#yyds干货盘点#数据分析从零开始实战,Pandas读取HTML页面+数据处理解析
Posted 简说Python
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了#yyds干货盘点#数据分析从零开始实战,Pandas读取HTML页面+数据处理解析相关的知识,希望对你有一定的参考价值。
这是我参与11月更文挑战的第17天。
零 写在前面
本系列学习笔记参考书籍: 《数据分析实战》托马兹·卓巴斯,会将自己学习本书的笔记分享给大家,同样开成一个系列『数据分析从零开始实战』。
点击查看第一篇文章: # 数据分析从零开始实战,Pandas读写CSV数据
点击查看第二篇文章: # 数据分析从零开始实战,Pandas读写TSV/Json数据
点击查看第三篇文章: # 数据分析从零开始实战,Pandas读写Excel/XML数据
前面三篇文章讲了数据分析虚拟环境创建和pandas读写CSV、TSV、JSON、Excel、XML格式的数据,今天我们继续探索pandas。
一 基本知识概要
- 利用Pandas检索html页面(read_html函数)
- 实战训练使用read_html函数直接获取页面数据
- 基本数据处理:表头处理、dropna和fillna详解
- 基本数据可视化分析案例
二 开始动手动脑
1.Pandas的read_html函数
这里我们要介绍的是Pandas里解析HTML页面的函数:read_html。

查看源码后我们可以看出,该函数的参数比较多,下面我挑重点给大家解释几个。 (1)io(最关键参数)
源码注释
A URL, a file-like object, or a raw string containing HTML. Note that
lxml only accepts the http, ftp and file url protocols. If you have a
URL that starts with ``https`` you might try removing the ``s``.
我的理解
数据地址(网页地址、包含HTML的文件地址或者字符串)。
注意lxml只接受HTTP、FTP和文件URL协议。
如果你有以“https”开头的URL,你可以尝试删除“s”再传入参数。
(2)match
源码注释
str or compiled regular expression, optional
The set of tables containing text matching this regex or string will be
returned. Unless the HTML is extremely simple you will probably need to
pass a non-empty string here. Defaults to .+ (match any non-empty
string). The default value will return all tables contained on a page.
This value is converted to a regular expression so that there is
consistent behavior between Beautiful Soup and lxml.
我的理解
字符串或编译的正则表达式,可选
包含与此正则表达式或字符串匹配的文本的一组表将返回。
除非HTML非常简单,否则您可能需要在此处传递一个非空字符串。
默认为“.+”(匹配任何非空字符串)。默认值将返回页面上包含的所有标签包含的表格。
该值将转换为正则表达式,以便Beautiful Soup和LXML之间一致。
(3)flavor
源码注释
flavor : str or None, container of strings
The parsing engine to use. bs4 and html5lib are synonymous with
each other, they are both there for backwards compatibility. The
default of ``None`` tries to use ``lxml`` to parse and if that fails it
falls back on ``bs4`` + ``html5lib``.
我的理解
要使用的解析引擎。bs4和html5lib是彼此的同义词,
它们都是为了向后兼容。默认为空,尝试用于lxml解析的默认值,
如果失败,则使用bs4和 html5lib。
2.数据基本处理
(1)处理列名
# 处理列名
import re
# 匹配字符串中任意空白字符的正则表达式
space = re.compile(r"\\s+")
def fix_string_spaces(columnsToFix):
将列名中的空白字符转变成下划线
tempColumnNames = [] # 保存处理后的列名
# 循环处理所有列
for item in columnsToFix:
# 匹配到
if space.search(item):
# 处理并加入列表
tempColumnNames.append(_.join((space.split(item))))
这句有点长涉及到列表的一些操作,我解释一下
str1.split(str2) str1 表示被分隔的字符串;str2表示分隔字符串
str3.join(list1) str2 表示按什么字符串进行连接;list1表示待连接的列表
list2.append(str4) 表示在列表list2的末尾添加str4这个元素
else :
# 否则直接加入列表
tempColumnNames.append(item)
return tempColumnNames
上面这段代码来自书本,其目的是处理列名,将列名里为空的字符转变成-符号,仔细一想,其实这个是可以通用的,比如处理某行数据里为空的,处理某个列表里为空的数据等,复用性很强。
(2)对缺失数据处理之dropna函数
dropna()函数:对缺失的数据进行过滤。

常用参数解析: axis:
源码注释
axis : {0 or index, 1 or columns}, default 0
Determine if rows or columns which contain missing values are removed.
