一个普通的开发日常-记一次缓存问题在实际开发中的解决方案
Posted 跟着小苏不加班
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一个普通的开发日常-记一次缓存问题在实际开发中的解决方案相关的知识,希望对你有一定的参考价值。
作为一个摸鱼大户,每天上班后看看热搜、听听音乐、刷刷知乎和同事扯扯闲淡,多么惬意而又美好的生活。但是生活啊,总是那么的不尽如人意。俗话说,摸鱼摸多了,人就废了。这不我顶着个位数QPS的压力去实现我们的首页,话不多说,先看业务需求。
业务介绍业务是为一个社区系统做一个CMS。对于前端的展示功能区,分为搜索、话题、banner轮播图和标签,标签的下面又划分为标签1、标签2和标签n。简单两句话也描述不清具体要干啥,还是直接上图吧。
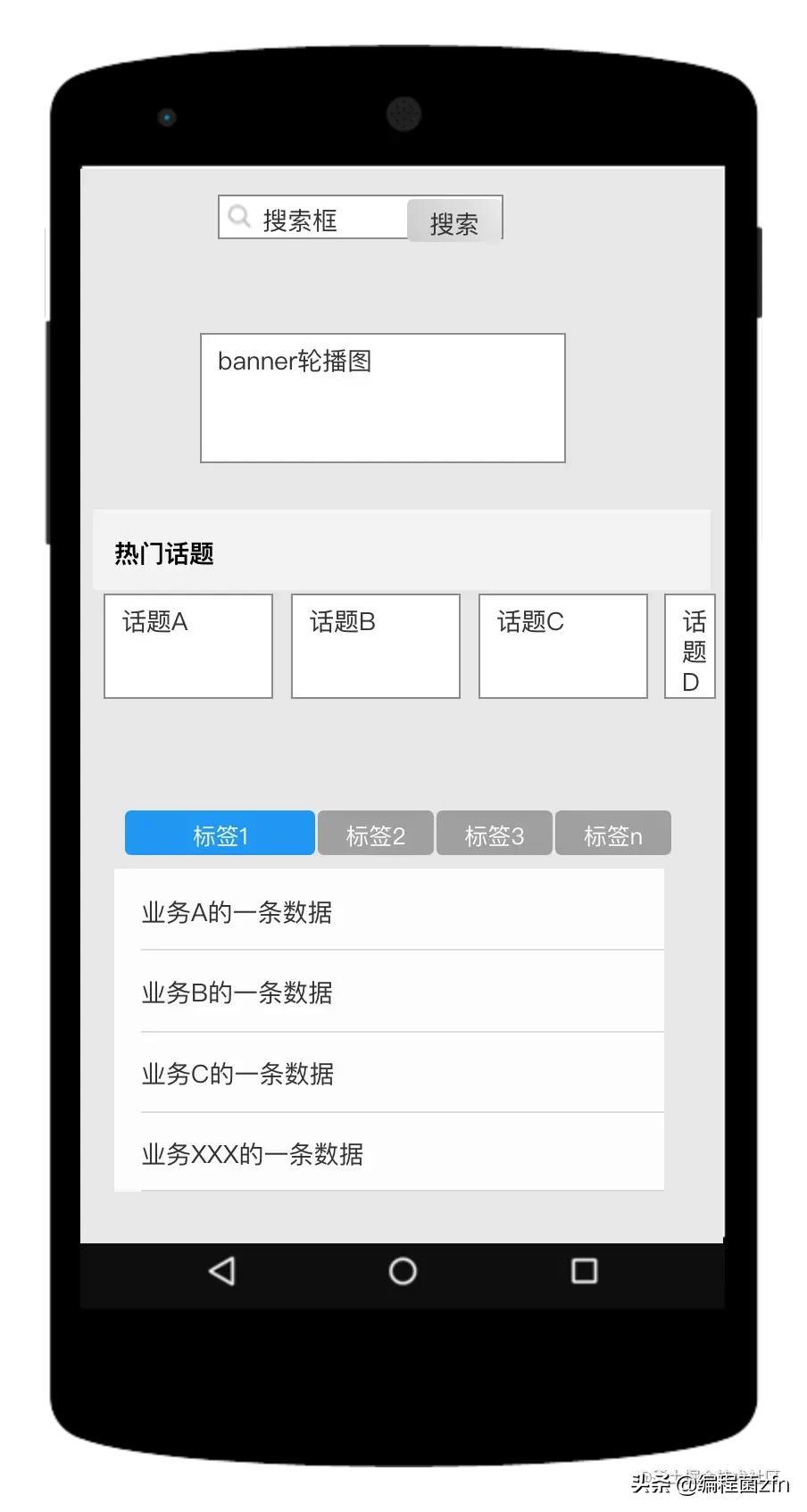
下面介绍C端这几个功能的作用。
- 搜索。根据用户输入的关键字或者已经配置的默认/热门搜索词来搜索社区内具体业务的数据,然后形成列表展示给用户。
- banner。根据用户的点击来跳转到具体的页面(比如:广告或者活动页面)。
