自定义类型:结构体
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自定义类型:结构体相关的知识,希望对你有一定的参考价值。
1.结构体的声明
1.1结构的基础知识
结构是一些值的集合,这些值称为成员变量。结构的每个成员可以是不同类型的变量。数组则是一组相同类型元素的集合。
1.2结构的声明
生活中有很多很多的类型,像学生,老师,公务员,程序员等等等等,我们就以学生为例,描述一个学生,我们可以描述他的名字,年龄,性别,身高,体重,学号,成绩等等等等

这就是结构体的基本结构,首先要写struct ,然后写你要声明的类型,接着大括号里面写各种成员变量,注意大括号外面的分号不能丢,部分编译器会自动加上。
1.3特殊的声明
在声明结构的时候,可以不完全声明。比如:

上面两个结构在声明的时候省略掉了结构体标签(tag)。
那么问题来了?

警告:编译器会把上面的两个声明当成完全不同的两个类型,即使里面的成员变量一模一样。所以是非法的。
1.4结构体的自引用
在结构中包含一个类型为该结构本身的成员是否可以呢?

可以发现,这个结构体的大小是计算不出来的,是没有穷尽的。既然大小无法确定,那么就不能这样写。
正确的自引用方式

如果是指针的话,大小是确定的,就可以。
1.5结构体变量的定义与初始化
有了结构体类型,那如何定义变量,其实很简单


这里的p1、p2定义在main函数的外面,所以是全局变量。

1.6结构体内存对齐
我们已经掌握了结构体的基本使用了。现在我们深入探讨一个问题:计算结构体的大小。
这也是一个特别热门的考点:结构体内存对齐
考点:
如何计算?
首先我们得掌握结构体的对齐规则:
1.第一个成员在与结构体变量偏移量为0的地址处。
2.其他的成员变量要对齐到某个数字(对齐数)的整数倍的地址处。
对齐数=编译器默认的一个对齐数与该成员大小的较小值
(VS中默认的值为8)
3.结构体总大小为最大对齐数(每个成员变量都有一个对齐数)的整数倍。
4.如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍数,结构体的整体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍。
接着我们来试着计算一下下面几个结构体的大小:
#include <stdio.h>
struct S1
char c1;
int i;
char c2;
;
int main()
printf("%d\\n", sizeof(struct S1));
return 0;

char是第一个成员变量,所以偏移量就是0,其实就是在就第一个字节的位置,int 大小为4,小于VS的默认的8,所以对齐数就是4,所以对齐到4,char是1,这里的所有数都是它的倍数,所以直接放在char的后面,整体的大小为最大对齐数的整数倍,而最大对齐数是4,所以整个结构体的大小就是12个字节。(编译器的验证在后面)


结构体大小应该是 8;


结构体大小应该是16;

 结构体的大小应该是32;
结构体的大小应该是32;
接下来让我们看看到底就对不对:

只能说:一模一样。
那就有同学要问了:为什么会存在内存对齐?
大部分的参考资料都是如是说的:
1. 平台原因(移植原因):
不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。
2. 性能原因:
数据结构(尤其是栈)应该尽可能地在自然边界上对齐。 原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访问。
总体来说:
结构体的内存对齐是拿空间来换取时间的做法。
那在设计结构体的时候,我们既要满足对齐,又要节省空间,如何做到?
就是让占用空间小的成员尽量集中在一起。

S1和S2类型的成员一模一样,但是S1和S2所占空间的大小有了一些区别。
1.7修改默认对齐数
之前我们见过了 #pragma 这个预处理指令,这里我们再次使用,可以改变我们的默认对齐数。

结果:

结论:
结构在对齐方式不合适的时候,我么可以自己更改默认对齐数。
1.8结构体传参
直接上代码:

上面的 print1 和 print2 函数哪个好些?
答案是:首选print2函数。
原因: 函数传参的时候,参数是需要压栈,会有时间和空间上的系统开销。 如果传递一个结构体对象的时候,结构体过大,参数压栈的的系统开销比较大,所以会导致性能的下降。
结论:
结构体传参的时候,要传结构体的地址。
好了,这就是结构体的所有内容了,当然,结构体远远不止于此,今天就先介绍到这里了,感谢大家的阅读!
c语言自定义类型——结构体,位段(匿名结构体,结构体的自引用,结构体的内存对齐)

