k8s版MongoShake数据迁移工具
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了k8s版MongoShake数据迁移工具相关的知识,希望对你有一定的参考价值。
说明
我们原有的 MongoDB 副本集集群部署在 k8s 上,后因业务需求,在 k8s 集群外使用三台虚拟机组建了一套相同架构的 MongoDB 副本集集群,现想将在k8s集群上mongoDB数据迁移到新的MongoDB集群里。
集群信息:
| mongodb-1:10.x.x.56 | mongodb-2:10.x.x.57 | mongodb-3:10.x.x.58 | 功能 |
|---|---|---|---|
| mongos:23000 | mongos:23000 | mongos:23000 | 路由服务,负责客户端的连接,并把任务分给shards,然后收集结果 |
| config server:24000 | config server:24000 | config server:24000 | 配置服务器,保存集群的元数据 |
| shard1:主:25001 | shard2:主:25002 | shard3:主:25003 | 分片:接受读写 |
| shard2:从:25002 | shard3:从:25003 | shard1:从:25001 | 副本集:备份数据 |
| shard3:仲裁:25003 | shard1:仲裁:25001 | shard2:仲裁:25002 |
MongoShake
Mongo-Shake由阿里云Nosql团队开发维护。Mongo-Shake是一个基于MongoDB的oplog的通用服务平台。它从源mongo数据库中获取oplog,并在目标mongo数据库中重放或发送到不同隧道的其他端。如果目标端是mongo数据库,即直接replay oplog,它就像一个同步工具,用于将数据从源MongoDB复制到另一个MongoDB,以建立冗余复制或双活复制。除了这种直接方式,还有其他隧道类型,如rpc、file、tcp、kafka。用户编写的接收器必须定义自己的接口以分别连接到这些隧道。用户还可以定义自己的可插入隧道类型。如果连接kafka等第三方消息中间件,消费者可以在pub/sub模块中灵活的异步获取订阅者数据。

更多有关MongoShake大家可以看下github,这里不再过多叙述。
下载 MongoShake 包
我们使用最简单的方式,直接在这里下载到最新的发行的包,免去编译的环节。
修改配置文件
对于MongoDB到MongoDB的同步需求,用户只需要修改collector.conf的配置文件。通常对于副本集的同步只需要配置两个:源mongodb的地址mongo_urls、目的mongodb的地址tunnel.address(与mongodb的url风格一致,db节点以逗号分割,没有用户名密码则不需要配置前缀username:password@),其余默认配置就行。如果有其他的需求再仔细阅读以下各个配置项信息。
以下我大概介绍一下我这边需求该如何进行配置,打开vim collector.conf:
# 同步模式,all表示全量+增量同步,full表示全量同步,incr表示增量同步。
# 原mongodb已不接收新写的数据
sync_mode = full
# 副本集:mongodb://username1:password1@primaryA,secondaryB,secondaryC
# 更改成自己的地址
mongo_urls = mongodb://root:test123@mongodb-cluster-0.mongodb-cluster.middle.svc.cluster.local:27017,mongodb-cluster-1.mongodb-cluster.middle.svc.cluster.local:27017,mongodb-cluster-2.mongodb-cluster.middle.svc.cluster.local:27017
# 更改成自己的地址
tunnel.address = mongodb://admin:test123@10.x.x.56:23000,10.x.x.57:23000,10.x.x.58:23000
退出,保存!
# 压缩文件
tar zcvf mongo-shake-v2.8.2.tgz mongo-shake-v2.8.2
Dockerfile文件
FROM ubuntu:18.04
LABEL maintainer="wutf@test.com"
WORKDIR /app
RUN apt-get update \\
&& apt-get install vim -y \\
&& rm -rf /var/lib/apt/lists/* \\
&& apt-get -y autoremove \\
&& apt-get clean
ADD mongo-shake-v2.8.2.tgz .
制作镜像:
docker build -t mongo-shake:v2.8.2 .
k8s deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: mongodb-migrate
spec:
selector:
matchLabels:
app: mongodb-migrate
replicas: 1
template:
metadata:
labels:
app: mongodb-migrate
spec:
containers:
- name: mongodb-migrate
image: mongo-shake:v2.8.2
command:
- /app/mongo-shake-v2.8.2/collector.linux
args:
- -conf=/app/mongo-shake-v2.8.2/collector.conf
- -verbose=1
#- sleep
#- "3600000"
resources:
limits:
cpu: 4
memory: 6Gi
requests:
cpu: 2
memory: 4Gi
数据迁移
执行yaml:
kubectl apply -f mongo-migrate.yaml
如果出现如下问题:

