TiCDC+Confluent同步数据到Oracle
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TiCDC+Confluent同步数据到Oracle相关的知识,希望对你有一定的参考价值。
使用 TiCDC 将 TiDB test 数据库多张表以 AVRO 格式发送到 Kafka 多个 Topic ,然后使用 Confluent 自带开源 connect 将 Kafka 多个 topic 数据实时写入到 Oracle 数据库,此链路支持实时数据 insert/delete/update/create table ddl/add column ddl 等。理论上此链路还可以支持下游为其它异构数据库。
暂时无法在飞书文档外展示此内容
一、通过TiCDC同步数据到kafka
1、通过tiup安装ticdc
1、编辑扩展文件
[root@172-16-5-146 tidb]# cat cdc.yaml
cdc_servers:
- host: 172.16.6.132
gc-ttl: 86400
data_dir: "/home/cdc-data"
2、扩展该文件
[root@172-16-5-146 tidb]# tiup cluster scale-out tidb-test cdc.yaml -uroot -p
3、查看该配置文件
[root@172-16-5-146 tidb]# tiup cluster display tidb-test
tiup is checking updates for component cluster ...
A new version of cluster is available:
The latest version: v1.10.3
Local installed version: v1.10.2
Update current component: tiup update cluster
Update all components: tiup update --all
Starting component `cluster`: /root/.tiup/components/cluster/v1.10.2/tiup-cluster display tidb-test
Cluster type: tidb
Cluster name: tidb-test
Cluster version: v6.1.0
Deploy user: tidb
SSH type: builtin
Dashboard URL: http://172.16.5.146:2399/dashboard
Grafana URL: http://172.16.5.146:3001
ID Role Host Ports OS/Arch Status Data Dir Deploy Dir
-- ---- ---- ----- ------- ------ -------- ----------
172.16.5.146:9099 alertmanager 172.16.5.146 9099/9095 linux/x86_64 Up /home/tidb/tidb-deploy/alertmanager-9099/data /home/tidb/tidb-deploy/alertmanager-9099
172.16.6.132:8300 cdc 172.16.6.132 8300 linux/x86_64 Up /home/cdc-data /home/tidb/tidb-deploy/cdc-8300
2、安装Confluent环境
2.1、下载安装文件
登陆 Confluent 官网: https://www.confluent.io/get-started/?product=software
下载 confluent-7.2.1.tar ,将下载的文件传输到服务器,解压缩为/root/software/confluent-7.2.1
[root@172-16-6-132 kafka]# ll
total 1952776
-rw-r--r-- 1 root root 104 Sep 21 13:50 c.conf
drwxr-xr-x 8 centos centos 92 Jul 14 12:07 confluent-7.2.1
-rw-r--r-- 1 root root 1999633201 Sep 21 10:33 confluent-7.2.1.tar.gz
-rw-r--r-- 1 root root 672 Sep 21 18:08 kafka.conf
[root@172-16-6-132 kafka]# du -sh *
4.0K c.conf
2.3G confluent-7.2.1
1.9G confluent-7.2.1.tar.gz
4.0K kafka.conf
2.2、配置环境变量
[root@172-16-6-132 kafka]#vim ~/.bashrc
# .bashrc
# User specific aliases and functions
alias rm=rm -i
alias cp=cp -i
alias mv=mv -i
# Source global definitions
if [ -f /etc/bashrc ]; then
. /etc/bashrc
fi
###最下边添加如下:
export CONFLUENT_HOME=/home/kafka/confluent-7.2.1
export PATH=$PATH:$CONFLUENT_HOME/bin
[root@172-16-6-132 kafka]# source ~/.bashrc
2.3、安装Confluent
cd /home/kafka/confluent-7.2.1/bin
./confluent-hub install --no-prompt confluentinc/kafka-connect-datagen:latest
2.4、启动Confluent
停止
confluent local services stop
启动
confluent local services start
查看状态
confluent local services status
##如果有启动某些组件失败的时候,需要指定组件重新启动
查看某个组件的日志
confluent local services schema-registry log -f
重新启动某个组件
confluent local services schema-registry start
查看某个组件的状态
confluent local services schema-registry status

