大规模服务网格性能优化 | Aeraki xDS 按需加载
Posted 腾讯云原生
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大规模服务网格性能优化 | Aeraki xDS 按需加载相关的知识,希望对你有一定的参考价值。
作者
钟华,腾讯云专家工程师,Istio project member、contributor,专注于容器和服务网格,在容器化和服务网格生产落地方面具有丰富经验,目前负责 Tencent Cloud Mesh 研发工作。
Istio 在大规模场景下 xDS 性能瓶颈
xDS 是 istio 控制面和数据面 envoy 之间的通信协议,x 表示包含多种协议的集合,比如:LDS 表示监听器,CDS 表示服务和版本,EDS 表示服务和版本有哪些实例,以及每个服务实例的特征,RDS 表示路由。可以简单的把 xDS 理解为,网格内的服务发现数据和治理规则的集合。xDS 数据量的大小和网格规模是正相关的。 当前 istio 下发 xDS 使用的是全量下发策略,也就是网格里的所有 sidecar,内存里都会有整个网格内所有的服务发现数据。比如下图,虽然 workload 1 在业务逻辑上只依赖 service 2, 但是 istiod 会把全量的服务发现数据(service 2、3、4)都发送给 workload 1。
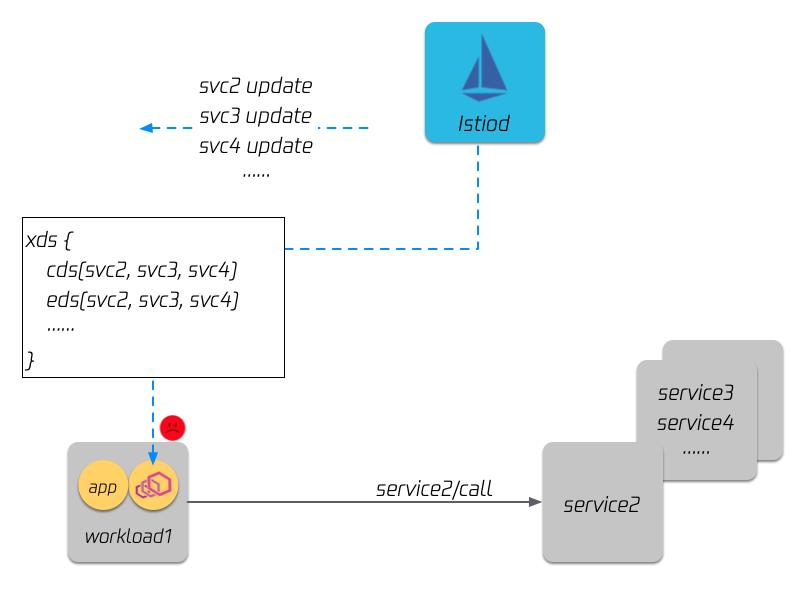
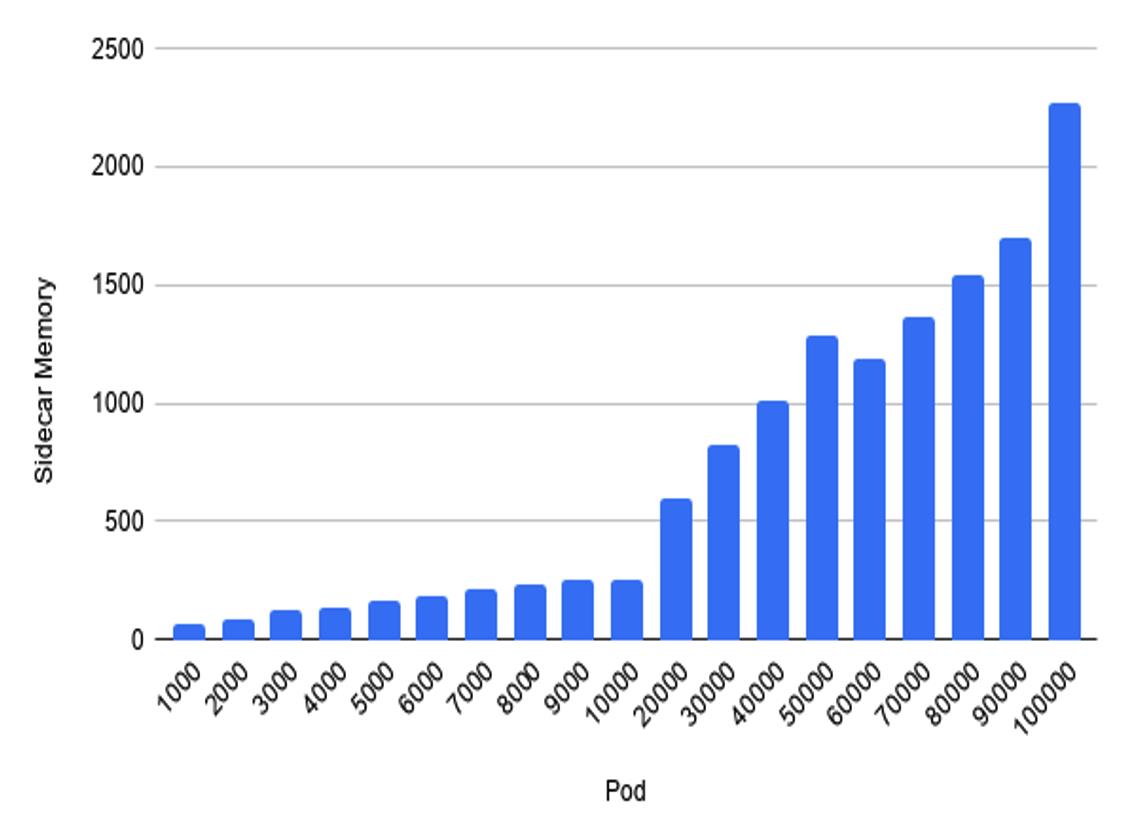
这样的结果是,每个 sidecar 内存都会随着网格规模增长而增长,下图是我们对网格规模和内存消耗做的一个性能测试,x 轴是网格规模,也就是包含多少个服务实例,y 轴是单个 envoy 的内存消耗。可以看出,如果网格规模超过 1万个实例,单个 envoy 的内存超过了 250 兆,而整个网格的开销还要再乘以网格规模大小。
Istio 当前优化方案
针对这个问题,社区提供了一个方案,就是 [Sidecar](https://istio.io/latest/docs/reference/config/networking/sidecar/ "Sidecar") 这个 CRD,这个配置可以显式的定义服务之间的依赖关系,或者说可见性关系。比如下图这个配置的意思就是 workload 1 只依赖 service 2 ,这样配置以后,istiod 只会下发 service 2 的信息给 workload 1。