* 0, or index : Drop rows which contain missing values.
* 1, or columns : Drop columns which contain missing value.
.. deprecated:: 0.23.0: Pass tuple or list to drop on multiple axes.我的理解
少用,默认值为0,表示删除包含缺少值的行;值为1,表示删除包含缺少值的列。
how:
源码注释
how : {any, all}, default any
Determine if row or column is removed from DataFrame, when we have at least one NA or all NA.
* any : If any NA values are present, drop that row or column.
* all : If all values are NA, drop that row or column.我的理解
默认值为any,表示如果存在任何NA(空)值,则删除该行或列;
值为all,表示如果全都是NA值,则删除该行或列。
thresh:
源码注释
thresh : int, optional
Require that many non-NA values.
我的理解
不为NA的个数,满足要求的行保留,不满足的行被删除。
inplace:
源码注释
inplace : bool, default False
If True, do operation inplace and return None.
我的理解
默认为False,表示不在原对象上操作,
而是复制一个新的对象进行操作并返回;
值为True时,表示直接在原对象上进行操作。
(3)对缺失数据处理之fillna函数
fillna()函数:用指定值或插值的方法填充缺失数据。

常用参数解析: value:
源码注释
value : scalar, dict, Series, or DataFrame
Value to use to fill holes (e.g. 0), alternately a
dict/Series/DataFrame of values specifying which value to use for
each index (for a Series) or column (for a DataFrame). (values not
in the dict/Series/DataFrame will not be filled). This value cannot
be a list.
