揭秘SQL Server 2014都有哪些新特性
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了揭秘SQL Server 2014都有哪些新特性相关的知识,希望对你有一定的参考价值。
1、内存数据库
在传统的数据库表中,由于磁盘的物理结构限制,表和索引的结构为B-Tree,这就使得该类索引在大并发的OLTP环境中显得非常乏力,虽然有很多办法来解决这类问题,比如说乐观并发控制,应用程序缓存,分布式等。但成本依然会略高。而随着这些年硬件的发展,现在服务器拥有几百G内存并不罕见,此外由于NUMA架构的成熟,也消除了多CPU访问内存的瓶颈问题,因此内存数据库得以出现。
内存的学名叫做RandomAccess Memory(RAM),因此如其特性一样,是随机访问的,因此对于内存,对应的数据结构也会是Hash-Index,而并发的隔离方式也对应的变成了MVCC,因此内存数据库可以在同样的硬件资源下,Handle更多的并发和请求,并且不会被锁阻塞,而SQLServer 2014集成了这个强大的功能,并不像Oracle的TimesTen需要额外付费,因此结合SSDAS Buffer Pool特性,所产生的效果将会非常值得期待。
SQLServer内存数据库的表现形式
在SQL Server的Hekaton引擎由两部分组成:内存优化表和本地编译存储过程。虽然Hekaton集成进了关系数据库引擎,但访问他们的方法对于客户端是透明的,这也意味着从客户端应用程序的角度来看,并不会知道Hekaton引擎的存在。如图1所示。
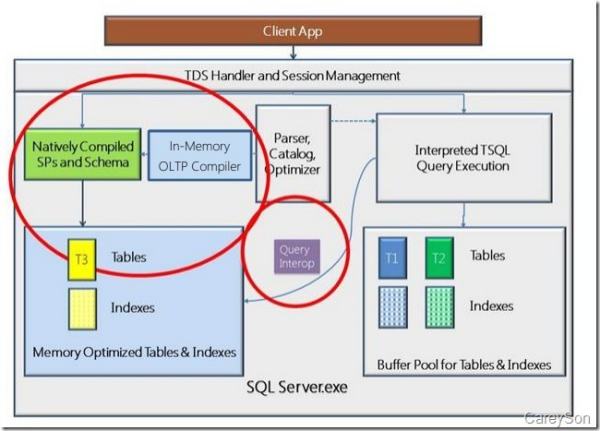
图1.客户端APP不会感知Hekaton引擎的存在
首先内存优化表完全不会再存在锁的概念(虽然之前的版本有快照隔离这个乐观并发控制的概念,但快照隔离仍然需要在修改数据的时候加锁),此外内存优化表Hash-Index结构使得随机读写的速度大大提高,另外内存优化表可以设置为非持久内存优化表,从而也就没有了日志(适合于ETL中间结果操作,但存在数据丢失的危险)
下面我们来看创建一个内存优化表:
首先,内存优化表需要数据库中存在一个特殊的文件组,以供存储内存优化表的CheckPoint文件,与传统的mdf或ldf文件不同的是,该文件组是一个目录而不是一个文件,因为CheckPoint文件只会附加,而不会修改,如图2所示。
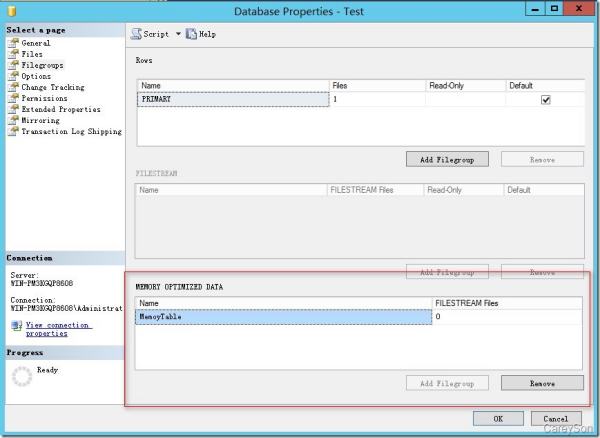
图2.内存优化表所需的特殊文件组
我们再来看一下内存优化文件组的样子,如图3所示。
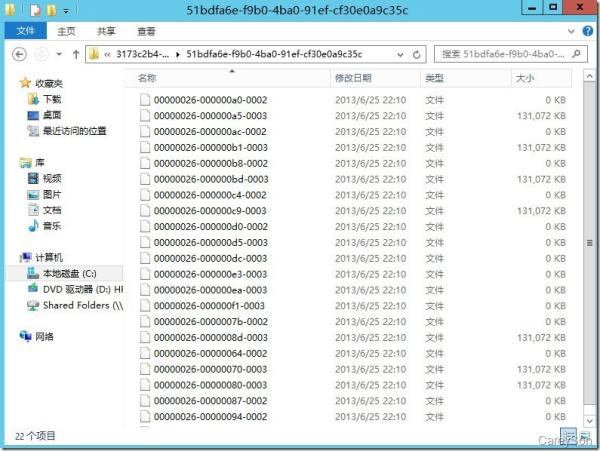
图3.内存优化文件组
有了文件组之后,接下来我们创建一个内存优化表,如图4所示。
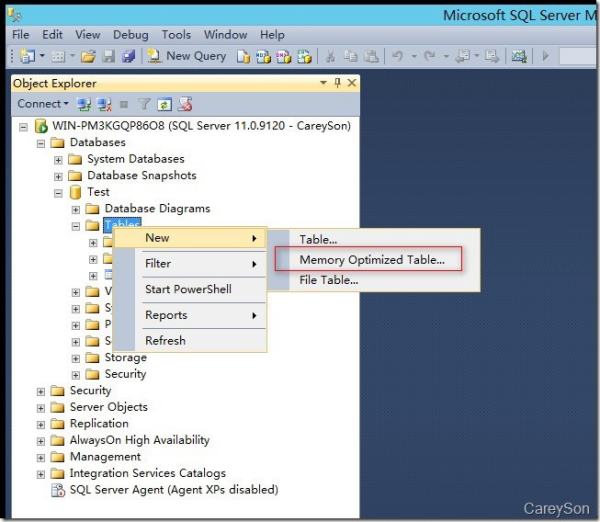
图4.创建内存优化表
目前SSMS还不支持UI界面创建内存优化表,因此只能通过T-SQL来创建内存优化表,如图5所示。

图5.使用代码创建内存优化表
当表创建好之后,就可以查询数据了,值得注意的是,查询内存优化表需要snapshot隔离等级或者hint,这个隔离等级与快照隔离是不同的,如图6所示。
