hadoop集群防止磁盘损坏导致block丢失的解决方案
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop集群防止磁盘损坏导致block丢失的解决方案相关的知识,希望对你有一定的参考价值。
参考技术A 原理: 数据冗余方案实质上是通过增加block数据副本数来防止block丢失,通过牺牲存储来保证数据安全。本方案主要针对于解决异常情况一。hadoop集群目前默认设置的数据副本数为3,也就是说最多能同时容忍不同主机的二块盘出现损坏,当出现不同主机三块盘同时损坏时,就可能出现block丢失情况。方法:
(1)hadoop 集群动态设置 block 副本:
将/user文件夹下的数据设置5个副本:
(2)hadoop 集群整体提高 block 副本数方法:
通过ambari修改hdfs配置文件:
可以修改为5,则设置集群数据副本数为5.
保存并重启hdfs生效。
注:这样即使三台主机的磁盘出现损坏,这个文件夹的数据也不会丢。除非同时五台主机的磁盘出现损坏,这个文件夹下的数据才可能丢失。
原理: 当一个主机的磁盘出现损坏时,集群会立刻对这块盘上的数据通过副本机制恢复到其它主机上。磁盘存储数据量越大,恢复时间会随之增长。我们通过优化hadoop集群的副本恢复参数来提升它的副本恢复速度,从而整体缩短副本恢复时间。本方案主要针对于解决异常情况二,防止出现数据恢复过程中的数据丢失。
方法:
通过ambari添加如下参数:
通过ambari保存配置并重启hdfs服务即可。
原理:hadoop 集群配置机架感知后,同一机架内的所有主机只存储block数据的1~2个副本,总会有一个副本在其它机架。当同一机架内多个主机出现坏盘情况时,至少还有一个block副本可以提供访问和恢复,不会出现block数据丢失情况。
方法:
hadoop集群本身自带机架感知功能,在集群部署是没有使用的话,那么集群所有主机默认在一个机架下: /default-rack
可以通过ambari添加机架感知功能,具体操作如下(两种方法,选其中一个即可):
单个主机设置:
批量设置:
2. 设置完成后,需要重启hdfs 、mapreduce。
3.查看机架命令:
raid-6磁盘阵列损坏导致数据丢失的恢复过程(图文教程)
一、故障描述
机房突然断电导致整个存储瘫痪,加电后存储依然无法使用。经过用户方工程师诊断后认为是断电导致存储阵列损坏。
整个存储是由12块日立硬盘(3T SAS硬盘)组成的RAID-6磁盘阵列,被分成一个卷,分配给几台Vmware的ESXI主机做共享存储。整个卷中存放了大量的Windows虚拟机,虚拟机基本都是模板创建的,因此系统盘都统一为160G。数据盘大小不确定,并且数据盘都是精简模式。
二、备份数据
将故障存储的所有磁盘和备份sss数据的目标磁盘连入到一台Windows Server 2008的服务器上。故障磁盘都设为脱机(只读)状态,在专业工具WinHex下看到连接状态如下图所示:(图中HD1-HD12为目标备份磁盘,HD13-HD24为源故障磁盘,型号为HUS723030ALS640):
