开源网络组件总结(kubernetes相关)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了开源网络组件总结(kubernetes相关)相关的知识,希望对你有一定的参考价值。
一、Flannel
作用:1,协助Kubernetes给每个Node上的Docker容器分配互不冲突的IP地址。
2,在这些IP地址之间建立一个覆盖网络(Overlay Network),通过这个覆盖网络,将数据包原封不动地传递到目标容器。
原理图

原理:1创建flannel0的网桥连接docker0和flanneld服务进程,利用修改Docker的启动参数--bip分配地址互不冲突的地址段。
2flanneld进程利用etcd来管理可分配的IP地址段资源,同时监控etcd中每个Pod的实际地址,在内存中建立一个Pod节点路由表;它下联docker0和物理网络,使用Pod节点路由表,将docker0发给它的数据包包装起来,用物理网络投递到目标flanneld上。
3Flannel之间的底层通信协议可选UDP,VxLan,AWS VPC等多种方式,通过源flanneld封包,目标flanneld解包传递原始数据。
优点:完美地实现了对Kubernetes网络的支持:自动建立覆盖网络;自动通过etcd感知Kubernetes的Service来动态维护自己的路由表。
缺点:1.引入多个网络组件,会引入延时损耗。2默认采用UDP协议,UDP本身非可靠协议,虽然内部封装数据为TCP,但在大流量、高并发场景下需要反复测试。
二、Open vSwitch
是开源虚拟交换软件,Kubernetes主要利用GRE/VxLAN实现互通,就要就是建立L3到L3的隧道。

步骤:1.为了避免Docker创建的docker0地址冲突,先将docker0网桥删除,然后手动建立Linux网桥并分配地址范围。
2.建立Open vSwitch的网桥ovs,使用ovs-vsctl给ovs增加gre端口,将gre端口目标NodeIP地址设为对端的IP地址。对每一对端都需要操作,大型集群最好做自动话脚本。
3.将ovs的网桥作为网络接口,加入Docker的网桥上(docker0)。
4.重启ovs网桥和Docker的网桥,并互相添加Docker网桥的路由。
通讯过程:容器数据包到自身docker0网桥,再用ovs网桥发到另一端的docker0。ovs网络间通过GRE/VxLAN隧道传输数据。
优势:作为开源虚拟交换机软件相对成熟,支持各类协议,通过了OpenStack等项目的考研。
缺点:相对于Flannel可以动态维护网络,使用OVS很多需要手工完成;引入了一些额外的通讯开销,如果对网络依赖严重的应用,需要评估对业务的影响。
三、Calico
Calico是一个基于BGP的纯三层的网络方案,与OpenStack、Kubernetes、AWS、GCE等云平台都能够良好地集成。Calico在每个计算节点都利用Linux Kernel实现了一个高效的vRouter来负责数据转发。每个vRouter都通过BGP1协议把在本节点上运行的容器的路由信息向整个Calico网络广播,并自动设置到达其他节点的路由转发规则。Calico保证所有容器之间的数据流量都是通过IP路由的方式完成互联互通的Calico节点组网时可以直接利用数据中心的网络结构(L2或者L3)不需要额外的NAT、隧道或者Overlay Network,没有额外的封包解包,能够节约CPU运算,提高网络效率,如图所示
.

Calico在小规模集群中可以直接互联,在大规模集群中可以通过额外的BGP route reflector来完成,如图所示。

此外,Calico基于iptables还提供了丰富的网络策略,实现了Kubernetes的Network Policy策略,提供容器间网络可达性限制的功能。
Calico的系统架构如图所示