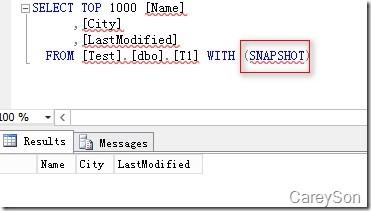
图6.查询内存优化表需要加提示
此外,由创建表的语句可以看出,目前SQLServer 2014内存优化表的HashIndex只支持固定的Bucket大小,不支持动态分配Bucket大小,因此这里需要注意。
与内存数据库不兼容的特性
目前来说,数据库镜像和复制是无法与内存优化表兼容的,但AlwaysOn,日志传送,备份还原是完整支持。
性能测试
上面扯了一堆理论,大家可能都看郁闷了。下面我来做一个简单的性能测试,来比对使用内存优化表+本地编译存储过程与传统的B-Tree表进行对比,B-Tree表如图7所示,内存优化表+本地编译存储过程如图8所示。
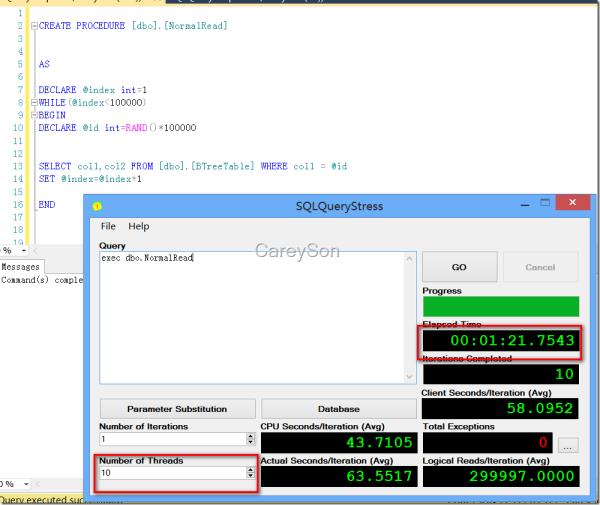
图7.传统的B-Tree表

图8.内存优化表+本地编译存储过程
因此不难看出,内存优化表+本地编译存储过程有接近几十倍的性能提升。
参考技术A 主要在BI和云计算两个方向有大的改动。以下是转载:
SQL Server 2014中已经增加了对物理IO资源的控制,这个功能在私有云的数据库服务器上的作用体现得尤为重要,它能够为私有云用户提供有效的控制、分配,并隔离物理IO资源。下面来详细了解一下SQL Server 2014的新特性。
方法/步骤
内置内存技术:
集成内存OLTP技术,针对数据仓库而改善内存列存储技术;通过 Power Pivot实现内存BI等。美国一家博彩企业,通过内置存储技术,将每秒请求量从15000增加到250000,不仅大幅改善了用户体验,而且还获得了压倒对手的竞争力。
安全方面:
连续5年漏洞最少的数据库,市场占有率是46%,全球使用率极高。
扩展性方面:
计算扩展,高达640颗逻辑处理器,每虚拟机64颗vCPU,没虚拟机1TB内存,没集群64个节点;网络扩展:网络虚拟化技术提升灵活性与隔离;分配最小和最大带宽;有以及存储扩展都有很大提升。
BI:
企业可以通过熟悉的工具,如Office中的Excel以及Office 365中的Power BI,加速分析以快速获取突破性的洞察力,并提供基于移动设备的访问。
混合云方面:
跨越客户端和云端,Microsoft SQL Server 2014为企业提供了云备份以及云灾难恢复等混合云应用场景,无缝迁移关键数据至Microsoft Azure。企业可以通过一套熟悉的工具,跨越整个应用的生命周期,扩建、部署并管理混合云解决方案,实现企业内部系统与云端的自由切换。
与闪存卡搭配:
与LSI Nytro闪存卡相结合使用,则可满足云中最苛刻工作负载对性能的要求,消除企业I/O瓶颈,加速交易,充分挖掘数据价值,使客户受益。本回答被提问者和网友采纳
前端哈希算法大揭秘
作者简介

陈龙
转转平台运营部前端负责人,9年前端经验,含3年技术管理,平时喜欢研究一些技术方案,写写文章,做做分享。
背景
前端做流量AB测
AB测应该注意什么?
-
保证流量分配尽量准确 -
命中某项规则的用户,下次访问依旧是命中相同规则 -
每个AB测相互独立
有同学说了:让server做不就行了
那我想问:前端不能做么?
