airflow+k8s 多用户-分布式-跨集群-容器化调度
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了airflow+k8s 多用户-分布式-跨集群-容器化调度相关的知识,希望对你有一定的参考价值。
对于考虑使用拖拉拽编排使用云原生调度的可以参考
https://github.com/tencentmusic/argo-workflow
全栈工程师开发手册 (作者:栾鹏)
架构系列文章
最开始采用airflow+k8s分布式容器化调度的方案主要是为了解决下面的问题:
1、特有环境/特有脚本调度的调度问题
2、大数据量任务或大算力任务节点故障和调度管理问题
目前已经基于airflow+k8s改造成多用户-分布式-跨集群-容器化调度的平台。
airflow官网:https://airflow.apache.org/docs/stable/
airflow介绍
airflow 是一个编排、调度和监控workflow的平台,由Airbnb开源,现在在Apache Software Foundation 孵化。airflow 将workflow编排为tasks组成的DAGs,调度器在一组workers上按照指定的依赖关系执行tasks。同时,airflow 提供了丰富的命令行工具和简单易用的用户界面以便用户查看和操作,并且airflow提供了监控和报警系统。
airflow源码改造,镜像封装
airflow的官方git在https://github.com/apache/airflow,而源码部分在airflow/airflow/目录下面,对应我们二次开源的版本地址在airflow/docker/mine/airflow-1.10.9/airflow 目录下面。前后端代码在www和www_rbac下面。
为了能方便的开源改造后部署,我们使用源码安装的方法部署airflow:
源码安装的方法比较简单,先使用pip安装一遍airflow,是为了使用pip将airflow的依赖包都安装上,再将源码目录复制进去,并且设置PYTHONPATH环境变量添加源码的目录,这样就可以使用我们的airflow库进行启动了。
RUN pip install apache-airflow==1.10.9
COPY airflow-1.10.9 /home/airflow/airflow
ENV PYTHONPATH $PYTHONPATH:/home/airflow/airflow
镜像构建分装分为两层:为避免频繁修改代码打包比较麻烦,所以先统一封装好环境镜像,再在环境镜像的基础上封装airflow代码。
airflow web改造
airflow rbac版本是基于flask appbuilder改造的,需要改造的可以先学习一下flask appbuilder。我们基于airflow1.10.9版本,对airflow web进行了部分改造。这样方便更多的用户进行使用。注意:不同版本的airflow,dag文件的语法不太一样。我们使用的airflow为1.10.9版本。在web上我们主要增加了如下的内容:
1、ioa登录认证
2、rbac鉴权
3、在线上传/删除dag文件
4、修复时区问题
5、插件化开发部署

有了多用户就可以针对每个人不同的权限来控制对调度任务的管理,实现多用户权限隔离。
插件化开发
了解airflow的同学应该知道,要想让airflow识别我们的pipeline,需要我们自己编写dag文件,是一个py文件。大体的结构可以参考:https://airflow.apache.org/docs/stable/concepts.html
如果直接推广给用户,就需要用户学习python和airflow的dag书写规则,这个成本还是比较高的。所以我们在airflow dag的基础上封装了一层工具的概念,也可以理解为插件的概念(注意不是airflow官方的插件概念)。这个工具组可以将很多通用 dag进行模板化,封装为工具,这些工具的使用只需要用户在界面上填写该工具需要使用的参数,保存这些参数后就可以自动渲染为dag。避免了用户自己编写dag和用户自己封装镜像。现在支持nrt插件、flinkx插件、datax插件、bash命令插件。

docker-compose部署调试
由于airflow包含多个功能组件,需要启动多个容器才能正常进行调试。多容器本地调试最好的方法就是使用docker-compose。
