求教c语言中fgets的用法
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了求教c语言中fgets的用法相关的知识,希望对你有一定的参考价值。
while((*fgets(buffer, 100, stdin) != '\n') && (i < 100))
ps[i] = (char *)malloc(strlen(buffer) + 1):
strcpy(ps[i++], buffer);
这段程序中while是在读入一行字符串后执行括号里面的语句吗?为什么这段代码能够在输入一个空行(\n)后结束?fgets在读入第一行字符串后会读入\n\0吧,这时循环应该结束了啊,为什么还会读入整段字符串?
请回答我的那几个问题,谢谢大家。
从流中读一行或指定个字符,原型是char*fgets(char*s,intn,FILE*stream);从流中读取n-1个字符,除非读完一行,参数s是来接收字符串,如果成功则返回s的指针,否则返回NULL。
*string结果数据的首地址;n-1:一次读入数据块的长度,其默认值为1k,即1024;stream文件指针fgets的返回值是个指针,*fgets(buffer,100,stdin)就是取返回指针所指向地址的第一个字符,fgets的返回值是char*.要是输入一串字符,返回的第一字符一定不是\\n如果要是一个空行,第一个一定是\\n,所以会推出循环,如果while中的两个条件都满足,就会进入循环继续计算。

扩展资料:
一、函数原型是:char *fgets(char *s, int n, FILE *stream);
从文件结构体指针stream中读取数据,每次读取一行。读取的数据保存在buf指向的字符数组中,每次最多读取bufsize-1个字符(第bufsize个字符赋'\\0'),如果文件中的该行,不足bufsize-1个字符,则读完该行就结束。
如若该行(包括最后一个换行符)的字符数超过bufsize-1,则fgets只返回一个不完整的行,但是,缓冲区总是以NULL字符结尾,对fgets的下一次调用会继续读该行。
函数成功将返回buf,失败或读到文件结尾返回NULL。因此我们不能直接通过fgets的返回值来判断函数是否是出错而终止的,应该借助feof函数或者ferror函数来判断。
二、与gets相比使用这个好处是:读取指定大小的数据,避免gets函数从stdin接收字符串而不检查它所复制的缓存的容积导致的缓存溢出问题。
三、功能:
1、《UNIX 环境高级编程》中指出,每次调用fgets函数会造成标准输出设备自动刷清!案例详见《UNIX环境高级编程(第二版)》中程序清单1-5和课后习题5.7,习题5.7的答案中给出了相关的论述。
2、初入门者,大多数是在WINDOWS下,使用VS进行练习的。此环境下,对注意1中的情况进行测试,并不能看到案例中所描述的情景,因为具体的实现不同。
stream文件流指针体指向文件内容地址的偏移原则
例:
如果一个文件的当前位置的文本如下
Love, I Have
Since you can do it.
如果用fgets(str1,6,file1);去读取
则执行后str1 = "Love," ,读取了6-1=5个字符
这个时候再执行fgets(str1,20,file1)则执行后str1 = " I Have\\n"
而如果
fgets(str1,23,file1);
则执行str1="Love ,I Have",读取了一行(包括行尾的'\\n',并自动加上字符串结束符'\\0'),当前文件位置移至下一行,虽然23大于当前行上字符总和,可是不会继续到下一行。而下一次调用fgets()继续读取的时候是从下一行开始读。
参考资料:百度百科-fgets
参考技术A从流中读一行或指定个字符,原型是char*fgets(char*s,intn,FILE*stream);从流中读取n-1个字符,除非读完一行,参数s是来接收字符串,如果成功则返回s的指针,否则返回NULL。
形参注释:*string结果数据的首地址;n-1:一次读入数据块的长度,其默认值为1k,即1024;stream文件指针
fgets的返回值是个指针,*fgets(buffer,100,stdin)就是取返回指针所指向地址的第一个字符,fgets的返回值是char*.要是输入一串字符,返回的第一字符一定不是\\n如果要是一个空行,第一个一定是\\n,所以会推出循环,如果while中的两个条件都满足,就会进入循环继续计算。

