pytorch Tensor和Variable
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了pytorch Tensor和Variable相关的知识,希望对你有一定的参考价值。
参考技术A Tensor是pytorch中最基本的构件,可以像numpy一样进行矩阵计算,最主要的是Tensor支持GPU加速运算。而且Tensor的运算与numpy的运算基本相似,但有部分高级的矩阵计算Tensor并不支持,比如计算特征值特征向量等。因此numpy还是有存在的必要的。tensor是Pytorch中非常高效数据格式,但用tensor构建神经网络还远远不够,为了构建计算图,所以Variable是不可或缺的数据形式。Variable是对tensor的封装。
Variable有三个属性:
PyTorch:tensor-基本操作
Tensor 和 Variable
torch新版本中合并了Tensor 和 Variable,Variable 仍然像以前一样工作,只不过返回的是 Tensor 。这意味着我们使用的时候只需要声明Tensor 就好了,更详细的,torch.tensor可以像旧的Variable一样对计算历史进行追踪了,你再也不用到处声明Variable了。
初始化
a = torch.tensor([1]) 或者a = torch.tensor([[1, 2]])什么的
b = torch.tensor(1)
a 和 b 之间是有很大的区别的,b是没有size的。
a.size() #torch.Size([1])
b.size() #torch.Size([])
b.size(0) #IndexError: dimension specified as 0 but tensor has no dimensions
torch.tensor([[1,2,3], torch.tensor([3,4,5])])
但是不能这么初始化:torch.tensor([torch.tensor([3,4,5]), [3,4,5]])
会报错:ValueError: only one element tensors can be converted to Python scalars
本地计算
torch函数参数: inplace-选择是否进行覆盖运算,True即对原值进行操作,然后将得到的值又直接复制到该值中,这样能够节省运算内存,不用多存储其他变量。
[nn.ReLU(inplace=True)中inplace的作用]
张量字节数
查看张量单个元素的字节数
torch.Tensor.element_size() → int
查看某类型张量单个元素的字节数。
torch.FloatTensor().element_size()
4
dtypes/devices
对于数据类型、设备和分布情况 (密集和稀疏) ,我们引入 torch.dtype, torch.device 和torch.layout 类来分别管理这些特性。
- Torch.dtype
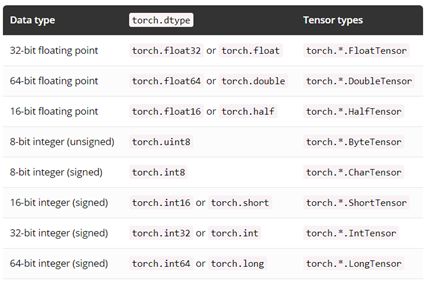
下面是完整的 dtype 列表,张量的 dtype 可以通过其 dtype 属性来获得
- Torch.device
Torch.device 包含了一个设备类型('cpu'或者'cuda') 和一个可选的该设备的序列号 (id) 可以被初始化为 torch.device('device_type') 或 torch.device('device_type:device_ or dinal' 如果设备的序列号没有被定义,那么默认使用当前的设备,比如 torch.device('cuda' ) 等于 torch.device('cuda:X') ,其中 X 是 torch.cuda.current_device( ) 的返回值
对于张量的设备类型可以通过其 device 属性获得
判断模型是在CPU还是GPU上:print(next(model.parameters()).device)
判断数据是在CPU还是GPU上:print(data.device)
此外,用.is_cuda也可以判断模型和数据是否在GPU上,例如: data.is_cuda 。
- Torch.layout
Torch.layout 代表了数据分布类型,目前支持 torch.strided 和 torch.sparse_coo 类型
张量的 layout 情况可以通过其 layout 属性获得
CUDA 的用法
# 判断cuda是否可用;
print(torch.cuda.is_available())
# 获取gpu数量;
print(torch.cuda.device_count())
# 获取gpu名字;
print(torch.cuda.get_device_name(0))
# 返回当前gpu设备索引,默认从0开始;
print(torch.cuda.current_device())
# 查看tensor或者model在哪块GPU上
print(torch.tensor([0]).get_device())
[gpu训练应用PyTorch:模型训练和预测]
GPU tensor 转CPU tensor
gpu_imgs.cpu()
其它转换
numpy转为CPU tensor
torch.from_numpy( imgs )
CPU tensor转为numpy数据
cpu_imgs.numpy()
Note:GPU tensor不能直接转为numpy数组,必须先转到CPU tensor。
如果tensor是标量的话,可以直接使用 item() 函数(只能是标量)将值取出来
loss.item()
数据分离
.data 与 .detach()
PyTorch0.4以及之后的版本中,.data 仍保留,但建议使用 .detach()。
区别在于:
.data 返回和 x 的相同数据的 tensor,但不会加入到x的计算历史里,且require s_grad = False,这样有些时候是不安全的,因为 x.data 不能被 autograd 追踪求微分 。
.detach() 返回和 x相同数据的 tensor,且 requires_grad=False,但能通过 in-place 操作报告给 autograd 在进行反向传播的时候。
.data例子
>>> a = torch.tensor([1,2,3.], requires_grad =True)
>>> out = a.sigmoid()
>>> c = out.data
Note: 通过.data “分离”得到的的变量会和原来的变量共用同样的数据,而且新分离得到的张量是不可求导的,c发生了变化,原来的张量也会发生变化。
>>> c.zero_()
tensor([ 0., 0., 0.])