airflow的配置涉及到多个文件:.env、airflow.cfg、airflow.env、bootstrap.sh、entrypoint.sh,可以根据自己的情况修改里面的内容。
使用docker-compose up启动airflow会启动redis、webserver、scheduler、worker等组件,并且连接外置的mysql,所以还需要你自己搭建mysql数据库,这是因为大部分开发者都有自己的mysql数据库,所以没有包含在部署文件中,如果你没有自己的mysql测试库,可以使用下面的命令自己部署一个
linux
docker run --network host --restart always --name mysql -e MYSQL_ROOT_PASSWORD=admin -d mysql:5.7
mac
docker run -p 3306:3306 --restart always --name mysql -e MYSQL_ROOT_PASSWORD=admin -d mysql:5.7
进入数据库创建一个db
CREATE DATABASE IF NOT EXISTS airflow DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
这些组件中redis做任务队列和任务结果存储。mysql存储平台元数据。scheduler每5分钟扫描指定目录检测可用的dag,并根据dag的调度时间产生后面5分钟需要产生的任务,并推送给redis。worker从redis中领取任务,并执行任务。webserver为airflow web的前后台部分,可以在线管理dag和任务实例。如果本地调试,redis和mysql是必须要启动的,其他的组件可以根据自己当前调试的内容来选择启动。
Airflow k8s高可用部署
部署k8s集群

这是airflow的原生架构,虽然我们在本地使用docker-compose进行调试,但是为了保证高可用,我们在生产线上肯定是使用多台机器。我们采用k8s模式部署airflow的原生架构,另外我们使用ceph分布式存储来挂载dags目录到schedule,web,worker中。当然scheduler的高可用这里没有涉及(如果是多个scheduler要注意避免任务重复),redis使用的组从模式(公司的ckv,ckv+部分功能不支持),mysql可以用cdb,多个worker容器,分布在不同的机器上。
在部署airflow前需要先部署依赖组件redis和mysql。然后就可以在k8s上部署airflow了。
airflow+k8s调度结构

airflow的原有架构是部署在k8s之上的,不过按照原有架构,所有任务都是在worker容器里执行的。虽然worker可以进行伸缩容来满足不同数量的任务,或者配置参数使得worker进程数进行动态伸缩容。
但是在worker执行的任务需要资源非常大的时候,worker就有可能oom,或者造成机器死机,这样在该worker容器或机器上的所有任务就都会受影响。我们在worker基础上添加k8s。让worker只进行k8s pod的管理,不具体进行大任务的执行,具体的任务在k8s pod中执行。
注意:在这里两个地方涉及到k8s,一个是airflow原生组件是使用k8s部署的。另外一个是每个worker节点也在向各种k8s集群发起pod部署指令。这些pod是执行具体业务任务的。
kubernetes-operator
上面架构的实现方法是使用了airflow中的kubernetes-operator。这里是一个包含了kubernetes-operator的示例https://git.code.oa.com/tme-data-infra/airflow/blob/master/dags/k8s-demo.py
通过KubernetesPodOperator方法控制pod的部署。其中
- namespace:为pod部署的命名空间
- image:为pod的镜像
- cmds:为pod的启动命令 数组格式
- labels::为pod的label,字典格式
- name:为pod的名称
- task_id:为pipeline中当前task的名册个
- get_logs:为是否实时获取pod的日志在airflow中显示
- dag:为当前task所属的dag的名称
- in_cluster:为是否在当前集群部署pod