- 话题。功能和搜索一致,只是搜索的关键词是给定的。
- 标签。每一个标签对应着一个或多个业务混合的数据列表。
介绍完毕了C端的这几个功能,现在来分析一下CMS系统的用例。C端需要搜索词,banner,话题和配置的标签,以及每个标签内的数据配置。其实仔细分析一下,就能看出来,C端首页的这一堆标签和配置,后端提供一个接口就能解决。
而至于实际去搜索,简单点说,社区系统的业务数据会发消息到一个搜索系统,C端这个界面的所有列表和搜索,都是直接去搜索系统中查询,只有拿到业务的唯一标识去查看详情的时候,采取直接调用社区系统,还可以进行点赞,收藏、评论等操作,这里不过多的去赘述。
描述到这里了,下面是流程的全貌图。
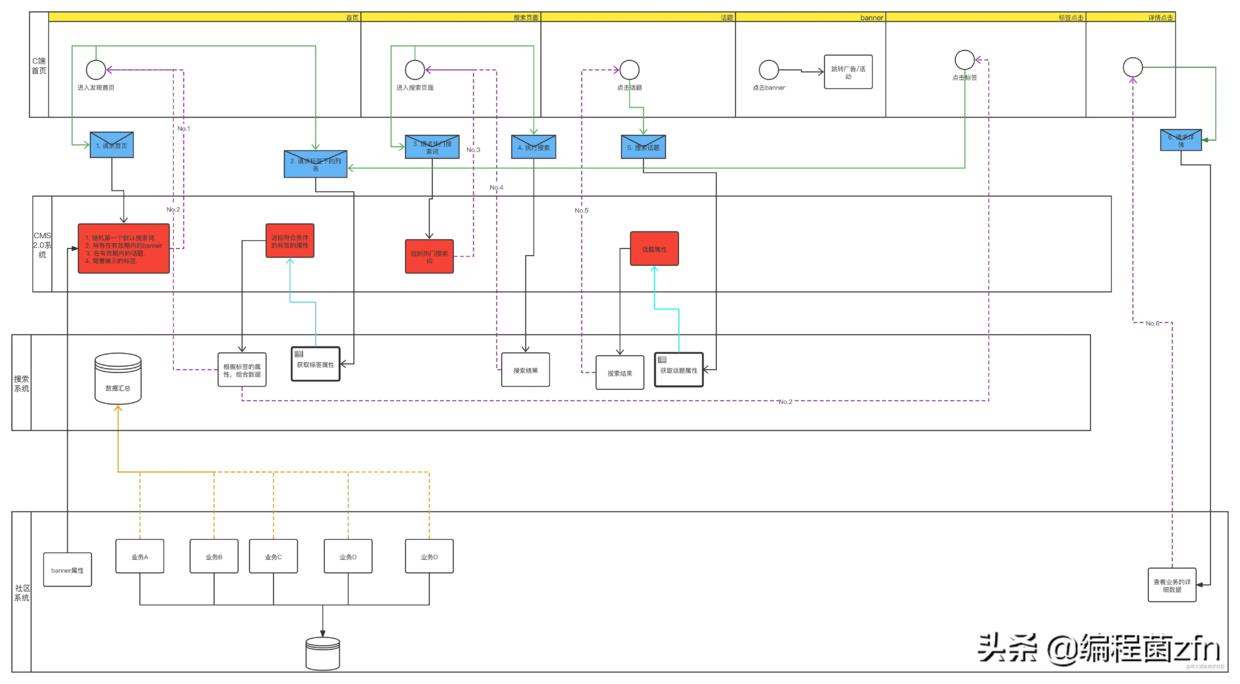
整个业务的流程就是这样了,介绍了业务流程,一眼就能看出,CMS系统的瓶颈就是查询的效率。对于CMS系统里面的配置,业务人员更改的频率比较低,按照菜鱼我所在的摸鱼无限无责任公司的尿性,一周更改一次都算是高频率了。
虽然更改的频率低,但是不排除万一哪天我们的市场人员突然人品大爆发,或者某个爬虫小老弟来搞我们,如果不对数据做特殊处理,我们那可怜的数据库容器可就遭殃了。既然这样,那就上Redis。
