for循环提交ajax,为啥只有第一次能够提交,后面的循环都没有提交到后台,但是for执行完了?急急急!
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了for循环提交ajax,为啥只有第一次能够提交,后面的循环都没有提交到后台,但是for执行完了?急急急!相关的知识,希望对你有一定的参考价值。
ajax是异步的,请检查一下每一次for代码块中的执行情况可以每次alert 看一下结果,或者 for中 每隔一定的时间执行一次ajax追问

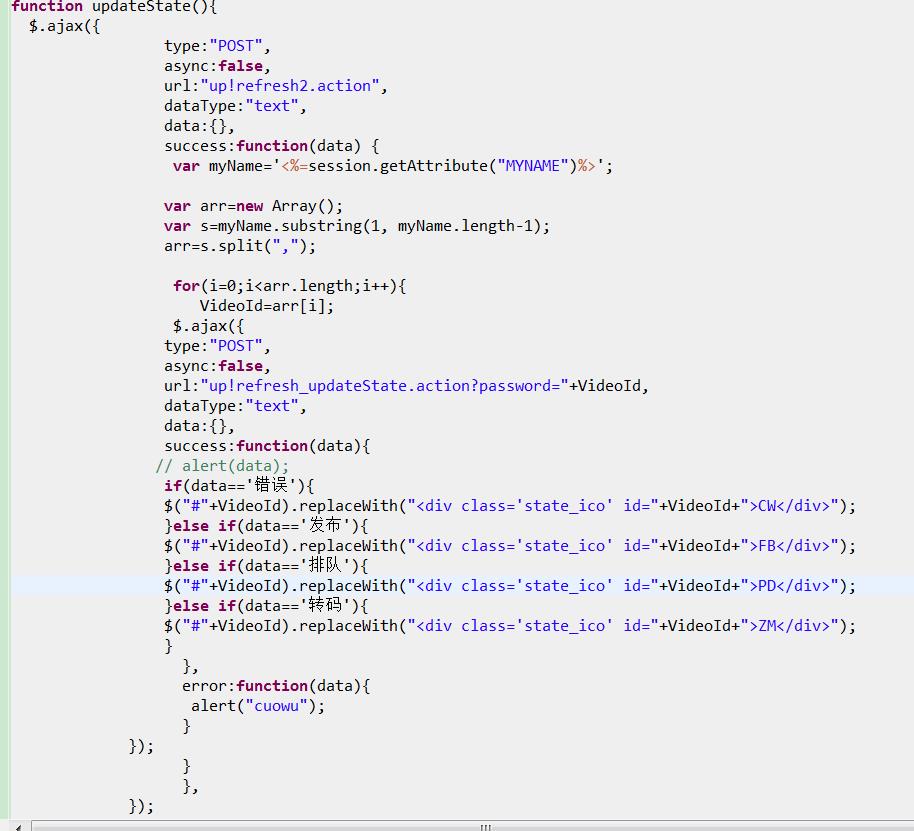
有个小建议,就是data=="错误" 这错误尽量改成error 英文的,否则有可能出现各种错误!
可以把 for 中的每个值都遍历出来,放到一个 string 中,然后一次性ajax,然后一次性返回你所需要的结果,这样的话,也减少了每次ajax请求所消耗的资源,还不会出现目前这种错误!
简单看了你的代码,没什么问题,可能就是ajax本身异步和for循环之间造成这种情况的
同步的也做过了,还是同一个情况,第二次循环后台都获取不到传的值了,
追答可以吧for循环ajax的代码贴出来看看吗?