2.5、Confluent组件介绍
[root@172-16-6-132 bin]# confluent local services
Manage Confluent Platform services.
Usage:
confluent local services [command]
Available Commands:
connect Manage Connect.
control-center Manage Control Center.
kafka Manage Apache Kafka®.
kafka-rest Manage Kafka REST.
ksql-server Manage ksqlDB Server.
list List all Confluent Platform services.
schema-registry Manage Schema Registry.
start Start all Confluent Platform services.
status Check the status of all Confluent Platform services.
stop Stop all Confluent Platform services.
top View resource usage for all Confluent Platform services.
zookeeper Manage Apache ZooKeeper™.
Global Flags:
-h, --help Show help for this command.
-v, --verbose count Increase verbosity (-v for warn, -vv for info, -vvv for debug, -vvvv for trace).
Use "confluent local services [command] --help" for more information about a command.
Connect 是本文后续使用的组件,它支持从kafka消费数据写入到下游组件,下游组件可以通过插件支持各种异构存储系统如:Oracle、MySQL、SQL Server、ES等
Control Center 是 Web 控制页面,用户可以在页面上管理 Kafka 集群和数据,管理 connect 任务和插件
Kafka 消息组件,不做介绍
ksqlDB Server 可以将 Kafka topic 映射为一张表,然后执行 SQL 做数据处理,此处不需要使用不过多介绍
Schema Registry 是 AVRO Schema 管理组件, Kafka 中消息 schema 变化时会往 schema registry 发送变更消息,数据同步组件发现 schema 变化之后会从 schema registry 获取最新的 schema 以便同步新 schema 数据到下游数据库
Zookeeper 元数据管理工具,支持 Kafka 选主等
3、配置TiCDC任务发生多张表到Confluent的kafka里的topic
3.1、在tiup服务器里配置kafka.conf配置文件
[root@172-16-5-146 kafka]# cat kafka.conf
# 指定配置文件中涉及的库名、表名是否为大小写敏感
# 该配置会同时影响 filter 和 sink 相关配置,默认为 true
case-sensitive = true
# 是否输出 old value,从 v4.0.5 开始支持,从 v5.0 开始默认为 true
enable-old-value = true
[filter]
# 忽略指定 start_ts 的事务
#ignore-txn-start-ts = [1, 2]
# 过滤器规则
# 过滤规则语法:https://docs.pingcap.com/zh/tidb/stable/table-filter#表库过滤语法
rules = [yz0920.*]
[sink]
dispatchers = [
matcher = [yz0920.*], topic = "tidb_schema_table", partition="index-value",
]
3.2、创建ticdc任务
tiup ctl:v6.1.0 cdc changefeed create --pd="http://172.16.5.146:2399" --sink-uri="kafka://172.16.6.132:9092/tidb-kafka-3?protocol=avro&partition-num=1&max-message-bytes=67108864&replication-factor=1" --changefeed-id="kafka-2" --config="/home/kafka/kafka.conf" --schema-registry="http://172.16.6.132:8081"
[root@172-16-5-146 kafka]# tiup ctl:v6.1.0 cdc changefeed create --pd="http://172.16.5.146:2399" --sink-uri="kafka://172.16.6.132:9092/tidb-kafka-3?protocol=avro&partition-num=1&max-message-bytes=67108864&replication-factor=1" --changefeed-id="kafka-2" --config="/home/kafka/kafka.conf" --schema-registry="http://172.16.6.132:8081"
Starting component `ctl`: /root/.tiup/components/ctl/v6.1.0/ctl cdc changefeed create --pd=http://172.16.5.146:2399 --sink-uri=kafka://172.16.6.132:9092/tidb-kafka-3?protocol=avro&partition-num=1&max-message-bytes=67108864&replication-factor=1 --changefeed-id=kafka-2 --config=/home/kafka/kafka.conf --schema-registry=http://172.16.6.132:8081
[WARN] This index-value distribution mode does not guarantee row-level orderliness when switching on the old value, so please use caution! dispatch-rules: &config.DispatchRuleMatcher:[]string"yz0920.*", DispatcherRule:"", PartitionRule:"index-value", TopicRule:"tidb_schema_table"[2022/09/22 15:14:20.498 +08:00] [WARN] [kafka.go:433] ["topics `max.message.bytes` less than the `max-message-bytes`,use topics `max.message.bytes` to initialize the Kafka producer"] [max.message.bytes=1048588] [max-message-bytes=67108864]
[2022/09/22 15:14:20.498 +08:00] [WARN] [kafka.go:442] ["topic already exist, TiCDC will not create the topic"] [topic=tidb-kafka-3] [detail="\\"NumPartitions\\":1,\\"ReplicationFactor\\":1,\\"ReplicaAssignment\\":\\"0\\":[0],\\"ConfigEntries\\":\\"segment.bytes\\":\\"1073741824\\""]