针对CMS这部分业务来说,我们并没有使用那些复杂的数据结构,而是直接使用的key-value。为什么呢,其中一个原因是CMS里面的数据量少,更重要的原因是没必要。适合自己的才是王道。既然使用缓存了,那么击穿、 穿透和雪崩这些是不是都需要考虑到呢?
缓存击穿所谓缓存击穿,是指某数据不存在于缓存中,但是数据库中却存在。常见的场景是在缓存到期或因为更新数据库从而删缓存以后。单线程的理想情况下,是不存在缓存击穿这个说法的,因为缓存中不存在,就直接查一次库,然后把缓存设置上就可以了,这是程序运行最合理的方式。当在多线程的情况下,缓存中不存在数据,在一定时间内会造成数据库的拥堵,当第一批线程查库并且设置缓存结束以后,后面的线程再过来,就直接查询缓存了,就像下面这样。
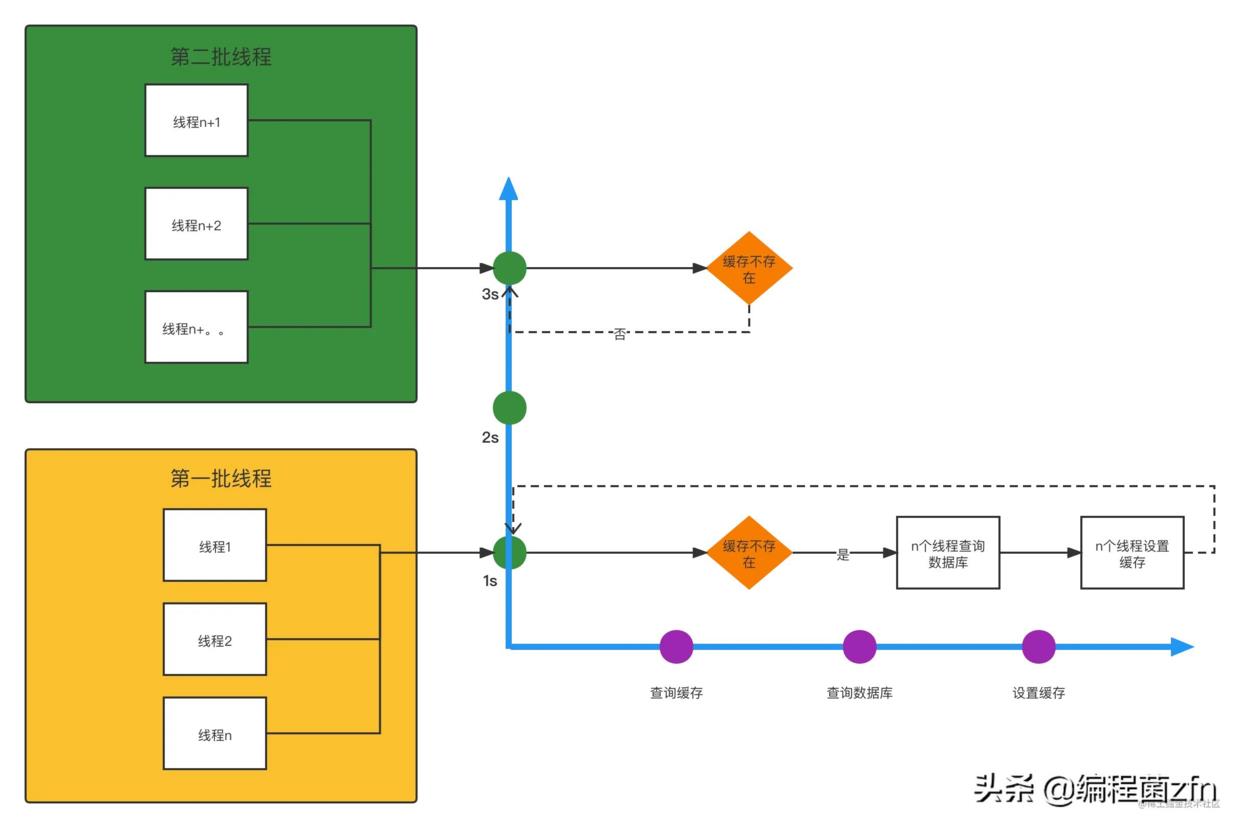
问题出来了,如何抗住第一波请求,让请求去查库的技术尽可能的少,这才是我们的目的。常见的解决方案就是锁或缓存不过期,技术的选型是根据业务来的。这里我们选择的方案是加锁,因为数据更改的频率不确定。