Calico的主要组件如下
◎ Felix:Calico Agent,运行在每个Node上,负责为容器设置网络资源(IP地址、路由规则、iptables规则等),保证跨主机容器网络互通。
◎ etcd:Calico使用的后端存储。
◎ BGP Client:负责把Felix在各Node上设置的路由信息通过BGP协议广播到Calico网络。
◎ Route Reflector:通过一个或者多个BGP Route Reflector来完成大规模集群的分级路由分发。
◎ CalicoCtl:Calico命令行管理工具。
部署:
(1)修改Kubernetes服务的启动参数,并重启服务.
设置Master上kube-apiserver服务的启动参数:--allowprivileged= true(因为calico-node需要以特权模式运行在各Node上)。
设置各Node上kubelet服务的启动参数:--networkplugin= cni(使用CNI网络插件)。
(2)创建Calico服务,主要包括calico-node和calico policy controller。需要创建的资源对象如下.
创建ConfigMap calico-config,包含Calico所需的配置参数。
创建Secret calico-etcd-secrets,用于使用TLS方式连接etcd。
在每个Node上都运行calico/node容器,部署为DaemonSet.
在每个Node上都安装Calico CNI二进制文件和网络配置参数 (由install-cni容器完成)。
部署一个名为calico/kube-policy-controller的Deployment,以对 接Kubernetes集群中为Pod设置的Network Policy。 从Calico官网下载Calico的YAML配置文件,下载地址为 http://docs.projectcalico.org/v3.5/gettingstarted/ kubernetes/installation/hosted/calico.yaml,该配置文件包括启动Calico所需的全部资源对象的定义.
Kubernetes学习总结(13)—— Kubernetes 各个组件的概念
Node
Node 很好理解,就是服务实际运行的实例, 可以是一台物理机, 也可以是一台 VM 虚拟机。
Pod
docker 我们都知道是容器,而 Pod 其实就类似于 docker-composer , 多个的相关联的容器组成了一个 Pod. 比如有一个 nginx 容器和一个 php-fpm 的容器, 他们两个就可以组合为一个Pod。
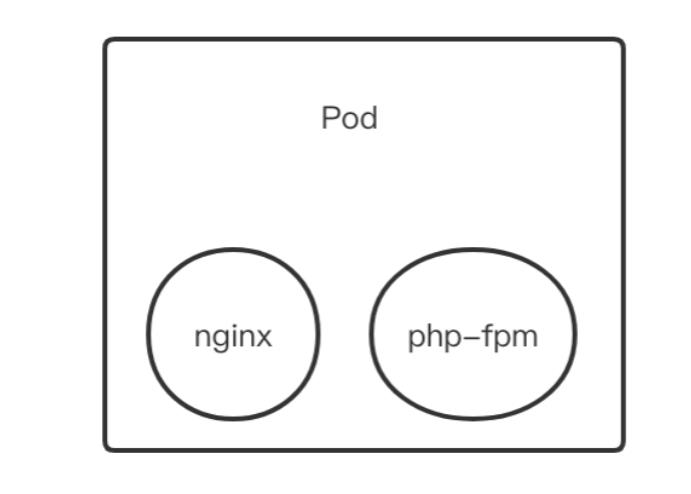
在同一个 Pod 中, 不同容器共享网络栈与存储卷。也就是说, nginx 访问 php-fpm 可以直接使用 localhost:9000 即可, 也就是说, 一个 Pod 中启动两个容器, 都占用 80 端口, 是无法成功启动的. 共享是通过Pause容器实现的。
Pod 控制器
在 Kubernetes中, Pod 是资源的最小单位了. 而这一堆控制器, 就是用来对 Pod 进行自动管理的。
- 管理Pod的数量
- 实现Pod的弹性伸缩
- 监控Pod的状态
- 定时启动并释放Pod
为了实现不同的需求, 出现了不同的 Pod 控制器. 以下控制器只是实现了不同的需求而已,本质上都是用来对最小单元即 Pod 的控制。
ReplicationController#
对 Pod 数量进行管理. 确保 Pod 数量保持在用户定义的数量. (若容器异常退出, 自动创建新的 Pod 若数量多了, 也会自动回收. ) 不过现在建议使用 ReplicaSet 替代ReplicationController。