[2022/09/22 15:14:20.560 +08:00] [WARN] [event_router.go:236] ["This index-value distribution mode does not guarantee row-level orderliness when switching on the old value, so please use caution!"]
[2022/09/22 15:14:20.561 +08:00] [WARN] [mq_flush_worker.go:98] ["MQ sink flush worker channel closed"]
[2022/09/22 15:14:20.561 +08:00] [WARN] [mq_flush_worker.go:98] ["MQ sink flush worker channel closed"]
Create changefeed successfully!
ID: kafka-2
Info: "upstream-id":0,"sink-uri":"kafka://172.16.6.132:9092/tidb-kafka-3?protocol=avro\\u0026partition-num=1\\u0026max-message-bytes=67108864\\u0026replication-factor=1","opts":,"create-time":"2022-09-22T15:14:20.42496876+08:00","start-ts":436163277049823233,"target-ts":0,"admin-job-type":0,"sort-engine":"unified","sort-dir":"","config":"case-sensitive":true,"enable-old-value":true,"force-replicate":false,"check-gc-safe-point":true,"filter":"rules":["yz0920.*"],"ignore-txn-start-ts":null,"mounter":"worker-num":16,"sink":"dispatchers":["matcher":["yz0920.*"],"dispatcher":"","partition":"index-value","topic":"tidb_schema_table"],"protocol":"avro","column-selectors":null,"schema-registry":"http://172.16.6.132:8081","cyclic-replication":"enable":false,"replica-id":0,"filter-replica-ids":null,"id-buckets":0,"sync-ddl":false,"consistent":"level":"none","max-log-size":64,"flush-interval":1000,"storage":"","state":"normal","error":null,"sync-point-enabled":false,"sync-point-interval":600000000000,"creator-version":"v6.1.0"
特别说明:
--sink-uri="kafka://172.16.6.132:9092" 设置为之前 Confluent 启动的kafka 地址。
protocol=avro 使用 avro 格式,avro 格式支持 schema 演化,支持自动部分 DDL 同步,对比其它格式有优势
--changefeed-id="kafka-2" 表示此 ticdc 同步任务id
--config="c.conf" 表示 ticdc 任务使用 3.1 中创建的配置文件,实现多表多 topic
--schema-registry=http://172.16.6.132:8081 配合 avro 实现 schema 演化,当 TiDB DDL 变更时会发送消息给 schema-registry ,以便消息组件更新 schema
具体请参考:
https://docs.pingcap.com/zh/tidb/stable/manage-ticdc#sink-uri-%E9%85%8D%E7%BD%AE-kafka
3.3、验证该服务
tiup ctl:v6.1.0 cdc changefeed list --pd=http://172.16.5.146:2399
[root@172-16-5-146 kafka]# tiup ctl:v6.1.0 cdc changefeed list --pd=http://172.16.5.146:2399
Starting component `ctl`: /root/.tiup/components/ctl/v6.1.0/ctl cdc changefeed list --pd=http://172.16.5.146:2399
[
"id": "kafka-1",
"summary":
"state": "normal",
"tso": 436163342428536833,
"checkpoint": "2022-09-22 15:18:29.728",
"error": null
,
"id": "kafka-2",
"summary":
"state": "normal",
"tso": 436163342428536833,
"checkpoint": "2022-09-22 15:18:29.728",
"error": null
]
状态 normal 表示数据正常同步
备注,如果发现有问题可以删除,命令如下
[root@172-16-5-146 kafka]# tiup ctl:v6.1.0 cdc changefeed remove --pd=http://172.16.5.146:2399 -c kafka-2
Starting component `ctl`: /root/.tiup/components/ctl/v6.1.0/ctl cdc changefeed remove --pd=http://172.16.5.146:2399 -c kafka-2
4、在tidb数据库里添加表并同步到kafka里
4.1、在tidb数据库里yz0920创建表并插入数据
mysql [(none)]> use yz0920
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
#创建表
CREATE TABLE `lqb0922` (
`id` int(11) NOT NULL,
`name` varchar(30) DEFAULT NULL,
PRIMARY KEY (`id`) /*T![clustered_index] CLUSTERED */
)
#插入数据
insert into lqb0922 values(1,sh1);
insert into lqb0922 values(2,sh2);
delete from lqb0922 where id = 1;
update lqb0922 set name = updated where id = 2;
alter table lqb0922 add column c1 varchar(32);
MySQL [yz0920]> select * from lqb0922
-> ;
+----+------+
| id | name |
+----+------+
| 1 | sh1 |
| 2 | sh2 |
+----+------+
2 rows in set (0.00 sec)
4.2、在confluent服务器里查看kafka的topic
kafka-topics --bootstrap-server 127.0.0.1:9092 --lis

