如何优雅地使用python采集阿里巴巴百万商户信息
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何优雅地使用python采集阿里巴巴百万商户信息相关的知识,希望对你有一定的参考价值。
参考技术A Sublime是一款轻量文本编辑工具,可以用来快速编写python脚本,这里就不多作介绍,详情自己百度。本期所需的工具包是selenium,用户需要自行安装,可以通过pip命令快速安装selenium,如下:因为本人先前已经成功安装selenium,所以这里提示“已经安装成功”,当然要使用pip命令,必须提前安装pip,自行百度,用户安装完上面的所有工具后我们就可以开始本期的装逼之旅了。
第一步、查看www.1688.com网页,确定抓取范围。我们打开阿里巴巴采购首页,我们发现阿里巴巴提供了厂商的搜索接口,如下所示:
第二步、我们试着搜索“化工”,查看得到的结果,如下:
第三步、我们可以看到,我们要的基本信息都存在了,但是联系方式没有,我们任意打开一个厂商的页面,可以看到“联系”这个导航栏项目,点击联系,就可以看到厂商的联系方式,我们在将注意力放到网址url上,我们可以看到,联系这个页面的URL呈现规律性,如www.xxx.1688.com/page/contactinfo.htm,并且联系电话的位置是最前的,这极大地方便了我们采集我们想要的信息,如下:
第四步、啰嗦了那么多,直接开始我们的代码:
首先使用python的selenium包打开一个Firefox浏览器窗口:
1
2
3
4
5
6
7
8
9
#! /usr/bin/env python
#coding:utf-8
from selenium import webdriver
import sys
# 解决中文报错的问题
reload(sys)
sys.setdefaultencoding('utf-8')
driver = webdriver.Firefox()
以上程序就可以打开Firefox浏览器窗口,并且打开的浏览器窗口对象为driver,接下来我们模拟登录,找到阿里巴巴模拟登录的地址为,我们通这个地址模拟登录,并通过selenium的find_element_by_name方法获取网页中的DOM节点,有学过javascript的同学应该就会了解DOM节点,具体的代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
url = '
k.635.1998096057.d1'
loginUrl = 't=true&redirect_url=
3Dlogin_target_is_blank_1688%26tracelog%3Dmember_signout_signin_s_reg'
driver = webdriver.Firefox()
time.sleep(3)
driver.get(loginUrl)
time.sleep(5)
driver.find_element_by_name("TPL_username").send_keys('这里是你的淘宝账号')
driver.find_element_by_name("TPL_password").send_keys('这里是你的淘宝密码')
driver.find_element_by_name("TPL_password").send_keys(Keys.ENTER)
time.sleep(5)
driver.get(url)
模拟登录成功后我们让页面自动跳转到我们刚才搜索“化工”厂商的那个页面,其中使用了time包里的sleep函数,是为了防止在网速较差的时候,网页加载速度较慢,源码还未下载完毕就执行查找节点的命令导致程序运行失败。接下来我们要做的是查找厂商的主页并找到其联系方式,并且发现厂商找到的结果共有100页,在这里,为了使用方便,我们直接使用for循环来模拟点击下一页进行采集。具体的所有源代码如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
#! /usr/bin/env python
#coding:utf-8
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
import time
import urllib
import urllib2
import sys
import os
import re
import csv
import numpy as np
# 解决中文报错的问题
reload(sys)
sys.setdefaultencoding('utf-8')
csvfile = file('data.csv', 'wb')
writer = csv.writer(csvfile)
writer.writerow((u'企业名称'.encode('gbk'), u'主页'.encode('gbk'), u'产品'.encode('gbk')
, u'联系人'.encode('gbk'), u'电话'.encode('gbk'), u'地址'.encode('gbk')))
url = '
635.1998096057.d1'
loginUrl = '
full_redirect=true&redirect_url=
_is_blank_1688%26tracelog%3Dmember_signout_signin_s_reg'
driver = webdriver.Firefox()
time.sleep(3)
driver.get(loginUrl)
time.sleep(5)
driver.find_element_by_name("TPL_username").send_keys('这里输入你的淘宝账号')
driver.find_element_by_name("TPL_password").send_keys('这里输入你的淘宝密码')
driver.find_element_by_name("TPL_password").send_keys(Keys.ENTER)
time.sleep(5)
driver.get(url)
time.sleep(15)
user_agents = [
'Mozilla/5.0 (Windows; U; Windows NT 5.1; it; rv:1.8.1.11) Gecko/20071127 Firefox/2.
