如何用Python爬取出HTML指定标签内的文本?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何用Python爬取出HTML指定标签内的文本?相关的知识,希望对你有一定的参考价值。
我想只要其中<tr>下<td>标签所包含的文本信息,或者有什么办法只留下页面显示的内容,把标签符号之类的去掉?最好能给出代码,谢谢啦!
你好!
可以通过lxml来获取指定标签的内容。
#安装lxmlpip install lxml
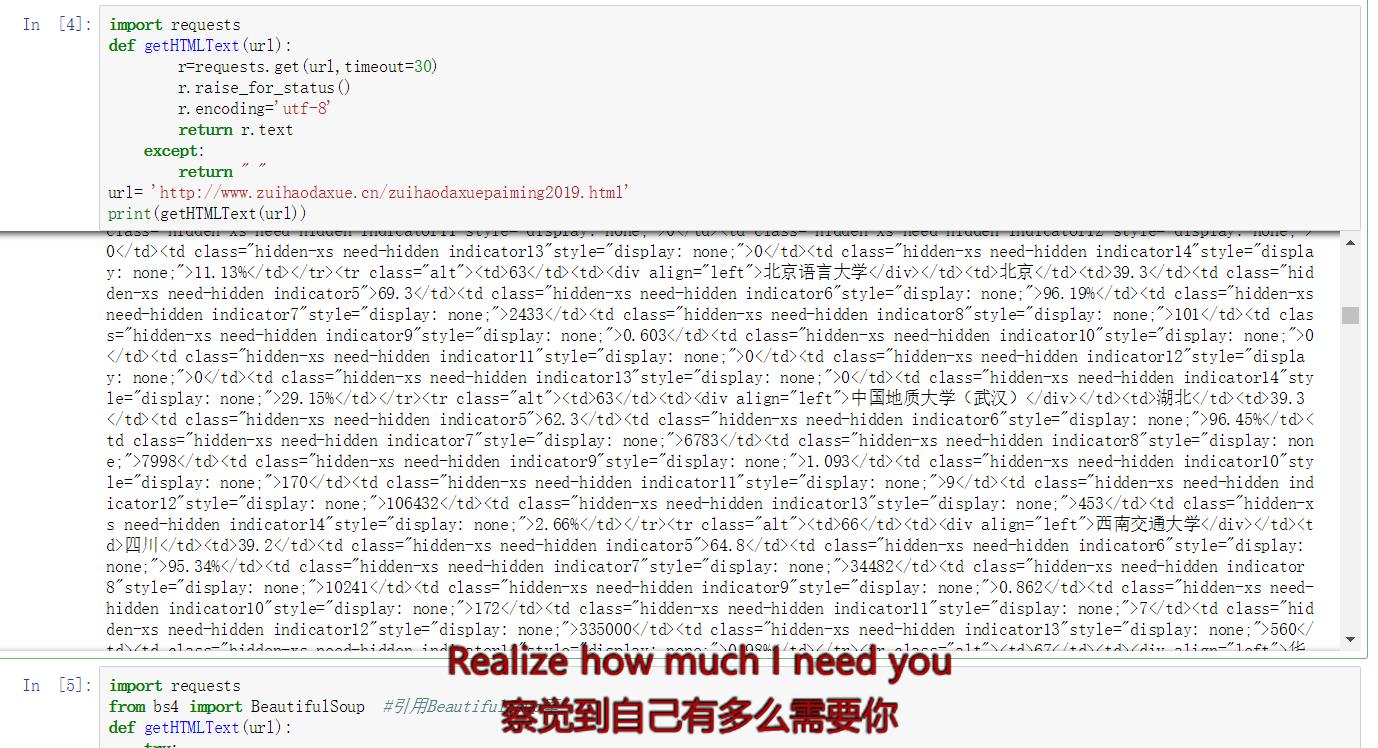
import requests
from lxml import html
def getHTMLText(url):
....
etree = html.etree
root = etree.HTML(getHTMLText(url))
#这里得到一个表格内tr的集合
trArr = root.xpath("//div[@class='news-text']/table/tbody/tr");
#循环显示tr里面的内容
for tr in trArr:
rank = tr.xpath("./td[1]/text()")[0]
name = tr.xpath("./td[2]/div/text()")[0]
prov = tr.xpath("./td[3]/text()")[0]
strLen = 22-len(name.encode('GBK'))+len(name)
print('排名::<3, 学校名称::<\\t, 省份:'.format(rank,name,strLen,prov))
希望对你有帮助!