图一: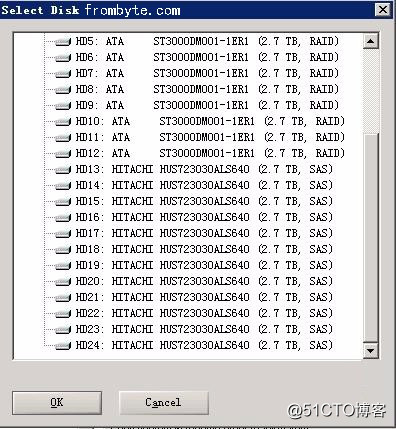
使用WinHex 对HD13-HD24以底层方式读取扇区,发现了大量损坏扇区。初步判断可能是这种硬盘的读取机制与常见的硬盘不一样。尝试更换操作主机,更换HBA卡,更换扩展柜,更换为Linux操作系统,均呈现相同故障。与用户方工程师联系,对方回应此控制器对磁盘没有特殊要求。
使用专业工具对硬盘损坏扇区的分布规律进行检测,发现如下规则:
1、损坏扇区分布以256个扇区为单位。
2、除损坏扇区片断的起始位置不固定外,后面的损坏扇区都是以2816个扇区为间隔。
所有磁盘的损坏扇区分布如下表(只列出前3个损坏扇区):
ID号 硬盘序列号 第1个损坏扇区 第2个损坏扇区 第3个损坏扇区
13 YHJ7L3DD 5376 8192 11008
14 YHJ6YW9D 2304 5120 7936
15 YHJ7M77D 2048 4864 7680
16 YHJ4M5AD 1792 4608 7424
17 YHJ4MERD 1536 4352 7168
18 YHJ4MH9D 1280 6912 9728
19 YHJ7JYYD 1024 6656 9472
20 YHJ4MHMD 768 6400 9216
21 YHJ7M4YD 512 6144 8960
22 YHJ632UD 256 5888 8704
23 YHJ6LEUD 5632 8448 11264
24 YHHLDLRA 256 5888 8704
临时写了个小程序,对每个磁盘的损坏扇区做绕过处理。用此程序镜像完所有盘的数据。
三、故障分析
1、分析损坏扇区
仔细分析损坏扇区发现,损坏扇区呈规律性出现。
-每段损坏扇区区域大小总为256。
-损坏扇区分布为固定区域,每跳过11个256扇区遇到一个坏的256扇区。
-损坏扇区的位置一直存在于RAID的P校验或Q校验区域。
-所有硬盘中只有10号盘中有一个自然坏道。
2、分析分区大小
对HD13、HD23、HD24的0-2扇区做分析,可知分区大小为52735352798扇区,此大小按RAID-6的模式计算,除以9,等于5859483644扇区,与物理硬盘大小1049524,和DS800控制器中保留的RAID信息区域大小吻合;同时根据物理硬盘底层表现,分区表大小为512字节,后面无8字节校验,大量的0扇区也无8字节校验。故可知,原存储并未启用存储中常用的DA技术(520字节扇区)。
分区大小如下图(GPT分区表项底层表现,涂色部分表示分区大小,单位512字节扇区,64bit):
图二: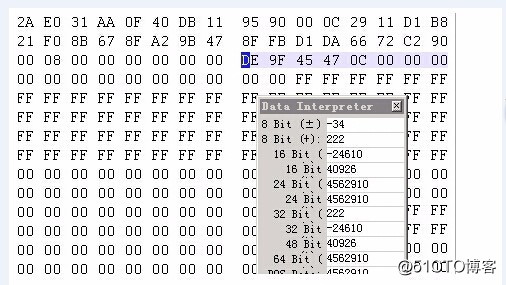
四、重组RAID
1、分析RAID结构
存储使用的是标准的RAID-6阵列,接下来只需要分析出RAID 成员数量以及RAID的走向就可以重组RAID。
-分析RAID条带大小
整个存储被分成一个大的卷,分配给几台ESXI做共享存储,因此卷的文件系统肯定是VMFS文件系统。而VMFS卷中又有存放了大量的Windows 虚拟机。Windows虚拟机中大多使用的是NTFS文件系统,因此可以根据NTFS中的MFT的顺序分析出RAID条带的大小以及RAID的走向。
