星环科技分布式搜索引擎 Transwarp Scope 查询优化技术解读
Posted 星环科技
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了星环科技分布式搜索引擎 Transwarp Scope 查询优化技术解读相关的知识,希望对你有一定的参考价值。
概述
分布式数据库系统是物理上分布而逻辑上集中的数据库系统,为了提高性能并最大限度地减少资源争用,其被广泛用于海量数据处理的场景中。在这种情况下,数据库查询速度是系统性能表现的决定性指标。而由于数据分布在不同节点上并通过网络通信在不同节点间传输,分布式查询的处理流程比单机集中式查询更加复杂。与传统的集中式数据库系统相比,对分布式查询的构建和优化需要同时考虑CPU、I/O成本以及网络通信成本。
本文旨在从分布式集群视角,对Transwarp Scope查询相关原理和优化技术进行较为全面的解读。
整体流程
对于分布式搜索引擎来说,一般情况下, 一次查询涉及到多台机器的多个分片,正确的结果需要汇总多个分片的各自结果之后才能获得。因此,无论是Transwarp Scope还是es,其查询过程都包括一个Merger的角色存在,这个Merger在es中是Coordinating node, 而在NS中是Client。而整个流程以Phase划分,可以分为DFS, QUERY, FETCH三类Phase。
专用词与明确
分片一般也被成为shard/tablet
Phase简介
DFS Phase:统计数据收集阶段,对于文本信息来说,其在单个text中的freq等信息是准确的。但是类似与idf这样的全局统计信息而言,每个分片只能明确该文本在分片内部的idf,也就是一个局部的idf。如果不进行全局idf综合统计,仅以local idf计算score,得出来的分数是不准确的。所以,在很多对打分结果准确性要求较高的场景下, 都会有dfs这个阶段进行全局统计信息汇总。当然,也因为多了这个阶段,相应地响应速度也会受到影响。
Query Phase:查询阶段, 根据client输入的信息在各个分片上找到匹配的文档集合。这一阶段基本上会做3件事情:match(匹配),score(打分),local_sort(本地排序)。各个分片会将匹配的doc_id集合,返回给Merger节点。Merger节点会对各个分片汇报上来的doc_set进行merge + global_sort。然后根据client设定的from,size, 从global_result_set中cut出[from, from + size],再进行下一阶段。