- service_account_name:为pod部署时所绑定的账户名
- affinity:为pod部署的亲密度,字典格式,可以参考git中的写法
- env_vars:为pod内的环境变量,字典格式
- volumes=[]:为pod的数据卷,数组格式,参考git中写法
- volume_mounts=[]:为pod部署的挂载点,参考git中写法
- hostnetwork:为pod部署是否使用host模式
- resources:为pod部署的资源限制
- is_delete_operator_pod:为pod完成后是否删除pod
- startup_timeout_seconds:为创建task多久后pod都没有成功启动
- config_file:为部署pod的k8s集群的kubeconfig文件
- image_pull_secrets:为pod拉取镜像的hubsecret
- image_pull_policy:为pod拉取镜像的策略。
通过上面的参数,我们就可以在选定的集群,选定的机器下进行并发的容器化任务调度了。
k8s安全升级airflow
当我们修改了参数或者修改了源码重新封装了镜像需要进行升级的时候,我们就需要重启容器。但是直接删除worker 会把里面job直接kill掉,然后schedule会重新调度。有时候我们的任务需要运行很长时间才会完成,我们并不想直接删除worker的pod。下面介绍一种优雅升级的方法,修改airflow的worker的升级模式设置为手动删除才升级。这样我们在修改了配置信息后,pod也不会自动重启。
updateStrategy:
type: OnDelete # OnDelete为手动升级 RollingUpdate
# podManagementPolicy: Parallel # 会同时终止所有pod
配置以后,进入任何一个worker容器,通过celery api设置为不再继续添加新任务。
celery control -b redis://:admin@redis-master.infra:6379/1 cancel_consumer default -d celery@airflow-worker-1
这样worker会消费当前已经接收的任务,不再继续接收新任务了,待已存在的任务全部结束后,就可以直接手动重启容器,重启后容器后就会继续接收新任务按照新的参数运行了。
因为airflow是基于celery来实现的,我们可以使用celery的命名来查看当前任务的调度运行情况。
airflow平台的使用
目前平台调度管理着dau各项指标监控、clickhosue读写分离构建、nrt/tdsql容器化调度、脚本容器化调度、abt数据各种任务容器。
跨园区容灾,升级不停服:高可用负载均衡集群实践
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~
作者:方坤丁
对于云计算行业来说,云服务的可用性和可扩展性是的检测其服务质量的重要标准,也是最受用户关注的两大难题。各云计算厂商针对容灾、升级等需求的解决方案,最能够体现其底层架构的实力。腾讯云基于基础架构的优势,为分期乐、微信红包等平台提供技术支持,可以完美满足如下三点需求:
1. 高可用能力,容灾能力强,升级不停服
2. 可扩展性强,功能丰富,性能超高
3. 避免重复造轮子,性价比之王
近期,针对一些客户对腾讯云产品可用性的问询,腾讯云基础产品团队对负载均衡产品的原理做出详细阐述,并希望通过对腾讯负载均衡集群底层架构的实现的讲解分析,揭示其强劲性能、高可用性的根源所在。
一、什么是负载均衡
单台web 服务器如 apache、nginx 往往受限于自身的可扩展硬件能力。在面对海量的 web 请求时,需要引入load balance将访问流量均匀的分发到后端的web集群,实现接入层的水平扩展。
Tencent 所有业务的负载均衡都是基于内部 Tencent GateWay 实现的,运行在标准x86服务器上,优点包括:自主研发、代码可控。Tencent GateWay 对外的版本为 Cloud load balance,是多机 active 部署的,通过 BGP 发布VIP、local adress 路由、同步 DNS 信息等,实现集群负载通过路由 OSPF 将流量分发到不同的服务器上。
Load balance 作为 IT 集群的出入口、咽喉要塞。开发商使用负载均衡器看中的无非是高可用能力、分发性能以及产品功能的丰富程度,咱先从高可用说起。