于是我就打算在前端实现。
怎么做分流
通常第一时间会想到:哈希算法
然后再将生成的hash值转换成0-99间的数字,再按比例分配就可以了
另外,误差要尽可能的小
比如:10W个hash值,转换后落在每个区间[0-9] [10-19] ..., [90-99] 各10%
当hash算法是现成的,直接拿过来用就行了
那问题来了,为什么hash能做到?
hash在数据结构中的含义和密码学中的含义并不相同,所以在这两种不同的领域里,算法的设计侧重点也不同
什么是hash算法
Hash算法也被称为散列算法,就是把任意长度的字符串,通过散列算法,变换成固定长度的输出,而输出值没有任何规律,这就是散列值
虽然被称为算法,但实际上它更像是一种思想。
Hash算法没有一个固定的公式,只要符合散列思想的算法都可以被称为是Hash算法
什么是散列思想?
对于每一个值,都可以唯一地映射到散列表中的一个位置,而且让位置分配尽可能的均匀
hash算法的特点
它是一种压缩映射,散列值的空间远远小于输入空间,不同的输入可能会有相同的输出。
-
抗碰撞能力:对于任意两个不同的数据块,其hash值相同的可能性极小;对于一个给定的数据块,找到和它hash值相同的数据块极为困难。
-
抗篡改能力:对于一个数据块,哪怕只改动其一个比特位,其hash值的改动也会非常大。
-
固定输出长度:无论多长的输入,输出一定是固定长度
-
单向唯一:它是一种单向密码体制,即它是一个从明文到密文的不可逆的映射,只有加密过程,没有解密过程
-
相同输入相同输出:同样的输入,每次都有同样的输出
以MD算法为例:
MD5("version1") = "966634ebf2fc135707d6753692bf4b1e";
MD5("version2") = "2e0e95285f08a07dea17e7ee111b21c8";
使用类型
在数据结构中
hash出来的key,只要保证value大致均匀的放在不同的桶里就可以了
比如hashmap,hash值(key)存在的目的是加速键值对的查找,key的作用是为了将元素适当地放在各个桶里,对于抗碰撞的要求没有那么高。
在密码学中
hash算法的作用主要是用于消息摘要和签名,换句话说,它主要用于对整个消息的完整性进行校验。
比如存储用户的账户密码信息,数据库里是不会存储明文的,通常是存储加密后的md5值,后台会把用户输入的账户和密码做md5,然后和库里存储的md5值做比对。
常见的hash算法
MD4
MD4(RFC 1320)是 MIT 的Ronald L. Rivest在 1990 年设计的,MD 是 Message Digest(消息摘要) 的缩写。它适用在32位字长的处理器上用高速软件实现——它是基于 32位操作数的位操作来实现的。
MD5
MD5(RFC 1321)是 Rivest 于1991年对MD4的改进版本。它对输入仍以512位分组,其输出是4个32位字的级联,与 MD4 相同。MD5比MD4来得复杂,并且速度较之要慢一点,但更安全,在抗分析和抗差分方面表现更好。
SHA-1
SHA1是由NIST NSA设计的,SHA1对任意长度明文的预处理和MD5的过程是一样的,即预处理完后的明文长度是512位的整数倍,但是有一点不同,那就是SHA1的原始报文长度不能超过2的64次方,然后SHA1生成160位的报文摘要。SHA1算法简单而且紧凑,容易在计算机上实现。
因为我用到的是sha-1算法,所以本次分享是基于sha-1算法的分析
SHA-1算法
算法介绍
SHA-1(英语:Secure Hash Algorithm 1,中文名:安全散列算法1)是一种密码散列函数,美国国家安全局设计,并由美国国家标准技术研究所(NIST)发布为联邦数据处理标准(FIPS)。SHA-1可以生成一个被称为消息摘要的160位(20字节)散列值,散列值通常的呈现形式为40个十六进制数。(来自百度)
SHA1的算法已被破解,出于安全考虑官方推荐用SHA2代替,
但作为不涉及安全性的功能(如AB测分流)依旧不失为一种选择
本次算法分析主要是跟大家一起了解Hash算法世界,并非要破解
里面会用到大量的位运算,如果不熟悉的同学,可以参看前面的文章
算法思路
-
对任意长度的明文字符串,转换成数字(32位二进制),并进行初始化分组, -
将初始分组后的数组每16个元素分为一组,不足16个元素部分会补齐 -
申请5个32位的计算因子,记为A、B、C、D、E。 -
每个分组进行80次复杂混合运算,每个分组计算完成后,得出新的A、B、C、D、E -
将新的A、B、C、D、E和老的A、B、C、D、E分别进行求和运算,得出新的计算因子,并重复(4 到 5)的操作,得出最终的A、B、C、D、E -
将最终得出的A、B、C、D、E每个元素进行8次混合运算,得出40位16进制hash码
js-sha1算法
var chrsz = 8; /* bits per input character. 8 - ASCII; 16 - Unicode */
function hex_sha1(s) {
return binb2hex(core_sha1(str2binb(s), s.length * chrsz));
}
/*
* Convert an 8-bit or 16-bit string to an array of big-endian words
* In 8-bit function, characters >255 have their hi-byte silently ignored.
*/
function str2binb(str) {
var bin = Array();
var mask = (1 << chrsz) - 1;
for (var i = 0; i < str.length * chrsz; i += chrsz)
bin[i >> 5] |= (str.charCodeAt(i / chrsz) & mask) << (24 - i % 32);
return bin;
}
/*
* Bitwise rotate a 32-bit number to the left.