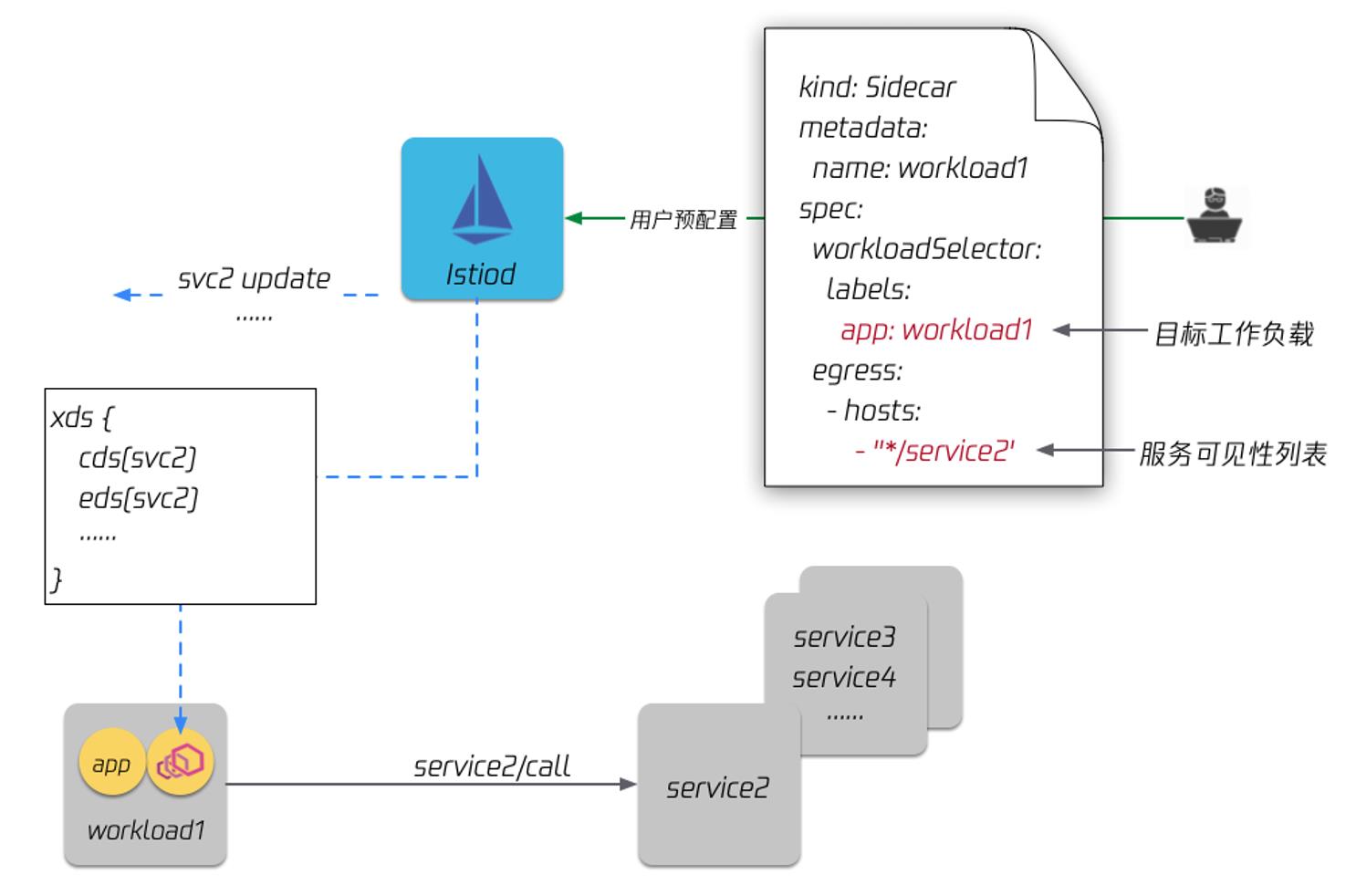
这个方案本身是有效的。但这种方式在大规模场景下很难落地:首先这个方案需要用户提前配置服务间完整的依赖关系,大规模场景下的服务依赖关系很难梳理清楚,而且通常依赖关系也会随着业务的变化而变化。
Aeraki Lazy xDS
针对上述问题,[TCM](https://cloud.tencent.com/product/tcm "TCM") 团队设计了一套无入侵的 xDS 按需加载方案,并开源到 github [Aeraki](https://github.com/aeraki-framework/aeraki "Aeraki") 项目,这是 Lazy xDS 具体的实现细节:
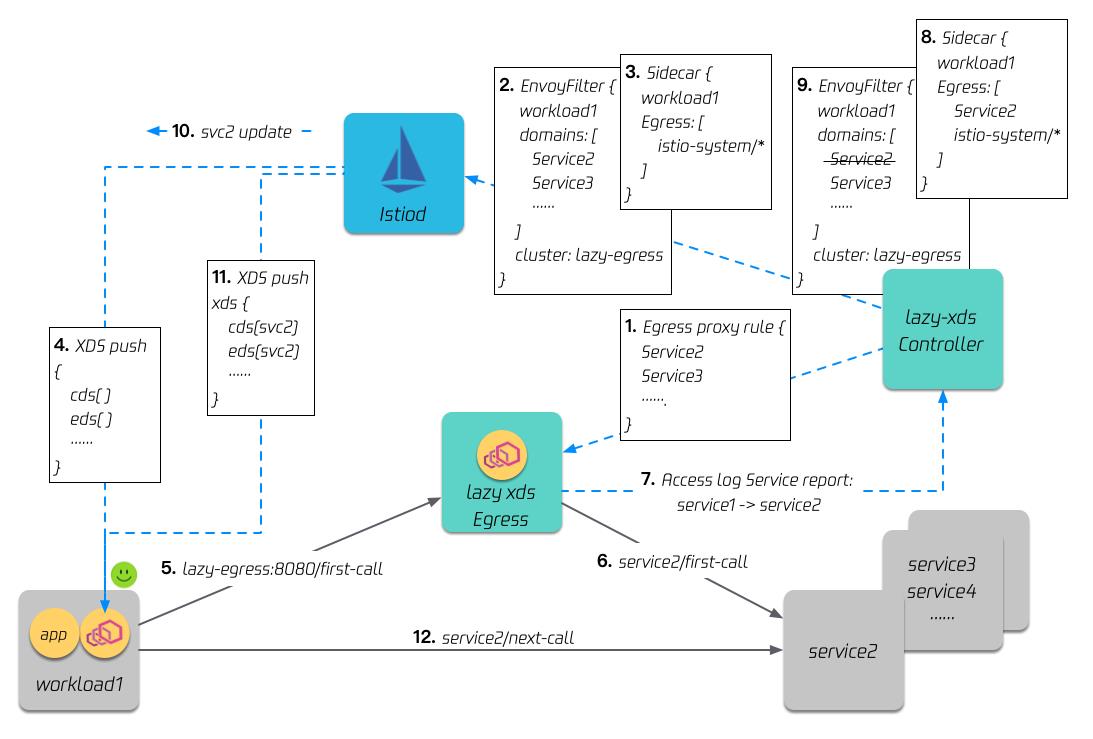
我们在网格里增加2个组件,一个是 Lazy xDS Egress,Egress 充当类似网格模型中默认网关角色,另一个是 Lazy xDS Controller,用来分析并补全服务间的依赖关系。
- 首先配置 Egress 的服务中转能力:Egress 会获取网格内所有服务信息,并配置所有 HTTP 服务的路由,这样充当默认网关的 Egress 就可以转发网格内任意 HTTP 服务的流量。
