互联网如何海量存储数据?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了互联网如何海量存储数据?相关的知识,希望对你有一定的参考价值。
参考技术A 目前存储海量数据的技术主要包括NoSQL、分布式文件系统、和传统关系型数据库。随着互联网行业不断的发展,产生的数据量越来越多,并且这些数据的特点是半结构化和非结构化,数据很可能是不精确的,易变的。这样传统关系型数据库就无法发挥它的优势。因此,目前互联网行业偏向于使用NoSQL和分布式文件系统来存储海量数据。下面介绍下常用的NoSQL和分布式文件系统。
NoSQL
互联网行业常用的NoSQL有:HBase、MongoDB、Couchbase、LevelDB。
HBase是Apache Hadoop的子项目,理论依据为Google论文 Bigtable: A Distributed Storage System for Structured Data开发的。HBase适合存储半结构化或非结构化的数据。HBase的数据模型是稀疏的、分布式的、持久稳固的多维map。HBase也有行和列的概念,这是与RDBMS相同的地方,但却又不同。HBase底层采用HDFS作为文件系统,具有高可靠性、高性能。
MongoDB是一种支持高性能数据存储的开源文档型数据库。支持嵌入式数据模型以减少对数据库系统的I/O、利用索引实现快速查询,并且嵌入式文档和集合也支持索引,它复制能力被称作复制集(replica set),提供了自动的故障迁移和数据冗余。MongoDB的分片策略将数据分布在服务器集群上。
Couchbase这种NoSQL有三个重要的组件:Couchbase服务器、Couchbase Gateway、Couchbase Lite。Couchbase服务器,支持横向扩展,面向文档的数据库,支持键值操作,类似于SQL查询和内置的全文搜索;Couchbase Gateway提供了用于RESTful和流式访问数据的应用层API。Couchbase Lite是一款面向移动设备和“边缘”系统的嵌入式数据库。Couchbase支持千万级海量数据存储
分布式文件系统
如果针对单个大文件,譬如超过100MB的文件,使用NoSQL存储就不适当了。使用分布式文件系统的优势在于,分布式文件系统隔离底层数据存储和分布的细节,展示给用户的是一个统一的逻辑视图。常用的分布式文件系统有Google File System、HDFS、MooseFS、Ceph、GlusterFS、Lustre等。
相比过去打电话、发短信、用彩铃的“老三样”,移动互联网的发展使得人们可以随时随地通过刷微博、看视频、微信聊天、浏览网页、地图导航、网上购物、外卖订餐等,这些业务的海量数据都构建在大规模网络云资源池之上。当14亿中国人把衣食住行搬上移动互联网的同时,也给网络云资源池带来巨大业务挑战。