4.3、重启个消费组进行查看kafka里的数据
[root@172-16-6-132 ~]# kafka-console-consumer --bootstrap-server 172.16.6.132:9092 --topic tidb_yz0920_lqb0922 --from-beginning
sh1
sh2
sh3
##返回如下:因为使用 AVRO 格式,所以数据显示并不完全可读,但是可以大致看到上面的数据变更过程
sh3是因为中间插入了一条新数据
5、使用Connect完成TiDB实时数据到Oracle
5.1、安装connect jdbcSinkConnector 插件
执行以下命令安装 kafka-connect-jdbc 插件,安装之后重启connect组件,(可能还需要重启 control center)
confluent-hub install confluentinc/kafka-connect-jdbc:latest
5.2、配置connect任务
5.2.1.打开control connect
5.2.2、选择 JdbcSinkConnector 插件
配置好 connect 插件之后登陆 control center ,进入主页面之后点击 connect ,再点击 connect-default ,可以看到之前已经安装的 connect 插件。

5.2.3、配置说明
点击 JdbcSinkConnector 之后输入,配置 Topic ,此处使用正则表达式: tidb_.* 表示匹配所以 TiCDC 任务创建出来的 Kafka Topic
创建kafka的topic

配置 Avro 格式:

配置 Oracle 信息

配置写入选项:
需要特别注意 Insert Mode 需要选择 upsert,它可以支持 update 和 delete,通过报错再次编辑的方式将 Enable deletes 修改为 true,以便支持 delete DML

配置数据转化信息
此处 Table Name Format 配置效果会将tidb 中 test.t9 写入到 oracle 的 kafka_tidb_test_t9 中国, Primary Key Mode 选择 record_key 以便支持 delete 操作

配置 DDL 支持
按下图配置支持自动创建 Table;自动 DDL 落地:目前验证支持 add column ,不支持 Drop Column,不支持 Rename Column; Quote Identifiers 需要设置为 always 它会在创建表时给表名添加双引号,否则 oracle 会无法创建表