-分析RAID是否存在掉线盘
镜像完所有磁盘。后发现最后一块硬盘中并没有像其他硬盘一样有大量的坏道。其中有大量未损坏扇区,这些未损坏扇区大多是全0扇区。因此可以判断这块硬盘是热备盘。
2、重组RAID
根据分析出来的RAID结构重组RAID,能看到目录结构。但是不确定是否为最新状态,检测几个虚拟机发现有部分虚拟机正常,但也有很多虚拟机数据异常。初步判断RAID中存在掉线的磁盘,依次将RAID中的每一块磁盘踢掉,然后查看刚才数据异常的地方,未果。又仔细分析底层数据发现问题不是出在RAID层面,而是出在VMFS文件系统上。VMFS文件系统如果大于16TB的话会存在一些其他的记录信息,因此在组建RAID的时候需要跳过这些记录信息。再次重组RAID,查看以前数据异常的地方可以对上了。针对其中的一台虚拟机做验证,将所有磁盘加入RIAD中后,这台虚拟机是可以启动的,但缺盘的情况下启动有问题。因此判断整个RAID处在不缺盘的状态为最佳。
五、验证数据
1、验证虚拟机
针对用户较为重要的虚拟机做验证,发现虚拟机大多都可以开机,可以进入登陆界面。有部分虚拟机开机蓝屏或开机检测磁盘,但是光盘修复之后都可以启动。
部分虚拟机现象开机如下:
图三:
2、验证数据库
针对重要的虚拟机中的数据库做验证,发现数据库都正常。其中有一个数据库,据用户描述是缺少部分数据,但是经过仔细核对后发现这些数据在数据库中本来就不存在。通过查询 master 数据库中的系统视图,查出原来的所有数据库信息如下:
图四: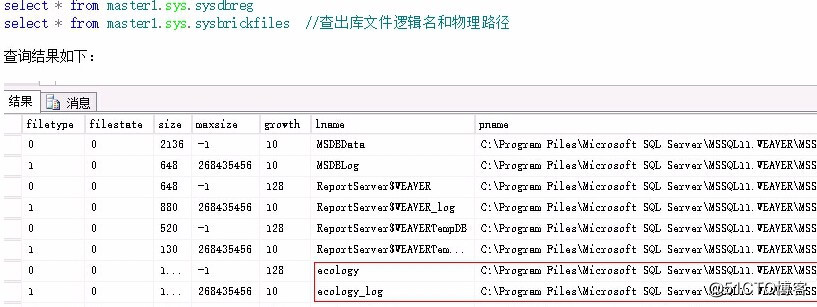
3、检测整个VMFS卷是否完整
由于虚拟机的数量很多,每台都验证的话,所需的时间会很长,因此我们对整个VMFS卷做检测。在检测VMFS卷的过程中发现有部分虚拟机或虚拟机的文件被破坏。列表如下:
图五: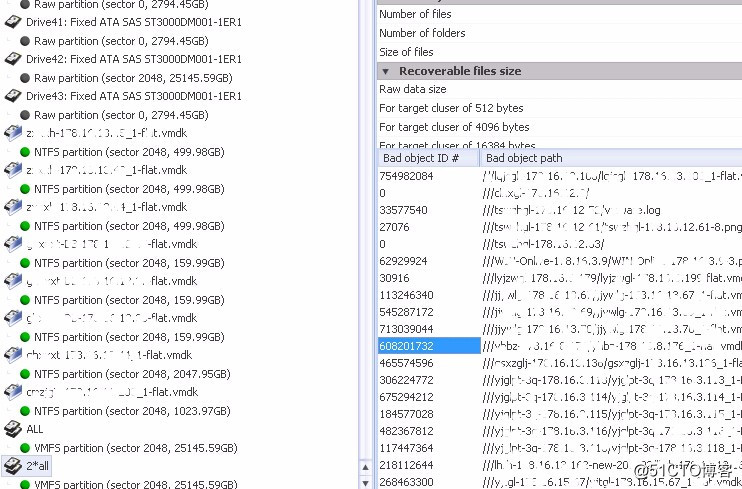
六、恢复数据
1、生成数据
北亚工程师跟客户沟通并且描述了目前恢复的情况。用户经过对几台重要的虚拟机验证后,用户反应恢复的数据可以接受,接着北亚工程师立即着手准备恢复所有数据。
先准备目标磁盘,使用一台dell 的MD 1200加上11块3T的硬盘组成一个RAID阵列。接着将重组的RAID数据镜像到目标阵列上。然后利用专业的工具UFS解析整个VMFS文件系统。
2、尝试挂载恢复的VMFS卷
将恢复好的VMFS卷连接到我们的虚拟化环境中的一台ESXI5.5主机上,尝试将其挂载到的ESXI5.5的环境中。但是由于版本(客户的ESXI主机是5.0版本)原因或VMFS本身有损坏,导致其挂载不成功。继续尝试使用ESXI的命令挂载也不成功,于是放弃挂载VMFS卷。
七、移交数据
由于时间紧迫,先安排北亚工程师将MD 1200 阵列上的数据带到用户现场。然后使用专业工具”UFS”依次导出VMFS卷中的虚拟机。
1、将MD 1200阵列上的数据通过HBA卡连接到用户的VCenter服务器上。