首先,用户需求动态变化,传统业务流量主要是端到端模式,较为稳定;而互联网流量易受热点内容牵引,数据流量流向复杂和规模多变:比如双十一购物狂潮,电商平台订单创建峰值达到58.3万笔,要求通信网络提供高并发支持;又如优酷春节期间有超过23亿人次上网刷剧、抖音拜年短视频增长超10倍,需要通信网络能够灵活扩充带宽。面对用户动态多变的需求,通信网络需要具备快速洞察和响应用户需求的能力,提供高效、弹性、智能的数据服务。
“随着通信网络管道十倍百倍加粗、节点数从千万级逐渐跃升至百亿千亿级,如何‘接得住、存得下’海量数据,成为网络云资源池建设面临的巨大考验”,李辉表示。一直以来,作为新数据存储首倡者和引领者,浪潮存储携手通信行业用户,不断 探索 提速通信网络云基础设施的各种姿势。
早在2018年,浪潮存储就参与了通信行业基础设施建设,四年内累计交付约5000套存储产品,涵盖全闪存储、高端存储、分布式存储等明星产品。其中在网络云建设中,浪潮存储已连续两年两次中标全球最大的NFV网络云项目,其中在网络云二期建设中,浪潮存储提供数千节点,为上层网元、应用提供高效数据服务。在最新的NFV三期项目中,浪潮存储也已中标。
能够与通信用户在网络云建设中多次握手,背后是浪潮存储的持续技术投入与创新。浪潮存储6年内投入超30亿研发经费,开发了业界首个“多合一”极简架构的浪潮并行融合存储系统。此存储系统能够统筹管理数千个节点,实现性能、容量线性扩展;同时基于浪潮iTurbo智能加速引擎的智能IO均衡、智能资源调度、智能元数据管理等功能,与自研NVMe SSD闪存盘进行系统级别联调优化,让百万级IO均衡落盘且路径更短,将存储系统性能发挥到极致。
“为了确保全球最大规模的网络云正常上线运行,我们联合用户对存储集群展开了长达数月的魔鬼测试”,浪潮存储工程师表示。网络云的IO以虚拟机数据和上层应用数据为主,浪潮按照每个存储集群支持15000台虚机进行配置,分别对单卷随机读写、顺序写、混合读写以及全系统随机读写的IO、带宽、时延等指标进行了360无死角测试,达到了通信用户提出的单卷、系统性能不低于4万和12万IOPS、时延小于3ms的要求,产品成熟度得到了验证。
以通信行业为例,2020年全国移动互联网接入流量1656亿GB,相当于中国14亿人每人消耗118GB数据;其中春节期间,移动互联网更是创下7天消耗36亿GB数据流量的记录,还“捎带”打了548亿分钟电话、发送212亿条短信……海量实时数据洪流,在网络云资源池(NFV)支撑下收放自如,其中分布式存储平台发挥了作用。如此样板工程,其巨大示范及拉动作用不言而喻。
分布式存储主导未来海量数据存储市场
摘要
近日,“众视Tech-VideoX学院”技术公益课开办【与“云”相辅相成,拥抱分布式存储新时代】专题公开课,特邀天茹1475王青水,蝶链科技顾问树哥,焜耀科技(原力区)品牌商务总监柏礼来为大家分享分布式存储的技术思考和发展趋势。
1
分布式存储如何挑战传统互联网巨头
蝶链 科技顾问
树哥
传统互联网带来的问题
传统互联网巨头几乎已经延伸到了我们生活的方方面面,影响力巨大的同时,也逐渐暴露出三大问题:
隐私保护 如个人隐私信息泄露、滥用,APP过度授权,AI换脸对于人脸识别的干扰等问题;