配置 Avro Schema Registry:
需要手工 Add Property,分别输入 key 为value.converter.schema.registry.url和key.converter.schema.registry.url ,然后为 key 添加对应的Value。

5.2.4、查看配置是否正确
点击 Next ,检查配置是否正确,最终启动任务实现实时同步数据。可以在配置检查页面与以下配置文件进行对比。
"name": "JdbcSinkConnectorConnector_2",
"config":
"value.converter.schema.registry.url": "http://localhost:8081",
"key.converter.schema.registry.url": "http://localhost:8081",
"name": "JdbcSinkConnectorConnector_2",
"connector.class": "io.confluent.connect.jdbc.JdbcSinkConnector",
"tasks.max": "1",
"key.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"topics.regex": "tidb_.*",
"connection.url": "jdbc:oracle:thin:@172.1.1.1:1521:orcl",
"connection.user": "test",
"connection.password": "****",
"dialect.name": "OracleDatabaseDialect",
"connection.attempts": "1",
"connection.backoff.ms": "1000",
"insert.mode": "upsert",
"batch.size": "20",
"delete.enabled": "true",
"table.name.format": "kafka_$topic",
"pk.mode": "record_key",
"auto.create": "true",
"auto.evolve": "true",
"quote.sql.identifiers": "always",
"max.retries": "1",
"retry.backoff.ms": "1000"
5.3、验证connect DML DDL实时同步能力
启动任务后可以在页面查看任务运行状态,如果失败则可以通过以下命令查看日志排查问题
滚动查看日志
confluent local services connect log -f
查看全量日志
confluent local services connect log
登陆 Oracle 数据库,可以看到 TiDB 中所有表已经自动在 Oracle 中映射创建。

备注,JdbcSinkConnectorConnector_0截图和配置文件如下:





配置文件json
"name": "JdbcSinkConnectorConnector_0",
"config":
"value.converter.schema.registry.url": "http://localhost:8081",
"key.converter.schema.registry.url": "http://localhost:8081",
"name": "JdbcSinkConnectorConnector_0",
"connector.class": "io.confluent.connect.jdbc.JdbcSinkConnector",
"tasks.max": "1",
"key.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"topics": "tidb_yz0920_lqbyz",
"connection.url": "jdbc:oracle:thin:@172.16.11.60:1521:orcl",
"connection.user": "ogg",
"connection.password": "***",
"dialect.name": "OracleDatabaseDialect",
"connection.attempts": "5",
"connection.backoff.ms": "1000",
"insert.mode": "upsert",
"batch.size": "20",
"table.name.format": "kafka_$topic",
"pk.mode": "record_key",
"auto.create": "true",
"auto.evolve": "true",
"quote.sql.identifiers": "always"
Launch
TIDB - 使用 TICDC 将数据同步至下游 Mysql 中
一、TICDC
TiCDC 是一款通过拉取 TiKV 变更日志实现的 TiDB 增量数据同步工具,具有将数据还原到与上游任意 TSO 一致状态的能力,同时提供开放数据协议 (TiCDC Open Protocol),支持其他系统订阅数据变更。
和前面学习的Tidb binlog 不同,binlog 是直接取的tidb-server 的日志信息,而TiCDC则是取的 Tikv 的,相比性能更优,但TiCDC 只有数据修改时会触发同步,不包括ddl,所以说使用TICDC,必须保证两端的数据结构一致。
TiCDC 的架构
TiCDC 运行时是一种无状态节点,通过 PD 内部的 etcd 实现高可用。TiCDC 集群支持创建多个同步任务,向多个不同的下游进行数据同步。

二、TICDC 的使用
在使用CDC前,先看下目前的集群架构,不了解的TIDB集群架构的,可以看下本专栏的TIDB系列文章。
tiup cluster display tidb-test

现在我们使用扩容的方式,扩容出一台TICDC:
vi scale-out.yaml
写入以下内容:
cdc_servers:
- host: 192.168.40.161
port: 8300
开始扩容:
tiup cluster scale-out tidb-test scale-out.yaml -uroot -p