- 第2步,对于开启了按需加载特性的服务(图中 Workload 1),利用 envoyfilter,将其访问网格内 http 服务的流量,都路由到 egress。
- 第3步,利用 istio sidecar CRD,限制 Workload 1 的服务可见性。
- 经过步骤3后,Workload 1 初始只会加载最小化的 xDS。
- 当 Workload 1 发起对 Service 2 的访问时,(因为步骤2)流量会转发到 Egress。
- (因为步骤 1)Egress 会分析接收到的流量特征,并将流量转发到 Service 2。
- Egress 会将访问日志,异步地上报给 Lazy xDS Controller,上报服务是利用 [Access Log Service](https://www.envoyproxy.io/docs/envoy/latest/api-v3/service/accesslog/v3/als.proto.html "Access Log Service")。
- Lazy xDS Controller 会对接收到的日志进行访问关系分析,然后把新的依赖关系(Workload 1 -> Service 2)表达到 sidecar CRD 中。
- 同时 Controller 还会将(步骤2) Workload 1 需要转发 Service 2 流量到 Egress 的规则去除,这样未来 workload 1 再次访问 Service 2 就会是直连。
- (因为步骤 8)istiod 更新可见性关系,后续会将 Service 2 的服务信息发给 Workload 1。
- Workload 1 通过 xDS 接收到 Service 2 的服务信息。
- 当 Workload 1 再次发起对 Service 2 的访问,流量会直达 Service 2(因为步骤9)。
这个方案的好处:
- 首先不需要用户提前配置服务间的依赖,而且服务间依赖是允许动态的增加的。
- 最终每个 envoy 只会获得自身需要的 xDS,性能最优。
- 这个实现对用户流量影响也比较小,用户的流量不会阻塞。性能损耗也比较小,只有前几次请求会在 Egress 做中转,后面都是直连的。
- 此方案对 istio 和 envoy 没有任何入侵,我们没有修改 istio/envoy 源码,使得这套方案能很好的适应未来 istio 的迭代。