*/
function rol(num, cnt) {
return (num << cnt) | (num >>> (32 - cnt));
}
/*
* Calculate the SHA-1 of an array of big-endian words, and a bit length
*/
function core_sha1(x, len) {
/* append padding */
x[len >> 5] |= 0x80 << (24 - len % 32);
x[((len + 64 >> 9) << 4) + 15] = len;
var w = Array(80);
var a = 1732584193;
var b = -271733879;
var c = -1732584194;
var d = 271733878;
var e = -1009589776;
for (var i = 0; i < x.length; i += 16) {
var olda = a;
var oldb = b;
var oldc = c;
var oldd = d;
var olde = e;
for (var j = 0; j < 80; j++) {
if (j < 16) w[j] = x[i + j];
else w[j] = rol(w[j - 3] ^ w[j - 8] ^ w[j - 14] ^ w[j - 16], 1);
var t = safe_add(safe_add(rol(a, 5), sha1_ft(j, b, c, d)), safe_add(safe_add(e, w[j]), sha1_kt(j)));
e = d;
d = c;
c = rol(b, 30);
b = a;
a = t;
}
a = safe_add(a, olda);
b = safe_add(b, oldb);
c = safe_add(c, oldc);
d = safe_add(d, oldd);
e = safe_add(e, olde);
}
return Array(a, b, c, d, e);
}
/*
* Add integers, wrapping at 2^32. This uses 16-bit operations internally
* to work around bugs in some JS interpreters.
*/
function safe_add(x, y) {
var lsw = (x & 0xFFFF) + (y & 0xFFFF);
var msw = (x >> 16) + (y >> 16) + (lsw >> 16);
return (msw << 16) | (lsw & 0xFFFF);
}
/*
* Perform the appropriate triplet combination function for the current
* iteration
*/
function sha1_ft(t, b, c, d) {
if (t < 20) return (b & c) | ((~b) & d);
if (t < 40) return b ^ c ^ d;
if (t < 60) return (b & c) | (b & d) | (c & d);
return b ^ c ^ d;
}
/*
* Determine the appropriate additive constant for the current iteration
*/
function sha1_kt(t) {
return (t < 20) ? 1518500249 : (t < 40) ? 1859775393 : (t < 60) ? -1894007588 : -899497514;
}
/*
* Convert an array of big-endian words to a hex string.
*/
function binb2hex(binarray) {
var hex_tab = hexcase ? "0123456789ABCDEF" : "0123456789abcdef";
var str = "";
for (var i = 0; i < binarray.length * 4; i++) {
str += hex_tab.charAt((binarray[i >> 2] >> ((3 - i % 4) * 8 + 4)) & 0xF) + hex_tab.charAt((binarray[i >> 2] >> ((3 - i % 4) * 8)) & 0xF);
}
return str;
}
ok,既然这是接口方法,我们就从这里开始分析
function hex_sha1(s) {
return binb2hex(core_sha1(str2binb(s), s.length * chrsz));
}
首先是str2binb方法
str2binb方法
/*
* Convert an 8-bit or 16-bit string to an array of big-endian words
* In 8-bit function, characters >255 have their hi-byte silently ignored.
*/
function str2binb(str) {
var bin = Array(); // 创建一个空数组
var mask = (1 << chrsz) - 1;
for (var i = 0; i < str.length * chrsz; i += chrsz)
bin[i >> 5] |= (str.charCodeAt(i / chrsz) & mask) << (24 - i % 32);
return bin;
}
创建一个bin空数组,用于存储分组后的内容(且转换成2进制数)
var chrsz = 8;
...
var mask = (1 << chrsz) - 1;
计算与运算值
(1 << 8) - 1 计算后为:255
for (var i = 0; i < str.length * chrsz; i += chrsz)
bin[i >> 5] |= (str.charCodeAt(i / chrsz) & mask) << (24 - i % 32);
遍历字符串,因为每个字符用8位表示,所以每次循环最后面是 i += chrsz,当前坐标要加8
str.charCodeAt(codeIndex)
charCodeAt() 方法: 可返回指定位置的字符的 Unicode 编码。这个返回值是 0 - 65535 之间的整数
str.charCodeAt(i / chrsz) & mask
因为chrsz是8的倍数,所以,i / chrsz 就是字符串中单个字符的索引值
该句意思为:求出单个字符的unicode编码值,并与255做与运算,这步其实就是把字符串转换成了数字
与255做与运算含义
255 转换成二进制为:11111111
任何2进制数与之做与操作,都以被与操作数为主,因为 x & 1 = x
相当于:将字符的Unicode编码值做了255的求余操作
ok ,我们继续
24 - i % 32
i对32求余
为什么是32:位运算32位,多余位数会被舍弃
因为i是8的整数
所以 i % 32 最终的结果只能是(0 8 16 24)
(str.charCodeAt(i / chrsz) & mask) << (24 - i % 32)
这句话总结一下:将字符对应的unicode编码做255求余,并左移(0 8 16 24)位
该位移操作会产生差异很大的数字。
ok,我们继续看for循环内部
bin[i >> 5] |= (str.charCodeAt(i / chrsz) & mask) << (24 - i % 32)
|= 是啥意思?即对等号左右两边做或操作,并赋值给左边变量
var a = 3 // 011
var b = 5 // 101
a |= b // 111 等于7
i >> 5: 带符号右移5位,而2的5次方为32,也就是说,小于2的5次方以内均为0
因为for循环,累加逻辑为 i += chrsz
这意味着,i = 0 8 16 24 的时候,位移后结果都为0
再往后枚举一下,即 i = 32 40 48 56 时,位移后为1
也就是说:bin[x]的单个元素由相邻的4个字符,连续做或运算得到
最终形成一个一维数组
var chrsz = 8; /* bits per input character. 8 - ASCII; 16 - Unicode */
/*
* Convert an 8-bit or 16-bit string to an array of big-endian words
* In 8-bit function, characters >255 have their hi-byte silently ignored.