我的理解
简单点说,就是替换NA(空值)的值。如果是直接给值,表示全部替换;
如果是字典: {列名:替换值} 表示替换掉该列包含的所有空值。
method:
源码注释
method : {backfill, bfill, pad, ffill, None}, default None
Method to use for filling holes in reindexed Series
pad / ffill: propagate last valid observation forward to next valid
backfill / bfill: use NEXT valid observation to fill gap我的理解
在重新索引系列中填充空白值的方法。
pad / ffill:按列检索,将最后一次不为空的值赋给下一个空值。
backfill / bfill:按列检索,将下一个不为空的值赋给该空值。
注意:该参数不可与value 同时存在
limit:
源码注释
limit : int, default None
If method is specified, this is the maximum number of consecutive.
NaN values to forward/backward fill. In other words, if there is a gap
with more than this number of consecutive NaNs, it will only be partially
filled. If method is not specified, this is the maximum number of entries
along the entire axis where NaNs will be filled. Must be greater than 0 if not None.
我的理解
其实很简单,就是按列搜索空值,然后limit的值表示最大的连续填充空值个数。
比如:limit=2,表示一列中从上到下搜索,只替换前两个空值,后面都不替换。
吐个槽:别看源码里的英文注释单词都很简单,但,太简单了,根本连不成句子,我都是一个个实践+表面翻译,然后才能弄明白参数的意思。
3.数据爬取实战训练
五行代码爬取2019富豪榜(60亿美元以上的)
import pandas as pd
# 排行榜
for i in range(15):
# 页面地址
url = "https://www.phb123.com/renwu/fuhao/shishi_%d.html" % (i+1)