追问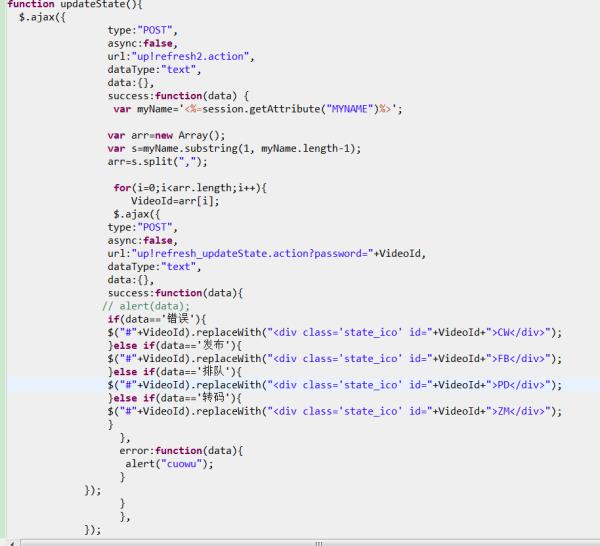 完整代码
完整代码
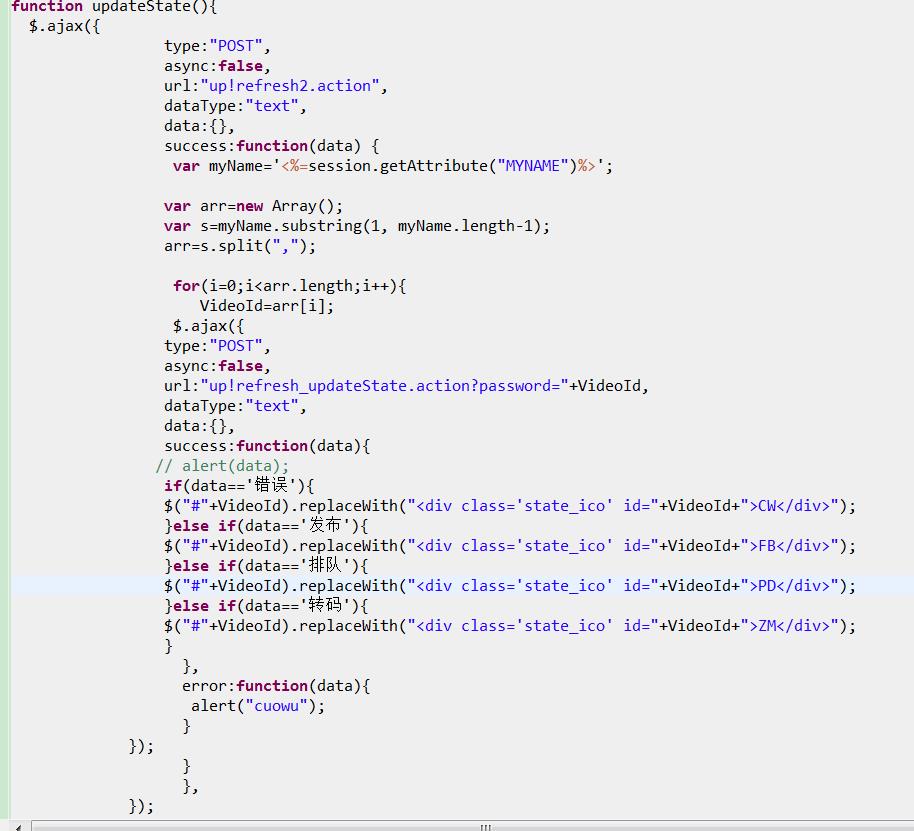
你为什么在ajax里面嵌套ajax?你在for循环里面alert(VideoId)能循环打出值吗?不行,把外面的ajax设成异步试试
为啥我的推送中突然有合并提交?
【中文标题】为啥我的推送中突然有合并提交?【英文标题】:Why do I suddenly have a merge commit in my pushes?为什么我的推送中突然有合并提交? 【发布时间】:2020-12-03 20:18:10 【问题描述】:嗯,我好像把事情搞砸了。
直到最近,我曾经能够进行合并提交,然后推送到源而不显示单独的提交。现在它完成了,合并提交就是我在管道中看到的所有内容:
在此开始之前,只有手动提交被推送到源(或至少显示为这样):
这是团队资源管理器(VS 2019 v16.6.5),行为改变后:
...这是我的本地分支历史记录:
看到变化了吗?
这一切都是在我恢复提交a13adadf、修复并重新发布之后开始的。现在我得到了某种奇怪的分支效应,我不知道如何让事情恢复到以前的状态。 (我试过研究这个问题,但是在搜索与merge commit相关的任何内容时,信噪比非常低。)
如何让我的仓库“忽略”(即停止显示)合并提交?
(注意:我是唯一在这个 repo 上工作的开发人员。)
【问题讨论】:
【参考方案1】:您之前似乎进行过快进操作。如果条件正确,git merge 命令将执行此操作而不是合并:
-
需要可以进行快进。
您需要避免
--no-ff 选项,这会禁用快进。
这一切都是在我恢复提交
a13adadf、修复并重新发布之后开始的。
这一定是创建了一个分支。这个词有一个问题 - “分支”,也就是说 - 这会让你误入歧途,但你在问题中显示的图表 sn-p 表明这实际上是发生的事情。
如何让我的仓库“忽略”(即停止显示)合并提交?