*/
function str2binb(str) {
var bin = Array(); // 创建一个空数组
var mask = (1 << chrsz) - 1;
for (var i = 0; i < str.length * chrsz; i += chrsz)
bin[i >> 5] |= (str.charCodeAt(i / chrsz) & mask) << (24 - i % 32);
return bin;
}
str2binb,解读如下:
-
将一个字符串,拆分成若干个以4为长度的区间 -
在这区间的4个字符中 -
等于分别乘以:1, 255, 65536, 16777216 -
unicode 取值范围(0 - 65535) -
与255做与运算相于对255求余 -
将每个字符的unicode编码和255做与运算 -
并依次左移(0,8,16,24)位 -
将这4个字符计算的结果依次做或操作 -
将4次或运算的结果存入数组
每个元素都是一个较大的(正负)值
总结
str2binb方法将一个字符串转换成数字,并进行首次压缩计算,形成长度为(Math.ceil(str.lenght / 4))的数组
ok,我们,继续
/*
* These are the functions you'll usually want to call
* They take string arguments and return either hex or base-64 encoded strings
*/
function hex_sha1(s) {
return binb2hex(core_sha1(str2binb(s), s.length * chrsz));
}
下一步这个逻辑
core_sha1(str2binb(s), s.length * chrsz)
接下来我们看core_sha1方法
core_sha1方法
/*
* Calculate the SHA-1 of an array of big-endian words, and a bit length
*/
function core_sha1(x, len) {
/* append padding */
x[len >> 5] |= 0x80 << (24 - len % 32);
x[((len + 64 >> 9) << 4) + 15] = len;
var w = Array(80);
var a = 1732584193;
var b = -271733879;
var c = -1732584194;
var d = 271733878;
var e = -1009589776;
for (var i = 0; i < x.length; i += 16) {
var olda = a;
var oldb = b;
var oldc = c;
var oldd = d;
var olde = e;
for (var j = 0; j < 80; j++) {
if (j < 16) w[j] = x[i + j];
else w[j] = rol(w[j - 3] ^ w[j - 8] ^ w[j - 14] ^ w[j - 16], 1);
var t = safe_add(safe_add(rol(a, 5), sha1_ft(j, b, c, d)), safe_add(safe_add(e, w[j]), sha1_kt(j)));
e = d;
d = c;
c = rol(b, 30);
b = a;
a = t;
}
a = safe_add(a, olda);
b = safe_add(b, oldb);
c = safe_add(c, oldc);
d = safe_add(d, oldd);
e = safe_add(e, olde);
}
return Array(a, b, c, d, e);
}
这个方法就是sha1的核心算法了
参数:x(前一步初步压缩计算后的数组)
参数:len(字符串长度乘以8)
开始处理数组
x[len >> 5] |= 0x80 << (24 - len % 32);
0x80 换算成10进制为 128
(24-len % 32) len是8的倍数,所以len % 32结果只能是(0 8 16 24)
也就是说 (24-len % 32) 结果为(24 16 8 0)
0x80 << 24 // -2147483648(出现负数了)
0x80 << 16 // 8388608
0x80 << 8 // 32768
0x80 << 0 // 128
x 和 len之间有什么关系?
x 是之前字符串每4个字符 分组运算后的数组。长度等于: Math.ceil(str.length/4)
len 是字符串长度乘以8
也就是说 len可能小于等于x长度的32倍
所以,len >> 5 会有2种情况
-
字符串长度能被4整除:x[len >> 5]将在末位额外添加一个undefined素 -
字符串长度不能被4整除:x[len >> 5]将指定数组最后一个元素
undefined和如何数做或操作都等于比对数字
这句话的含义:无论字符串长度能否被4整除,保持x数组最后一位有相同算法
-
能被整除,添加1位,值为 0x80 << (24 - len % 32) -
不能整除,将最后一位修改,和 0x80 << (24 - len % 32) 做或操作
继续往下看
x[((len + 64 >> 9) << 4) + 15] = len;
len + 64 >> 9 将长度加64,再右移9位,2 ** 9 = 512,512 - 64 = 448
而len = 字符串长度 x 8, 再除以8, 448 / 8 = 56
也就是说,长度小于56的字符串换算完均为0,长度每增加512,结果加1
(len + 64 >> 9) << 4,再对结果左移4位
// 如:字符串长度为40,x的长度为10,len的长度为320,
// 经过这一步计算,会像数组中补充一个元素,即长度为 11
x[len >> 5] |= 0x80 << (24 - len % 32) 为 x[10] |= -2147483648
// 因为x长度总共为11,这里设置了第16个元素
x[((len + 64 >> 9) << 4) + 15] 为 x[15] = 320
// 如:字符串长度为501,x的长度为126,len的长度为4008,
x[len >> 5] |= 0x80 << (24 - len % 32) 为 x[125] |= -2147483648
// 因为x长度总共为126,这里设置了第127个元素
x[((len + 64 >> 9) << 4) + 15] 为 x[127] = 4008
// 如:字符串长度为743,x的长度为186,len的长度为5944,
x[len >> 5] |= 0x80 << (24 - len % 32) 为 x[185] |= -2147483648
// 因为x长度总共为186,这里设置了第191个元素
x[((len + 64 >> 9) << 4) + 15] 为 x[191] = 5944
因为这步操作导致x数组长度增加,多了一些empty元素和len
比如:x长度为10,添加了一个 x[15] = 320
这就导致x长度由10变为16、第x[10]到位x[15]为empty元素
这么写的含义(个人理解):
后续因为是每16个元素做一个分组,当数组无法被16完全分组时,剩下的元素会被舍弃
为了避免这种情况,通过补齐元素,来让数组中的内容全部参与运算
ok,我们继续
var w = Array(80); // 申请一个80长度的数组
var a = 1732584193; // 01100111010001010010001100000001
var b = -271733879; // 10010000001100100101010001110111
var c = -1732584194; // 11100111010001010010001100000010
var d = 271733878; // 00010000001100100101010001110110
var e = -1009589776; // 10111100001011010001111000010000
// 遍历数组
for (var i = 0; i < x.length; i += 16) {
// 拷贝一份上面的变量
var olda = a;
var oldb = b;
var oldc = c;
var oldd = d;
var olde = e;
for (var j = 0; j < 80; j++) {
if (j < 16) w[j] = x[i + j];
else w[j] = rol(w[j - 3] ^ w[j - 8] ^ w[j - 14] ^ w[j - 16], 1);
var t = safe_add(safe_add(rol(a, 5), sha1_ft(j, b, c, d)), safe_add(safe_add(e, w[j]), sha1_kt(j)));
e = d;
d = c;
c = rol(b, 30);
b = a;
a = t;
}
a = safe_add(a, olda);
b = safe_add(b, oldb);
c = safe_add(c, oldc);
d = safe_add(d, oldd);
e = safe_add(e, olde);
}
首先定义了5个常量
然后整体看2个for循环
for (var i = 0; i < x.length; i += 16) {
...