可能是目标mongodb内存资源不足,副本进程宕掉了,这里不进行深度分析,可以使用netstat -lnp|grep xxx查看服务进程。停止迁移服务。
注意事项
-
数据迁移过程中会占用一部分 mongodb 主机资源,尽量在业务低峰迁移。
-
做好数据备份。
-
最好保证mongodb主机资源充足。
参考文档
mongoshake实现mongodb数据同步
前言
MongoShake是阿里云以Golang语言编写的通用平台型服务工具,它通过读取MongoDB的Oplog操作日志来复制MongoDB的数据以实现特定需求。
MongoShake还提供了日志数据的订阅和消费功能,可通过SDK、Kafka、MetaQ等方式的灵活对接,适用于日志订阅、数据中心同步、Cache异步淘汰等场景。
官方地址:https://github.com/alibaba/MongoShake
使用场景
- MongoDB集群间数据的异步复制,免去业务双写开销(数据灾备);
- MongoDB集群间数据的镜像备份(当前1.0开源版本支持受限);
- 日志离线分析;
- 日志订阅;
- 数据路由,根据业务需求,结合日志订阅和过滤机制,可以获取关注的数据,达到数据路由的功能;
- Cache同步。日志分析的结果,知道哪些Cache可以被淘汰,哪些Cache可以进行预加载,反向推动Cache的更新;
- 基于日志的集群监控
基于mongoshake可以衍生出很多的场景,从而提供给开发者在架构设计中更多更灵活、更丰富的选择
搭建步骤
mongoshake本身的使用不难,这个参考官方的配置即可,主要是根据自身的业务场景做好配置文件中各个参数的配置即可达到目的,下面以mongoshake一个较为常用的场景,即使用mongoshanke完成2个mongodb复制集群之间的数据同步
环境准备
- 两台服务器(阿里云、腾讯云服务器或虚拟机)
- 提前规划相关的端口,并开放相关端口
- 提前下载mongodb以及mongoshake安装包,两台服务器均上传,本次mongodb版本为:mongodb-linux-x86_64-4.0.10.tgz,mongo-shake-v2.4.6.tar.gz

一、搭建mongodb复制集
选择其中一台服务器搭建一个mongodb的单机版复制集群,这里使用端口号区分,启动的时候启动多个实例即可(有条件的可以采用3个不同的服务器操作),按照下面的步骤依次执行即可:
1、创建3个目录
mkdir replications
cd replications
mkdir myrs_27017
mkdir myrs_27018
mkdir myrs_27019
2、在3个主目录下,分别创建data和log目录
mkdir data
cd data
mkdir db