如果您只是想避免显示它们,您的查看器可能会有一些选项来执行此操作。
如果你想回到不制作它们的状态——你以前的情况——你需要消除你制作的分支。
Long:这里发生了什么(以及为什么“分支”这个词有问题)
首先要记住的是,Git 是关于提交的。刚接触 Git 的人,甚至已经使用了很长时间的人,经常认为 Git 是关于文件或分支的。但实际上并非如此:这是关于提交。
每个提交都有编号,但这些数字不是简单的计数数字。取而代之的是,每个提交都会获得一个看似随机的(但实际上根本不是随机的)哈希 ID。这些东西又大又丑,Git 有时会缩写它们(例如你的a13adadf),但每一个都是某个 Git 对象的数字 ID——在这种情况下,是 Git 提交。
Git 有一个包含所有对象的大型数据库,它可以通过 ID 进行查找。如果你给 Git 一个提交号,它会通过 ID 找到提交的内容。
提交的内容分为两部分:
首先,有一个 Git 知道的所有文件的快照。这往往是大多数提交的大部分内容,除了一件事:文件以特殊的、只读的、仅限 Git 的、压缩和去重的格式存储。当您进行新提交时,其中大部分文件与某些先前 提交大部分相同,新提交实际上不会再次存储文件。它只是重新使用现有文件。换句话说,特定文件的特定版本会被摊销,但许多提交会重新使用它。重复使用是安全的因为文件是只读的。
除了保存的快照之外,每个提交都存储一些关于提交本身的元数据:信息。这包括提交人的姓名和电子邮件地址,以及一些日期和时间信息,等等。值得注意的是,每个提交的元数据还存储了供 Git 使用的提交编号(哈希 ID)或在此特定提交之前 的提交。 Git 将此称为 parent,或者,对于合并提交,称为提交的 parents。
这样做是为了让 Git向后工作。这就是 Git 的工作方式,倒退。如果我们有一长串提交,都在一行中,像这样:
... <-F <-G <-H
其中H 代表链中最后 次提交的实际哈希ID,Git 将从提交H 开始,从其对象数据库中读取它。在 commit H 中,Git 会找到所有保存的文件,以及之前提交 G 的 hash ID。如果 Git 需要它,Git 将使用这个哈希 ID 从对象数据库中读取提交 G。这为 Git 提供了更早的快照,以及更早提交的哈希 ID F。
如果 Git 需要,Git 将使用哈希 ID F(存储在G)来读取F,当然F 也包含另一个父哈希 ID。所以通过这种方式,Git 可以从 last 提交开始并向后工作。
这给 Git 留下了一个问题:它如何快速找到链中 last 提交的哈希 ID?这就是分支名称的用武之地。
分支名称只是保存最后一次提交的哈希 ID
鉴于上述情况——并且故意变得有点懒惰,并将从提交到提交的连接绘制为一条线,而不是从子级到父级的箭头——我们现在可以像这样绘制 master 分支:
...--F--G--H <-- master
name master 仅包含现有提交 H 的实际哈希 ID。
让我们添加另一个名称,develop,它还包含哈希 ID H,如下所示:
...--F--G--H <-- develop, master
现在我们有一个小问题:我们要使用哪个name?在这里,Git 使用特殊名称HEAD 来记住要使用哪个分支名称,所以让我们稍微更新一下绘图:
...--F--G--H <-- develop, master (HEAD)
这代表git checkout master 之后的结果:当前分支名称 现在是master,而master 选择提交H,所以这就是我们正在使用的提交(以及我们也在使用的分支名称)。
如果我们现在运行git checkout develop,Git 将切换到该分支。 name 仍然标识提交 H,因此没有其他需要更改的地方,但现在我们有了:
...--F--G--H <-- develop (HEAD), master
如果我们现在进行新的提交,Git 会:
把它知道的所有文件打包(这是Git的index或暂存区进来的地方,但我们这里根本不介绍); 添加适当的元数据,包括作为作者和提交者的姓名以及作为时间戳的“现在”,但重要的是,将提交H 设为新提交的父级;
使用所有这些来进行新的提交,我们称之为I。
Git 还会做一件事,但现在让我们画出这部分。结果是:
...--F--G--H
\
I
那两个名字呢?还有一件事:Git 会将I 的哈希 ID 写入 当前名称。如果那是develop,我们得到这个:
...--F--G--H <-- master
\
I <-- develop (HEAD)
请注意,master 保持不变,但名称 develop 已移动到指向最新提交。
当两个名称标识同一个提交时,任一名称都选择该提交
请注意,最初,当master 和develop 都选择提交H 时,从某种意义上说,与git checkout 一起使用哪一个并不重要。无论哪种方式,您都将提交 H 作为当前提交。但是当你提交 new 时,这很重要,因为 Git 只会更新一个分支 name。没有人知道新提交的哈希 ID 是什么(因为它部分取决于您提交的确切秒数),但一旦提交,develop 将持有该哈希 ID,如果 develop 是当前名字。