结构体的定义
结构体是一些值的集合,这些值称为成员变量。结构的每个成员可以是不同类型的变量。
数组是一组相同类型的元素的集合。结构体也是一些值的集合,结构体的每个成员可以是不同类型的。
为什么要使用结构体
现实生活中,我们会遇到很多复杂的对象,这些复杂的对象仅通过c语言中的整型数据类型或者浮点数数据类型是无法全面且准确的描述的,这时候我们就需要用到结构体来描述这些复杂的对象。
结构体类型的声明
完全声明
struct tag
{
member_list;
} variable_list;
**
**> 结构体关键字:struct
结构体的标签:tag
结构体的类型:struct tag
结构的成员列表:member_list
结构体变量列表:variable_list**
**
例如描述一件衣服,衣服的属性有衣服名称,衣服编号,衣服价格,衣服颜色等等。
struct cloth
{
char name[20];//衣服名称
char id[20];//衣服编号
int price;//衣服价格
char color [5];//衣服颜色
};//分号不能丢弃
上面的结构体声明方式属于完全声明,当然也存在不完全声明的情况,比如说省略结构体的标签,这种结构体称为匿名结构体,如下代码:
//匿名结构体类型
struct
{
int a;
char b;
float c;
}x;
struct
{
int a;
char b;
float c;
}*p;
int main()
{
p =&x;
return 0;
}
上面的匿名结构体,成员都是一样的,表面上是同一类型,第一次创建了一个变量x,第二次创建了一个结构体指针,主函数里面取变量x的地址放在指针变量p里面,看似可行,但实际上他们是两种不同的类型,是不能进行赋值的,虽然没有什么大的问题,但编译器会报错发出警告**(在定义的时候没有写结构体类型名称,编译器当做两种不同的类型,所以编译不过,就会有如下报错了)**
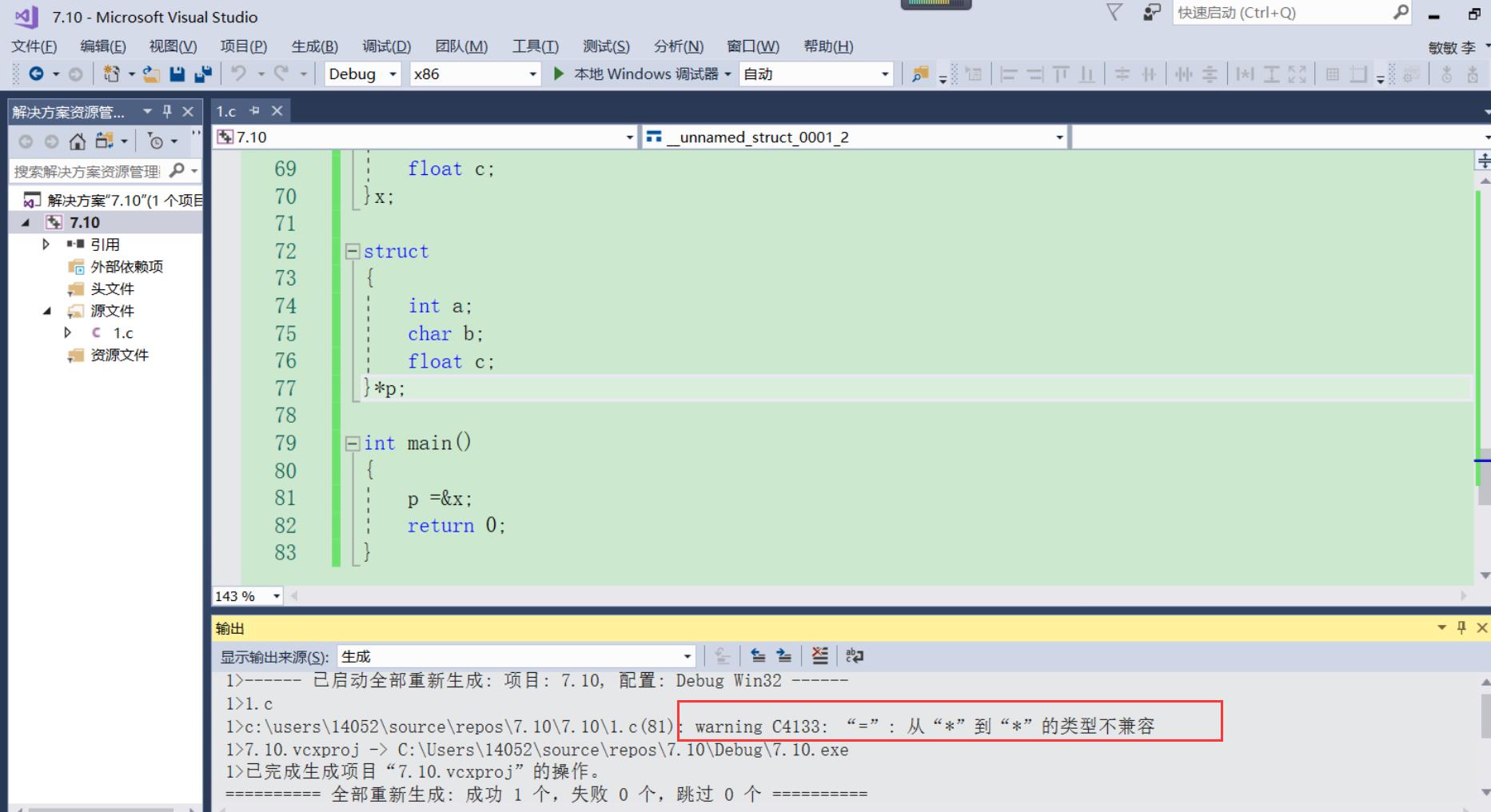
结构体的自引用
思考:在结构中包含一个类型为该结构本身的成员是否可以呢 ?
//代码1
struct Node
{
int data;//占4个字节
struct Node n;
};
//可行否?
如果可以,那sizeof(struct Node)是多少 ?
我们首先进行简要分析一下,发现是不行的,要求struct Node 的大小,成员data占4个字节,之后又求struct Node n成员的大小,要求struct Node n成员的大小,又要求struct Node的大小,**要求其大小又要求它自己的大小,我们发现在求其大小的时候都要求它自己的大小,而它自己的大小都是未知的,求其大小的过程就陷入一个死递归的过程,永远无法求出struct Node 的大小,**因此这种自引用的方式不行。还有语法也不支持的,经过我的实验编译报错如下:
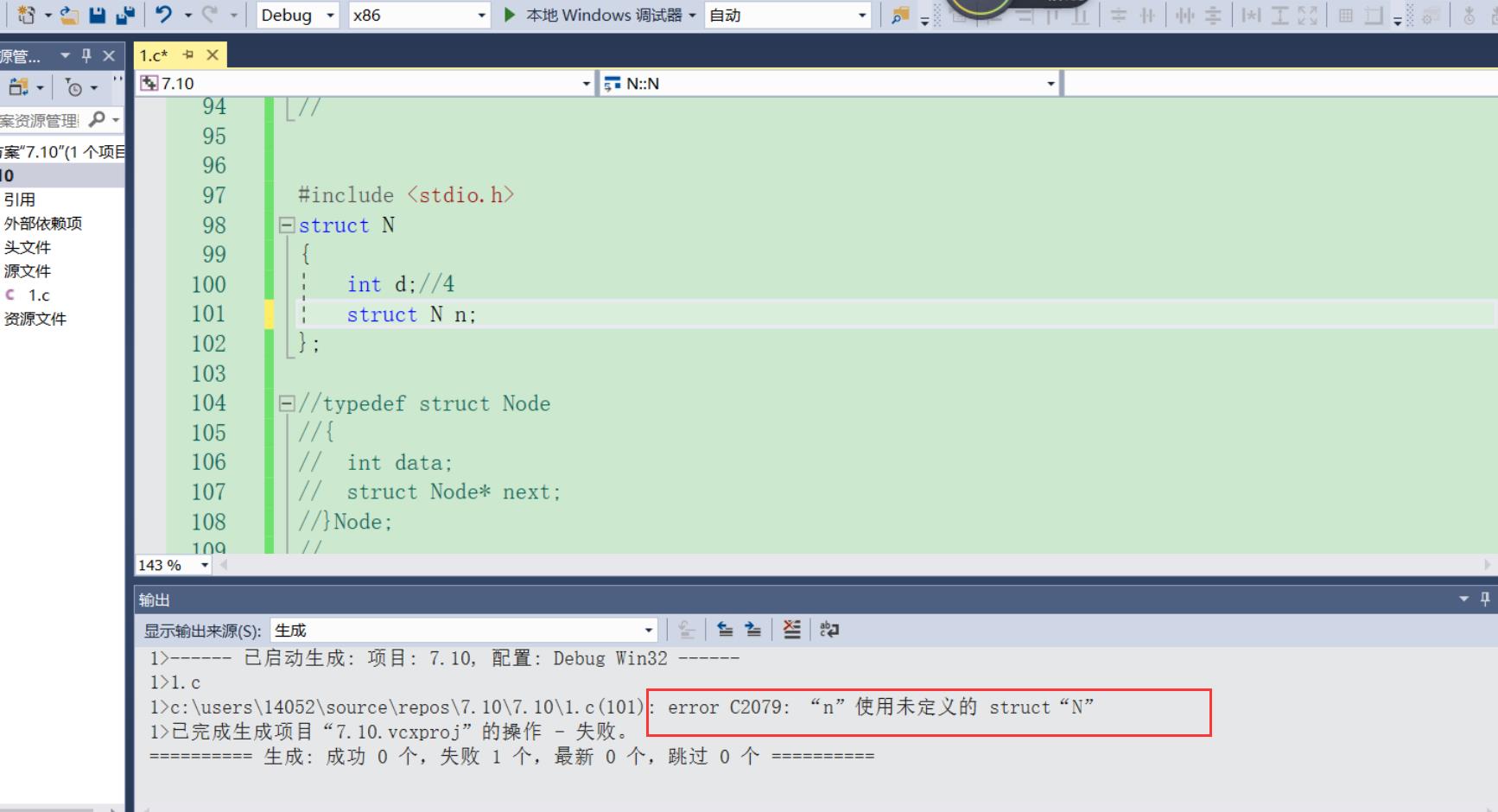
正确的自引用方式:
正确的自引用方式是要通过结构体指针的方式实现,那为什么要通过结构体指针的方式呢?我的理解是数据在内存中的存储多种多样,有像数组那样元素一个挨着一个顺序存储的,也有一些数据在内存中杂乱存储,但是要想对它们进行顺序访问,一个一个像连线一样访问就要使用结构体指针,还有我们知道,指针的大小跟其所指向的类型无关,仅跟平台环境有关,32位平台指针大小为4个字节,64位平台,指针大小为8个字节。正因为指针大小的确定性,所以再自引用的时候结构体类型的整体大小也是可以确定的。
//代码2
struct Node
{
int data;//数据域
struct Node* next;//指针域
};
假设我们存储5个数据1 2 3 4 5,有顺序存放的顺序表,也有杂乱存放的链表,它们都是线性数据结构,我们通过结构体指针,通过链表方式就可以顺序访问内存空间不相邻的数据了,像一根线一样把访问的数据串联起来(这里涉及数据结构知识没有能力深谈)
在链表数据结构中,链表中每一个元素称为“结点”,每个结点都应包括两个部分:一个是需要用的实际数据data;另一个就是存储下一个结点地址的指针,即数据域和指针域。数据结构中的每一个数据结点对应于一个存储单元,这种储存单元称为储存结点,也可简称结点
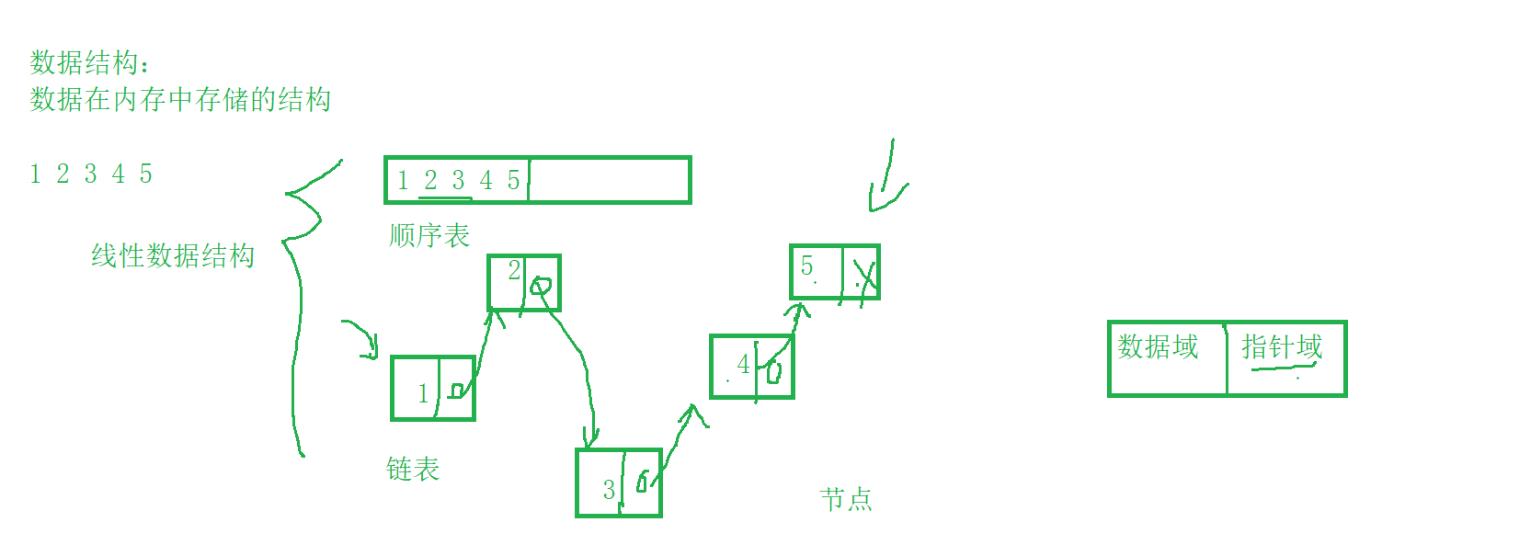
那么对于匿名结构体又如何实现结构体的自引用呢?
```c
//代码1
struct
{
int data;
struct Node* next;
}Node1;
int main()
{
printf("%d", sizeof(Node1));//结果8
return 0;
}
上面的代码省略了结构体标签,创建了匿名结构体,我在vs2017上面测试通过了,虽然通过了,但按理论来说是不对的,因为下面定义了一个struct Node *的指针,但stuct Node都没定义,不知道从哪里来,怎么就创建了一个结构体指针了呢?可能原因很多,但这种写法错的,是编译器检测不严格造成的。
//代码2
typedef struct
{
int data;
Node* next;
}Node;
//这样写代码,可行否?
//代码2
typedef struct Node
{
int data;
struct Node* next;
}Node;