接下来就选择单机锁还是分布式锁的问题了,现在微服务很流行啊,为了高可用,把同一个服务部署在两容器上也不难,所以这里选择了分布式锁,setnx命令实现的分布式锁,至于其内部原理,这里不过多赘述。 先来看一下没有加锁代码是怎么实现的:
无锁的逻辑:
ResponseVO queryData(){
// 先从缓存中查数据
ResonseVO vo=queryFromCache();
if(Objects.isNull(vo){
// 缓存中没有数据,去数据库中查询数据
DataBaseEntity entity=queryFromDataBase();
vo=dataConvert(entity);
// 设置缓存
setCache(vo);
}
return vo;
}
再来考虑一下如何使用分布式锁,有两个思路:
- 第一个思路:当n个线程来同时来竞争锁的时候,只有一个线程能胜出,这个线程查库和设置缓存结束以后,释放掉锁。而后其他n-1个线程竞争,当某线程胜出后,查一遍缓存,发现缓存已经存在了,就直接返回查询值释放掉锁。
就像下面这样:
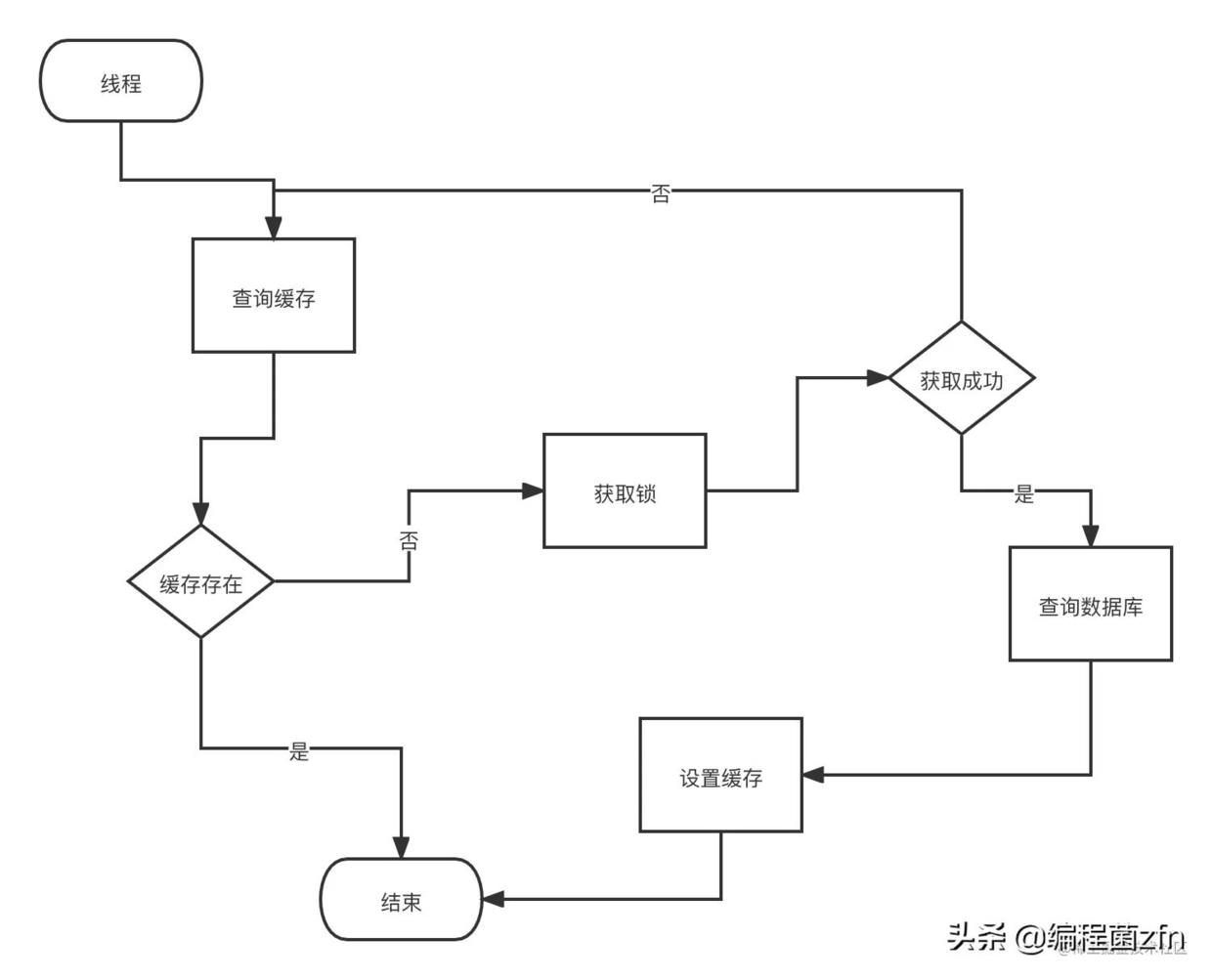
加锁的代码逻辑,思路一:
ResponseVO queryData() {
int retry = 0;
boolean locked;
try {
do {
// 从缓存中查询数据
ResponseVO vo = queryFromCache();
if (Objects.isNull(vo) {
return vo;
}
// 尝试获取锁,setnx命令
locked = tryLock();
if (locked) {
// 获取到锁以后,再次从缓存查数据.
// 因为当前线程获取到的锁是被另外一个线程释放掉的,而另外一个线程此时已经设置了缓存
vo = queryFromCache();
if (Objects.isNull(vo) {
return vo;
}
// 如果缓存中还是没有数据,只能查库了
DataBaseEntity entity = queryFromDataBase();
vo = dataConvert(entity);
// 设置缓存
setCache(vo);
return vo;
}
retry++;
} while (!locked && retry <= 10); // 如果某线程一直获取不到锁,就进入死循环了,设置一个循环次数
} finally {
if (locked) {
// 释放锁
releaseLock();
}
}
return null;
}
这种方式如果控制不得当,比如某线程就是获取不到锁,那整个程序就陷入死循环了,所以加入一个重试机制,循环十次获取不到锁,就退出循环。
- 第二个思路:还是n个线程来竞争,只有一个线程能胜出,其他没有能获取到锁的线程直接去sleep,给他们设置一个睡眠时间,让他们睡一觉再去获取锁。就像下面这样:
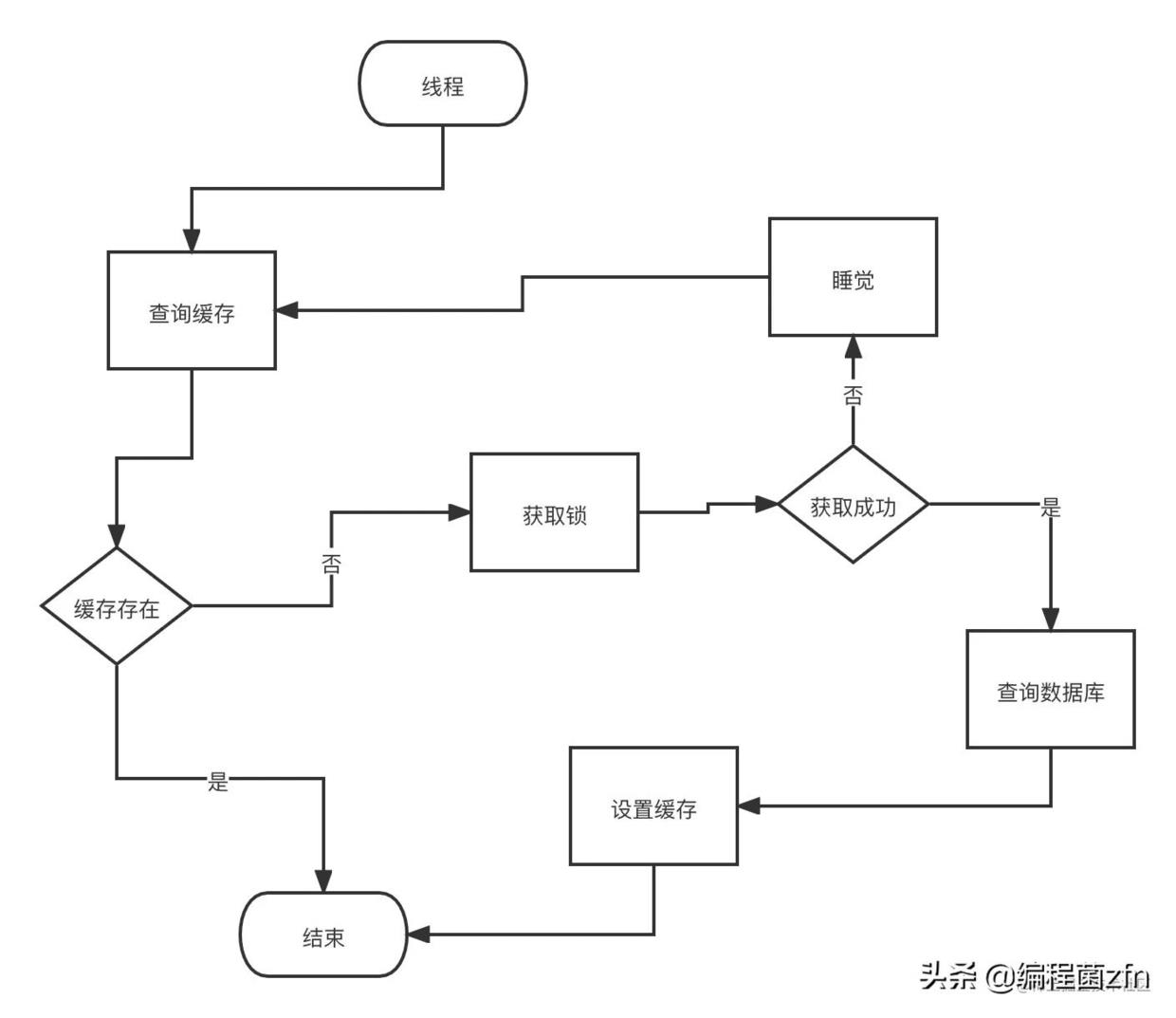
加锁的代码逻辑,思路二:
ResponseVO queryData() {
int retry = 0;
boolean locked;
try {
do{
// 从缓存中查询数据
ResponseVO vo = queryFromCache();
if (Objects.isNull(vo) {
return vo;
}
// 尝试获取锁,setnx命令,没获取到锁,就睡两秒钟
locked = tryLock(2);
if (locked) {
// 获取到锁以后,再次从缓存查数据.