目前我们只支持七层协议服务的按需加载,原因是流量在 Egress 这里中转的时候,Egress 需要通过七层协议里的 header 判断原始目的地。纯 TCP 协议是没有办法设置额外的 header。不过因为 istio 主要目的就是为了做七层流量的治理,当网格的大部分请求都是七层的,这个情况目前可以接受的。
Lazy xDS 性能测试
测试方案
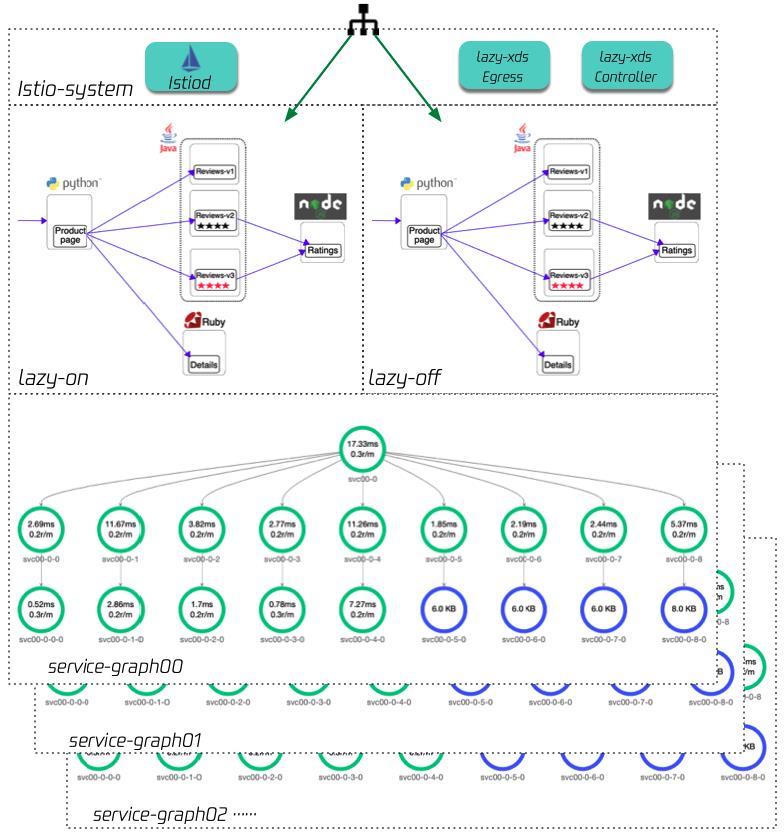
在同一网格内的不同 namespace 中,我们创建了 2 组 book info,左边 namespace lazy-on 中 productpage 开启按需加载,右边 namespace lazy-off 保持默认情况。 然后在这个网格内,我们逐渐增加服务数量,使用的是 istio 官方[负载测试工具集](https://github.com/istio/tools/tree/master/perf/load "负载测试工具集")(以下简称「负载服务」),每个 namespace 里有 19 个服务, 其中4个 tcp 服务,15个 http 服务,每个服务初始 pod 数目为 5,共95个 pod(75 个http,20 个tcp)。我们逐渐增加负载服务的 namespace 数量, 用于模拟网格规模增长。