那我们能不能通过typedef类型重定义实现匿名结构体的自引用呢?可以但要写成代码二的形式,我们通过typedef将结构体重新命名为Node,之后创建一个结构体指针,但不能省略调结构体标签Node,原因还是因为我们结构体重命名为node ,结构体里面在未重定义Node之前就定义了一个Node*的指针,之前并没有这个指针,它是从哪里冒出来的呢?中间的指针创建是非法的,typedef的定义也是非法的。
结构体变量的定义和初始化
结构体变量的定义和初始化其实很简单,和其它类型的变量的定义和初始化基本一样,基本形式都是:变量类型+变量名称,进行定义,(struct *
+变量名称,是结构体指针)等号右边进行初始化。唯一不同的是结构体可以在结构体声明的代码块的后面,分号前面,添加变量名称进行定义。结构体变量进行初始化的时候,初始化的内容是放在一个花括号里面。不同的成员之间用逗号隔开即可,如果遇到结构体嵌套的情况,括号里面再加括号,括号里面放置嵌套结构体的成员。可以结合下面的代码更好地进行理解
代码一:
struct Point
{
int x;
int y;
}p1;//声明结构体类型的同时定义变量p1
struct Point p2;//定义结构体变量p2
struct Point p3 = { 1,1 };//初始化:定义变量的同时给变量赋值
代码二:
struct Stu//类型声明
{
char name[20];//姓名
int age;//年龄
};
struct Stu s = { "Student_zhang",20 };//定义和初始化初始化
代码三:
struct Node
{
int data;
struct Point p;
struct Node* next;
}n1 = { 10,{4,5},NULL };//结构体嵌套初始化
struct Node n2 = { 20,{1,2},NULL };//结构体嵌套初始化
结构体内存对齐(结构体的存放规则)
对于结构体的声明,定义和初始化。我们已经基本了解,接下来我们一起来探讨一下结构体在内存当中的存放规则。数据的存放规则决定了它在内存当中的大小。在定义变量的时候编译器给不同类型的数据分配内存空间,比如char大小为1个字节,int类型为4个字节,double类型是8个字节等等,那么,结构体的大小是多少?又该如何计算呢?
结构体内存对齐规则:
1.第一个成员放在结构体变量偏移量为O的地址处。 ⒉.其他成员变量要放在某个数字(对齐数)的整数倍的地址处。 ①对齐数 = 编译器默认的一个对齐数与该成员大小的较小值。 ②VS中默认对齐数的值为8, Linux中无对齐数的概念,以自身大小为对齐数
3.结构体总大小为最大对齐数(每个成员变量都有一个对齐数)的整数倍。