已经扩容成功,再来看下集群信息:

CDC就已经装好了,下面我们可以通过ctl 工具查看下CDC的部署信息,如果没有ctl工具的话,会自动安装:
tiup ctl:v5.0.0 cdc capture list --pd=http://192.168.40.160:2379

is-owner 为 true 代表当 TiCDC 节点为 owner 节点。
创建同步任务:
tiup cdc cli changefeed create --pd=http://192.168.40.160:2379 --sink-uri="mysql://root:root123@192.168.40.1:3307/" --changefeed-id="replication-task-1" --sort-engine="unified"
如果没有工具的话会下载,如果不想下载,可以去安装CDC的主机上,进入CDC的安装目录的bin下,就有cdc的执行脚本:
直接使用脚本创建任务:
./cdc cli changefeed create --pd=http://192.168.40.160:2379 --sink-uri="mysql://root:root123@192.168.40.1:3307/" --changefeed-id="replication-task-1" --sort-engine="unified"
–sink-uri=“mysql://root:root123@192.168.40.1:3307/” : 目标库(下游)MySQL 数据库的信息
–changefeed-id=“replication-task-1” 数据同步任务 ID
–sort-engine=“unified” :不定义引擎。

出现上面日志,则代表任务创建成功。
使用下面指令可以查看同步任务:
./cdc cli changefeed list --pd=http://192.168.40.160:2379

“state”: “normal” : 表示任务状态正常。
“tso”: 429574071882350593 : 表示同步任务的时间戳信息。
“checkpoint”: “2021-12-05 17:03:57.393” :表示同步任务的时间。
查询任务的详细信息:
./cdc cli changefeed query --pd=http://192.168.40.160:2379 --changefeed-id=replication-task-1

三、测试同步任务
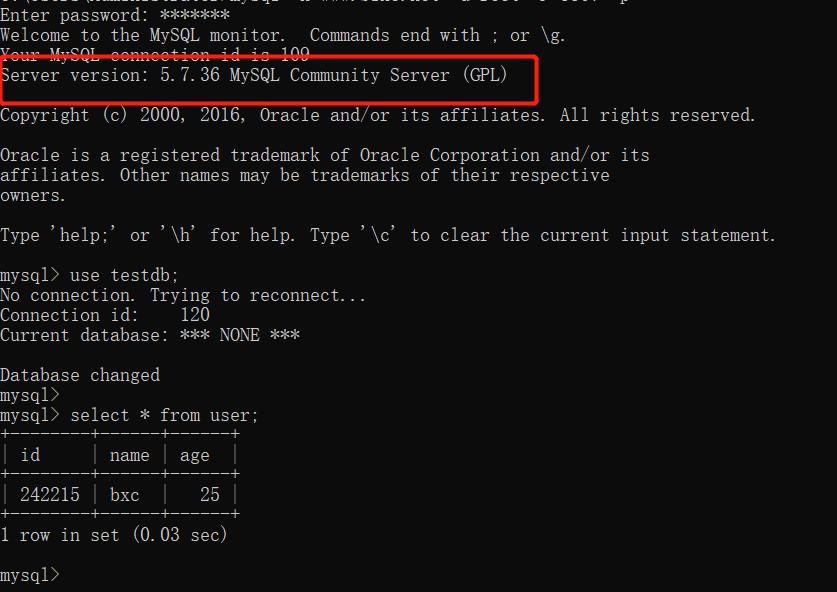
TIDB 和 Mysql中都有testdb 数据库,和user 表:

首先在Tidb中插入一条数据:
insert into user(name,age) value('bxc','25');

然后在mysql 中查询信息:

喜欢的小伙伴可以关注我的个人微信公众号,获取更多学习资料!
以上是关于TiCDC+Confluent同步数据到Oracle的主要内容,如果未能解决你的问题,请参考以下文章
TIDB - 使用 TICDC 将数据同步至下游 Kafka 中