for (var j = 0; j < 80; j++) {
...
}
}
i += 16 表示将传入的数组,每16个元素为一个分组
每个分组做80次运算
我们先看里面的for循环
for (var j = 0; j < 80; j++) {
if (j < 16) w[j] = x[i + j];
else w[j] = rol(w[j - 3] ^ w[j - 8] ^ w[j - 14] ^ w[j - 16], 1);
var t = safe_add(safe_add(rol(a, 5), sha1_ft(j, b, c, d)), safe_add(safe_add(e, w[j]), sha1_kt(j)));
e = d;
d = c;
c = rol(b, 30);
b = a;
a = t;
}
第一句
if (j < 16) w[j] = x[i + j];
j在0-15时,假设i取值,看下规律
// 当i = 0时
w[0] = x[0]
w[1] = x[1]
w[2] = x[2]
...
// 当i = 1时
w[0] = x[1]
w[1] = x[2]
w[2] = x[3]
...
将x,带有偏移量的赋值给w数组的前16个元素,
将x的每个分组的元素复制到w中,因为后面的运算会用到
如果数组长度不足,就会返回undefined
再看第二句
当16 <= j < 80 时
else w[j] = rol(w[j - 3] ^ w[j - 8] ^ w[j - 14] ^ w[j - 16], 1);
关于w[j - 3] ^ w[j - 8] ^ w[j - 14] ^ w[j - 16]部分
j = 16时,w[13] ^ w[8] ^ w[2] ^ w[0]
j = 17时,w[14] ^ w[9] ^ w[3] ^ w[1]
j = 18时,w[15] ^ w[10] ^ w[4] ^ w[2]
...
j = 59时,w[56] ^ w[51] ^ w[45] ^ w[43]
四个固定间隔元素做异或操作
将异或计算结果,做rol操作,设置在w剩下的64个位置中
rol(w[j - 3] ^ w[j - 8] ^ w[j - 14] ^ w[j - 16], 1)
也就是说:剩下的64的元素,也是由该16个分组元素,通过算法得来的
我先看下rol方法
/*
* Bitwise rotate a 32-bit number to the left.
*/
function rol(num, cnt) {
return (num << cnt) | (num >>> (32 - cnt));
}
看注释:按位向左旋转32位数字
先看几个例子
// 小于32位
rol(45678765, 1) // 91357530
45678765二进制:10101110010000000010101101(26位)
45678765 << 1 // 91357530 即:101011100100000000101011010
45678765 >>> 31 // 0
91357530 | 0 = 91357530
// 大于等于32位
rol(1732584193, 2) // -1659597820
1732584193二进制:1100111010001010010001100000001(31位)
1732584193 << 2 // -1659597820
1)先左移2位(去掉左边多余内位数,右边补0)
2)10011101000101001000110000000100
3)符号位变成1,负数需要取反
4)11100010111010110111001111111011
5) 再+1
6)11100010111010110111001111111100
7)-1659597819
总结
向左移动 cnt 位,将被舍弃的元素依次补到队尾
-
当num 左移结果小于32位时,该方法等于 num << cnt(因为 num >>> (32 - cnt)一定是0) -
只有num 左移结果大于等于32位时,才有运算
因为cnt固定为1,所以num就固定无符号右移31位,所以值只可能为0或1
继续
接下来是
safe_add(safe_add(rol(a, 5), sha1_ft(j, b, c, d)), safe_add(safe_add(e, w[j]), sha1_kt(j)));
方法嵌套太多了,先拆一下
// 【第一句】
const leftVal = safe_add(rol(a, 5), sha1_ft(j, b, c, d))
// 【第二句】
const rightVal = safe_add(safe_add(e, w[j]), sha1_kt(j))
safe_add(leftVal, rightVal)
再对【第一句】继续拆分
safe_add(rol(a, 5), sha1_ft(j, b, c, d))
拆分成
const leftVal = rol(a, 5)
const rightVal = sha1_ft(j, b, c, d)
safe_add(leftVal, rightVal)
这就很明确了,rol方法前面介绍过
rol(a, 5)
// 即为
rol(1732584193, 5) // -391880660
将参数a循环左移5位
下面看看
sha1_ft方法
/*
* Perform the appropriate triplet combination function for the current
* iteration
*/
function sha1_ft(t, b, c, d) {
if (t < 20) return (b & c) | ((~b) & d);
if (t < 40) return b ^ c ^ d;
if (t < 60) return (b & c) | (b & d) | (c & d);
return b ^ c ^ d;
}
注释说:为当前数组3元组合
这里的t就是前面的j,即:取值在[0-79]之间
// b、c、d值分别如下
var b = -271733879;
var c = -1732584194;
var d = 271733878;
b & c // -2004318072
~b // 271733878
(~b) & d // 271733878
// t:[0, 20) 时
(b & c) | ((~b) & d) // -1732584194
// t:[20, 40) 或 [60, 80)时
b ^ c ^ d // 1732584193
// t:[40, 60)时
(b & c) | (b & d) | (c & d) // -1732584194
总结
该方法就是将传入的 b c d,在不同条件下做各种组合的位运算
接下来看
safe_add方法
/*
* Add integers, wrapping at 2^32. This uses 16-bit operations internally
* to work around bugs in some JS interpreters.