Fetch阶段:获取doc原始内容的phase。该Phase会根据Query Phase结束后的global_result_set向各个分片索要目标的doc_set, 包括文档的原始内容以及可能的某些再加工内容,比如Highlight。由于要真正地加载文档内容[source],所以 Fetch阶段会产生比较大的io负载(page cache缺失的情况下)。因此,如果是一些大宽表(500列+)的场景,其行数据size比较大的情况下,更可行的方式其实是把ES/NS作为一张纯粹的Index Table,即只对目标列设置索引 + 对外表主键列存储source。如此,当query阶段阶段执行完之后,进行fetch phase的时候只需要加载rowkey这一列的值,再global_result_set中的外表rowkey值去外部行数据库中拿到原始内容,这样做能明显减轻es/ns集群的存储和读写压力。
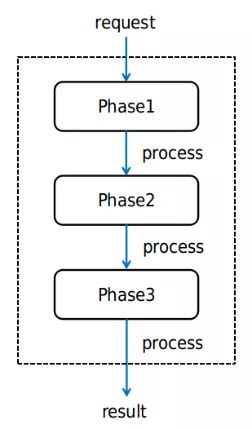
从整体上来看,查询部分基本的架构原则就是用各种不同的Phase拼接执行不同的查询动作,即Compose Phases into Action.如上图示意。
查询操作类型简介
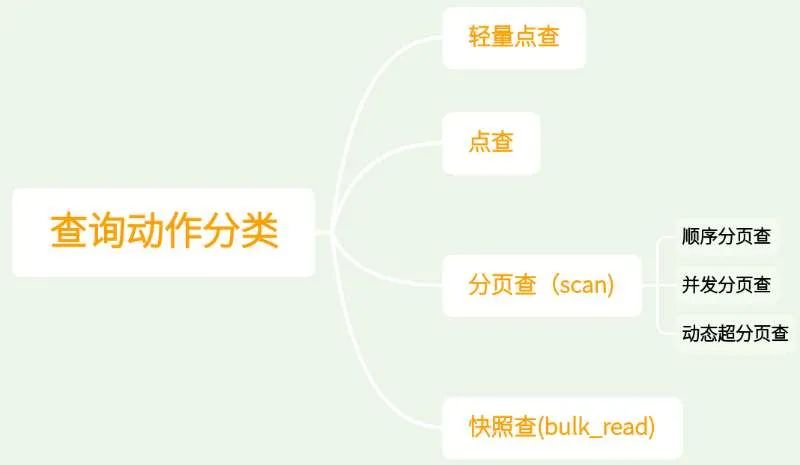
查询操作本身可以按照如上图这样进行细分, 各自含义如下表:
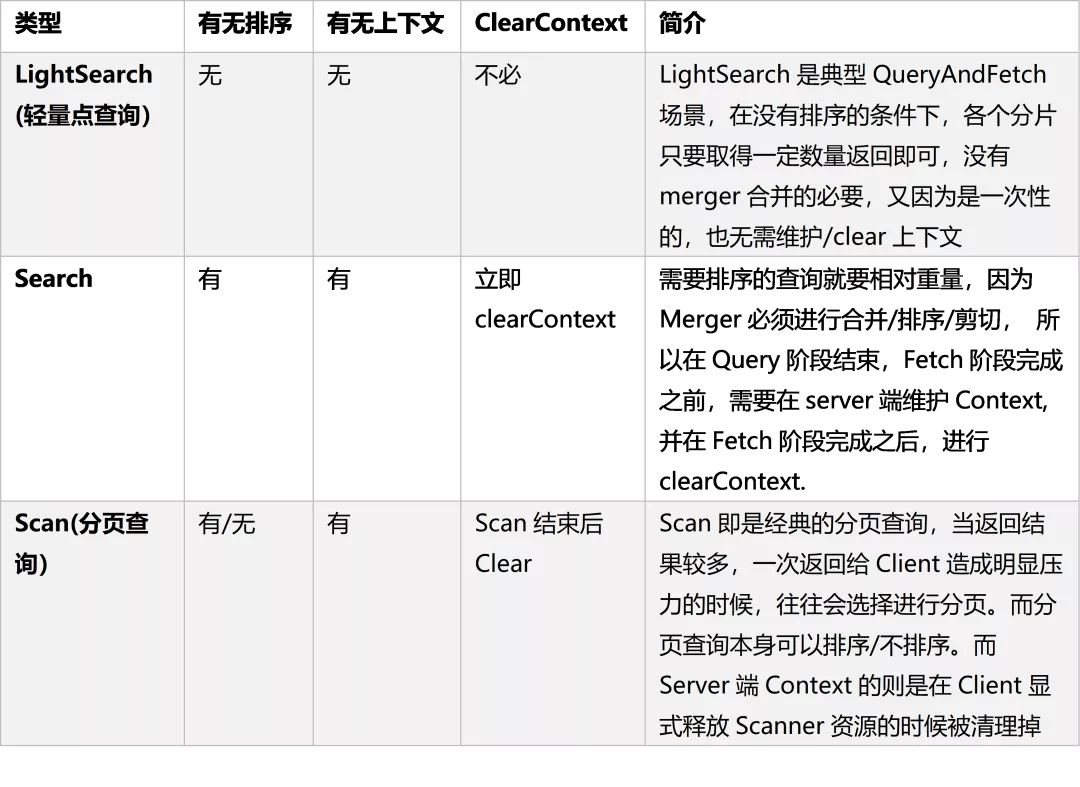
点查询图解
点查,或者说排序查询是核心功能,举例如下。
对于一张成绩表schema=(姓名、数学成绩、语文成绩、 英语成绩),整张表格有3个tablet, 现在要获取全部成绩的前3名,则整体流程如下图所示。
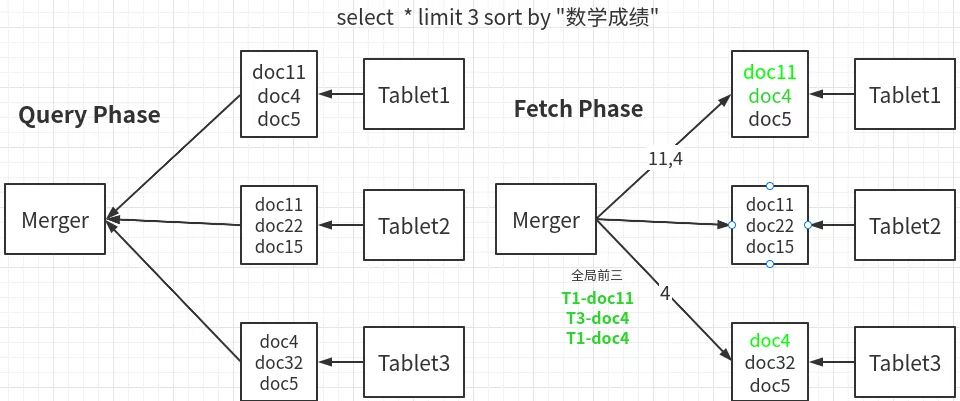
如上图所示,即为单次点查询的原理示意图。在Query阶段,所有Tablet都将自己的数学成绩的前3名汇总给Merger, Merger进行全局排序之后,发现真正的前三名是tablet1的11,4号, tablet3的4号。然后在Fetch阶段,将这些对应doc标识发送给tablet1, tablet3, 再拿到对应的文档原始内容,这里有2处细节值得提及。