0.0.11',
'Opera/9.25 (Windows NT 5.1; U; en)',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR
2.0.50727)',
'Mozilla/5.0 (compatible; Konqueror/3.5; Linux) Khtml/3.5.5 (like Gecko) (Kubuntu)',
'Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.8.0.12) Gecko/20070731 Ubuntu/dapper-se
curity Firefox/1.5.0.12',
'Lynx/2.8.5rel.1 libwww-FM/2.14 SSL-MM/1.4.1 GNUTLS/1.2.9',
"Mozilla/5.0 (X11; Linux i686) AppleWebKit/535.7 (KHTML, like Gecko) Ubuntu/11.04 Chr
omium/16.0.912.77 Chrome/16.0.912.77 Safari/535.7",
"Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:10.0) Gecko/20100101 Firefox/10.0 ",
]
for page in xrange(1, 100):
try:
title = driver.find_elements_by_css_selector("a[class=list-item-title-text]")
product = driver.find_elements_by_xpath("//div[@class=\"list-item-detail\"]/div[1]
/div[1]/a[1]")
print len(title)
pattern = re.compile('<div class="contcat-desc".*?>(.*?)</div>', re.S)
telPattern = re.compile('<dd>(.*?)</dd>', re.S)
membernamePattern = re.compile('<a.*?class="membername".*?>(.*?)</a>', re.S)
addressPattern = re.compile('"address">(.*?)</dd>', re.S)
for i in xrange(len(title)):
titleValue = title[i].get_attribute('title')
hrefValue = title[i].get_attribute('href') + 'page/contactinfo.htm'
productValue = product[i].text
agent = np.random.choice(user_agents)
headers = 'User-Agent' : agent, 'Accept' : '*/*', 'Referer' : ''
request = urllib2.Request(hrefValue, headers=headers)
response = urllib2.urlopen(request)