在myrs_27017 ,myrs_27018 ,myrs_27019 3个目录下分别做同样的操作,
3、编辑mongod.conf配置文件
#数据保存路径
dbpath=/usr/local/soft/mongo/replications/myrs_27017/data/db
#日志保存路径
logpath=/usr/local/soft/mongo/replications/myrs_27017/log/mongod.log
#日志追加写入
logappend=true
#复制集名称
replSet=myrs
bind_ip=服务器IP(云服务器建议使用内网IP)
#mongo默认端口
port=27017
#操作日志容量
oplogSize=10000
noprealloc=true
#开启子进程
fork=true
在另外的myrs_27018 ,myrs_27019两个目录下做同样的操作,只需要分别修改下配置文件中的端口号即可
4、使用下面的命令依次启动3个不同的mongodb实例
进入mongodb的bin目录下,依次执行下面的命令
./mongod -f /usr/local/soft/mongo/replications/myrs_27017/mongod.conf
./mongod -f /usr/local/soft/mongo/replications/myrs_27018/mongod.conf
./mongod -f /usr/local/soft/mongo/replications/myrs_27019/mongod.conf
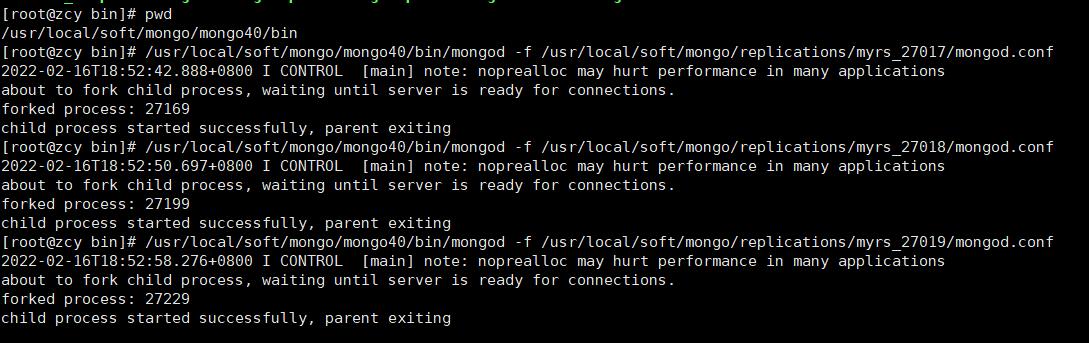
看到下面的信息表名启动成功

5、创建集群
使用mongo的shell登录到其中一个实例上,进入bin目录下,执行下面命令
./mongo --host 服务器IP(建议使用内网IP) --port 27017
6、执行数集群信息的初始化操作
使用下面的命令执行
cfg= _id:"myrs", members:[ _id:0,host:'服务器IP:27017',priority:1, _id:1,host:'服务器IP:27018',priority:2, _id:2,host:'服务器IP:27019',arbiterOnly:true];

再使用:rs.initiate(cfg); 命令完成集群初始化

执行完毕后,可以使用: rs.status() 查看集群各个节点信息,打印出的信息太长,就不放截图了,注意,执行完毕之后,当前节点会出现短暂的 secondary ,但是过一会儿就变成 primary了
7、将另外两个节点加入集群
在上一步的窗口下依次执行下面的命令,将两位2个mongo实例加入到集群中
rs.add("服务器IP:27018") #加入第一个从节点
rs.add("服务器IP:27019") #加入第二个仲裁节点
8、主节点上创建数据
在上一步的窗口下,即主节点上,给某个库的某个集合下插入一条数据

登录从节点,由于是复制集群,主节点上的数据必然会同步到从节点上,我们可以登陆进去查看是否同步成功
./mongo --host 服务器IP --port 27018

可以发现没有权限,默认情况下,从节点是没有读写权限的,需要做设置才行,可以在上面从节点的窗口执行下面的命令即可
rs.slaveOk()
执行完毕后,再次查询即可看到主节点上插入的数据了

以上就是基于单机模式下搭建一个伪复制集群的全部过程,将同样的操作在另外一个服务器上执行即可
在另一个集群上,我们在主节点上创建了下面一个test库,并在库下新建了一条数据

