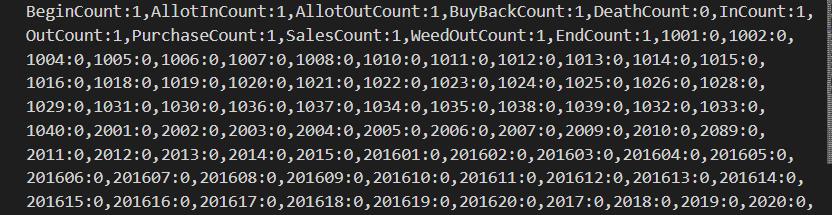
自定义序列化的数据
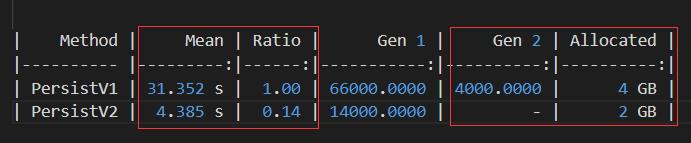
采用自定义序列化比采用JSON序列化,数据空间减少17%,尽管处理速度并没有明显提升,但内存耗用降低了50%。如下图所示

第四步:优化反射性能
上一步自定义序列化的过程中使用到了反射,由于数据量大,反射的性能问题被放大,这一步采用委托优化反射性能。
相较于上一步,速度提升近1倍,但内存耗用也增加了1倍,如下图

第五步:多线程并行处理
经过以上几步,执行速度降到了2秒,但这个速度我依然不够满意,于是祭出性能优化的终极杀器:多线程处理。有关多线程编程可以参考我之前的文章。
至此:处理速度为0.59秒,性能提升近50倍(49.23倍)内存占用减少50%。

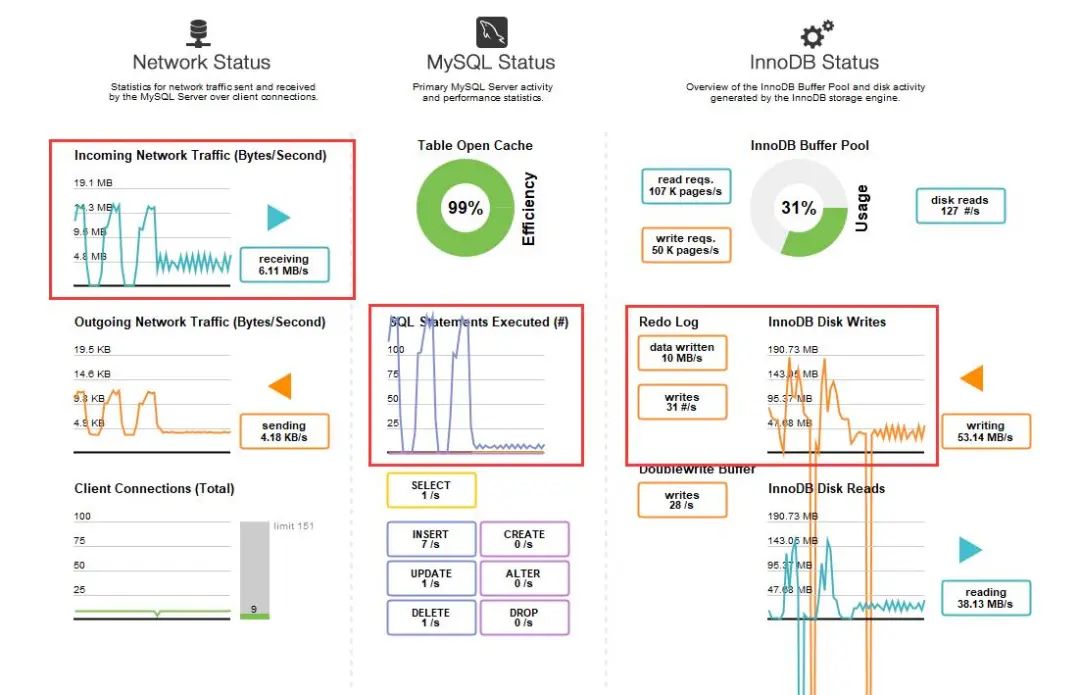
用一张MySql数据库仪表盘的截图,直观展示两段逻辑执行时的性能差异:
03
—
思路总结
1.减少数据数量:合并数据项
2.减小数据空间:GZip压缩
3.优化反射性能:创建属性访问委托,提升属性读写速度
4.多任务并行:信号量控制并发数量,加锁控制临界资源访问,留意多线程下异常处理,任务取消
04
—
再啰嗦几句
起初优化的目标是性能提升100倍,显然有点高了,最终提升了50倍,当然目前还有一定优化空间,比如:有些小伙伴可能已经看到了,计算结果数据大部分的是0,这些为0的数据,其实是不需要保存的,这样即可以进一步减小数据量。
另外考虑到数据增量,每次有几百万数据入库,一年产生的数据将近5亿,这样大的数据量,在MySql中处理压力是很明显的,因此,引入分布式数据库才是长久的解决办法。
相关阅读:
喜欢此内容的朋友可以点赞,转发,关注
以上是关于从5秒到1秒,核心业务优化思考的主要内容,如果未能解决你的问题,请参考以下文章
从20秒到0.5秒:一个使用Rust语言来优化Python性能的案例