数据海啸 2025年全球数据总量将达到175ZB,而未来随着自动驾驶、物联网、智慧城市、超高清音视频、人工智能的普及,全球数据将会呈几何爆发式增长,传统的存储模式无法承载;
数据孤岛 传统互联网行业马太效应的加剧,各大厂商之间形成数据壁垒,不利于数据的流通使用。
分布式存储的巨大优势
传统互联网模式,数据的流通绕不开中心节点,这也是导致数据割裂的根本原因;分布式存储,任意节点之间都是互相连接的,使得数据可以在全球范围内流动。
这种流通带来的最大意义有两点:
任何人都可以用最低的代价,将数据分发到全球网络;
对于初创企业来说,使用分布式存储的起点都是面向全球的。
在一个变化如此快的世界里, 最大的风险就是不冒风险,在未来的5-20年内,分布式存储将会挑战传统架构,带来翻天覆地的变化。
2
数据是灵魂,存储是容器,网络是流动
TokenDAO Research Spring Fund,Why Lab发起人
王青水(Shawn Wang)
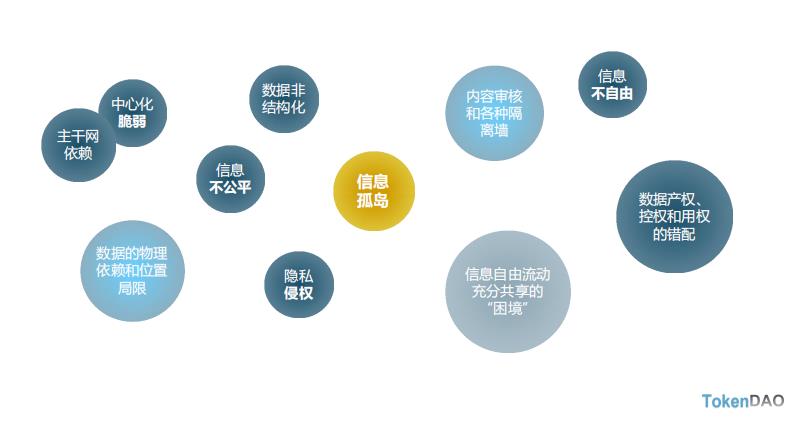
Web2.0存在的问题
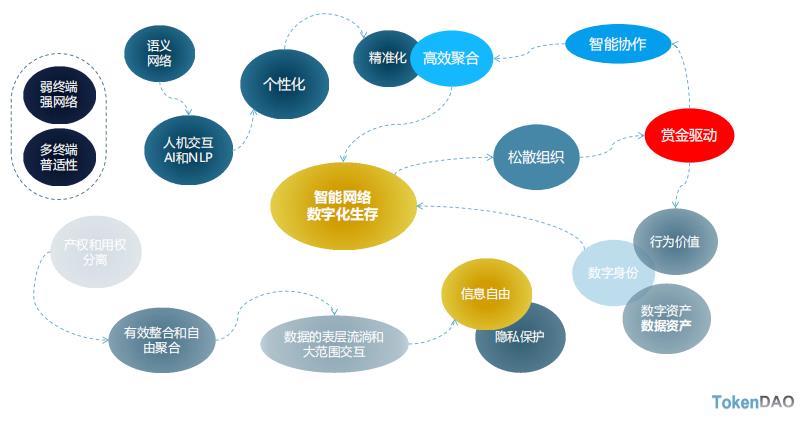
Web3.0的特征
WEB 3.0的发展阻碍
Web 3.0是互联网发展的新阶段,它将把互联网带入一个全新的发展水平,然而现阶段Web 3.0发展面临着诸多障碍,其中最为掣肘的是信息不能自由流通,不能充分共享。
信息不能自由流动(技术问题):基于IP物理主机和位置寻址,将数据内容和物理地理过度绑定,导致信息不能自由流动;IPFS基于内容寻址,解耦后的信息可以更加自由的流动、更加直接的处理;
信息不能充分共享(关系问题):数据的源头不能确权、数据的使用环节不能大范围交易;Filecoin价值符号、存储证明、智能合约等社会关系构件,让数据的确权、激励以及 大范围的非信任主体之间的交易得以实现。
IPFS+Filecoin的珠联璧合,有望成为Web3.0的基石和全新的基础网络设施!
区块链为什么没有应用落地
目前区块链只有虚拟货币的交易数据,没有现实世界的场景数据,任何信息产业的落地应用,都是以场景数据为前提,区块链没有解决非交易性数据的问题,因此想要落地应用非常困难。而IPFS和Filecoin的去中心存储系统,提供了场景数据的栖身之地,使得后续的落地应用成为可能。
IPFS+Filecoin带来的不止是存储和传输:
语义网络:IPFS资源自描述的设计,解决了数据结构兼容和数据可交互的问题
双重解耦:IPFS基于内容寻址,将数据的逻辑结构和存储传输的底层物理结构解耦,让数据摆脱物理和位置依赖,给数据插上了翅膀,便利化了数据的表层流淌和大范围交互(肉体和灵魂的关系);场景调用和数据产权解耦,行为→数据→价值
Filecoin激励层+IPFS协议层:前后相继、珠联璧合,打造的去中心存储网络,让数据产权和数据 调用的解耦成为可能,只有数据产权的回归和私有化,才能调动数据生产和数据共享的原动力;
加密确权和智能合约:解决了数据的确权、授权和交易的信任问题,才能调动陌生对手、异构数 据的大范围的数据共享,润滑了数据广泛流动的摩擦阻力(隐私保护和交易可靠)