html = response.read()
info = re.findall(pattern, html)
try:
info = info[0]
except Exception, e:
continue
tel = re.findall(telPattern, info)
try:
tel = tel[0]
tel = tel.strip()
tel = tel.replace(' ', '-')
except Exception, e:
continue
membername = re.findall(membernamePattern, html)
try:
membername = membername[0]
membername = membername.strip()
except Exception, e:
continue
address = re.findall(addressPattern, html)
try:
address = address[0]
address = address.strip()
except Exception, e:
address = ''
print 'tel:' + tel
print 'membername:' + membername
data = (titleValue.encode('gbk', 'ignore'), title[i].get_attribute('href'), pr
oductValue.encode('gbk', 'ignore'), membername, tel, address)
writer.writerow(data)
for t in title:
print t.get_attribute('title')
print t.get_attribute('href') + 'page/contactinfo.htm'
print len(product)
for p in product:
a = repr(p.text)
a = a.encode('gbk', 'ignore')
print a
print '#' * 50
js = 'var q=document.documentElement.scrollTop=30000'
driver.execute_script(js)
time.sleep(2)
page = driver.find_elements_by_css_selector("a[class=page-next]")
page = page[0]
page.click()
time.sleep(10)
except Exception, e:
print 'error'
continue
csvfile.close()
driver.close()
图片获取太麻烦?python爬虫实战:百度百万级图片采集
项目分析
效果展示
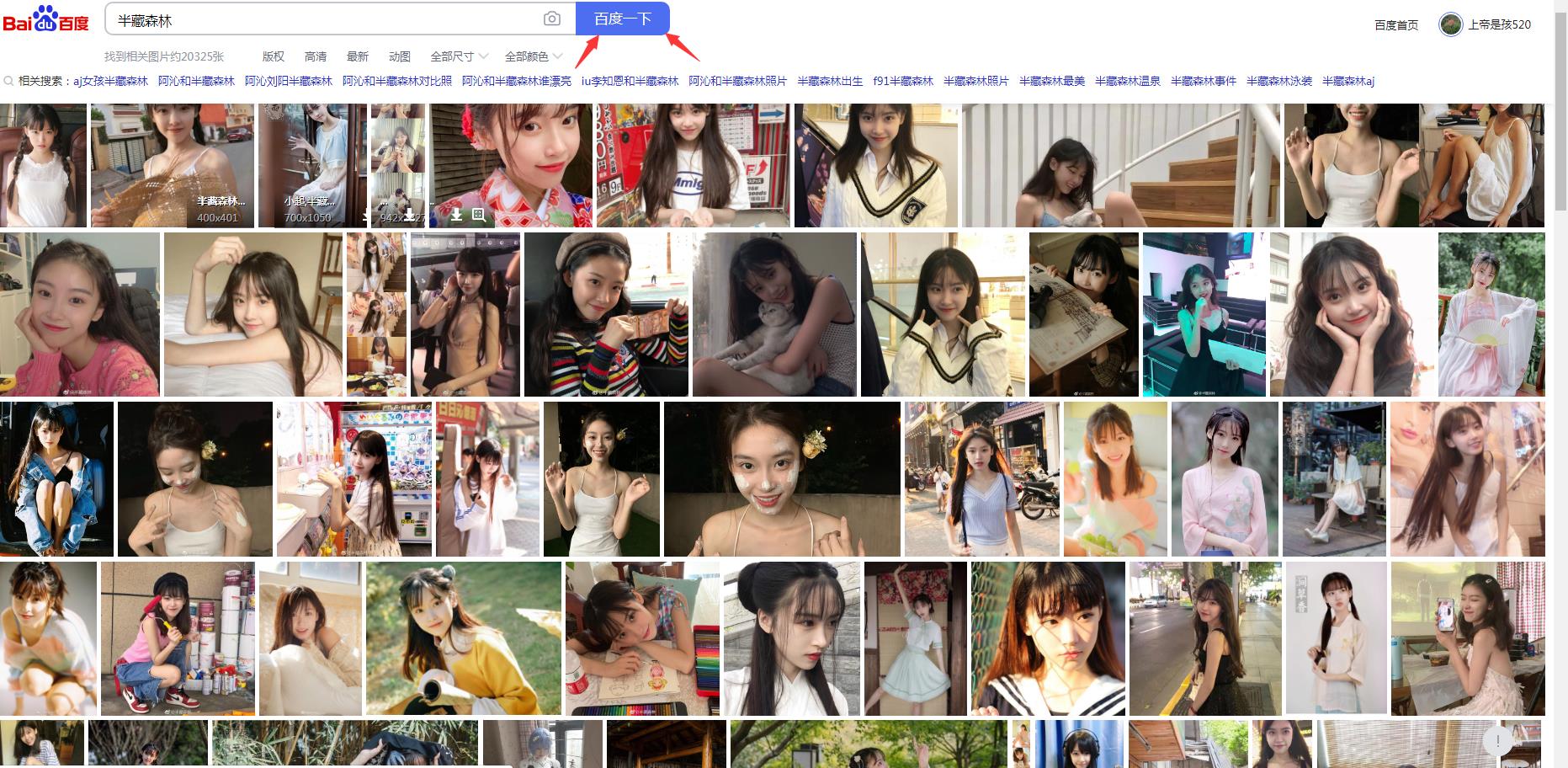
开发工具
开发环境: Python3.7 + win10
开发工具: pycharm + chrome
主要内容:
1.获取网址数据
2.正则提取数据
3.保存表格数据
项目解析
找到图片的动态数据接口
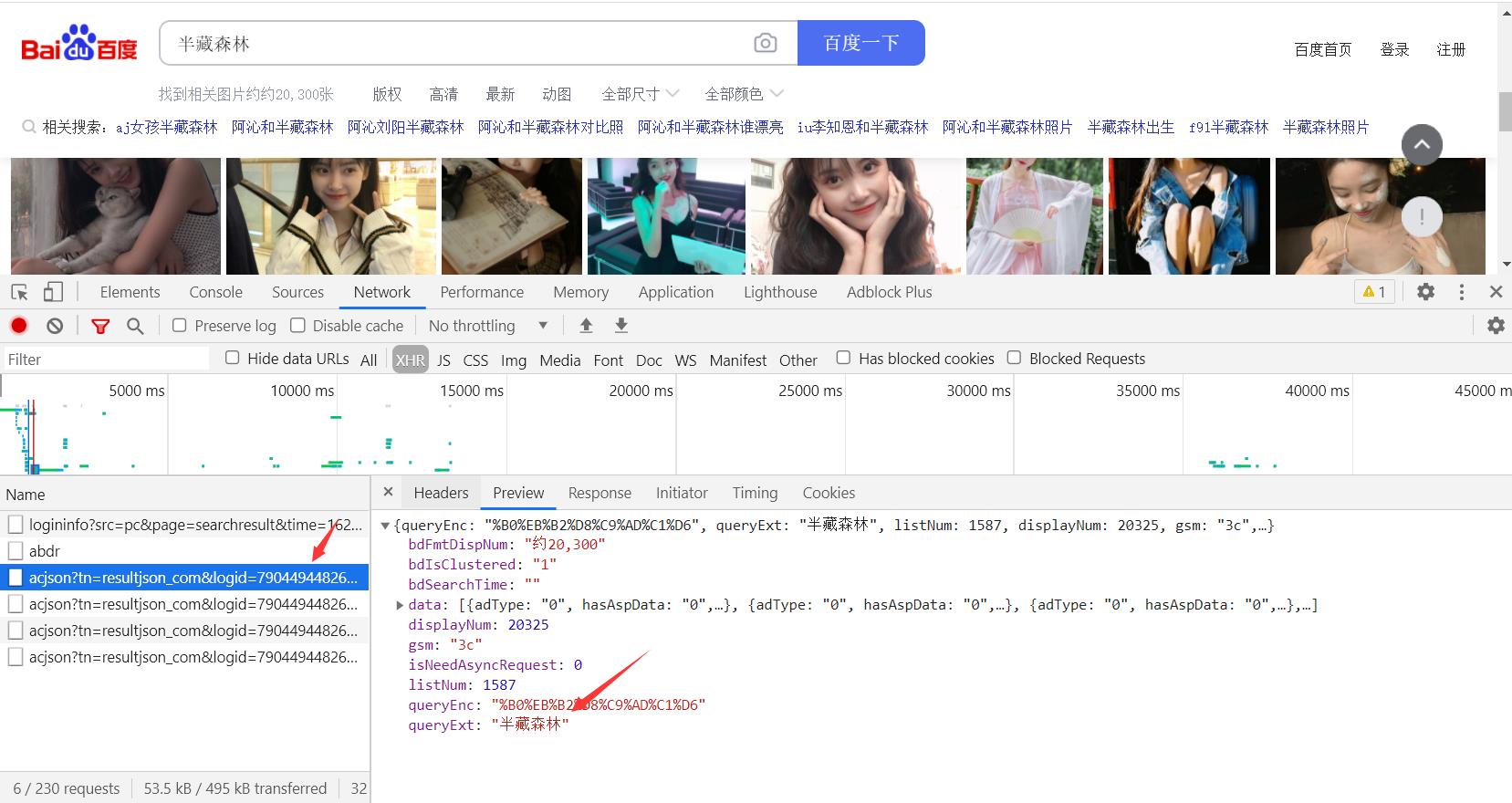