二、高可用能力
a. 单集群容灾能力
集群容灾,简单来说就是一个集群中一台服务器倒掉不会影响整个集群的服务能力。LVS是国内厂商常用的开源框架,常用Keepalived完成主备模式的容灾。有3个主要缺点:
1、主备模式利用率低。一个集群同时只有一半的服务器在工作,另外一半的机器处于冷备状态,主节点不可用之后的切换速度相对较慢;
2、横向平行扩展能力差。LVS服务集群扩展后转发效率大幅下降;
3、依赖的VRRP协议存在脑裂的风险,需引入第三方仲裁节点,在金融领域、跨园区容灾领域备受挑战。
CLB在设计之初就考虑到这个问题,采用自研的ospf动态路由协议来实现集群的容灾,若一台机器倒掉,ospf协议可以保证在10s以内把机器从集群中剔除。
CLB一个集群放在两个接入交换机下,并且保证跨机架的容灾,这样保证在即便有单边的交换机出故障或者单边机架掉电时,本集群的服务不受影响。同事实现了集群内session连接定期同步。这样在别的服务器接管故障机器的包时,client端的用户体验不受影响(如未登录的账户,在电商购物车里的未付款商品不丢失)
b. 跨园区容灾能力
为了满足金融核心客户,24小时核心业务持续服务的要求。腾讯云负载均衡已在各金融专区(region)部署了多可用区(zone)容灾套件,从路由器、交换机和服务器以及布线是全冗余的,任意一个路由器、交换机或者服务器接口挂掉之后,流量会从冗余组件提供服务。
当client端请求,经过CLB代理,访问到后端CVM时,负载均衡的源 ip、目的ip、转发策略、会话保持机制,健康探测机制等业务配置。会实时的同步到另一个zone的集群。当主可用区的机房故障、不可用时,负载均衡仍然有能力在非常短的时间内(小于10s)切换到另外一个备可用区的机房恢复服务能力,而业界产品的切换时间一般在分钟级别。当主可用区恢复时,负载均衡同样会自动切换到主可用区的机房提供服务。目前包括webank、富途证券等金融开发商已启用跨园区容灾能力。
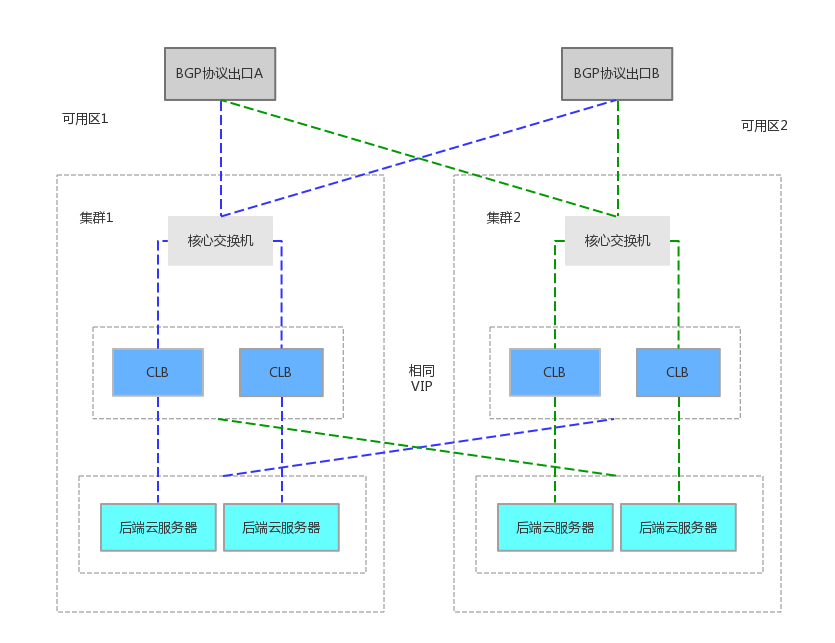
容灾演练实测:
1、协议切换(模拟交换机、CLB集群任何一层故障导致整个机房外网LB不可用),切换时间ping丢包不超过1秒,但长链接会瞬断,结果符合预期。
2、在高可用机房的LB外网完全瘫痪发生切换,恢复后不主动回切,过程中瘫痪机房的任何操作不应影响另外一边,结果符合预期。
3、模拟(与CLB开发商沟通好以后)流量回切操作,流量回切时间ping丢包不超过1秒,但长链接发生瞬断,结果符合预期。


c. 升级不停服
CLB内核升级、Linux 内核缺陷、安全漏洞等原因,免不了要做后端集群的重启升级,如果服务器每年由于维护等原因重启一次,1小时的恢复时间就已经达不到99.99%的可用性了。
目前CLB已能做到客户无感知的,完成服务器升级。升级时会选取集群一半负载均衡器,停掉OSPF协议,实行“温暖关机”。将其权重设置为0,从而保证数据包不会在经过这几台LB。另一半LB集群会接管预备关机LB的流量,集群内连接同步,负责接管的LB上具有全量的连接信息,连接不会中断。升级完成后的LB将重新启动ospf,加入集群,正常服务。
三、高可扩展性
a. 性能强劲
1)流量分发
腾讯云负载均衡内部实现,利用了intel DPDK提供的高性能多核开发框架、hugepage内存管理及ring buffer共享队列方案,CLB团队将DPDK常见的逻辑设计框架run-to-completion与pipeline结合。极大提升了流量分发的效率。
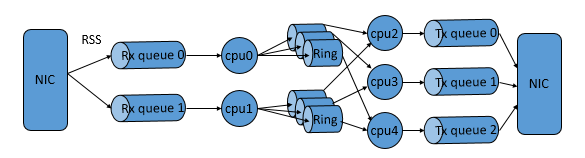
2017年1月28日,微信公布了用户在除夕当天收发微信红包的数量:142亿个,而其收发峰值也已达到76万每秒。面对亿级的用户数及百亿级的红包,系统的性能至关重要。而承载新年红包的手机QQ和微信都接入了腾讯云负载均衡集群,得到了有效的性能保障。CLB单集群可承受的TCP最大并发连接数超过1.2亿,处理峰值40Gb/s的流量,每秒处理包量(QPS)可达600万。为广大用户提供了流畅、愉快的抢红包体验,实现了除夕夜系统零故障。
2)Https加速
CLB性能上最大的一个难题是如何提升HTTPS的效率。同样的物理设备下cpu满负载,nginx SSL完全握手的性能不到普通HTTP性能的10%,如果说HTTP的性能是QPS 1万,HTTPS可能只有几百。为什么会这么低呢?