# 调用read_html函数,解析页面获取数据 List
url_read = pd.read_html(url, header=0)[0]
# 将数据存入csv文件
url_read.to_csv(rrich_list.csv, mode=a, encoding=utf_8_sig, header=0, index=False)
页面数据:

爬取结果
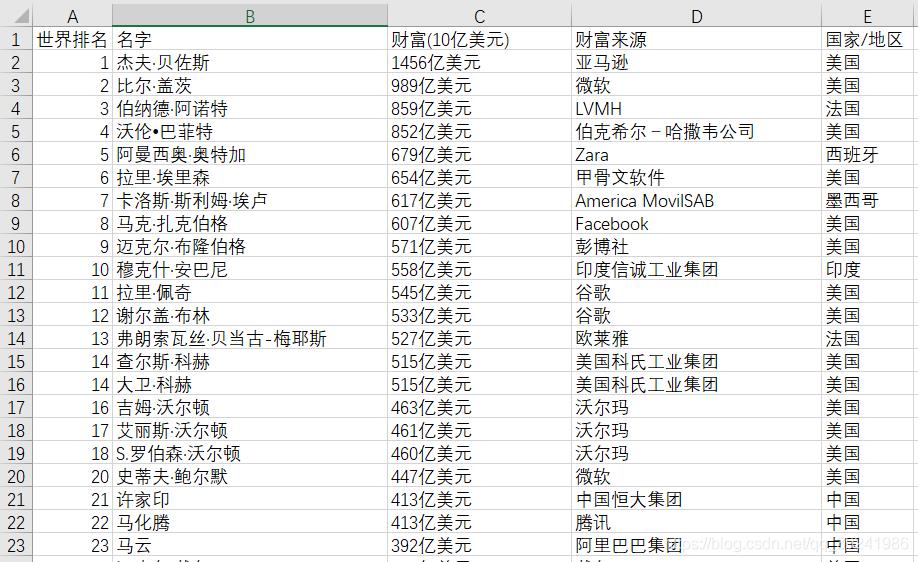
通过上面实战,你需要知道: 1、不要觉得怎么这么简单啊(是因为我找好了网站,这个网站数据里只有一个table,数据也比较干净); 2、真正工作中网站可能是不配合的,数据可能是不配合的,这个时候最好的方法是见仁见智,多看源代码。
4.数据可视化分析实战训练
基于我们上面拿到的数据,我们做个简单的数据可视化和分析报告。 上面我们已经拿到了2019富豪榜(60亿美元以上的)的数据,包含排名、姓名、财富数额、财富来源、国家这些信息,明确数据属性后,我们就该想一下我们能从那些方面去分析那些问题? 我想到的几个方面: (1)排行榜上各个国家的人数各多少?那些国家最多? (2)那些公司上榜的人数最多? (3)排行榜上的人所在的行业分布?
(0)读取数据和数据可视化
读取数据我们直接利用pandans的read_csv函数。
import pandas as pd
# 原始数据文件路径
rpath_csv = rich_list.csv
# 读取数据
csv_read = pd.read_csv(rpath_csv)
# 提取出来的数据是pandans的Series对象
# 后期处理可以直接转换成列表
name_list = csv_read["名字"]
money_list = csv_read["财富(10亿美元)"]
company_list = csv_read["财富来源"]
country_list = csv_read["国家/地区"]
数据可视化,我们从最简单的pyecharts模块。
pip install pyecharts==0.5.11
(1)排行榜上各个国家的人数各多少?那些国家最多?
# 排行榜上各个国家的人数各多少?那些国家最多?
"""
1、统计数据
利用collections模块的Counter函数
"""
country_list = list(country_list)
from collections import Counter
dict_number = Counter(country_list)
"""
2、数据可视化
利用pyecharts模块的Bar类
"""
bar = Bar("富豪国家分布柱状图")
bar.add("富豪", key_list, values_list, is_more_utils=True, is_datazoom_show=True,