4.如果嵌套了结构体的情况,嵌套的结构体放到自己的最大对齐数的整数倍处,结构体的整体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍。嵌套结构体的对齐数不是结构体大小的整数倍,不是简单的对齐数相加,而是结构体自己的最大对齐数的整数倍。这里的对齐数,可以简单的理解为对齐规则下的存储位置,也是偏移量位置。
接下来,我们通过以下练习来加深对结构体内存对齐规则的理解
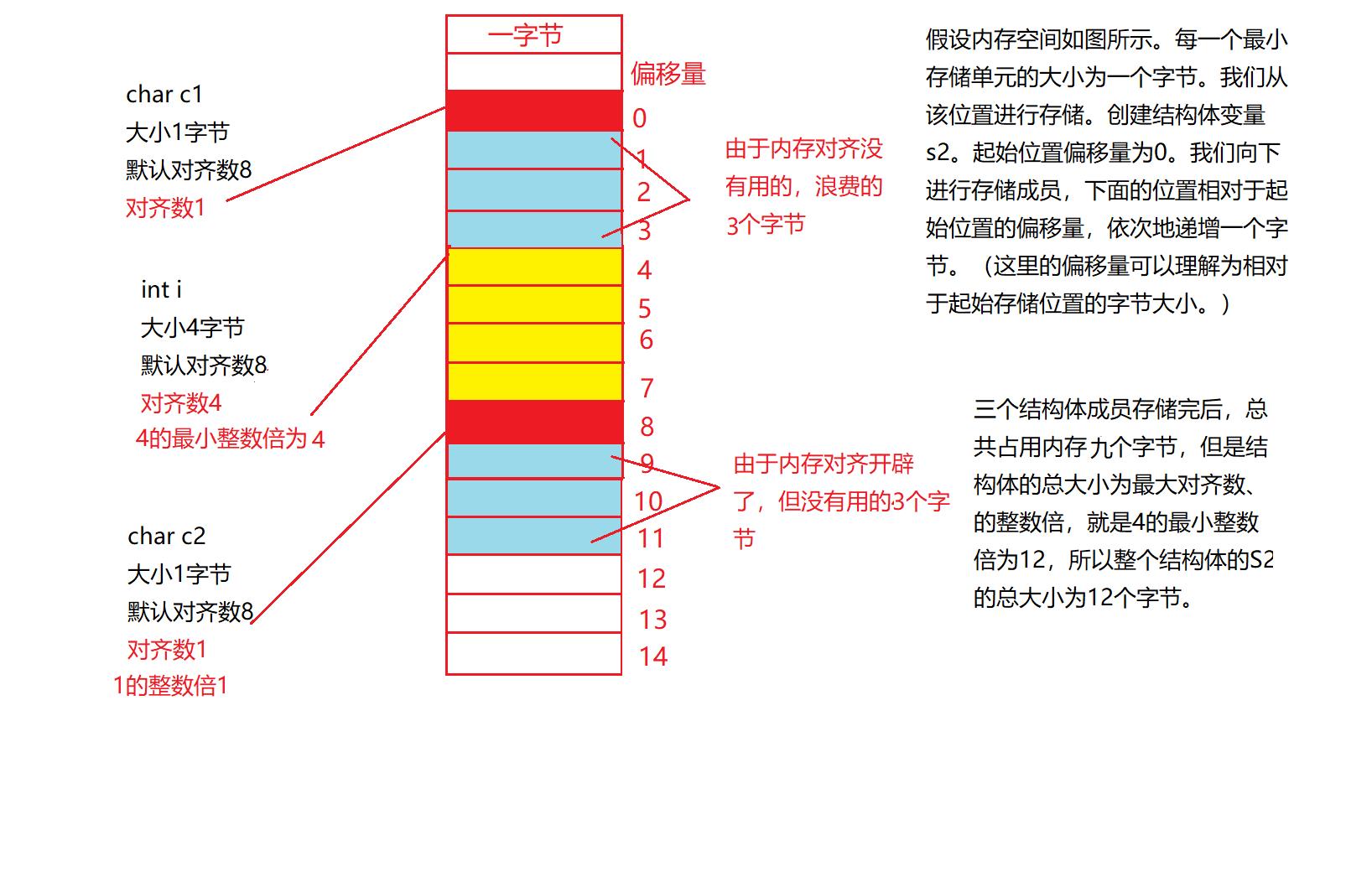
练习一:
#include<stdio.h>
struct s1
{
char c1;
int i;
char c2;
};
int main()
{
printf("%d\\n", sizeof(struct s1));
return 0;
}
运行结果为12,详细理解如图。
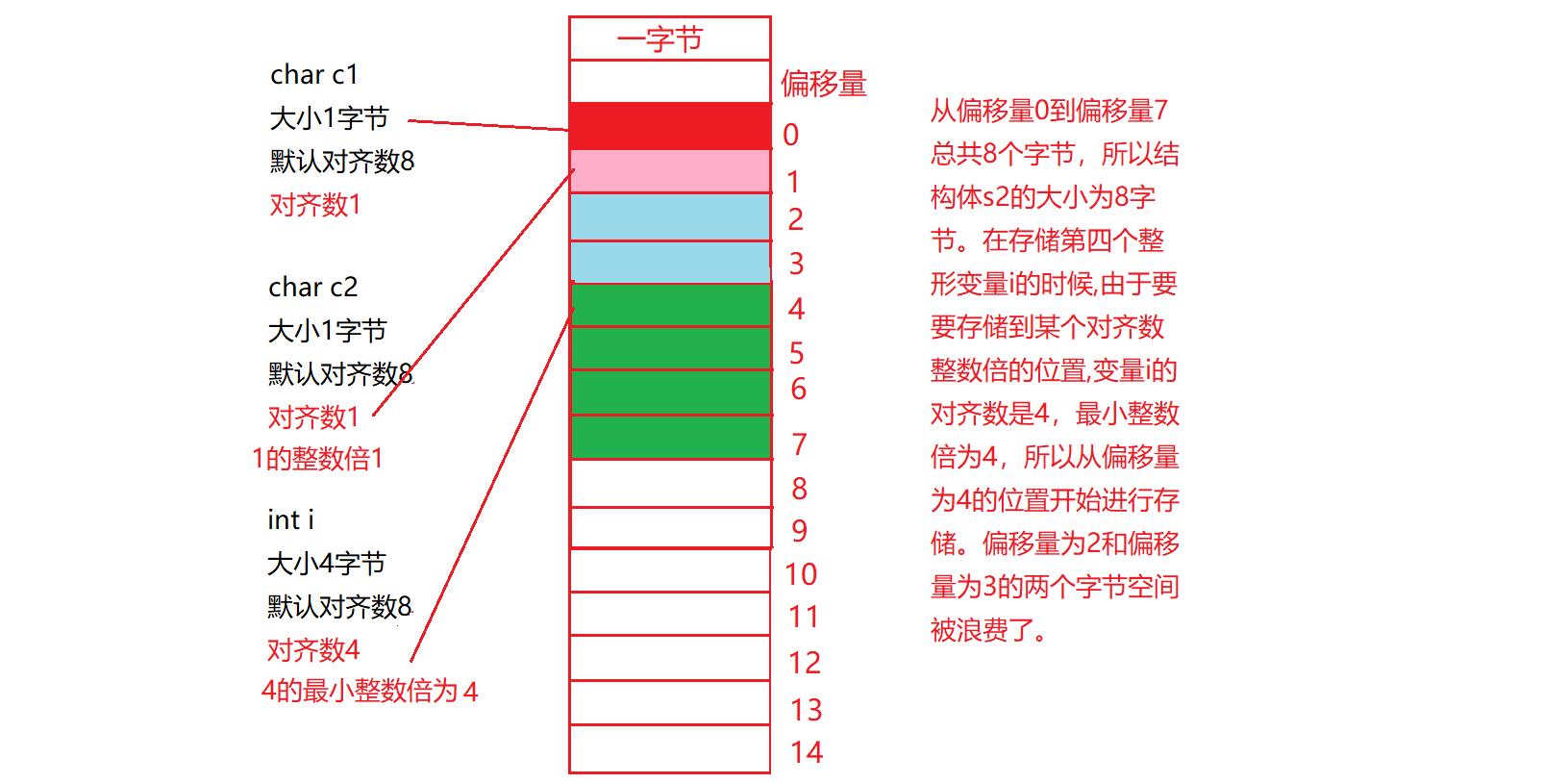
练习二:
#include<stdio.h>
struct s2
{
char c1;
char c2;
int i;
};
int main()
{
printf("%d\\n", sizeof(struct s2));
return 0;
}
程序运行结果为8
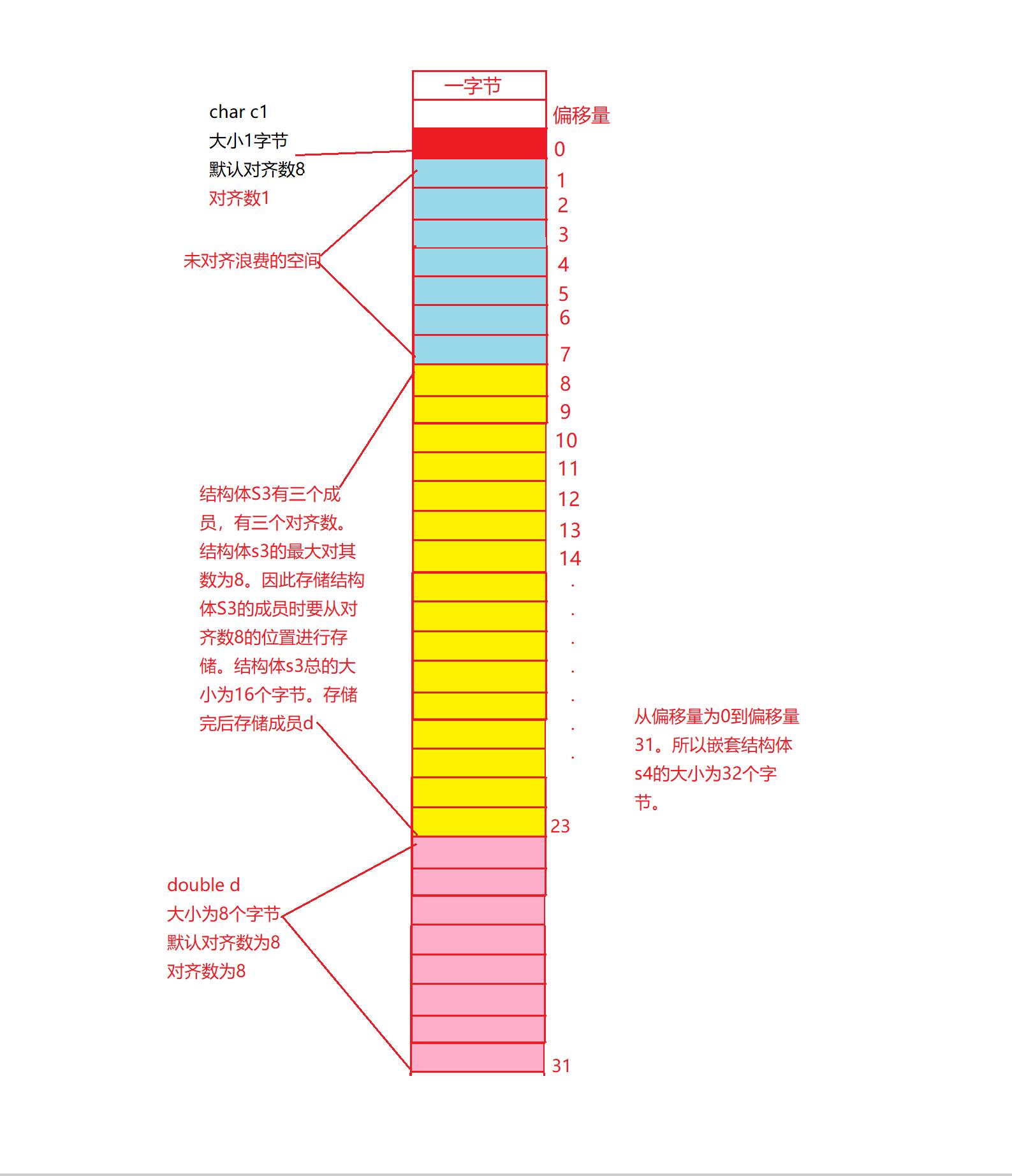
练习三,结构体的嵌套
计算嵌套结构体的大小,也是要遵循结构体的对齐规则的,第一个成员都是默认从偏移量为零的位置进行对齐,如遇到结构体结构体从结构体的最大对齐数位置开始开辟空间,空间的大小为结构体的大小,之后再继续进行对齐,开辟相应的变量空间,和上面的没有嵌套的对齐方式一样开辟空间一样。
#include<stdio.h>
struct s3
{
double d;
char c;
int i;
};
struct s4
{
char c1;
struct s3 s3;
double d;
};
int main()
{
printf("%d\\n", sizeof(struct s4));//程序运行结果4
return 0;
}
思考:为什么存在内存对齐 ?
大部分的参考资料都是这样解释的::
1.平台原因(移植原因)∶不是所有的硬件平台都能访问任意地址上的任意数据的; 某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。(所以我们对齐到能够被硬件访问的位置,在对齐位置进行存储数据)
⒉性能原因∶数据结构(尤其是栈)应该尽可能地在自然边界上对齐。原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;