追问这个可以用!谢谢啦!
参考技术A这种情况用xpath啊,什么re和bs4都弱爆了。
import requestsfrom lxml import etree
def getHTMLtext(url):
res=requests.get(url,timeout=30)
# 处理中文编码问题
res.encoding='gb2312'
# 转化html
html=etree.HTML(res.text)
# xpath提取tr标签下td的内容
HTMLtext=html.xpath("//tr/td/text()")
return HTMLtext追问
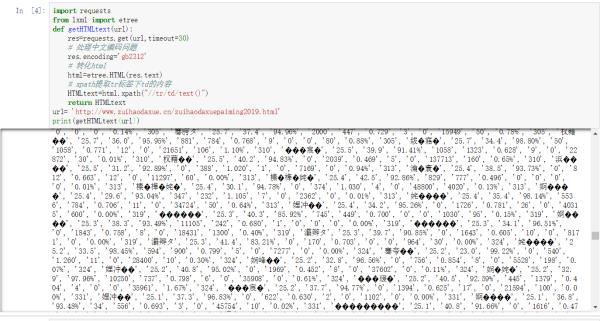
会乱码哦!
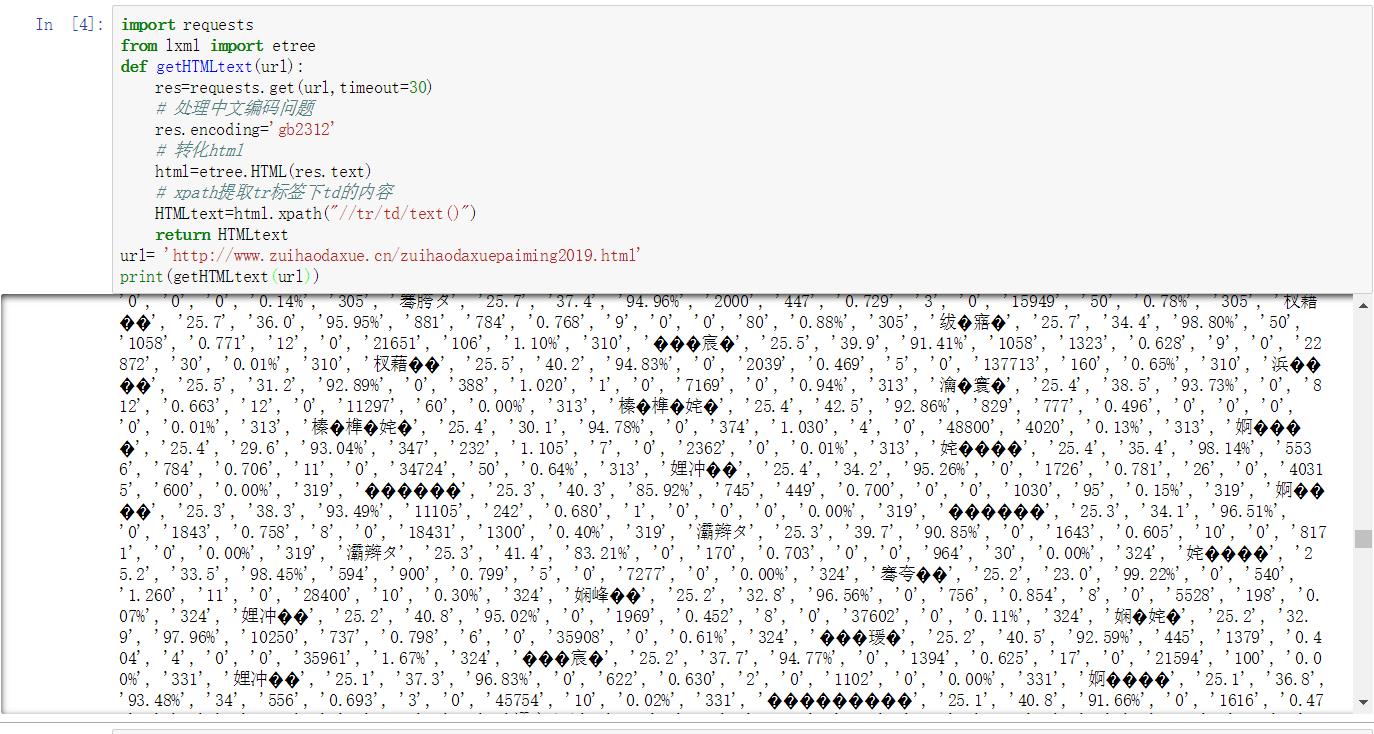
这是中文编码问题,跟提取没有关系,通过res.apparent_encoding查看真实编码,然后把gb2312改成真实编码
参考技术B 爬取这些主要看规则,如果就你刚才所说,可以用正则。可以试下一次正则是否能提取,如果不行的话,先取包含内容的部分,然后正则再区分。当然还可以查下类似xml解析的方法将HTML转化为数组,然后取值 参考技术C 如果只要tr td中的文本内容,建议还是用正则表达式来提取更为方便。追问
能给代码吗?我看到网上很多都说用正则表达式,但是那些代码复制来都报错。
参考技术D 举个例子:想要提取全部标签<h4></h4>内的文本,可使用如下Python代码:
import re
with open("html.html",'rU') as strf:
....str = strf.read()
res = r'(?<=<h4>).*?(?=</h4>)'
li = re.findall(res,str)
with open("new.txt","w") as wstr:
....for s in li:
........wstr.write(s)
........wstr.write(" ")
........print(s,' ')
正则表达式r'(?<=<h4>).*?(?=</h4>)中括号部分属于向后向前查找,相当于字符串作为边界进行查找。
运行后会将标签<h4></h4>内的文本提取到文件new.txt
终于搞懂如何用Java去除HTML标签了
在我平时的工作中,偶尔会用 Java 做一些解析HTML的工作。有的时候我需要删除所有的HTML标签,只保留纯文字内容。这个问题在做过一些爬虫工作的朋友来说很简单。下面来说说,我们平时使用到的集中解析的方法。
使用正则表达式
通过爬虫爬到的HTML内容,从程序角度来讲,就是一个字符串。我们可以对其按照纯文本处理的方式来处理。
我们在做文本处理的时候,第一个想到的就是正则表达式。从一个字符串中删除HTML,对于正则来说,还是比较简单的。毕竟还是有固定的格式,比如“<...>”。
我们常用的的正则就是 <[^>]> 或者 <.*?> 。
我们在使用正则的时候,需要注意的是正则默认是贪婪匹配。也就是说,正则表达式<.*> 能够匹配到更多的HTML内容,而不是单个标签。