1、主要是RSA算法,它对性能的影响占了75%左右;
2、ECC椭圆曲线如果使用最常用的ECDHE算法,这部分约占整体计算量的7%;
3、对称加解密和MAC计算,它们对性能影响比较小,是微秒级别的。
有了这些分析结论,优化的方向就很明确了:
1、减少完全握手(采用分布式session cache、全局Session ticket、自定义session ticket)
2、RSA异步代理计算
3、对称加密优化

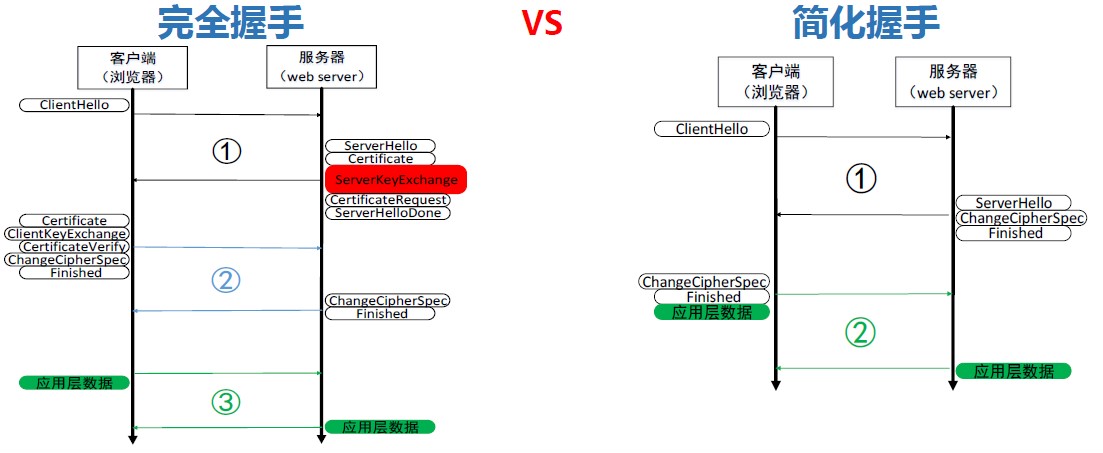
经过以上努力CLB团队通过异步代理、减少完全握手等方式,释放了CPU负载,。经过优化后,https请求的访问时延与http请求相差无几。单集群的单台云服务器完全握手性能可达到65000QPS,长连接时单台服务器性能可以达到300000QPS。完美的支撑了红包业务对SSL卸载的性能要求
b. 均衡能力丰富
我们来看看另一个case。分期乐一家专注于大学生分期购物的在线商城及金融服务提供商,提供分期贷款和还款服务。原分期乐(fenqile.com)的电商门户,有三十多个业务模块,通过多个二级域名、公网IP来分隔业务模块。门户的日PV超过亿次,峰值带宽超过5GB。
随着访问量的增多,其自建的nginx负载均衡集群已无法承载海量的请求,频繁出现丢包、SSL卸载慢等额问题。为了保证其业务在九月开学大促、双十一大促中平稳运行,分期乐引导部分流量到云端架构中,通过负载均衡进行业务整合:
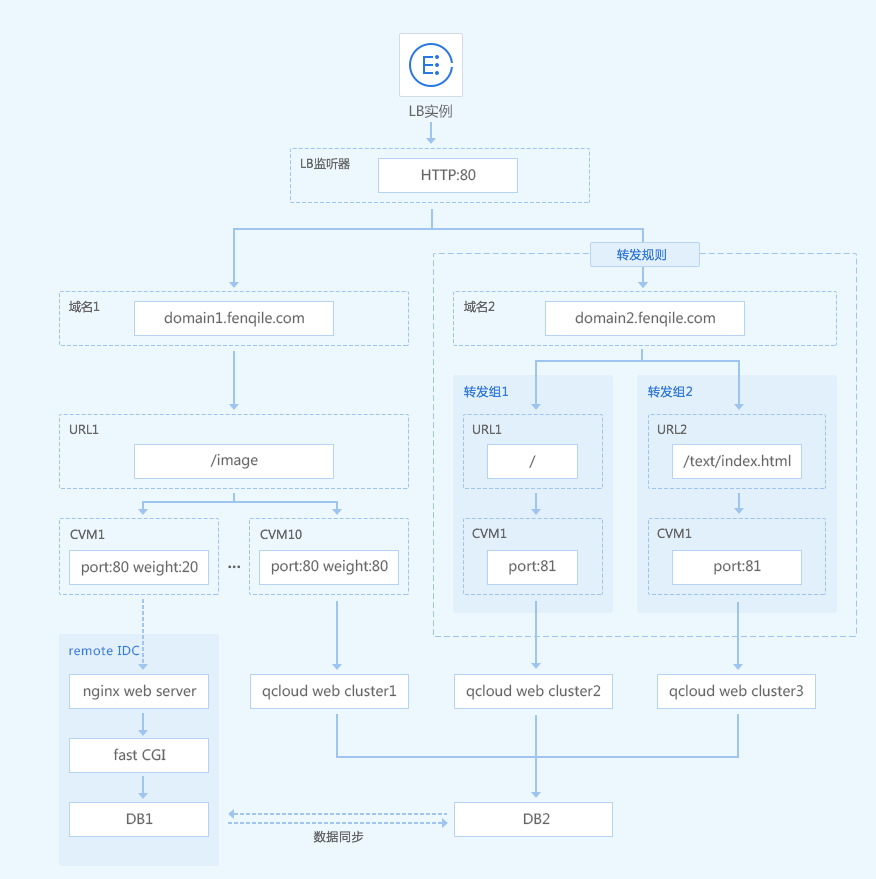
1)Content base的流量转发
