Python 适合大数据量的处理吗
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python 适合大数据量的处理吗相关的知识,希望对你有一定的参考价值。
python可以处理大数据,python处理大数据不一定是最优的选择。适合大数据处理。而不是大数据量处理。 如果大数据量处理,需要采用并用结构,比如在hadoop上使用python,或者是自己做的分布式处理框架。
python的优势不在于运行效率,而在于开发效率和高可维护性。针对特定的问题挑选合适的工具,本身也是一项技术能力。
Python处理数据的优势(不是处理大数据):
1. 异常快捷的开发速度,代码量巨少
2. 丰富的数据处理包,不管正则也好,html解析啦,xml解析啦,用起来非常方便
3. 内部类型使用成本巨低,不需要额外怎么操作(java,c++用个map都很费劲)
4. 公司中,很大量的数据处理工作工作是不需要面对非常大的数据的
5. 巨大的数据不是语言所能解决的,需要处理数据的框架(hadoop, mpi)虽然小众,但是python还是有处理大数据的框架的,或者一些框架也支持python。

扩展资料:
Python处理数据缺点:
Python处理大数据的劣势:
1、python线程有gil,通俗说就是多线程的时候只能在一个核上跑,浪费了多核服务器。在一种常见的场景下是要命的:并发单元之间有巨大的数据共享或者共用(例如大dict)。
多进程会导致内存吃紧,多线程则解决不了数据共享的问题,单独的写一个进程之间负责维护读写这个数据不仅效率不高而且麻烦
2、python执行效率不高,在处理大数据的时候,效率不高,这是真的,pypy(一个jit的python解释器,可以理解成脚本语言加速执行的东西)能够提高很大的速度,但是pypy不支持很多python经典的包,例如numpy。
3. 绝大部分的大公司,用java处理大数据不管是环境也好,积累也好,都会好很多。
参考资料来源:百度百科-Python
大数据量处理使用python的也多。如果单机单核单硬盘大数据量(比如视频)处理。显然只能用c/c++语言了。
大数据与大数据量区别还是挺大的。 大数据意思是大数据的智慧算法和应用。 大数据量,早在50年前就有大数据量处理了。 中国大约在95年左右,大量引入PC机的大数据量处理。一个模型计算数据量大,而且计算时间通常超过一个星期,有时候要计算半年。
气象,遥感,地震,模式识别,模拟计算的数据量与计算量都是巨大的。当时远远超过互联网。 后来互联网发起起来以后数据量才上去。即使如此,数据的复杂度也还是比不上科学研究领域的数据。
python早些年就在科学研究和计算领域有大量的积累。所以现在python应用到大数据领域就是水到渠成。 参考技术B
题主所谓的大数据量,不知到底有多大的数据量呢?按照我的经验,Python处理个几亿条数据还是绰绰有余的。但,倘若题主想要处理PB级别的数据,单纯依靠Python是不行的,还需要一些分布式算法来进行辅助。

其实,大多数公司的数据量并不大,就拿我们数据分析师行业来说。大多数的数据分析师所处理的数据,很少有上百万的数据量。当然,也有一些数据分析师是要处理上万上亿的数据量的,但占比是没有前者多的。

因此,当今数据分析领域中最活跃的工具并不是Python,反而是Excel。当然,Excel作为数据的处理工具是有其独到之处。灵活的函数功能+一力降十会的数据透视表能让用户对Excel如视珍宝。

但很遗憾,Excel就有数据量大小的限定,Excel记录数事不能超过105万的。超过这个数据限制,要么分表统计,要么就使用sql或者Python来进行数据分析。
通常在工作中,我就经常将几百个表用python进行合并,做简单的清洗工作。而一旦清洗完毕,用抽样工具一抽我们就可以进行抽样以及数据分析了。
希望对你有所帮助,欢迎评论。
参考技术Cpython可以处理大数据,但是python处理大数据不一定是最优的选择