2、在VCenter服务器安装“UFS”工具,然后使用“UFS”工具解释VMFS卷。
3、使用“UFS”工具将VMFS卷中的虚拟机导入到VCenter服务器上。
4、使用VCenter的上传功能将虚拟机上传到ESXI的存储中。
5、接着将上传完的虚拟机添加到清单,开机验证即可。
6、如果有虚拟机开机有问题,则尝试使用命令行模式修复。或者重建虚拟机并将恢复的虚拟机磁盘(既VMDK文件)拷贝过去。
7、由于部分虚拟机的数据盘很大,而数据很少。像这种情况就可以直接导出数据,然后新建一个虚拟磁盘,最后将导出的数据拷贝至新建的虚拟磁盘中即可。
统计了一下整个存储中虚拟机的数量,大约有200台虚拟机。目前的情况只能通过上述方式将恢复的虚拟机一台一台的恢复到用户的ESXI中。由于是通过网络传输,因此整个迁移的过程中网络是一个瓶颈。经过不断的调试以及更换主机最终还是无法达到一个理想的状态,由于时间紧张,最终还是决定在当前的环境迁移数据。
八、数据恢复总结
1、故障总结
所有磁盘坏道的规律如下表: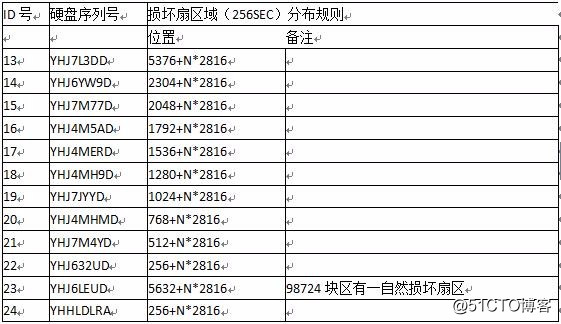
经过仔细分析后得出坏道的结论如下:
-除去SN:YHJ6LEUD上的一个自然坏道外,其余坏道均分布于RAID-6的Q校验块中。
-坏道区域多数表现为完整的256个扇区,正好当时创建RAID-6时的一个完整RAID块大小。
-活动区域表现为坏道,非活动区域坏道有可能不出现,如热备盘,上线不足10%,坏道数量就比其他在线盘少(热备盘的镜像4小时完成,其他有坏道盘大概花费40小时)
-其他非Q校验区域完好,无任何故障。
结论:
通常情况,经如上坏道规则表现可推断,坏道为控制器生成Q校验,向硬盘下达IO指令时,可能表现为非标指令,硬盘内部处理异常,导致出现规律性坏道。
2、数据恢复总结
数据恢复过程中由于坏道数量太多,以致备份数据时花费了很长世间。整个存储是由坏道引起的,导致最终恢复的数据有部分破坏,但不影响整体数据,最终的结果也在可接受范围内。
整个恢复过程,用户方要求紧急,我方也安排工程师加班加点,最终在最短的时间内将数据恢复出来。后续的数据迁移过程中由我方工程师和用户方工程师配合完成。
九、项目成员?
以上是关于hadoop集群防止磁盘损坏导致block丢失的解决方案的主要内容,如果未能解决你的问题,请参考以下文章
可以将hadoop从节点设为hadoop主节点而不会导致数据丢失
Hadoop集群安全模式退出失败问题处理,Safe mode is ON。hdfs dfsadmin -safemode leave 或 forceExit
重启集群造成块丢失问题org.apache.hadoop.hdfs.CannotObtainBlockLengthException: Cannot obtain block length for L
重启集群造成块丢失问题org.apache.hadoop.hdfs.CannotObtainBlockLengthException: Cannot obtain block length for L