为了实现业务分离,分期乐使用七层负载均衡获取HTTP/HTTPS头部信息,并根据企业业务的实际需要,将请求路由到不同的后端服务器集群,从而让负载均衡基于内容进行路由转发。此外,采用了细致到转发组级别的健康检查,具有更强灵活性,满足更多业务场景。
分期乐业务架构中,通过自定义域名/URL,实现了基于内容的路由转发。根据业务类型,分期乐配置了a.fenqile.com/image 和a.fenqile.com/text 两个URL路径。通过识别请求内容,将后缀带有/image的请求转发到后端服务器群组1,并将后缀带有/text的请求转发到后端服务器群组2,从而保证了流量分发到不同的服务器群组中,减轻单个节点的负载。原来以上配置都需要在自建的nginx location中配置完成,转发请求时消耗大量的cpu资源,现在交给CLB就好了。
CLB同时提供多元化的重定向能力,可以满足电商的两种场景:A.浏览器发起的http请求,强制转换为https请求,加密更可靠。B.电商中商品更替、库存售罄、后端某服务器负载过高(限制连接数、请求)等场景,常见的做法是直接拉黑页面,给client端返回404、503。但这种体验太差了,CLB支持智能重定向,将超负载的请求,转发到其它页面,如门户首页。
2)专线接入
迁移上云从不是一蹴而就的,腾讯云强大的专线互联能力,满足客户逐步从自建IDC将业务迁移上云的能力:
a.分期乐首先逐步将业务迁移到云端,例如mall.fenqile.com这个域名会同时部署在自建idc及腾讯云负载均衡集群中。首先通过weight权重的配比,将30%的流量迁移到腾讯云,70%的流量回IDC。在稳定运营后,再逐步增加腾讯云端的权重,替换原有数据中心IDC的服务。
