PHP字符串长度计算 - strlen()函数使用介绍
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PHP字符串长度计算 - strlen()函数使用介绍相关的知识,希望对你有一定的参考价值。
参考技术A strlen()函数和mb_strlen()函数在php中,函数strlen()返回字符串的长度。函数原型如下:
复制代码
代码如下:
int
strlen(string
string_input);
参数string_input为要处理的字符串。
strlen()函数返回字符串所占的字节长度,一个英文字母、数字、各种符号均占一个字节,它们的长度均为1。一个中午字符占两个字节,所以一个中午字符的长度是2。例如
复制代码
代码如下:
<?php
echo
strlen("www.sunchis.com");
echo
strlen("三知开发网");
?>
“echo
strlen("www.sunchis.com");”的运行结果:15
“echo
strlen("三知开发网");”的运行结果:15
这里有一个疑问,一个中文字符不是占2个字节吗?“三知开发网”,明明是五个汉字,运行的结果怎么会是15?
原因出在这里:strlen()计算时,对于一个UTF-8的中文字符,会把它当做长度为3来处理。当出现中英文混排的情况下,怎么准确的计算字符串的长度呢?这里,得引入另外一个函数mb_strlen()。mb_strlen()函数的用法与strlen()几乎一摸一样,只是多了一个指定字符集编码的参数。函数原型为:
复制代码
代码如下:
int
mb_strlen(string
string_input,
string
encode);
PHP内置的字符串长度函数strlen无法正确处理中文字符串,它得到的只是字符串所占的字节数。对于GB2312的中文编码,strlen得到的值是汉字个数的2倍,而对于UTF-8编码的中文,就是3倍的差异了(在UTF-8编码下,一个汉字占3个字节)。
因此,下面的代码能准确计算出中文字符串的长度:
复制代码
代码如下:
<?php
$str
=
"三知sunchis开发网";
echo
strlen($str)."<br>";
//结果:22
echo
mb_strlen($str,"UTF8")."<br>";
//结果:12
$strlen
=
(strlen($str)+mb_strlen($str,"UTF8"))/2;
echo
$strlen;
//结果:17
?>
原理分析:
strlen()计算时,对待UTF-8的中文字符长度是3,所以“三知sunchis开发网”的长度为5×3+7×1=22
在mb_strlen计算时,选定内码为UTF8,则会将一个中文字符当作长度1来计算,所以“三知sunchis开发网”长度为5×1+7×1=12
剩下的就是纯数学问题了,在此就不啰嗦了……
注意:对于mb_strlen($str,'UTF-8'),如果省略第二个参数,则会使用PHP的内部编码。内部编码可以通过mb_internal_encoding()函数得到。需要注意的是,mb_strlen并不是PHP核心函数,使用前需要确保在php.ini中加载了php_mbstring.dll,即确保“extension=php_mbstring.dll”这一行存在并且没有被注释掉,否则会出现未定义函数的问题。
php哪个函数能取得字符串长度
1、首先新建一个php文件,命名为test.php。

2、在test.php文件内,定义两个字符串,一个纯英文字符串,另一个中英文混合的字符串。
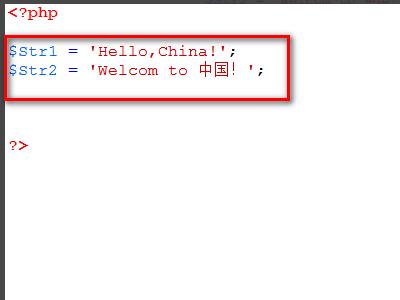
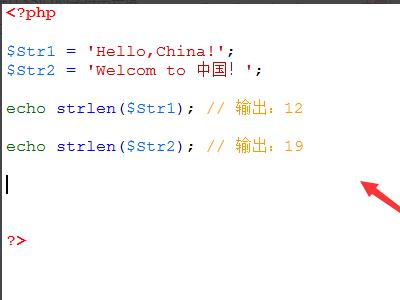
3、使用strlen()方法统计长度,从执行程序结果可见,strlen()方法统计$Str1的字符串长度是正确的,统计第二个字符串$Str2的长度是错误的。
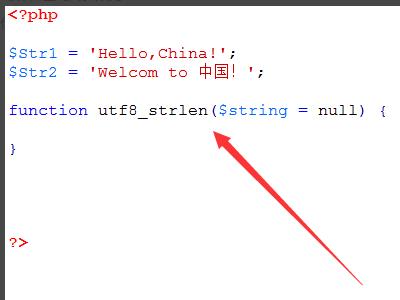
4、新建一个utf8_strlen()函数,定义其参数为$string,默认为null。
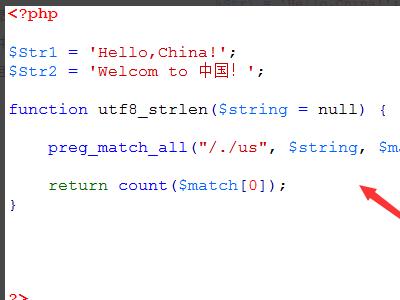
5、在utf8_strlen()函数内,使用preg_match_all()方法通过正则表达式拆分字符串,并保存在$match变量中,最后,通过count()方法统计得到的数组元素的个数,将结果返回。
6、使用utf8_strlen()方法分别统计$Str1,$Str2字符串的长度,并使用echo将结果输出到页面中。

7、在浏览器运行test.php文件,查看程序执行的结果,从两个结果可以看出成功实现了统计字符串的长度。

PHP自带的函数如strlen()、mb_strlen()都是通过计算字符串所占字节数来统计字符串长度的,一个英文字符占1字节。例:
$enStr = ‘Hello,China!’;
echo strlen($enStr); // 输出:12
而中文则不然,做中文网站一般会选择两种编码:gbk/gb2312或是utf-8。utf-8能兼容更多的字符,所以受到很多站长的喜爱。gbk与utf-8对中文的编码不同,导致中文在gbk与utf-8编码下所占字节也有差异。
gbk编码下每个中文字符所占字节为2,例:
$zhStr = ‘您好,中国!’;
echo strlen($zhStr); // 输出:12
utf-8编码下每个中文字符所占字节为3,例:
$zhStr = ‘您好,中国!’;
echo strlen($zhStr); // 输出:18
那么如何计算这组中文字符串的长度呢?有人可能会说gbk下获取中文字符串长度除以2,utf-8编码下除以3不就行了吗?但是您要考虑字符串并不老实,99%的情况会以中英混合的情况出现。
这是WordPress中的一段代码,主要思想就是先用正则将字符串分解为个体单元,然后再计算单元的个数即字符串的长度,代码如下(只能处理utf-8编码下的字符串):
$zhStr = ‘您好,中国!’;
$str = ‘Hello,中国!’;
// 计算中文字符串长度
function utf8_strlen($string = null)
// 将字符串分解为单元
preg_match_all(“/./us”, $string, $match);
// 返回单元个数
return count($match[0]);
echo utf8_strlen($zhStr); // 输出:6
echo utf8_strlen($str); // 输出:9 收起
以上是关于PHP字符串长度计算 - strlen()函数使用介绍的主要内容,如果未能解决你的问题,请参考以下文章