// 因为当前线程获取到的锁是被另外一个线程释放掉的,而另外一个线程此时已经设置了缓存
vo = queryFromCache();
if (Objects.isNull(vo) {
return vo;
}
// 如果缓存中还是没有数据,只能查库了
DataBaseEntity entity = queryFromDataBase();
vo = dataConvert(entity);
// 设置缓存
setCache(vo);
return vo;
}
retry++;
}while (!locked && retry<=10);
} finally {
if (locked) {
// 释放锁
releaseLock();
}
}
return null;
}
代码逻辑和思路一差不多,无非是在循环获取锁的时候做了一点小手脚。具体使用还是看并发量吧,至于你问菜鱼使用的是哪一种方式,那当然是高精尖的无锁的版本喽。原因无他,适合自己的才是王道。
缓存穿透所谓缓存穿透,是指某数据不存在于缓存中,数据库中也不存在。这个问题应该对应于特定的业务,比如上面CMS系统中的banner和话题,这两个业务中的数据是可有可无的。面对这个问题,最简单的解决办法就是给缓存设置特殊值。 比如:
ResponseVO queryData(){
// 先从缓存中查数据
ResonseVO vo=queryFromCache();
if(Objects.isNull(vo){
// 缓存中没有数据,去数据库中查询数据
DataBaseEntity entity=queryFromDataBase();
if(Objects.isNull(entity){
// 数据库中不存在,就设置一个空值
vo=new ResonseVO();
}else{
vo=dataConvert(entity);
}
// 设置缓存
setCache(vo);
}
return vo;
}
至于加不加锁,那就看业务的并发量喽。不过,菜鱼也看到网络上有其他解决方案,比如权限校验,布隆过滤器等等,之前菜鱼也考虑过实现一个布隆过滤器,后来估了一下开发时间,还是算了。