找到图片的url地址

请求当前动态的接口网址
提取图片的网址信息
再次对图片网址发送请求
保存数据
源码展示
import requests # 导入请求的工具包
import re # 正则匹配工具包
# 添加请求头
headers = {
# cookie信息
"Cookie": "BDqhfp=%E6%98%8E%E6%98%9F%E5%8D%95%E4%BA%BA%E7%85%A7%26%260-10-1undefined%26%261132%26%263; PSTM=1606885275; BAIDUID=D9B7A2A3C7555B9A30BC448DE032D13B:FG=1; BIDUPSID=5EEB8A912FC8FDCB0C187D519FABA455; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; BDSFRCVID=RxtOJeC62CaLjt3rvnJAhLqAYfS_AG3TH6ao5bUjY3stbaPxsXJ7EG0P8f8g0KubzcDrogKKLmOTHpKF_2uxOjjg8UtVJeC6EG0Ptf8g0f5; H_BDCLCKID_SF=tJPD_CLKtDI3fP36qRQtbt00qxby26nfa6T9aJ5nJDoNqIopb5bK54CkXM7rbxok3gQ3Lqo8QpP-HJ7zbxRqQhkD3NQXJU3p2erEKl0MLU7tbb0xynoDMbtNMfnMBMnramOnaPJc3fAKftnOM46JehL3346-35543bRTLnLy5KJYMDF4jj-hj5QLjaRf-b-X2CjyWb88Kb7VbUo95MnkbfJBD4bKWPTJt5rqWqcp2pRaEfTI0pnNQTt7yajK25QaQCQko-O2KJjmJ-Oyy6JpQT8reMDOK5OibCrE3hb-ab3vOpRzXpO1KMPzBN5thURB2DkO-4bCWJ5TMl5jDh3Mb6ksDMDtqtJHKbDDVILMJMK; BDUSS=g5U3pnMlhCRWJWT1lYQzR3SVBuSUN0MUNkWERaSDJHV2xKN3NHUDJzMFhGZTlmRUFBQUFBJCQAAAAAAAAAAAEAAAAIs6iyAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABeIx18XiMdfRE; BDUSS_BFESS=g5U3pnMlhCRWJWT1lYQzR3SVBuSUN0MUNkWERaSDJHV2xKN3NHUDJzMFhGZTlmRUFBQUFBJCQAAAAAAAAAAAEAAAAIs6iyAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABeIx18XiMdfRE; delPer=0; PSINO=6; __yjsv5_shitong=1.0_7_65901da49a5a59037e920cbd2020d5073dda_300_1606918958343_113.240.215.138_cdf8224b; H_PS_PSSID=1468_32855_33059_33098_33100_33199_33147_22160; BA_HECTOR=20050k2gakah8100r71fsguaf0q; BDRCVFR[X_XKQks0S63]=mk3SLVN4HKm; firstShowTip=1; cleanHistoryStatus=0; BDRCVFR[dG2JNJb_ajR]=mk3SLVN4HKm; userFrom=tupian.baidu.com; BDRCVFR[-pGxjrCMryR]=mk3SLVN4HKm; indexPageSugList=%5B%22%E6%98%8E%E6%98%9F%E5%8D%95%E4%BA%BA%E7%85%A7%22%2C%22%E6%98%8E%E6%98%9F%22%5D",
# 用户代理
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36",
# 请求数据来源
"Referer": "https://tupian.baidu.com/search/index",
"Host": "tupian.baidu.com"
}
key = input("请输入要下载的图片:")
# 保存图片的地址
path = r"E:\\\\python_project\\\\vip_course\\\\百度图片\\\\图片\\\\"
# 请求数据接口
for i in range(5, 50):
url = "https://tupian.baidu.com/search/acjson?tn=resultjson_com&logid=11528842549528169565&ipn=rj&ct=201326592&is=&fp=result&queryWord={}&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&hd=&latest=©right=&word={}&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&pn={}&rn=30&gsm=78&1606974013784=".format(key, key, i*30)
# 发送请求
response = requests.get(url, headers=headers)
# 正则匹配数据
url_list = re.findall('"thumbURL":"(.*?)",', response.text)
print(url_list)
# 循环取出图片url 和 name
for new_url in url_list:
# 再次对图片发送请求
result = requests.get(new_url).content
# 分割网址获取图片名字
name = new_url.split("/")[-1]
print(name)
# 写入文件
with open(path + name, "wb")as f:
f.write(result)
①3000多本Python电子书有
②Python开发环境安装教程有
③Python400集自学视频有
④软件开发常用词汇有
⑤Python学习路线图有
⑥项目源码案例分享有
如果你用得到的话可以直接拿走,在我的QQ技术交流群里(纯技术交流和资源共享,广告勿入)可以自助拿走,群号是764406565。
以上是关于如何优雅地使用python采集阿里巴巴百万商户信息的主要内容,如果未能解决你的问题,请参考以下文章