二、mongoshake配置
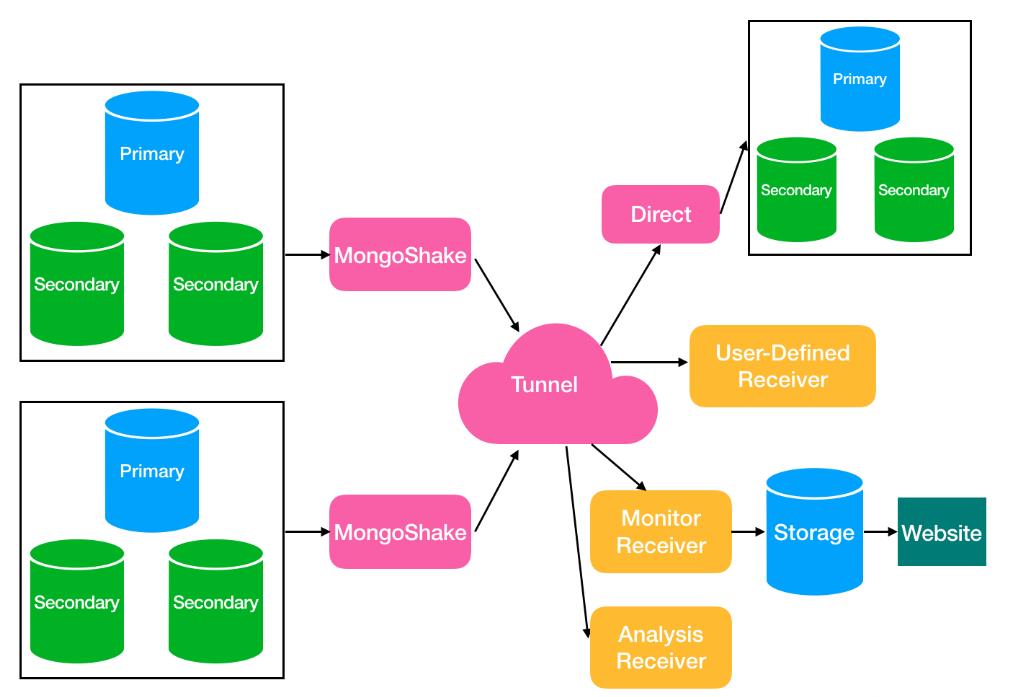
有了上面的两个复制集群,mongoshake的使用就变得非常简单了,mongoshake实现数据同步的基本原理是通过监听mongodb的oplog,解析其中的事件,从而完成数据的读取与写入
mongoshake常用的同步包括,增量同步、全量同步、增量+全量同步,下面从列举了mongoshake内部实现数据同步的业务机制

1、解压mongoshake包
2、进入解压后的目录编辑并配置 collector.conf文件
下面列举比较常用的几个配置
#源数据库地址,集群多个地址中间用逗号分割
mongo_urls = mongodb://源mongoIP:27017,源mongoIP:27018,源mongoIP:27019
# 通道模式。直接数据库到数据库
tunnel = direct
# 此处配置通道的地址,格式与mongo_urls对齐。【目标同步地址】
tunnel.address = mongodb://目标mongoIP:27017,目标mongoIP:27018,目标mongoIP:27019
# all 表示全量+增量,full表示仅全量,incr表示仅增量
sync_mode = all
# raw是默认的类型,其采用聚合的模式进行写入和
# 读取,但是由于携带了一些控制信息,所以需要专门用receiver进行解析。
# json以json的格式写入kafka,便于用户直接读取。
# bson以bson二进制的格式写入kafka。
tunnel.message = raw
其他更多高级配置柯参考官方详细说明进行了解,比如可以同步到kafka等
3、启动mongoshake服务
在主目录下,执行下述命令启动同步任务,并打印日志信息
./collector.linux -conf=collector.conf -verbose

模拟测试
mongoshake服务启动完毕后,这时可以去被同步的第一台服务器上检查数据是否同步成功

由于我们配置的是全量+增量的方式,因此服务一旦启动,数据就全部同步过去了

这时候再次去第二台服务器的test数据库下再次新增一条数据

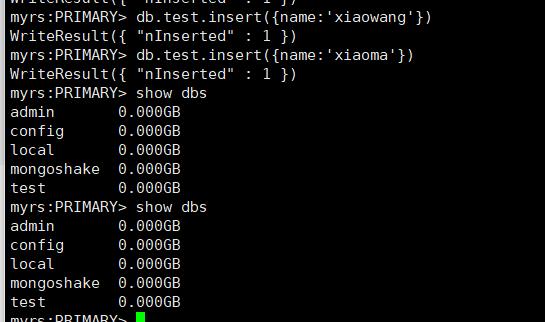
再返回到第一台机器上检查数据是否成功同步

可以看到,数据成功同步到第一台机器上了
以上是关于k8s版MongoShake数据迁移工具的主要内容,如果未能解决你的问题,请参考以下文章