缓存雪崩所谓缓存雪崩,是指存在缓存中的数据批量过期或者频繁更新数据库,然后导致大量请求落到数据库上,从而给数据库造成压力。对于前者,解决方案就比较简单了,根据业务的具体需求,设置缓存不过期,或者把缓存过期的时间打散。 设置带有逾期时间的缓存,下面这条语句就是王道:
set(key,value,100+ThreadLocalRandom.current().nextInt(1,500));
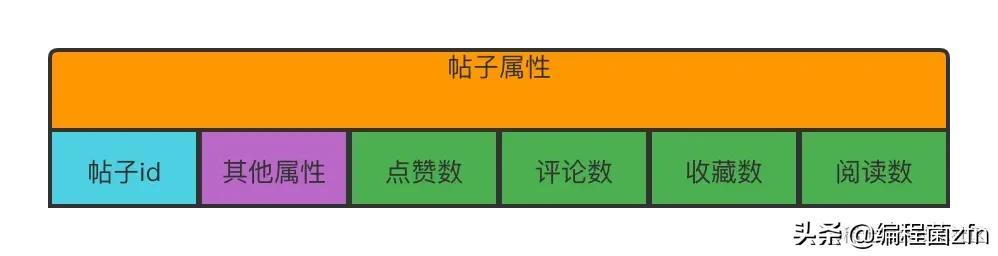
对于后者,那就要考虑一下业务了,频繁更新的数据要不要放在缓存里面,以及这个数据的重要性。上文提到,社区系统里面的有多种类型的数据,其中一个是发帖。帖子的属性有点赞数,收藏数,评论数和阅读次数。用户A发帖了,用户B能看到,并且可以点赞、收藏和评论,根据业务需求,这三个数值是要存关系的。用户B可以看到自己点赞,收藏和评论了哪些帖子。这是帖子的属性:
这是业务全貌图:
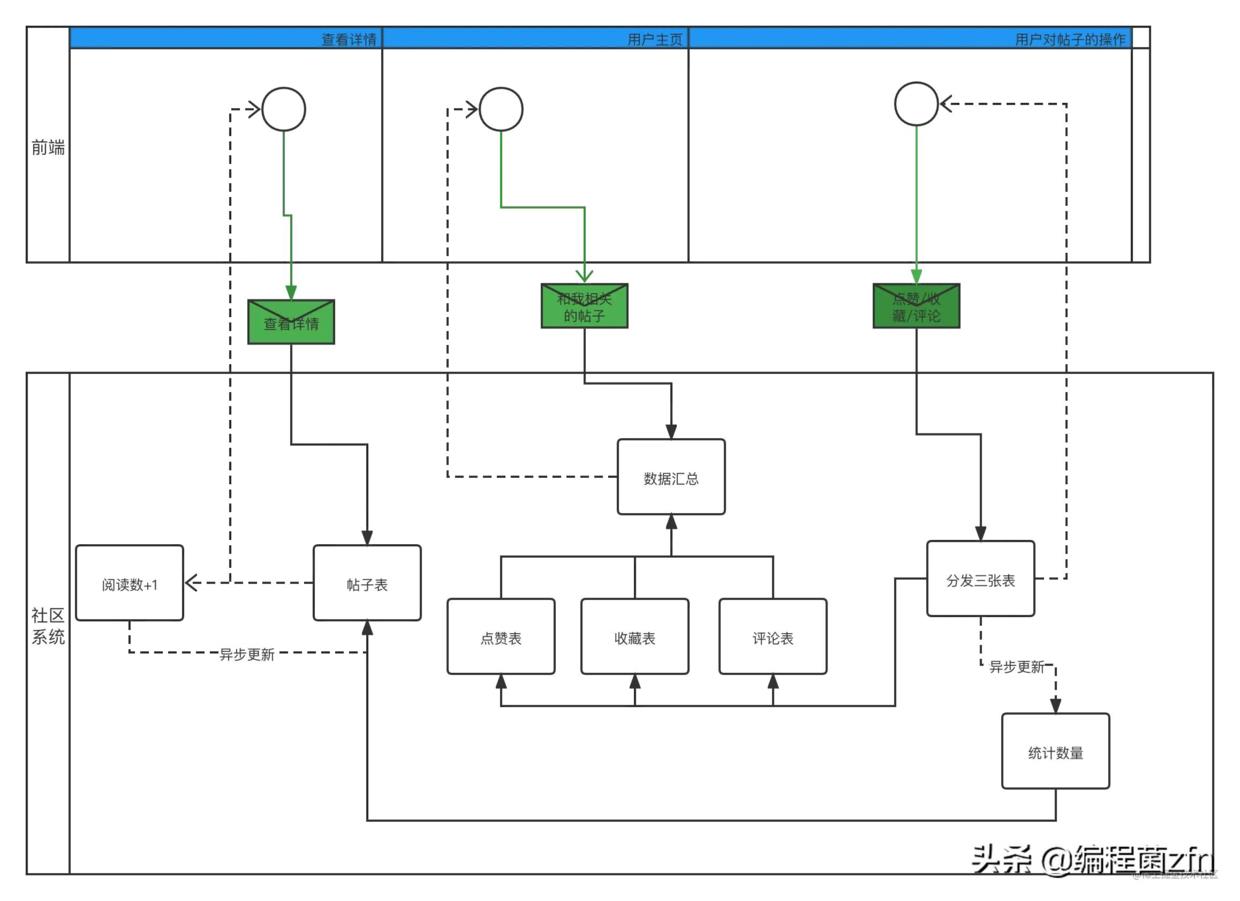
解释一下用例:
- 查看详情。直接从数据库中把帖子拿出来,然后阅读数+1,异步更新表,这个数值的正确与否,不重要。
- 用户主页。对业务而言,用户只需要看到和自己相关的帖子,这是重要的。
- 对帖子的操作。只需要把关系存储到三张表中,至于帖子上的点赞、收藏和评论数量,不重要,甚至数值是错的都没关系,只要能把关系维护完善。
这就是频繁更新数据库的一个例子,甚至都没把数据放在缓存里面。之前我们在讨论的架构的时候,有人提出要把这几个数字存放在缓存里面,讨论来讨论去,得出三个字的结论:没必要。如果非得放在缓存里面,然后还需要维护一张数值和帖子的关系表,累不累啊!!!
没有最好设计,只有最适合的设计。
本文仅作为个人学习使用,如有不足或错误请指正!
感兴趣也可以关注一下我的公众号,每天都会更新一篇技术文章

以上是关于一个普通的开发日常-记一次缓存问题在实际开发中的解决方案的主要内容,如果未能解决你的问题,请参考以下文章