b.当业务流量增大时,clb负载均衡无性能瓶颈,需要注意的时候后端的apache、nginx接入层需要做到无状态,并借用autoscaling能力实现弹性伸缩。
大促当天,CLB支持了海量的并发访问,分期乐门户的日PV超过亿次,峰值带宽超过5Gbps,支持了过亿的交易额。
四、性价比之王
传统的硬件负载均衡,以F5为例,其缺点非常明显, 从商业角度来说,硬件负载均衡产品过于昂贵,高端产品动辄五十万甚至数百万的价格对于用户是几乎不可承受的负担,如下图所示:
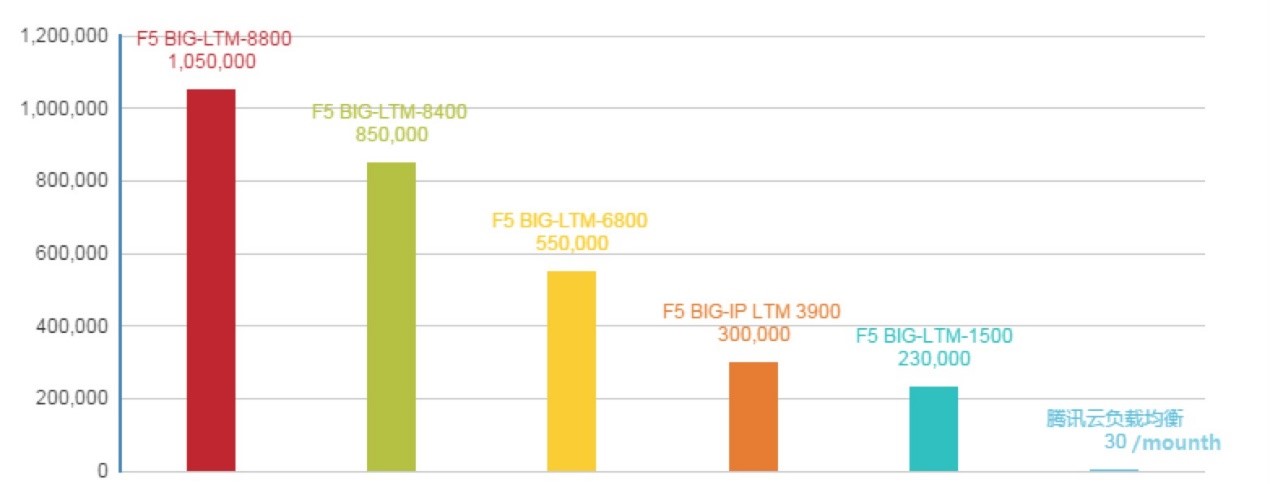
从使用角度来说,硬件负载均衡是黑盒,有BUG需要联系厂商等待解决,时间不可控、新特性迭代缓慢且需资深人员维护升级,也是变相增加昂贵的人力成本。
腾讯云在2015年起,将内部的负载均衡服务,正式对外商业化服务,单实例1个月的开销为30元(费用节省达99%以上)。您还有什么理由购买硬件负载均衡,或使用开源方案造轮子呢?快来试用吧:)
相关推荐
问答
相关阅读
此文已由作者授权腾讯云+社区发布,原文链接:https://cloud.tencent.com/developer/article/1004789?fromSource=waitui
欢迎大家前往腾讯云+社区或关注云加社区微信公众号(QcloudCommunity),第一时间获取更多海量技术实践干货哦~
海量技术实践经验,尽在云加社区! https://cloud.tencent.com/developer?fromSource=waitui
以上是关于airflow+k8s 多用户-分布式-跨集群-容器化调度的主要内容,如果未能解决你的问题,请参考以下文章