*/
function safe_add(x, y) {
var lsw = (x & 0xFFFF) + (y & 0xFFFF);
var msw = (x >> 16) + (y >> 16) + (lsw >> 16);
return (msw << 16) | (lsw & 0xFFFF);
}
安全累加,这个方法很秀
var lsw = (x & 0xFFFF) + (y & 0xFFFF);
0xFFFF // 1111 1111 1111 1111 十进制为 65535
x & 0xFFFF 意味着对x做65535的求余,保证结果在 -65535 到 65535 之内
这句表示:将传入的x和y,进行低位16位的求和
var msw = (x >> 16) + (y >> 16) + (lsw >> 16);
(x >> 16) + (y >> 16)表示两个数高位16位内容求和计算
msw 为低位16位求和计算,计算结果可能会超出16位,
所以在高位计算时,要加上可能进位的内容,即 (lsw >> 16)
所以这句表示:表示完整高位16位的累加运算
return (msw << 16) | (lsw & 0xFFFF);
这句表示:将高位16位和低位16位运算返回
总结
该方法表示安全累加,即使再大的数值,计算完也控制在32位之内
sha1_kt方法
/*
* Determine the appropriate additive constant for the current iteration
*/
function sha1_kt(t) {
return (t < 20) ? 1518500249 : (t < 40) ? 1859775393 : (t < 60) ? -1894007588 : -899497514;
}
转换一下
function sha1_kt(t) {
if (t < 20) return 1518500249;
if (t < 40) return 1859775393;
if (t < 60) return -1894007588;
else return -899497514
}
这就很清楚了,不同情况返回不同的常数
再回到之前拆分之后的代码
// 【第一句】
const leftVal = safe_add(rol(a, 5), sha1_ft(j, b, c, d))
// 【第二句】
const rightVal = safe_add(safe_add(e, w[j]), sha1_kt(j))
safe_add(leftVal, rightVal)
leftVal
-
rol(a, 5):将常数a,循环左移5位 -
sha1_ft(j, b, c, d):根据j,将b c d做不同的3元运算 -
safe_add(rol(a, 5), sha1_ft(j, b, c, d)):将两个数安全累加,
rightVal
-
safe_add(e, w[j]):将常数e和w[j]安全累加 -
sha1_kt(j):根据j返回不同常数 -
safe_add(safe_add(e, w[j]), sha1_kt(j)):将两个数安全累加
safe_add(leftVal, rightVal)
-
将两边的数再进行安全累加 -
赋值给t
再整体看下内部的for循环
for (var j = 0; j < 80; j++) {
if (j < 16) w[j] = x[i + j];
else w[j] = rol(w[j - 3] ^ w[j - 8] ^ w[j - 14] ^ w[j - 16], 1);
var t = safe_add(safe_add(rol(a, 5), sha1_ft(j, b, c, d)), safe_add(safe_add(e, w[j]), sha1_kt(j)));
e = d;
d = c;
c = rol(b, 30);
b = a;
a = t;
}
-
t被多个值(a, b, c, d, e, j, w[j], "固定"常量),多次位运算和安全累加 -
随后更新abcde5个计算因子 -
e切换成d -
d切换成c -
c根据b重新计算 -
b切换成a -
将计算出的t付给a -
带到下一次计算
内部for循环总结
-
该for循环每次利用a, b, c, d, e, j, w[j], "固定"常量等计算出新的常量因子 -
再将新的常量因子带到下一次计算中 -
得出单组的a, b, c, d, e因子
/*
* Calculate the SHA-1 of an array of big-endian words, and a bit length
*/
function core_sha1(x, len) {
/* append padding */
x[len >> 5] |= 0x80 << (24 - len % 32);
x[((len + 64 >> 9) << 4) + 15] = len;
var w = Array(80);
var a = 1732584193;
var b = -271733879;
var c = -1732584194;
var d = 271733878;
var e = -1009589776;
for (var i = 0; i < x.length; i += 16) {
var olda = a;
var oldb = b;
var oldc = c;
var oldd = d;
var olde = e;
for (var j = 0; j < 80; j++) {
if (j < 16) w[j] = x[i + j];
else w[j] = rol(w[j - 3] ^ w[j - 8] ^ w[j - 14] ^ w[j - 16], 1);
var t = safe_add(safe_add(rol(a, 5), sha1_ft(j, b, c, d)), safe_add(safe_add(e, w[j]), sha1_kt(j)));
e = d;
d = c;
c = rol(b, 30);
b = a;
a = t;
}
a = safe_add(a, olda);
b = safe_add(b, oldb);
c = safe_add(c, oldc);
d = safe_add(d, oldd);
e = safe_add(e, olde);
}
return Array(a, b, c, d, e);
}
再整体看下外面的for循环
-
将单组80次计算后的a, b, c, d, e因子与旧的a, b, c, d, e因子安全累加,得到新的计算因子 -
将单组计算的a, b, c, d, e,代入到后面的组循环计算中 -
遍历完所有分组后,将最终计算的a, b, c, d, e以数组形式返回
OK 继续往后面看
function hex_sha1(s) {
return binb2hex(core_sha1(str2binb(s), s.length * chrsz));
}
最后来看下
binb2hex方法
var hexcase = 0
/*
* Convert an array of big-endian words to a hex string.