二维全局rowKey。在上图所示数据分布体系中, 用以表示全局唯一row或者doc的标识是一个(tablet, docId)的二元组,及tablet1和tablet3都有doc4, 但2者没有关系。
上图所示是在全局数据本身无序分布的情况下进行排序查询的流程,如果对数据本身就是有序分布的, 那么流程会大大简化,这一点会在后续内容中讨论。
分页查询
所谓分页查询,或者扫描,就是当结果集比较大的时候,分成多次rpc返回结果。
1.并发分页查询
所谓并发分页,如下图所示,就是client同时向所有的tablet发送request。这种情况下,每一页的具体流程以排序/不排序分可以对应上文点查/轻量点查。
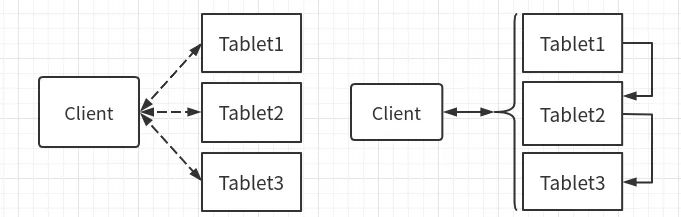
2.顺序分页查
所谓顺序分页查,如上右图所示,指的是每一页并不是将rpc同时发送给所有tablet, 而是对所有tablet进行逐个扫描,tablet1,tablet2,tablet3。这种扫描方式的明显好处就是大幅度减少了rpc的数量,降低了集群整体负载。又因为每个rpc只有1个tablet的结果,所以也不需要进行多个tablet结果的合并,降低了client的处理负载。
3.动态超分页查询
对于查询操作来说,缓存是很有效果的优化措施。尤其是对一些单线程扫描全表的应用,其客户端内存可能大量闲置。这种场景下,合理地使用客户端内存作为缓存来优化查询速度,就是动态超分页查询的思想,其基本原理仍以是否排序分2种情况讨论。
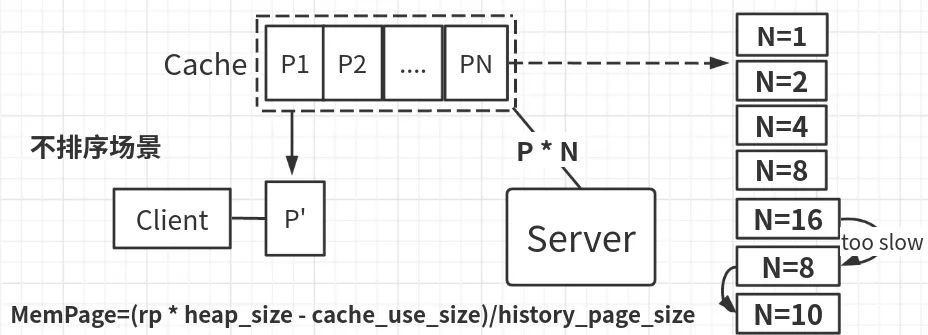
对于不排序场景,缓存的策略很简单,如上图所示,就是一次rpc取n个整页,放在客户端内存中备用,从第二次之后,直接从本地内存中取用。而为了在保证稳定性的基础上尽可能地加快scan,对于N这个值采用二进制试探+回退的方式进行控制。即最开始只取一页,然后是2,4,8,16。在这个过程中,保存Page的平均大小和已经使用的内存量,综合jvm内存大小,从而计算出下一次scan最大能拿多少页。从而让N回退,降低client内存压力,保证客户端程序的稳定。在实际使用中,一般会限定客户端jvm_heap的8%作为scan_cache的上限。