请注意,如果您现在 git checkout master 并进行另一个新提交,则名称 master 将是这次更新的名称:
...--F--G--H--J <-- master (HEAD)
\
I <-- develop
我们暂时假设您没有这样做。
快进
考虑到之前的情况,现在让我们运行git checkout master,然后返回到提交H:
...--F--G--H <-- master (HEAD)
\
I <-- develop
在这种状态下,让我们现在运行git merge develop。
Git 将执行它为 git merge 所做的事情(见下文)并发现 合并基础 是提交 H,这也是当前提交。另一个提交 I,领先 提交 H。这些是 Git 可以进行快进操作的条件。
快进并不是真正的合并。发生的事情是 Git 对自己说:如果我进行真正的合并,我会得到一个快照与提交 I 匹配的提交。因此,我会走捷径,只需 check out 提交 I,同时拖动名称 master。 结果如下所示:
...--F--G--H
\
I <-- develop, master (HEAD)
现在没有理由在绘图中保留这个扭结——我们可以把这全部画成一条直线。
真正的合并
有时,上述那种快进而不是合并的技巧是行不通的。假设你开始:
...--G--H <-- develop, master (HEAD)
并进行两次新的提交I-J:
I--J <-- master (HEAD)
/
...--G--H <-- develop
现在你git checkout develop 再提交两次K-L:
I--J <-- master
/
...--G--H
\
K--L <-- develop (HEAD)
此时,无论您给git checkout 取哪个名字,如果您在另一个名字上运行git merge,就无法前进从J 到L , 或相反亦然。从J,你必须备份到I,然后向下到共享提交H,然后才能前进到K,然后是L。
那么,这种合并不能是快进操作。 Git 将改为进行真正的合并。
为了执行合并,Git 使用:
当前 (HEAD) 提交:让我们先通过 git checkout master 来实现 J;
您命名的另一个提交:让我们使用git merge develop 选择提交L;
还有一个提交,Git 自己找到。
最后——或者实际上,第一个——提交是合并基数,合并基数是根据称为最低公共祖先的图操作定义的,但简短易懂的版本是Git 从 both 提交向后工作,以找到 最佳共享共同祖先。在这种情况下,这是提交H:两个分支的分歧点。虽然G 和更早的提交也被共享,但它们不如提交H。
所以 Git 现在会:
比较合并基础H 快照和HEAD/J 快照,看看我们对master 所做的更改;
将合并基础H 快照与另一个/L 快照进行比较,以查看它们在develop 上的变化;和
合并这两组更改,并将它们应用到合并基础快照。
这是合并的过程,或合并作为动词。如果可以的话,Git 会自己完成所有这些工作。如果成功,Git 将进行新的提交,我们称之为M:
I--J
/ \
...--G--H M <-- master (HEAD)
\ /
K--L <-- develop
请注意,新提交 M 指向 两个 提交 J 和 L。这实际上是使这个新提交成为合并提交的原因。因为快进实际上是不可能的,Git 必须做出这个提交,以实现合并。
你最初是在做快进
你是从这种情况开始的:
...--G--H <-- master, develop (HEAD)
然后产生:
...--G--H <-- master
\
I <-- develop (HEAD)
您使用git checkout master; git merge develop 或类似方式获取:
...--G--H--I <-- master (HEAD), develop
之后你可以重复这个过程,首先是develop,然后是develop 和 master,命名新的提交J:
...--G--H--I--J <-- master (HEAD), develop
但此时你做了一些不同的事情:你在master 上做了一个git revert。
git revert 命令进行新的提交。新提交的快照就像之前的快照一样,其中一个提交被撤消了,所以现在你有:
K <-- master (HEAD)
/
...--G--H--I--J <-- develop
K 中的快照可能与 I 中的快照匹配(因此它会重复使用所有这些文件),但提交编号是全新的。
从这里开始,你做了git checkout develop 并写了比J 更好的提交,我们可以称之为L:
K <-- master
/
...--G--H--I--J--L <-- develop (HEAD)
然后你回到master 并运行git merge develop。这一次,Git 必须进行一个新的合并提交。所以它就是这样做的:
K--M <-- master (HEAD)
/ /