ReplicaSet#
与 ReplicationController 的功能差不多, 额外增加了集合式 selector 的支持(标签选择器)。虽然 ReplicaSet 可以单独使用, 但建议用 Deployment 进行管理。
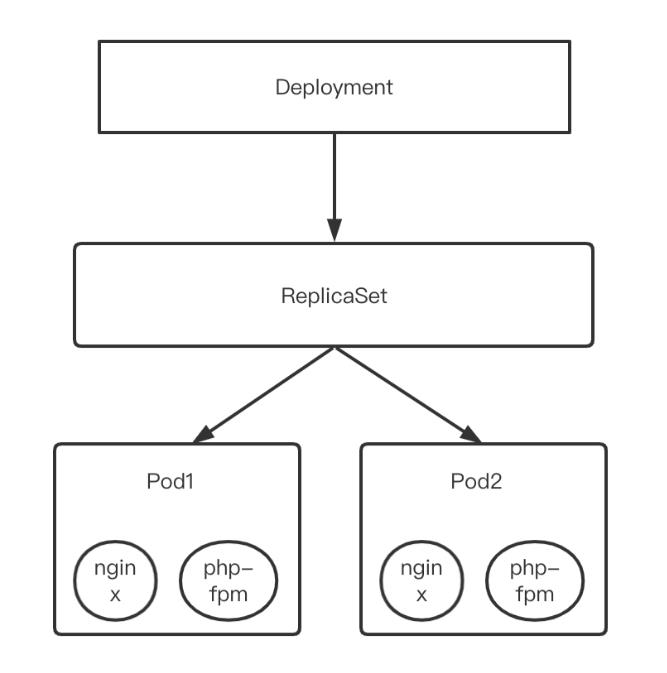
Deployment#
Deployment 不会直接管理 Pod, 而是通过管理 ReplicaSet,再经由 ReplicaSet 管理 Pod。Deployment 处理了很多 ReplicaSet 不支持的额外操作. 如:
- rolling-update (滚动更新) 和回滚
- 自动伸缩(扩容和缩容)
- 暂停和继续
Deployment 热更新就是通过新建一个 ReplicaSet 逐渐减少原来 ReplicaSet 中 Pod 数量并增加新 ReplicaSet 中 Pod 数量来实现的,回滚则反之。
HorizontalPodAutoscaler#
HPA 也不会直接管理 Pod,而是管理 Deployment 或者 ReplicaSet。HPA 可以检测 Pod 资源使用率。可以实现这样的场景:当Pod CPU 使用率大于 80 则自动新建,否则自动释放同时启动的 Pod 数量最多 30 个,最少 5 个即实现服务的水平扩展。
StatefulSet#
StatefulSet 是为了解决有状态服务的. 上面的控制器都是无状态的. StatefulSet 可以实现如下功能:
- 稳定的持久化存储. 当 Pod 动态调整后能够访问到相同的持久化数据. 基于 PVC 实现
- 稳定的网络标识. Pod 动态调整后 PodName HostName 不变. 基于 Headless Service实现.
- 有序部署. 既前一个 Pod 启动成功, 才会创建下一个 Pod. 解决服务依赖的问题. 基于 init containers 实现.
- 有序删除. 有序部署的反向操作.
DeamonSet#
可以确保所有(或指定的一部分) Node 都运行一个 Pod 副本. 当新 Node 加入集群时自动新增对应的 Pod, 当 Node 从集群移除时, 对应的 Pod 也会被回收。这种运行在 Node 中的 Pod 有什么用呢? 比如资源监控, 再比如日志收集等等.
Job#
批处理任务. kubernetes可以保证此任务的一个或多个Pod成功结束, 若任务失败, kubernetes会自动重启, 直到成功.
CronJob#
Job的crontab版本. 基于时间管理的Job. 是通过在特定时间创建Job实现的. 可以在指定时间运行一次任务, 或者周期性的在指定时间运行.
服务发现及负载均衡
Service#
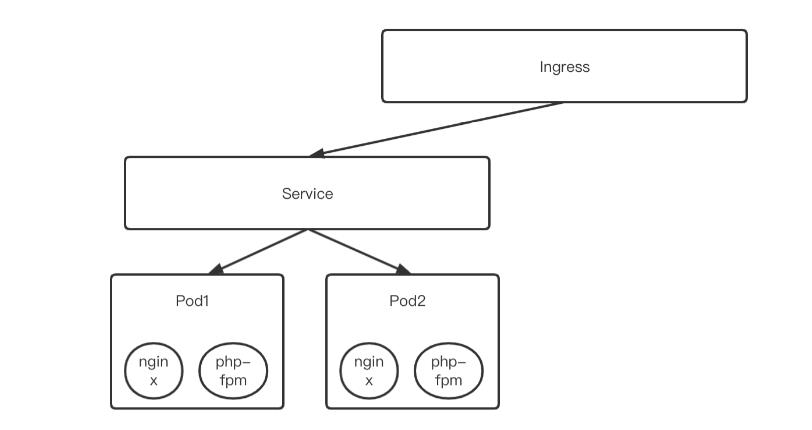
Pod 控制器只是对 Pod 的管理, 比如在一个 Deployment 中运行了 5 个 Pod, 如果外部访问 Pod 服务时写的是每一个 Pod 的地址, 当 Pod 动态伸缩的时候, 维护这些地址就是一个让人头大的问题了.而 Service 就是为了解决这个问题而出现的. 它为一组 Pod 提供了一个统一对外的接口, 外部访问 Service 再经由 Service 将请求发给 Pod, 而不需要关心 Pod 的数量、启动、释放等等。同时 Service 还能够对流量进行负载均衡。

Ingress#
因为 Service 是四层负载均衡, 也就是说只能代理到 IP 层, 无法实现像 nginx 一样根据不同域名不同路径进行负载均衡. 为了解决这个问题而提出了 Ingress, Ingress 是独立与其他服务对请求进行转发的. 可以将其理解为 Service 的 Service。一般来说, 通过 Service 对 Pod 进行内部代理, 然后通过 Ingress 将请求转发给 Service. Ingress 也有不同的实现, 而其中比较常用的就是 ingress-nginx 了,其配置文件类似与 nginx. 由官方维护的. 启动命令为:
kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.1.0/deploy/static/provider/cloud/deploy.yaml官方文档:https://kubernetes.github.io/ingress-nginx/
以上是关于开源网络组件总结(kubernetes相关)的主要内容,如果未能解决你的问题,请参考以下文章