官网下载安装python
在VS code里面安装python插件 https://www.cnblogs.com/bloglkl/archive/2016/08/23/5797805.html
- cmd进入python输入
/*
没报错则证明urllib安装成功
*/
from urllib.request import urlopen
- 直接在cmd输入
pip install beautifulsoup4//安装beautifulsoup4
- cmd进入python输入
/*
没报错验证beautifulsoup4安装
*/
from bs4 import BeautifuSoup
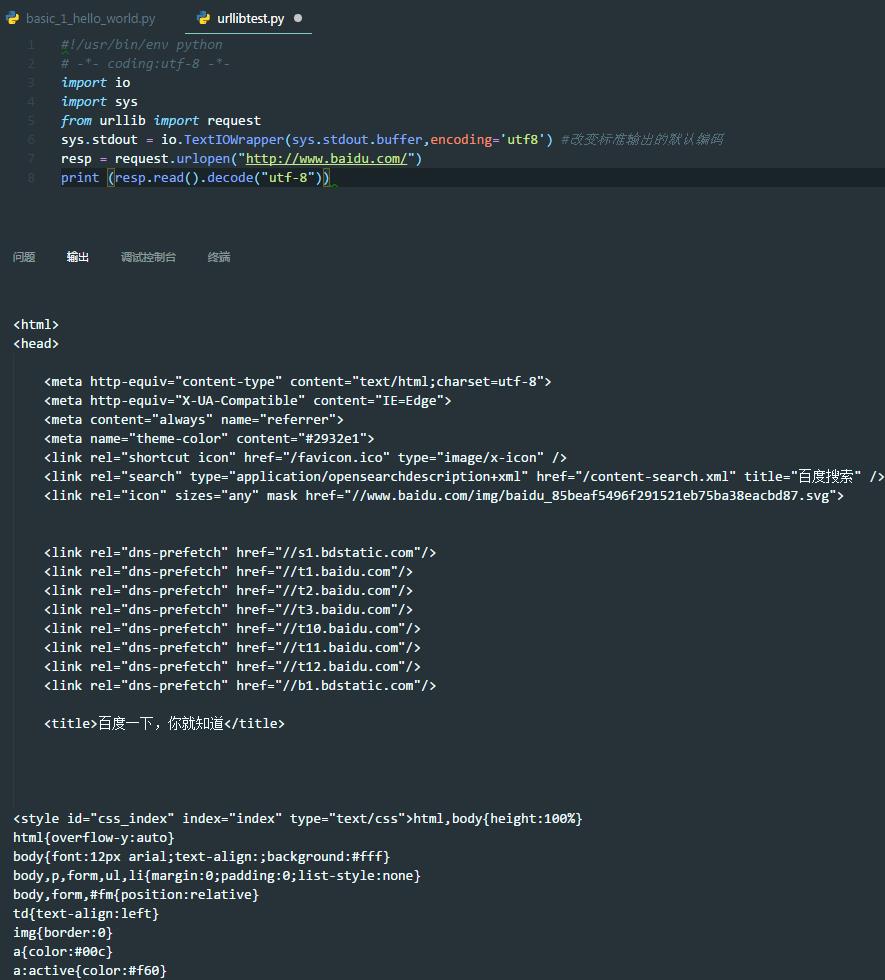
- 爬取百度首页
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import io
import sys
from urllib import request
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding=\'utf8\') #改变标准输出的默认编码
resp = request.urlopen("http://www.baidu.com/")
print (resp.read().decode("utf-8"))