公链、存储共享、基础设施、生态配套,四位一体、虚实兼备
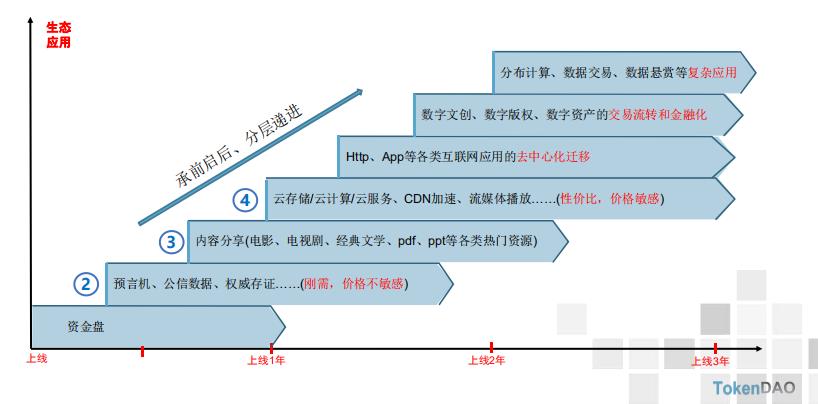
承前启后、分层递进
传统互联网带来的问题
Filecoin的发展目前还存在着一定的问题,导致Filecoin在问世三年后依然处于发展的初级阶段:其一,是不信任以及安全担忧带来的不安;其二,Seal封装的耗时很长;其三,在保障数据安全性和公信力的同时,成本随之水涨船高。
Filecoin今后的发展,需要Gas优化、Unseal算法优化,同时还依赖于:
有效数据和生态应用:海量场景和价值数据的导入,存储只是第一步,共享、交互→数据的确权和交易
转接桥:ETH和Polkadot的转接桥,信息和价值交互的打通→配套生态的完善
智能合约:链上的无抵押借贷、生态内含生息资产、Fil上的理财和投资→数据资产的分销、贸易和金融
随着各种场景数据的导入,存储生态也逐步出圈,迎来百花齐放的时代。
3
分布式存储助力新数据时代
焜耀科技(原力区) 品牌商务总监
柏礼
随着5G、物联网、数字化转型发展的脚步,我们逐渐迈入新数据时代。数据量庞大、数据存储类型和格式复杂、数据价值大、数据处理效率要求高是新数据时代的典型特征。
根据互联网世界统计(IWS)的统计数据显示,全球互联网用户数量将近47亿,占世界总人口的60%;互联网经济在G20的GDP占比达到5.5%,占美国GDP比重的10%。
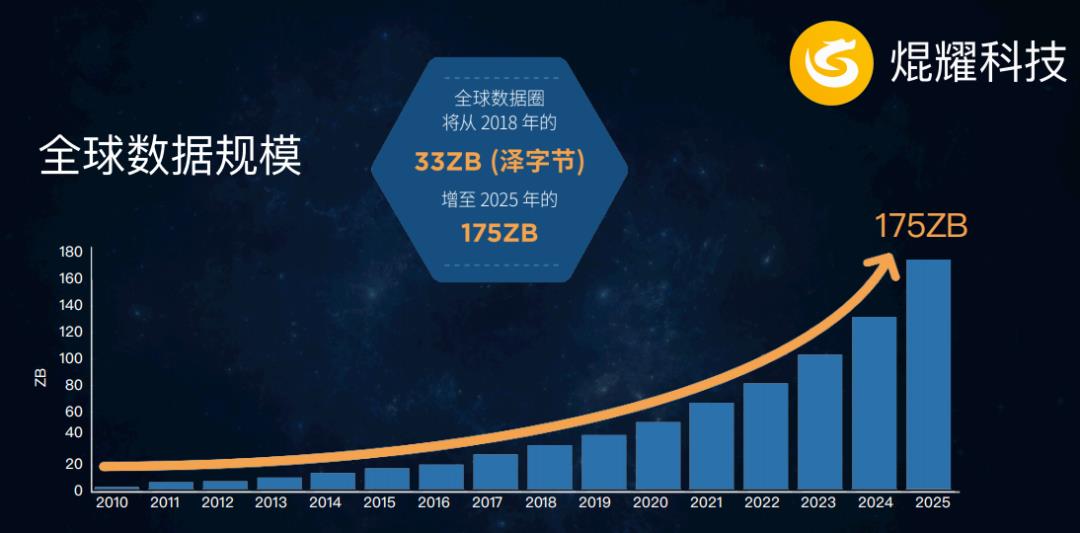
未来,4K/8K超高清视频、5G/物联网等智能设备暴增、自动驾驶的普及应用以及AI/大数据改变存储周期等,将带来海量的数据处理需求。围绕数据产生的诸如信任、所有权、交换共享、价值流通、隐私泄露、信息孤岛等一系列问题亟待解决。
在上述问题中,解决信任危机尤为紧迫,长期以来,在数据的使用上都存在隐私信息非法采集/兜售、隐私泄露、APP强制授权/过度授权、隐私信息不正当使用等问题,近期曝出了一系列大数据杀熟和用户数据泄露实践急剧加剧了网络用户的信任危机。
如何解决信任危机?区块链天然的去中心化属性和不可篡改性,以区块链为代表的分布式存储网络能够有效的应对这一问题。Filecoin是目前全球最大的分布式存储网络,它诞生的初心就是为了存储人类社会最重要的信息。

Filecoin数据

Filecoin技术支撑
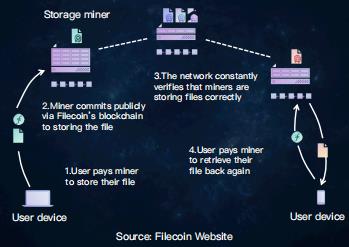
Filecoin运作方式
目前,Filecoin生态还在构建中,目前整个生态的参与者主要还是以旷工为主。未来包括开发者、客户端、持币者、生态合作伙伴们能够共同参与进来,扮演好自身的角色,让整个Filecoin网络更好地发挥作用,推动生态构建、应用落地,实现真实数据存储。
Distributed Cloud丨全球分布式云大会
Distributed Cloud丨联系我们
赞助、参展、加入联盟
姓名|林婷婷
以上是关于互联网如何海量存储数据?的主要内容,如果未能解决你的问题,请参考以下文章