而对齐的内存访问仅需要一次访问。 总体来说︰ 结构体的内存对齐是拿空间来换取时间的做法。
那在设计结构体的时候,我们既要满足对齐,又要节省空间,如何做到?
让占用空间小的成员尽量集中在—起。
如对比之前写的代码
struct s1
{
char c1;
int i;
char c2;
};
struct s2
{
char c1;
char c2;
int i;
};
之前讲解结构体的对齐规则的时候,举例了两个代码,结构体s1和s2类型的成员一模一样,但是s1和s2所占用的空间大小是有区别的,前者大小为12个字节,后者为8个字节,显然后者这种方式空间利用的效率更高,节省内存。
使用#pragma,可以用来改变我们的默认对齐数。
如通过#pragma修改我们上面所写代码的默认对齐数
#include <stdio.h>
#pragma pack(8)//设置默认对齐数为8
struct s1
{
char c1;
int i;
char c2;
};
#pragma pack()//取消设置的默认对齐数,还原为默认
#pragma pack(1)//设置默认对齐数为1
struct s2
{
char c1;
int i;
char c2;
};
#pragma pack()//取消设置的默认对齐数,还原为默认
int main()
{
printf("%d\\n", sizeof(struct s1));
printf("%d\\n", sizeof(struct s2));
return 0;
}
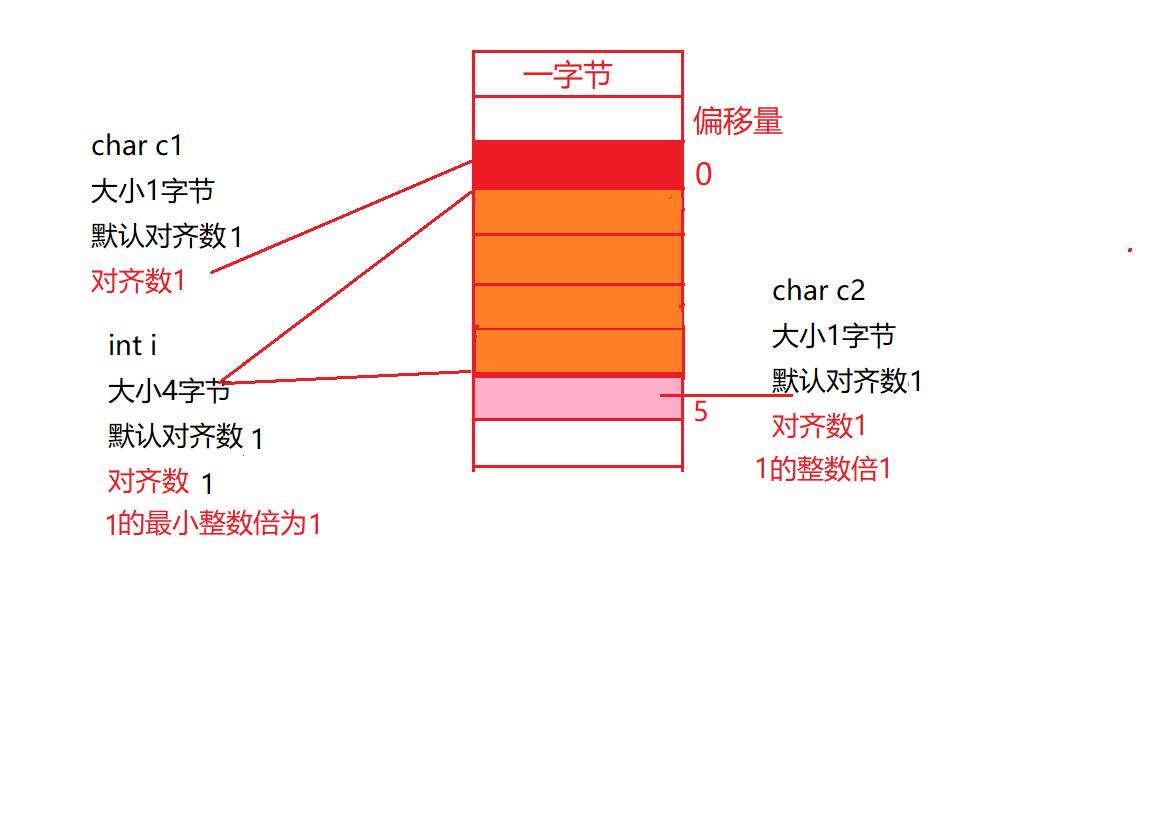
s1的大小为12,s2的大小为6,默认对齐数为1,就不存在规则了,结构体成员就是顺序开辟空间的,因为存储信息的最小单元是一个字节,默认对齐数为1,取两者的较小值对齐数就都为1,之后的对齐位置都是1的倍数。所以结构体在对齐方式不合适的时候,我们可以自己更改默认对齐数来满足需求。
offsetof,这是一个宏,用来计算结构体成员相对于结构体起始位置的偏移量
如下面代码通过这个宏,计算结构体中某变量相对于首地址的偏移。不太清楚的还是自己画图看看。
#include<stdio.h>
#include<stdlib.h>
struct s2
{
char c1;
int i;
char c2;
};
int main()
{
printf("%d\\n", offsetof(struct s2, c1));
printf("%d\\n", offsetof(struct s2, i));
printf("%d\\n", offsetof(struct s2, c2));
return 0;
}
程序运行结果:0,4 8