性能对比
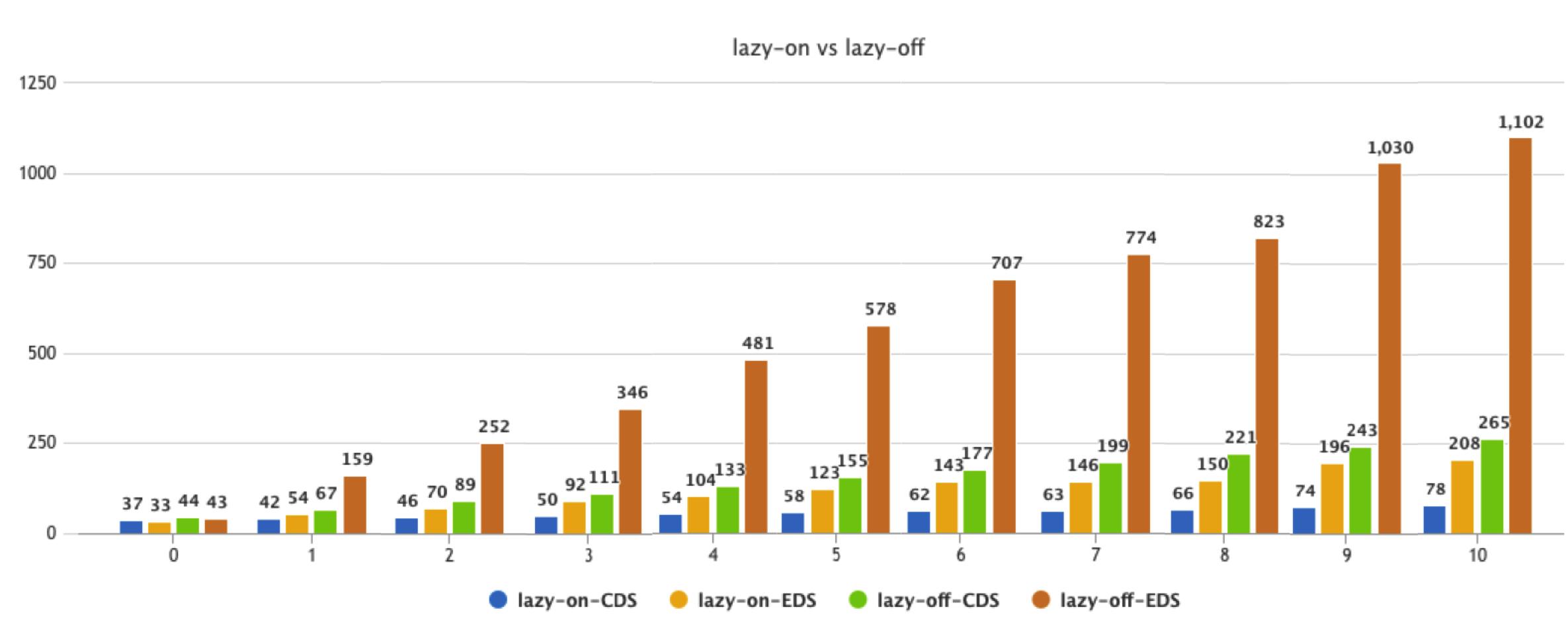
首先是 CDS 和 EDS 的对比,下图每组数据代表负载服务 namespace 的增加,每组数据里 4 个值:前 2 个值是开启按需加载后的 CDS 和 EDS,后面 2个值是没开启按需加载的 CDS 和 EDS。
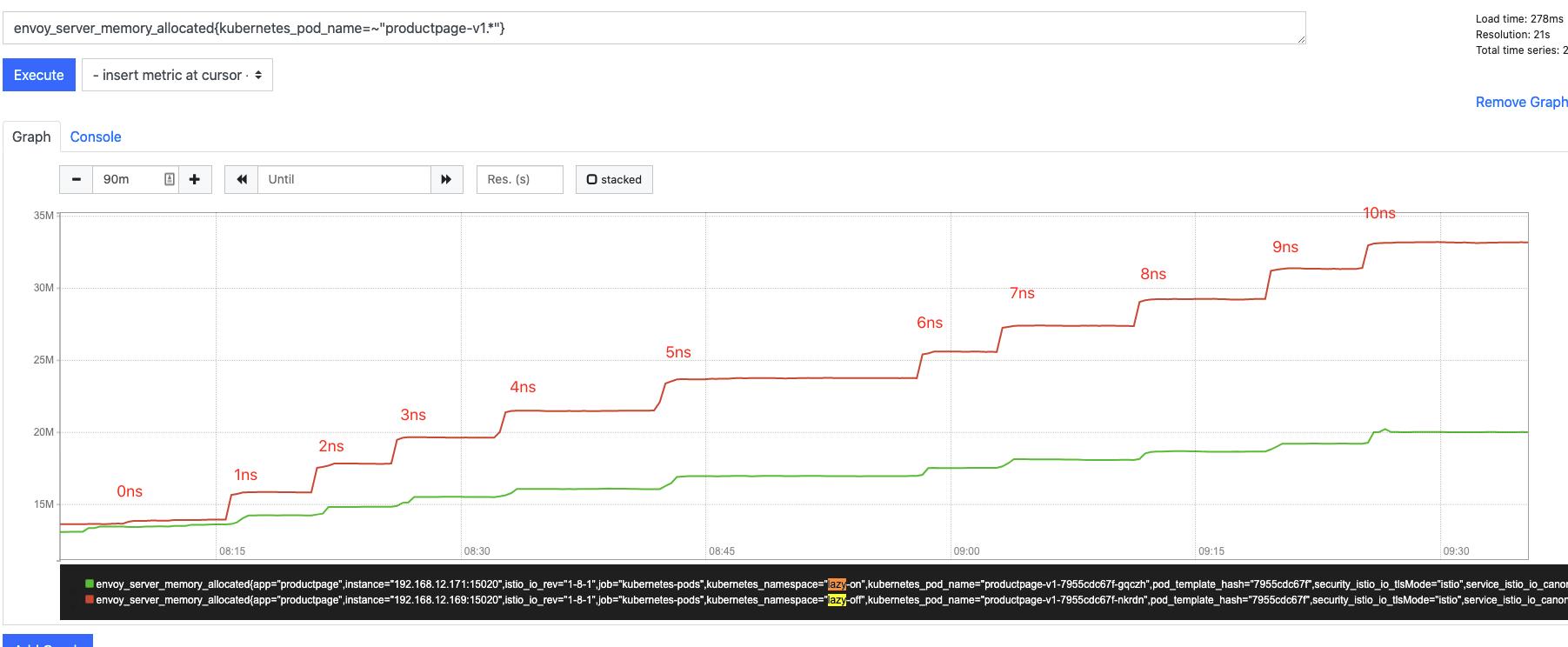
接下来是内存对比,绿色数据表示开启按需加载后 envoy 的内存消耗,红色的是未开启的情况。900 pods 规模 mesh,envoy 内存减少 14M ,降低比例约 40%;一万 pods 规模 mesh,envoy 内存减少约 150M,降低比例约 60%。
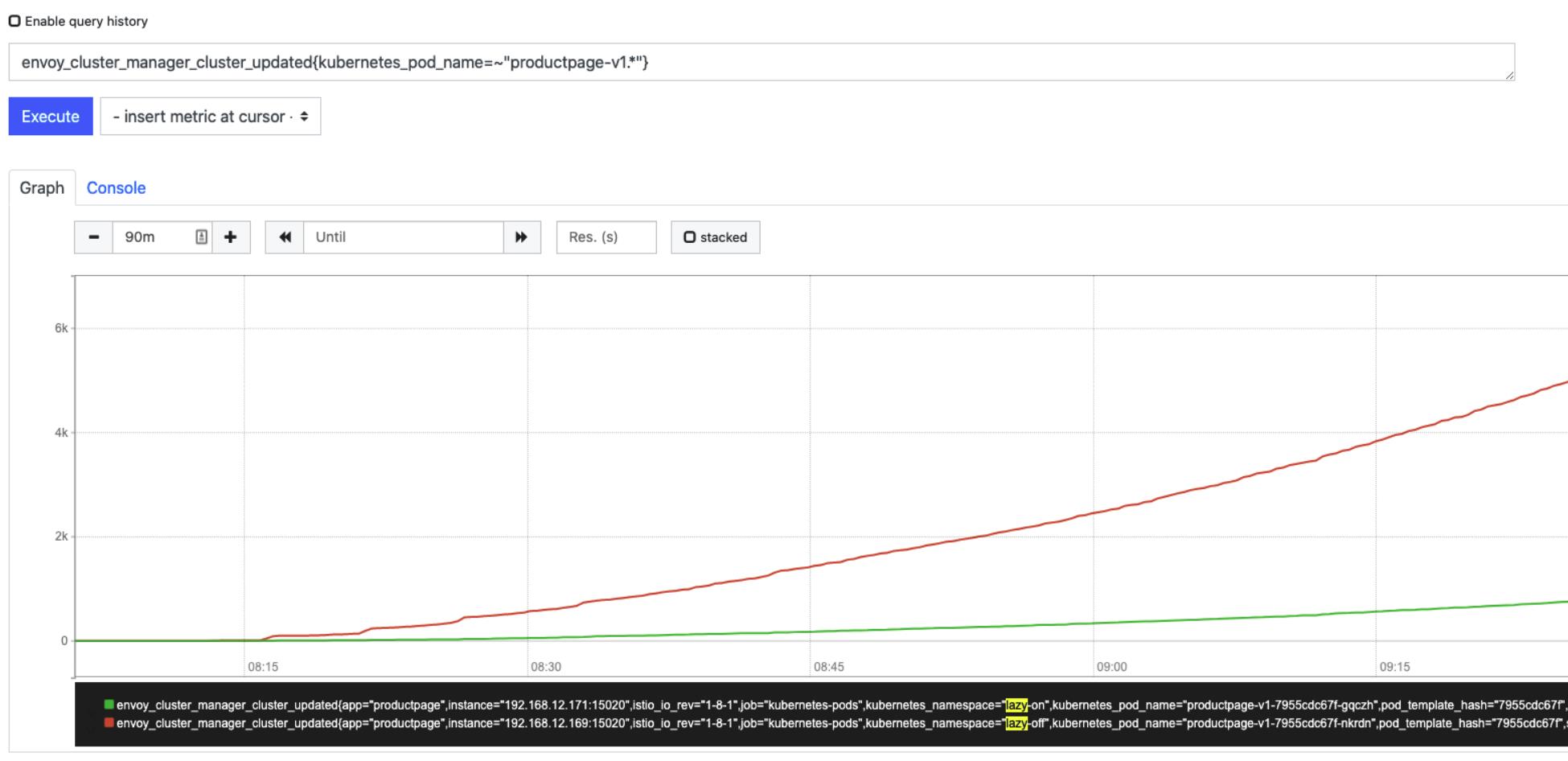
随着服务可见性的限制,envoy 不会再接收全量的 xDS 更新,下图是在测试周期内 envoy 接收到 CDS 更新次数的对比,开启按需加载后,更新次数从 6 千次降低到了 1 千次。
小结
Lazy xDS 已经在 github 开源,请访问 [lazyxds README](https://github.com/aeraki-framework/aeraki/blob/master/lazyxds/README.md "lazyxds README")了解如何使用。 Lazy xDS 功能还在持续演进,未来我们将支持多集群模式、ServiceEntry 按需加载等功能。 如果您希望了解更多关于 Aeraki 的内容,欢迎访问 Github 主页:https://github.com/aeraki-framework/aeraki
关于我们
更多关于云原生的案例和知识,可关注同名【腾讯云原生】公众号~ 福利: ①公众号后台回复【手册】,可获得《腾讯云原生路线图手册》&《腾讯云原生最佳实践》~ ②公众号后台回复【系列】,可获得《15个系列100+篇超实用云原生原创干货合集》,包含Kubernetes 降本增效、K8s 性能优化实践、最佳实践等系列。 ③公众号后台回复【白皮书】,可获得《腾讯云容器安全白皮书》&《降本之源-云原生成本管理白皮书v1.0》
以上是关于大规模服务网格性能优化 | Aeraki xDS 按需加载的主要内容,如果未能解决你的问题,请参考以下文章
KubeCon 2021|使用 eBPF 代替 iptables 优化服务网格数据面性能