现在,让我们测试一下它是否能从HTML源中删除标签。
正则测试删除标签1
在我们测试删除HTML标签之前,首先让我们创建一个HTML例子,例如example1.html。
<!DOCTYPE html>
<html>
<head>
<title>这是标题</title>
</head>
<body>
<p>
如果应用程序X没有启动,可能的原因是<br/>
1. <a href="https://maven.apache.org">Maven</a>没有安装<br/>
2. 磁盘空间不足<br/>
3. 内存不足
</p>
</body>
</html>
现在,让我们写一个测试,用String.replaceAll()来删除HTML标签。
String html = ... // load example1.html
String result = html.replaceAll("<[^>]`>", "");
System.out.println(result);
如果我们运行这个测试方法,我们会看到结果。
这是标题
如果应用程序X没有启动,可能的原因是
1.Maven没有安装
2.磁盘空间不足
3.没有足够的内存
输出结果保留了剥离后的HTML的空白处。我们在处理提取的文本时,可以很容易地删除或跳过这些空行或空白处。
正则测试删除标签2
我们刚才已经看到了,通过使用Regex来删除HTML标签是非常简单。但是粗暴的使用这种方法会有很多问题,我们不能预测最终的结果会是怎么样的。
例如,一个HTML文档可能有<script>或<style>标签,而我们可能不希望在结果中出现它们的内容。
此外,<script>、<style>、甚至是<body>标签中的文本可能包含 <或 >字符。如果是这种情况,我们的正则方法可能会出错。
现在,让我们看看另一个例子,比如example2.html。
<!DOCTYPE HTML>
<html>
<head>
<title>这是标题</title>
</head>
<script>
// some js function
</script>
<body>
<p>
如果应用程序X没有启动,可能的原因是<br/>
1. <a
id="link"
href="http://maven.apache.org/">
Maven
</a> 没有安装<br/>
2. 磁盘空间不足 (<1G) <br/>
3. 内存不足(<64MB)<br/>
</p>
</body>
</html>
现在我们有一个<script>标签和 <字符在<body>标签内。
如果我们对example2.html使用同样的方法,我们会得到如下内容。
这是标题
// some js function
如果应用程序X没有启动,可能的原因是
1.
Maven
没有安装
2. 磁盘空间不足 (
3. 内存不足(
显然,由于"<"字符的存在,我们丢失了一些文本。所以正则在处理文本的时候并不是万能的。我们可以使用一些 HTML 解析器来做这些比较复杂的场景。
使用Jsoup