>>> out # out的数值被c.zero_()修改
tensor([ 0., 0., 0.])
>>> out.sum().backward() # 反向传播
>>> a.grad # 这个结果很严重的错误,因为out已经改变了。# 不会报错,但是结果却并不正确
tensor([ 0., 0., 0.])
.detach()例子
>>> a = torch.tensor([1,2,3.], requires_grad =True)
>>> out = a.sigmoid()
>>> c = out.detach()
Note: c = out.detach() # 需要走注意的是,通过.detach() “分离”得到的的变量会和原来的变量共用同样的数据,而且新分离得到的张量是不可求导的,c发生了变化,原来的张量也会发生变化。
>>> c.zero_()
tensor([ 0., 0., 0.])
>>> out # out的值被c.zero_()修改 !!
tensor([ 0., 0., 0.])
>>> out.sum().backward() # 需要原来out得值,但是已经被c.zero_()覆盖了,结果报错 # 此时会报错,错误结果参考下面,显示梯度计算所需要的张量已经被“原位操作inplace”所更改了。
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation.
使用tensor.data的局限性
tensor.data是不安全的, 因为 x.data 不能被 autograd 追踪求微分 。从上面的例子可以看出,由于更改分离之后的变量值c,导致原来的张量out的值也跟着改变了,但是这种改变对于autograd是没有察觉的,它依然按照求导规则来求导,导致得出完全错误的导数值却浑然不知。它的风险性就是如果我再任意一个地方更改了某一个张量,求导的时候也没有通知我已经在某处更改了,导致得出的导数值完全不正确,故而风险大。
使用tensor.detach()的优点
从上面的例子可以看出,由于我更改分离之后的变量值c,导致原来的张量out的值也跟着改变了,这个时候如果依然按照求导规则来求导,由于out已经更改了,所以不会再继续求导了,而是报错,这样就避免了得出完全牛头不对马嘴的求导结果。
总结
相同点:tensor.data和tensor.detach() 都是变量从图中分离,都是“原位操作 inplace operation”,都是变成require s_grad = False。
不同点:
(1).data 是一个属性,.detach()是一个方法;
(2).data 是不安全的,.detach()是安全的。
detach()的主要用途
detach()的主要用途是将有梯度的变量变成没有梯度的,即requires grad=True变成requires grad=False. 因为网络内的值或输出的值都有梯度,所以要想将值转换成其他类型(如转换成numpy类型),都需要先去掉梯度,一般这样搭配使用:
1 .detach().cpu().numpy() 将GPU类型变成CPU类型,再继续转换成numpy类型。
2 .detach().numpy() CPU类型转换成numpy()类型。如果你的电脑是用GPU训练就用第一种,用CPU训练就用第二种。
3 predictions = outputs.squeeze().contiguous()
predictions.cpu().detach().numpy().reshape((-1,))
4 如果想保持a不变,则可以
a = out.clone().detach().cpu().numpy()
clone()是torch.tensor类型才有的。
5 detach的方法,将variable参数从网络中隔离开,不参与参数更新。
# y=A(x), z=B(y) 求B中参数的梯度,不求A中参数的梯度
y = A(x)
z = B(y.detach())
z.backward()
.item()与.data的区别
.data返回的是一个tensor。
.item()返回的是一个具体的数值。
Note:对于元素不止一个的tensor列表,使用item()会报错
import torch
a = torch.ones([1,3])
print(a)
print(a.data)
print(a.data[0,1])
print(a.data[0,1].item())
# print(a.item()) 运行该行代码会报错
tensor([[1., 1., 1.]])
tensor([[1., 1., 1.]])
tensor(1.)