xaxis_interval=0, xaxis_rotate=30, yaxis_rotate=30, mark_line=["average"], mark_point=["max", "min"])
bar.render("rich_country.html")
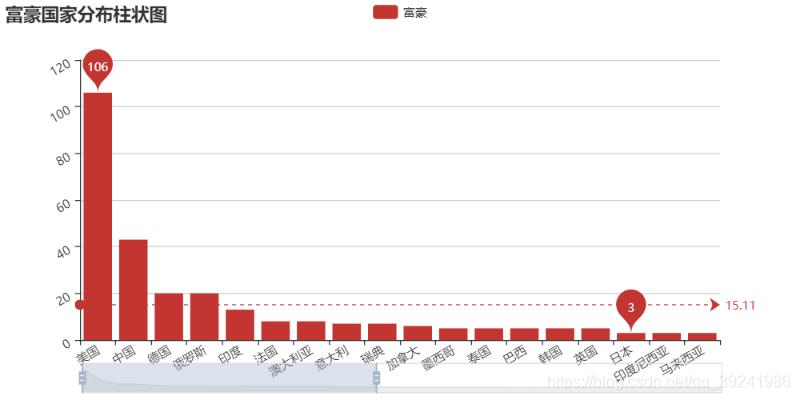
从上面数据,我们可以很明显的发现,富豪榜上富豪的国籍,美国居多,而且可以说是遥遥领先,总共是300人,美国国籍的有106人,占了总数据的1/3还多,这个比较好理解,美国一直是一个超级大国,各个方面的发展都位列全球前列。 位列第二的是中国,占了43人,也是特别多的,而且对于中国,发展到现在是非常非常不容易的,从1949年成立,到今年2019年,建国70年,从“为中华之崛起而读书”到“为实现中国梦、建设富强民主文明和谐美丽的社会主义现代化强国而奋斗”,作为中国人,我是骄傲的。 第三名是德国和俄罗斯,各占20人,德国是个工业大国,欧洲最大经济体,所以德国的强健是显而易见的,另外俄罗斯,世界面积最大的国家,曾经苏联也是世界第二经济强国,虽然苏联解体后不如从前,但近几年普京执政,经济稳步回升。 再后面的国家中以欧洲国家居多,其中第五是印度,其科技实力十分发达。
(2)那些公司上榜的人数最多?
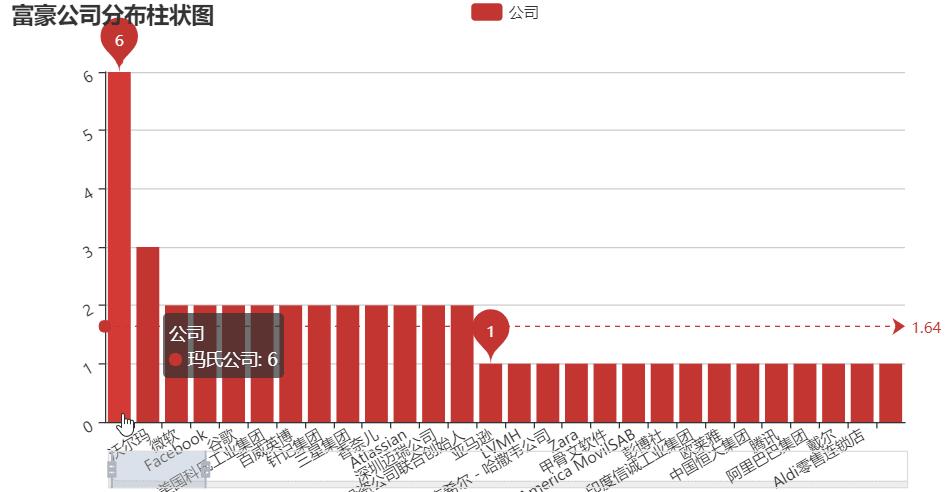
注意哦~能上这个榜的,财富最低都是60亿美元,从统计数据来看,玛氏公司上榜人数最多,有6个上榜的富豪来自玛氏公司,其次是沃尔玛百货有限公司,有3个人来自该公司,这两个公司都是日化类公司,接下来的:微软、Facebook、谷歌都是科技类公司
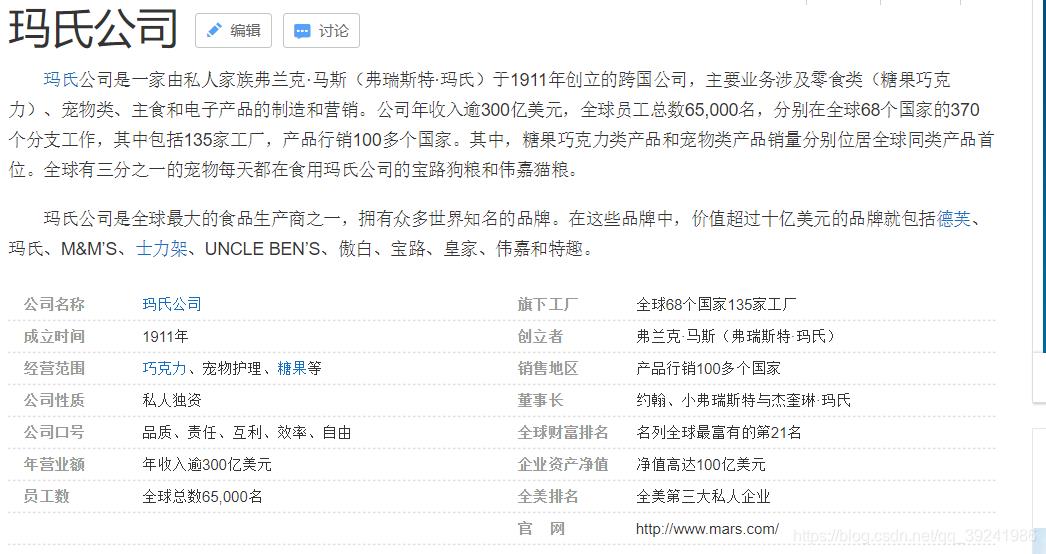
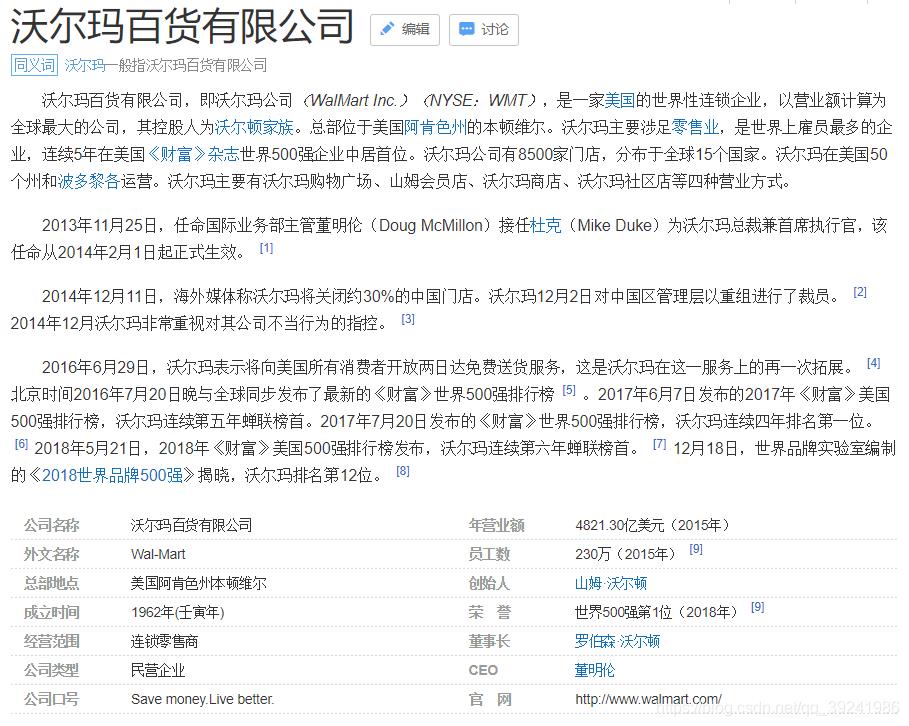
不查一下,我还真不知道原来“饿货,快来条士力架”的士力架、“德芙,纵享丝滑”的德芙是来自一家公司的,而且是玛氏公司的,此处双击666。另外沃尔玛在2018年被评选为世界五百强的第一位,莫种意义来说,这就是宇宙最强公司啊~(小时候我一直以为富迪是最厉害的超市,长大后我又以为万达是最厉害的超市,现在,我知道了,是沃尔玛!)
(3)排行榜上的人所在的行业分布?等你回答
这部分其实是不好做的,因为我们获取到的数据里没有直接和行业相连的数据,唯一能和行业有点联系的就是公司,这就需要我们通过公司名称去判断(或者在网上获取)该公司的类别属性,比如是互联网公司,还是传统行业等等方面。
三 送你的话
坚持 and 努力 : 终有所获。
思想很复杂,
实现很有趣,
只要不放弃,
终有成名日。