Jsoup 是一个流行的HTML解析库,如果想要从一个HTML文档中提取文本,我们可以简单地调用Jsoup.parse(htmlString).text()。
在项目中使用的时候,我们首先需要添加 jsoup 的依赖库,我们这里就通过maven的方式引入。
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.14.3</version>
</dependency>
我们用 example2.html来测试一下。
String html = ... // load example2.html
System.out.println(Jsoup.parse(html).text());
如果我们让这个方法运行,它就会打印出来。
这是标题 如果应用程序X没有启动,可能的原因是 1.Maven没有安装 2.没有足够的(<1G)磁盘空间 3.没有足够的(<64MB)内存
从输出结果可知,Jsoup已经成功地从HTML文档中提取了文本。另外,<script>元素中的文本已经被忽略了。
此外,默认情况下,Jsoup会删除所有的文本格式和空白处,比如换行符。
使用HTMLCleaner
HTMLCleaner 也是一个HTML解析库。
首先,我们需要在pom.xml中添加HTMLCleaner 依赖。
<dependency>
<groupId>net.sourceforge.htmlcleaner</groupId>
<artifactId>htmlcleaner</artifactId>
<version>2.25</version>
</dependency>
我们可以设置[各种参数](http://htmlcleaner.sourceforge.net/parameters.php)来控制HTMLCleaner的解析行为。我们在这里使用HTMLCleaner在解析example2.html时跳过<script>元素。
String html = ... // load example2.html
CleanerProperties props = new CleanerProperties();
props.setPruneTags("script");
String result = new HtmlCleaner(props).clean(html).getText().toString();
System.out.println(result);
运行一下,HTMLCleaner将产生这样的输出。
这是标题
如果应用程序X没有启动,可能的原因是:
1.Maven没有安装
2.没有足够的(<1G)磁盘空间
3.内存不足(<64MB)
我们可以看到,<script>元素中的内容被忽略了, <br/>标签转换为提取的文本中的换行符。另外, HTMLCleaner 保留了HTML的空白内容。
总结
在这篇文章中,我们学习了几种去除HTML的方法,我们需要注意的是,正则在文本处理的过程中并不是万能的。

以上是关于如何用Python爬取出HTML指定标签内的文本?的主要内容,如果未能解决你的问题,请参考以下文章