# yyds干货盘点 # 手把手教你抖音系列视频批量下载器开发
Posted Python进阶者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了# yyds干货盘点 # 手把手教你抖音系列视频批量下载器开发相关的知识,希望对你有一定的参考价值。
程序使用演示
大家好,我是小小明。这里开发了一个抖音视频下载器,打开效果如下:

如果本地的谷歌游览器之前从来没有访问过抖音主页,点击开始下载按钮会有如下输出:

此时我们只需要点击 访问抖音主页,程序则会使用本地的谷歌游览器访问抖音主页。再次点击下载按钮:

可以看到该视频是一个合集视频:

那么程序只需要勾选第一个选项即可下载整个合集:
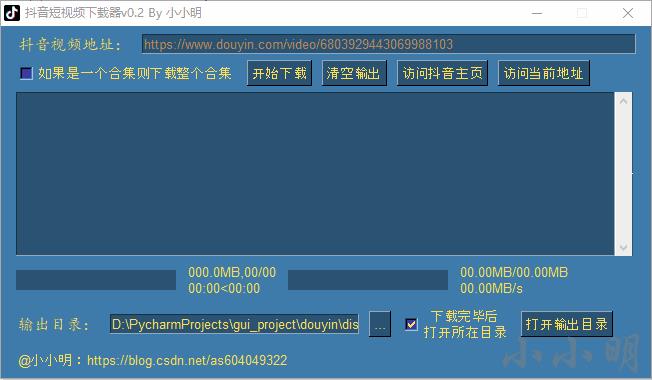
这样一次性就将整个合集都下载下来了:

开发流程
首先根据上一篇文章:提取谷歌游览器Cookie的五重境界
读取谷歌游览器安装的位置和本地抖音相关的cookie:
"""
小小明的代码
CSDN主页:https://blog.csdn.net/as604049322
"""
__author__ = 小小明
__time__ = 2022/1/23
import base64
import json
import os
import sqlite3
import winreg
import win32crypt
from cryptography.hazmat.primitives.ciphers.aead import AESGCM
def load_local_key(localStateFilePath):
"读取chrome保存在json文件中的key再进行base64解码和DPAPI解密得到真实的AESGCM key"
with open(localStateFilePath, encoding=u8) as f:
encrypted_key = json.load(f)[os_crypt][encrypted_key]
encrypted_key_with_header = base64.b64decode(encrypted_key)
encrypted_key = encrypted_key_with_header[5:]
key = win32crypt.CryptUnprotectData(encrypted_key, None, None, None, 0)[1]
return key
def decrypt_value(key, data):
"AESGCM解密"
nonce, cipherbytes = data[3:15], data[15:]
aesgcm = AESGCM(key)
plaintext = aesgcm.decrypt(nonce, cipherbytes, None).decode(u8)
return plaintext
def fetch_host_cookie(host):
"获取指定域名下的所有cookie"
userDataDir = os.environ[LOCALAPPDATA] + r\\Google\\Chrome\\User Data
localStateFilePath = userDataDir + r\\Local State
cookiepath = userDataDir + r\\Default\\Cookies
# 97版本已经将Cookies移动到Network目录下
if not os.path.exists(cookiepath) or os.stat(cookiepath).st_size == 0:
cookiepath = userDataDir + r\\Default\\Network\\Cookies
# print(cookiepath)
sql = f"select name,encrypted_value from cookies where host_key like %.host"
cookies =
key = load_local_key(localStateFilePath)
with sqlite3.connect(cookiepath) as conn:
cu = conn.cursor()
for name, encrypted_value in cu.execute(sql).fetchall():
cookies[name] = decrypt_value(key, encrypted_value)
return cookies
def get_chrome_path():
try:
key = winreg.OpenKey(winreg.HKEY_CLASSES_ROOT, r"Chromehtml\\Application")
path = winreg.QueryValueEx(key, "ApplicationIcon")[0]
chrome_path = path[:path.rfind(",")]
return chrome_path
except FileNotFoundError as e:
return
if __name__ == __main__:
print(fetch_host_cookie("douyin.com"))
print(get_chrome_path())
有了这个工具类,我们就不再需要使用selenium。
然后是视频解析的核心代码如下:
def get_video_url(url, cookies):
headers =
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36",
"referer": "https://www.douyin.com"
res = requests.get(url, headers=headers, cookies=cookies)
if res.status_code == 200:
RENDER_DATA, = re.findall(
r<script id="RENDER_DATA" type="application/json">([^<>]+)</script>, res.text)
data = json.loads(unquote(RENDER_DATA))
key = 8 if url.find("collection") != -1 else 34
try:
detail = data[key][aweme][detail]
title = detail[desc]
except Exception as e:
print(f"url无效,报错的key:", e)
return
if not title:
title, = re.findall("<title[^>]+>\\s*([^>]+)\\s*</title>", res.text)
video_url = urljoin(url, detail[video][playApi])
collection_urls = set(re.findall("//www.douyin.com/collection/\\d+/\\d+", res.text))
collection_urls = [urljoin("https://www.douyin.com", url) for url in collection_urls]
collection_urls.sort(key=lambda s: int(s[s.rfind("/") + 1:]))
collection_title = re.findall("<h2 [^>]+>([^<>]+)</h2>", res.text)[0]
return video_url, title, collection_urls, collection_title
else:
print(视频链接请求失败!!!)
视频下载的核心代码:
def download_video(video_url, title, folder):
start_time = time.time()
res = requests.get(url=video_url, stream=True)
done_size, total = 0, int(res.headers[content-length])
chunk_size = 1024 * 1024
title = format_filename(title)
file_size = round(int(res.headers[content-length]) / 1024 / 1024, 2)
basename = f"title.mp4"
filename = f"folder/title.mp4"
if os.path.exists(filename):
print(basename, "已存在,跳过...")
return
print("-----------------------------------")
print(f开始下载文件:basename\\n当前文件大小:file_sizeMB)
with open(filename, wb) as f:
for chunk in res.iter_content(chunk_size):
f.write(chunk)
done_size += len(chunk)
cost_time = time.time() - start_time
yield done_size, cost_time, total
# print(f"进度:done_size / total:.2%,done_size / cost_time / 1024 / 1024:.2fMB/s")
cost_time = time.time() - start_time
print(f文件:basename 下载完成!\\n耗时:cost_time:0.2f 秒)
关于视频链接的分析,大家可以参考才哥的文章:
链接:https://mp.weixin.qq.com/s/NNVT6IH6dpT0rTeu1-oD6w
UI界面设计核心代码如下:
layout = [
[sg.Text(抖音视频地址:, font=("楷体", 12)),
sg.In(key=url, size=(70, 1), text_color="#bb8b59",
default_text="https://www.douyin.com/video/6803929443069988103")],
[sg.Checkbox(如果是一个合集则下载整个合集, key="download_collection", default=False),
sg.Button(开始下载),
sg.Button(清空输出),
sg.Button(访问抖音主页),
sg.Button(访问当前地址),
],
[sg.Output(size=(85, 10), key="out", text_color="#15d36a")],
[
sg.ProgressBar(1000, size=(20, 20), key=video_bar, bar_color=("#bb8b59", "#295273")),
sg.Text(000.0MB,00/00\\n00:00<00:00, key="message_video"),
sg.ProgressBar(1000, size=(20, 20), key=progressbar, bar_color=("#15d36a", "#295273")),
sg.Text(00.00MB/00.00MB\\n00.00MB/s, key="message")
],
[sg.Text(输出目录:, font=("楷体", 12)),
sg.In(size=(35, 1), key="save_dir"),
sg.FolderBrowse(..., target=save_dir, initial_folder="."),
sg.Checkbox( 下载完毕后 \\n打开所在目录, key="open_folder", default=True),
sg.Button(打开输出目录),
],
[sg.Text("@小小明:https://blog.csdn.net/as604049322"), ],
]
程序下载
该工具的完整代码和已打包的工具下载地址:
https://gitcode.net/as604049322/python_gui/-/tree/master/douyin

小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
以上是关于# yyds干货盘点 # 手把手教你抖音系列视频批量下载器开发的主要内容,如果未能解决你的问题,请参考以下文章