结构体传参
#include <stdio.h>
struct S
{
int data[1000];
int num;
};
struct S s = { {1, 2, 3, 4}, 1000 };
//结构体传参
void print1(struct S s)
{
printf("%d \\n", s.num);
}
// 结构体地址传参
void print2(struct S* ps)
{
printf("%d \\n", ps->num);
}
int main()
{
print1(s);//传结构体
print2(&s);//传结构体地址,通过结构体指针接收
return 0;
}
结构体传参有两种方式:
一种是传递结构体对象(传值),对应的就是print1函数的方式
另一种是传递结构体地址(传址),对应的就是print2函数的方式
那么上面的print1和print2函数哪个好些 ?print2更好一点
对于结构体的传参首选传递地址,原因如下:
函数传参的时候,参数是需要压栈,会有时间和空间上的系统开销。
如果传递一个结构体对象的时候,结构体过大,参数压栈的的系统开销比较大,所以会导致性 能的下降。
结构体实现位段
什么是位段 ? 位段的声明和结构是类似的,所以放在一起研究,但有两个不同︰
1.位段的成员必须是int、unsigned int,char
2.位段的成员名后边有一个冒号和一个数字。
3.int 表示定义整形的位段成员,冒号后面的数字表示成员所占的大小,单位为字节,首先开辟一个整形大小的空间(32字节)来存储位段成员,如果空间不足继系开辟一个整形空间大小来创建位段成员。
如下代码:
#include<stdio.h>
struct A
{
int _a : 2;
int _b : 5;
int _c : 10;
int _d : 30;
};
int main()
{
printf("%d\\n", sizeof(struct A));
return 0;
}
那么如何计算位段A的大小呢?
位段的计算分两种情况:
情况一:
位段类型相同:
一句话来说就是一次一次的开辟位段类型对应的空间大小,依次把空间分给位段成员,假设使用后的空间不够分配给后面的成员,需要重新开辟空间,位段的总大小就是所有开辟空间的总和。如上代码计算位段大小大致如下:1.首先位段的类型是int,int类型的大小是4个字节
2.开辟4个字节的空间,其中_a占用2个bit位,_b占5个bit,_c占10bit,这时候已经使用17个bit的空间,4个字节=32bit,还剩下15bit空间,而_d大小为30个bit,剩余的空间不够其使用
3.再次开辟4个字节的空间,_d占用30个bit
4.所以位段A的大小为4+4=8个字节