百万级别数据是小数据,python处理起来不成问题,python处理大数据还是有些问题的
Python的劣势:
绝大部分的大公司,用java处理大数据不管是环境也好,积累也好,都会好很多
python线程有gil,通俗说就是多线程的时候只能在一个跑道上跑,浪费了多跑道服务器。在一种常见的场景下是要命的:并发单元之间有巨大的数据共享或者共用,多进程会导致内存闪红,多线程则解决不了数据共享的问题,单独的写一个进程之间负责维护读写这个数据不仅效率不高而且麻烦
python执行效率不高,在处理大数据的时候,效率不高。
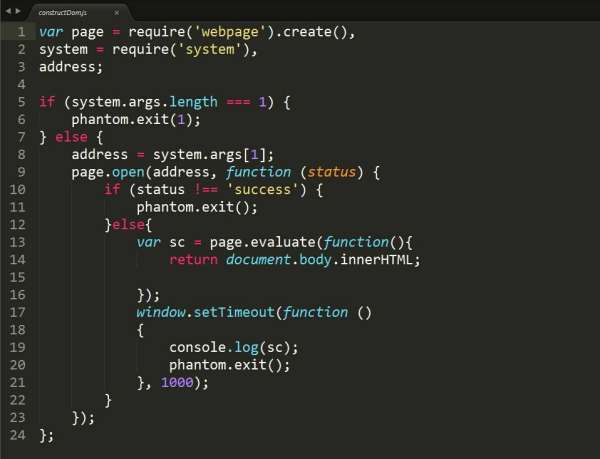
Python的优势:
python的优势不在于运行效率,而在于开发效率和高可维护性。针对特定的问题挑选合适的工具,本身也是一项技术能
异常快速的开发速度,代码量非常的少
丰富的数据处理包,用起来非常方便,不管正则也好,html解析,xml解析等
内部类型使用成本低,不需要额外怎么操作

公司中,很大量的数据处理工作工作是不需要面对非常大的数据的
Python处理大数据的劣势:
1、python线程有gil,通俗说就是多线程的时候只能在一个核上跑,浪费了多核服务器。在一种常见的场景下是要命的:并发单元之间有巨大的数据共享或者共用(例如大dict),多进程会导致内存吃紧,多线程则解决不了数据共享的问题,单独的写一个进程之间负责维护读写这个数据不仅效率不高而且麻烦
2、python执行效率不高,在处理大数据的时候,效率不高,这是真的,pypy(一个jit的python解释器,可以理解成脚本语言加速执行的东西)能够提高很大的速度,但是pypy不支持很多python经典的包,例如numpy(顺便给pypy做做广告,土豪可以捐赠一下PyPy - Call for donations)
3、绝大部分的大公司,用java处理大数据不管是环境也好,积累也好,都会好很多
Python处理数据的优势(不是处理大数据):
1、异常快捷的开发速度,代码量巨少
2、丰富的数据处理包,不管正则也好,html解析啦,xml解析啦,用起来非常方便
3、内部类型使用成本巨低,不需要额外怎么操作(java,c++用个map都很费劲)
4、公司中,很大量的数据处理工作工作是不需要面对非常大的数据的
5、巨大的数据不是语言所能解决的,需要处理数据的框架(hadoop, mpi。。。。)虽然小众,但是python还是有处理大数据的框架的,或者一些框架也支持python
6、编码问题处理起来太太太方便了
综上所述:
1、python可以处理大数据
2、python处理大数据不一定是最优的选择
3. python和其他语言(公司主推的方式)并行使用是非常不错的选择
4. 因为开发速度,你如果经常处理数据,而且喜欢linux终端,而且经常处理不大的数据(100m一下),最好还是学一下python本回答被提问者和网友采纳
blob存储大数据量的二进制文件时会丢失数据吗?
望大虾救助啊》》》》》》》》》》》》》
参考技术A BLOB 类型 的最长字节是 65,535 字节 即 64KB 超过就是丢失了如果需要更大的存储空间, 可以用 MEDIUMBLOB (16MB) LONGBLOB(4GB) 这种大存储类型的本回答被提问者采纳
以上是关于Python 适合大数据量的处理吗的主要内容,如果未能解决你的问题,请参考以下文章