此外,为了避免N过大导致延迟过长问题,当单次时间超过一定阈值的时候,N也会相应回退,避免让客户端感觉到太明显的卡顿。
对于排序场景,缓存不能像no sort场景下这么鲁莽。因为排序本身存在一个回收率(1/s)的问题,即前文所提及的,3个shard, 取前3名,则实际上需要拿到3×3=9行数据,最终有效返回却是只有3行,所以回收率=1/3。在超大集群场景下,一张大表可能有500+个shard,此时如果贸然地扩大N倍,一次性从server端取回4000-5000个page,很有可能造成client剧烈的gc, 影响程序稳定。因此,排序场景下客户端缓存,Transwarp Scope采用了客户端复用的方式来进行。
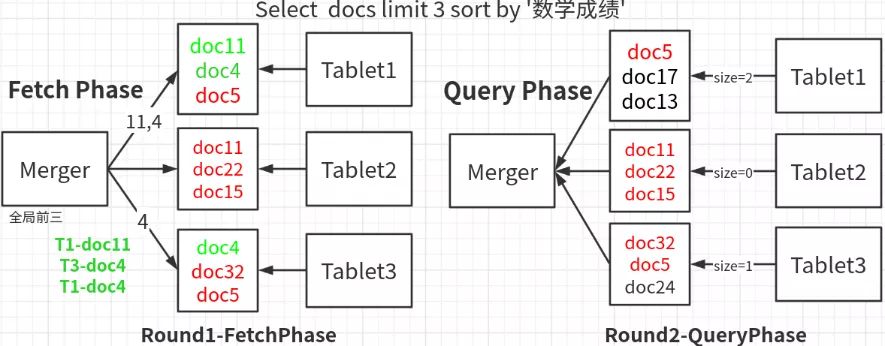
如上图所示,续前文所述排序场景下QueryThenFetch的流程,当第一轮Fetch结束之后,真正的全局前三被fetch之后,剩余的(图中标红的)T1-doc5, T2-doc11-doc22-doc15和T3-doc32-doc5,一定是下一轮全局排序的备选项,所以下一轮query阶段并不需要再从每个tablet拿3个了,对于tablet1,只需要再拿2个,tablet3再拿3个, 而tablet2则不需要在round2进行query阶段。在超大表的场景下,以500shard, page_size=1000为例, 那么98%的row都可以在客户端进行复用,从而大大减少了rpc次数和server端查询排序的开销。当然,实际生产环境中也要考虑到rpc_size的问题,配合整页缓存一起使用。
查询优化的基础:分区
分区是最直接有效的查询加速手段,尤其是对于超大规模的集群的大表(1000+ shard, 单表50T)这样的场景,如果能在查询真正开始之前将搜索范围缩小到全量数据集合的1-2%,即10-20shard,500G-1000G这个规模。那么实际表现出来的性能就是百毫秒到秒级级别。
最常见的两种分区机制,是Range分区和Hash分区。
1.Range分区
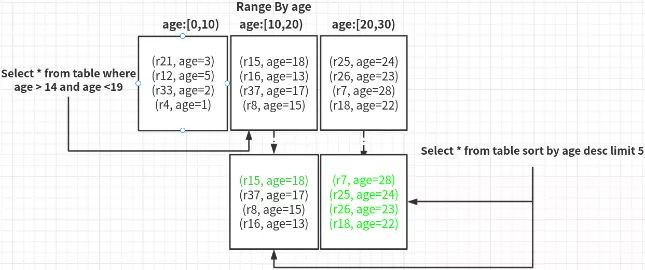