情况二:
位段成员不同,其实位段也是结构体,这时计算位段的大小就要按结构体的对齐规则来计算了和上面的一样了
#include<stdio.h>
struct Test
{
char a : 1;
char b : 6;
int c : 1;
}Test;
int main()
{
printf("size = %d\\n", sizeof(struct Test));
return 0;
}
程序运行结果8
位段的内存分配
1.位段的成员可以是int ,unsigned int或者是char(属于整形家族)类型
2.位段的空间上是按照需要以4个字节([int)或者1个字节(char)的方式来开辟的。
3.位段涉及很多不确定因素,位段是不跨平台的,注重可移植的程序应该避免使用位段。这些不确定因素体现在: ①空间是否要被浪费? ②空间是从左向右使用还是从右向左使用?
如如下代码:
#include<stdio.h>
struct S
{
char a : 3;
char b : 4;
char c : 5;
char d : 4;
}s;
int main()
{
struct S s = { 0 };
s.a = 10;
s.b = 12;
s.c = 3;
s.d = 4;
return 0;
}
我利用以上代码在vs2013里面进行测试,数据的存储先使用低地址再使用高地址。假设位段成员在一个字节空间里面是从右向左进行存储的,存储完一个结构体成员后,当一个字节的空间不够存储下一个结构体成员的时候,之前一个字节里面的空间舍弃。调试后结果如图和我们的假设一样(其实这里的假设有点牵强,我们已知在vs里面的存储情况,我们可以通过类似的假设方法在linux的gcc编译器下进行一下探究)
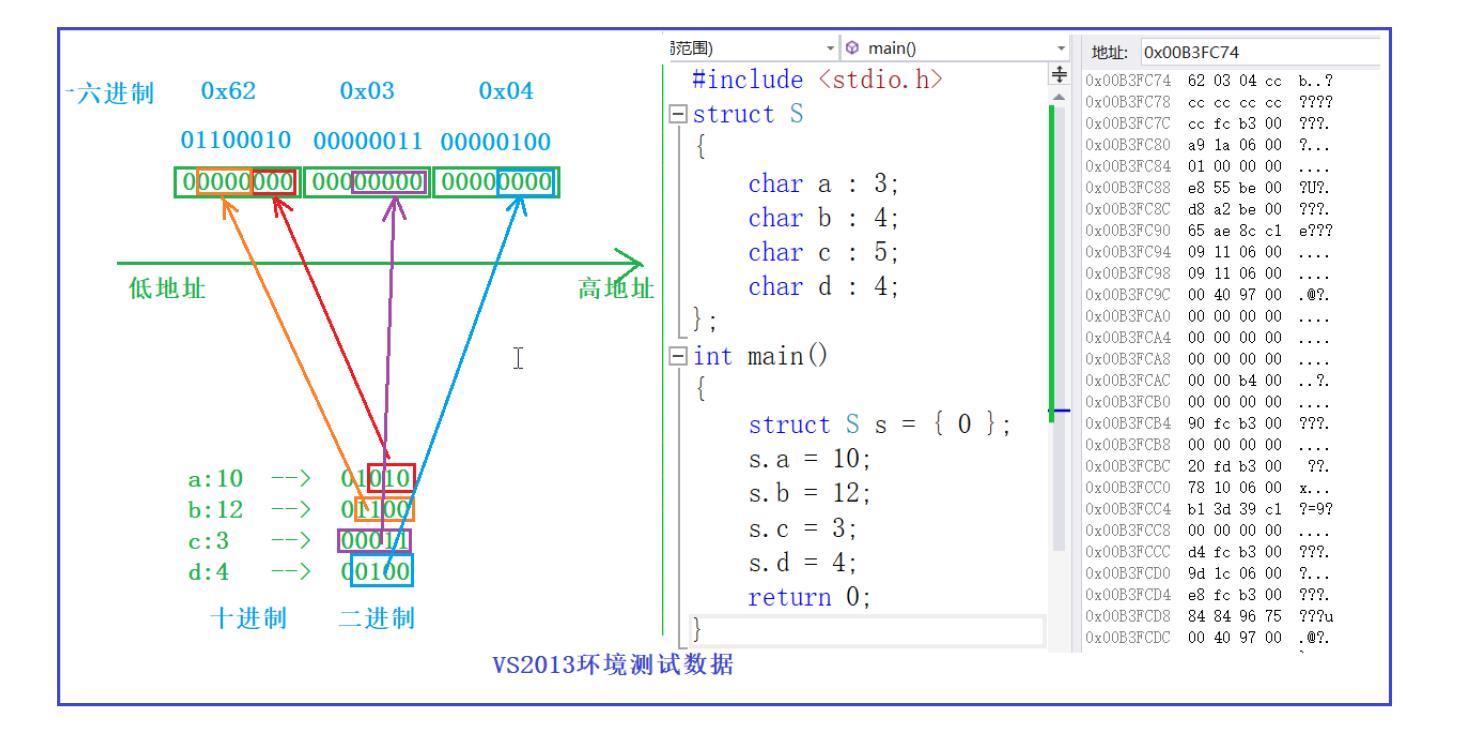
调试的时候数据是以16进制显示,四个二进制转化为一个16进制,第一个数据转化大致如图

位段的跨平台问题
1.int位段被当成有符号数还是无符号数是不确定的。
2.位段中最大位的数目不能确定。(16位机器最大16,32位机器最大32),写成27,在16位机器会出问题。
3.位段中的成员在内存中从左向右分配,还是从右向左分配标准尚未定义。
4.当一个结构包含两个位段,第二个位段成员比较大,无法容纳于第一个位段剩余的位时 是舍弃剩余的位还是利用,这是不确定的。
5.跟结构体相比,位段可以达到同样的效果,但是可以很好的节省空间
总结
博文是我学习过程的一些总结和个人理解,如有错误还请指正,欢迎大家点赞评论收藏支持,也希望和一起学习的小伙伴一起交流学习。
以上是关于自定义类型:结构体的主要内容,如果未能解决你的问题,请参考以下文章