*/
function binb2hex(binarray) {
var hex_tab = hexcase ? "0123456789ABCDEF" : "0123456789abcdef";
var str = "";
for (var i = 0; i < binarray.length * 4; i++) {
str += hex_tab.charAt((binarray[i >> 2] >> ((3 - i % 4) * 8 + 4)) & 0xF) + hex_tab.charAt((binarray[i >> 2] >> ((3 - i % 4) * 8)) & 0xF);
}
return str;
}
因为hexcase固定为0,所以hex_tab值为 0123456789abcdef
将传入因子数组遍历, binarray长度为5, 乘4后,循环20次
str += hex_tab.charAt((binarray[i >> 2] >> ((3 - i % 4) * 8 + 4)) & 0xF) + hex_tab.charAt((binarray[i >> 2] >> ((3 - i % 4) * 8)) & 0xF);
该部分运算分为2部分
hex_tab.charAt((binarray[i >> 2] >> ((3 - i % 4) * 8 + 4)) & 0xF)
和
hex_tab.charAt((binarray[i >> 2] >> ((3 - i % 4) * 8)) & 0xF)
运算符顺序:逻辑运算符 > 位运算符(<< >> >>>)
先看第一部分
因为 i取值 0 到 19 之间, 所以 i >> 2 取值 0 到 4 之间
每4个区间取值相同,如 0-3 取值均为 0
hex_tab.charAt((binarray[i >> 2] >> ((3 - i % 4) * 8 + 4)) & 0xF) + hex_tab.charAt((binarray[i >> 2] >> ((3 - i % 4) * 8)) & 0xF)
举几个例子
i = 0 时 hex_tab.charAt(binarray[0] >> 28 & 0xF) + hex_tab.charAt(binarray[0] >> 24 & 0xF)
i = 1 时 hex_tab.charAt(binarray[0] >> 20 & 0xF) + hex_tab.charAt(binarray[0] >> 16 & 0xF)
i = 2 时 hex_tab.charAt(binarray[0] >> 12 & 0xF) + hex_tab.charAt(binarray[0] >> 8 & 0xF)
i = 3 时 hex_tab.charAt(binarray[0] >> 4 & 0xF) + hex_tab.charAt(binarray[0] >> 0 & 0xF)
无论将binary中的内容右移多少位,都将和0xF做与操作,最终返回0-15的数
根据计算后的索引值,每次累加 “0123456789abcdef” 中的2个字符
循环20次,最终返回一个长度为40的hash串
hash算法总结
为什么hash算法可以将哪怕只有1个字符不同的输入,输出却是颠覆式的
我个人总结为:
-
多次、高强度组合位运算 -
每次循环的计算因子都重新计算 -
完全打破字符串本身的内容规律
当然,理解比较简单:)
如何将一个hash值转换成0-99的数字
// 计算hash值
const hashStr = hex_sha1((Math.random() * 10**16).toString())
// 转换成10进制
const hashVal = parseInt(hashVal, 16)
// 因为SHA-1 hash串是个 40位的16进制,所以最大值为
const maxHashVal = 16 ** 40
// 转换成99的数字
const rst = Math.floor(hashVal / maxHashVal * 100)
看个例子:
var rst = {
'0_9': 0,
'10_19': 0,
'20_29': 0,
'30_39': 0,
'40_49': 0,
'50_59': 0,
'60_69': 0,
'70_79': 0,
'80_89': 0,
'90_99': 0
}
var maxHashVal = 16 ** 40
for (var i = 0; i < 100000; i++) {
var num = Math.floor(parseInt(hex_sha1(Math.random().toString()), 16) / maxHashVal * 100)
for (var j in rst) {
var arr = j.split('_')
var start = parseInt(arr[0])
var end = parseInt(arr[1])
if (num >= start && num <= end) {
rst[j] ++
break
}
}
}
console.log(rst)

最大值:10115;最小值:9877
(10115 - 9877) / 100000 = 0.00238
即误差为:0.238%,符合分布预期
注意:AB测独立性
AB测分流通常会用用户的唯一标识来计算
该唯一标识要保证登录与未登录时都一致(比如:token)
那么不同位置的AB测,虽然依据都是token
但可以通过加前缀来区分
// 首页AB测
hex_sha1(`index_${token}`)
// tab页AB测
hex_sha1(`tab_${token}`)
为什么加前缀?
前面已经提到,hash算法一大特性是相同输入,相同输出
假设有这样一个场景
入口M,要做AB测(符合A进入到M), 再对进入到M入口的用户做AB测(A访问M1页,B访问M2页)
如果不加前缀,两次AB测都是通过token来计算
那进入入口M的用户,符合正常分布
但第二个AB测,计算结果永远都是A,B没有人能访问到
所以,每次AB测,都要加一个区分性质的前缀
利用hash,不同输入,颠覆式输出的特性
OK,以上都是个人的一些理解,
算法确实比较复杂,给能看到最后的同学点赞:)
福利来了

扫描二维码
一个有意思的前端团队
以上是关于揭秘SQL Server 2014都有哪些新特性的主要内容,如果未能解决你的问题,请参考以下文章