...--G--H--I--J--L <-- develop
现在,当您返回 develop 并进行新的提交时,您会得到相同的模式:
K--M <-- master
/ /
...--G--H--I--J--L--N <-- develop (HEAD)
当您切换回master 和git merge develop 时,Git 必须再次进行新的合并提交。快进是不可能的,取而代之的是:
K--M--O <-- master (HEAD)
/ / /
...--G--H--I--J--L--N <-- develop
你能做些什么
假设您现在运行git checkout develop && git merge --ff-only master。第一步选择develop作为当前分支。第二个要求与master 合并。这个额外的标志 --ff-only 告诉 Git:但只有在你可以快进的情况下才这样做。
(我们已经相信 Git 可以快进,所以这个 --ff-only 标志只是一个安全检查。不过我认为这是个好主意。)
由于快进是可能的,你会得到这个:
K--M--O <-- master, develop (HEAD)
/ / /
...--G--H--I--J--L--N
注意名称 develop 是如何向前移动的,指向提交 O,而不添加新的合并提交。这意味着您 on develop 的下一次提交将有 O 作为其父项,如下所示:
P <-- develop (HEAD)
/
K--M--O <-- master
/ / /
...--G--H--I--J--L--N
如果您现在git checkout master; git merge develop,您将获得快进,两个名称都标识新提交P,您将回到在develop 上提交允许快进的情况。
请注意,这样做实际上是在声称您根本不需要名称 develop
如果你的工作模式是:
进行新的提交 向前拖动master进行匹配
那么您需要做的就是在master 上进行新的提交。
用另一个名字做新的提交本身并没有错误,如果这只是有时你的工作模式,那可能是一个好习惯:使用大量的分支名字会在以后帮助你,并且在开始工作之前有一个新名字的习惯是好的。不过,您可能需要考虑使用比 develop 更有意义的名称。
无论如何,请注意 Git 关心的是 commits。 分支名称只是让 Git 帮助您查找特定提交的方法:每个名称找到的提交是您使用该名称工作的点。实际的分支(如果有的话)是您所做的提交的函数。
换句话说:要将提交形成分支,您需要分支名称,但仅拥有分支名称并不能使提交形成分支。即:
...--F--G--H <-- master
\
I--J <-- develop
给你两个“最后”提交,但是一个以提交J 结尾的线性链。从某种意义上说,有两个分支,一个以H 结束,一个以J 结束,但在另一种意义上,只有一个以J 结束的分支。我们可以添加更多名称,指向现有的提交:
...--F <-- old
\
G--H <-- master
\
I--J <-- develop
现在有三个 names(和三个“最后”提交),但存储库中的实际 commits 集并没有改变。我们只是把F单独画在一条线上,让old这个名字指向它。
【讨论】:
天哪!现在那是知识的源泉。优秀。美丽的。清如钟声。正好解决了我的问题。值得赏金,所以给我一个。非常感谢。 “你之前好像做过快进操作。” 事实证明这是对的,虽然我当时没有意识到。现在,在您的帮助下,我知道如果/当这种情况再次发生时要注意什么。但我注意到了一些事情......这个语法git checkout master; git merge develop不应该是git checkout master && git merge develop吗?我尝试了前者并收到了一些 Git 错误消息。后者运行良好。
“不过,您可能需要考虑使用一个比开发更有意义的名称。” 你说得对。仅供参考,我通常这样做,但在这种情况下,我正在处理必须在“生产”环境中测试的代码(即安装后)。因此,我每隔几分钟或更频繁地提交和推动;多个分支将使工作的复杂性成倍增加。换句话说,我需要保持“接近金属”的状态。也就是说,还有更多这样的内容,我可能会厌倦并在此期间切换到master(现在我有你的解决方案作为观点)。
...或者我可以创建一个功能分支并临时将该分支设置为我的管道中的构建触发器。嗯,我得考虑一下。这可能是明智之举。
@InteXX:sh / bash 语法cmd1 && cmd2 表示当且仅当 cmd1 返回成功退出状态时运行 cmd2,通常是个好主意。我不知道如何在 Windows shell 中做到这一点。 :-) cmd1; cmd2 表示运行 cmd1,然后运行 cmd2,即使 cmd1 失败,所以是的,&& 在这里更好(因为 git checkout 可能会失败,如果它失败了,那将停止git merge)。以上是关于for循环提交ajax,为啥只有第一次能够提交,后面的循环都没有提交到后台,但是for执行完了?急急急!的主要内容,如果未能解决你的问题,请参考以下文章