1.0
view()
类似numpy中resize()的功能,但是用法可能不太一样。把原先tensor中的数据按照行优先的顺序排成一个一维的数据(这里应该是因为要求地址是连续存储的),然后按照参数组合成其他维度的tensor。比如说是不管你原先的数据是[[[1,2,3],[4,5,6]]]还是[1,2,3,4,5,6],因为它们排成一维向量都是6个元素,所以只要view后面的参数一致,得到的结果都是一样的。
参数不可为空。参数中的-1就代表这个位置由其他位置的数字来推断。比如a tensor的数据个数是6个,如果view(1,-1),我们就可以根据tensor的元素个数推断出-1代表6。而如果是view(-1,-1,2),人不知道怎么推断,机器也不知道。还有一种情况是人可以推断出来,但是机器推断不出来的:view(-1,-1,6),人可以知道-1都代表1,但是机器不允许同时有两个负1。如果没有-1,那么所有参数的乘积就要和tensor中元素的总个数一致了,否则就会出现错误。
示例:
a=torch.Tensor([[[1,2,3],[4,5,6]]])
b=torch.Tensor([1,2,3,4,5,6])
print(a.view(1,6))
print(b.view(1,6))
都是tensor([[1., 2., 3., 4., 5., 6.]])
print(a.view(3,2))
tensor([[1., 2.],
[3., 4.],
[5., 6.]])
如果想得到如下的结果:
tensor([[1., 4.],
[2., 5.],
[3., 6.]])
就需要使用另一个函数了:permute()[PyTorch中permute的用法 ]。
contiguous()
关于 contiguous,PyTorch 提供了is_contiguous、contiguous(形容词动用)两个方法 ,分别用于判定Tensor是否是 contiguous 的,以及保证Tensor是contiguous的。
is_contiguous直观的解释是Tensor底层一维数组元素的存储顺序与Tensor按行优先一维展开的元素顺序是否一致。
为什么需要 contiguous ?
1. torch.view等方法操作需要连续的Tensor。
transpose、permute 操作虽然没有修改底层一维数组,但是新建了一份Tensor元信息,并在新的元信息中的 重新指定 stride。
torch.view 方法约定了不修改数组本身,只是使用新的形状查看数据。
如果我们在 transpose、permute 操作后执行 view,Pytorch 会抛出以下错误:invalid argument 2: view size is not compatible with input tensor's size and stride (at least one dimension spans across two contiguous subspaces). Call .contiguous() before .view(). at /Users/soumith/b101_2/2019_02_08/wheel_build_dirs/wheel_3.6/pytorch/aten/src/TH/generic/THTensor.cpp:213
为什么不在view 方法中默认调用contiguous方法?
1 因为历史上view方法已经约定了共享底层数据内存,返回的Tensor底层数据不会使用新的内存,如果在view中调用了contiguous方法,则可能在返回Tensor底层数据中使用了新的内存,这样打破了之前的约定,破坏了对之前的代码兼容性。为了解决用户使用便捷性问题,PyTorch在0.4版本以后提供了reshape方法,实现了类似于 tensor.contigous().view(*args)的功能,如果不关心底层数据是否使用了新的内存,则使用reshape方法更方便。
2 出于性能考虑
连续的Tensor,语义上相邻的元素,在内存中也是连续的,访问相邻元素是矩阵运算中经常用到的操作,语义和内存顺序的一致性是缓存友好的(What is a “cache-friendly” code?[4]),在内存中连续的数据可以(但不一定)被高速缓存预取,以提升CPU获取操作数据的速度。transpose、permute 后使用 contiguous 方法则会重新开辟一块内存空间保证数据是在逻辑顺序和内存中是一致的,连续内存布局减少了CPU对对内存的请求次数(访问内存比访问寄存器慢100倍[5]),相当于空间换时间。
.new()
作用
创建一个新的Tensor,该Tensor的type和device都和原有Tensor一致,且无内容。
随机定义一个m*n大小的Tensor有两种创建方法,如下:
inputs = torch.randn(m, n)
new_inputs = inputs.new()
new_inputs = torch.Tensor.new(inputs)
实际应用(添加噪声)
可以对Tensor添加噪声:
inputs = torch.randn(1,4)
noise = inputs.data.new(inputs.size()).normal_(0,0.01)
print(noise)
结果如下:
tensor([ 0.0062, 0.0137, -0.0209, 0.0072], device='cuda:0')
模型输出函数sigmoid
这里只提一个精度问题:
torch.sigmoid(torch.Tensor([10])) = torch.sigmoid(torch.Tensor([-89])) = tensor([1.0000])
超出-89和10之外的,都是极值。
from: -柚子皮-
ref: torch官网tensor函数[TORCH.TENSOR]
以上是关于pytorch Tensor和Variable的主要内容,如果未能解决你的问题,请参考以下文章