如上图所示,即为Range分区的基本原理示意图,所有的row, 按照age这一列进行划分partition。当select (14,19)之间的row时,就可以通过partition prune将查询限制在一个tablet1上,从而避免了全表搜索,大幅度减少了集群负载。
另外,在排序场景下,如果要获取全局age最大的5个row, 那么在已有范围分区的情况下,只需要对tablet1和tablet2的数据进行排序, 填满结果集即可,避免了对Tablet1的无效查询和排序。
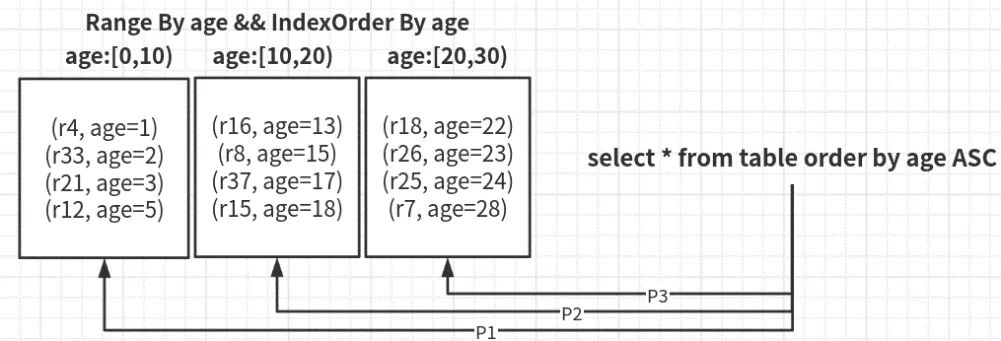
又如上图所示,在Range分区的基础上,配合分片内部的预排序,就可以保证整张表格数据的全局有序。此时的升序扫表动作,就转换成了顺序依次扫描每个shard,从而完全避免了分片级别/表级别的排序动作,极大提升速度。
2.Hash分区

hash分区的即是根据指定列的hash值进行分区,如上图所示,当搜索age=13的所有row时, 由于13的hash值是1,所以搜索可以被剪枝到tablet1上,从而避免了tablet0, tablet2的无效搜索。
3.混合分区
分区的实际意义在于,通过对数据进行物理分布上的隔离,从而查询时进行大片的剪枝。在实际使用中,真实数据可能有很多的细化查询需求,需要对数据进行不止一层或一种分区,这就对应了混合分区的概念。
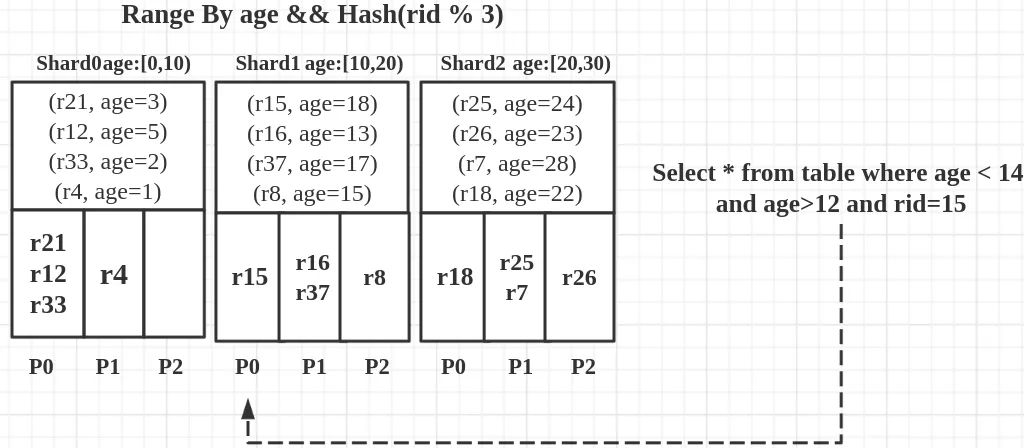
如上图所示,数据全集采用2层分区进行物理隔离,在shard级别,按照age进行范围分区。在每个shard内部,再按照rid进行hash分区。那么对于如上图sql, 查询操作能立刻通过partiton prune将范围缩小到shard1的P0 Parition上,查询范围大大缩小。
注意,在同一个物理隔离级别上,只能有一个Range分区标准,否则会有歧义导致无法排序。而Hash分区可以组合多个。
总结
本文分别从客户端和集群的视角,介绍了Transwarp Scope的查询的基本流程、基本原理、实现方式以及不同类型分区对查询速度带来的优化。
以上是关于星环科技分布式搜索引擎 Transwarp Scope 查询优化技术解读的主要内容,如果未能解决你的问题,请参考以下文章
星环 KunDB 2.2 发布,为高并发事务与查询混合的业务系统提供一个新选择