扩展资料:
从文件结构体指针stream中读取数据,每次读取一行。读取的数据保存在buf指向的字符数组中,每次最多读取bufsize-1个字符(第bufsize个字符赋'\\0'),如果文件中的该行,不足bufsize-1个字符,则读完该行就结束。
如若该行(包括最后一个换行符)的字符数超过bufsize-1,则fgets只返回一个不完整的行,但是,缓冲区总是以NULL字符结尾,对fgets的下一次调用会继续读该行。
函数成功将返回buf,失败或读到文件结尾返回NULL。因此我们不能直接通过fgets的返回值来判断函数是否是出错而终止的,应该借助feof函数或者ferror函数来判断。
函数原型
char *fgets(char *buf, int bufsize, FILE *stream);
参数
*buf: 字符型指针,指向用来存储所得数据的地址。
bufsize: 整型数据,指明存储数据的大小。
*stream: 文件结构体指针,将要读取的文件流。
返回值
成功,则返回第一个参数buf;
在读字符时遇到end-of-file,则eof指示器被设置,如果还没读入任何字符就遇到这种情况,则buf保持原来的内容,返回NULL;
如果发生读入错误,error指示器被设置,返回NULL,buf的值可能被改变。
参考资料:百度百科——c语言fgets用法
原型是char *fgets(char *s, int n, FILE *stream);
从流中读取n-1个字符,除非读完一行,参数s是来接收字符串,如果成功则返回s的指针,否则返回NULL。
形参注释:*string结果数据的首地址;n-1:一次读入数据块的长度,其默认值为1k,即1024;stream文件指针
fgets的返回值是个指针,*fgets(buffer, 100, stdin)就是取返回指针所指向地址的第一个字符,fgets的返回值是char *.要是输入一串字符,返回的第一字符一定不是\n如果要是一个空行,第一个一定是\n,所以会推出循环,如果while中的两个条件都满足,就会进入循环继续计算本回答被提问者和网友采纳 参考技术C 写数据你用fprintf(fp,"格式描述符",要写的变量的地址);
fp是你的文件的指针
FILE *fp;
读的话用fscanf(fp,"格式描述符",要写的变量的地址);
其他的还有fputs();fgets();
fgets();是用来读字符串的
fputs()是用来写字符串的
用法是fgets(字符串地址,大小,fp)
fputs(字符串地址,大小,fp)
例如
char s[10];
FILE *fp;
fgets(s,8,fi);
从文件中读出的8个字符到数组s中
你在用
printf("%s",s);
输出就行了
还有好多,就先介绍到这里把 参考技术D 首先fgets函数是以指定的文件作为读的对象的,和gets功能类似。
回答:
①:while是条件,如果后面的那句成立,则向下执行,否则循环结束;
②:和第一个问题一样(注条件是!= '\n')是循环,否则结束,所以当读入的字符为'\n'循环结束;
③:这个读入的时候必需得有 '\n'这个符号是才停止循环,你按回车换行它是读不出来的。。。。
c语言里:sizeof怎样用法?
1、首先打开VS,新建一个 使用sizeof求出数组的大小 project。
2、接着在左侧文件树添加一个 sizeof.c 源文件。

3、其里面有stdio.h和stdlib.h头文件,也可自己输入。

4、然后输入main函数主体及返回值。
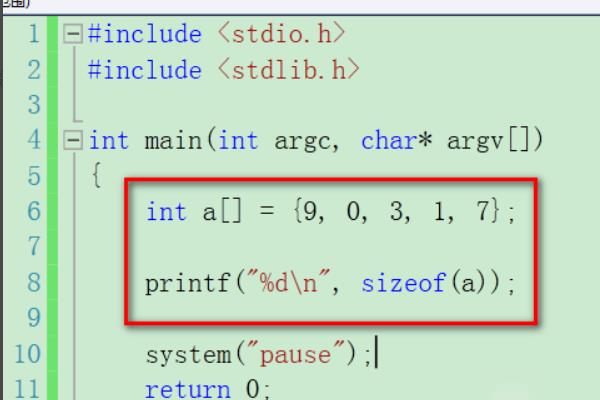
5、定义一个数组,使用sizeof计算出数组的大小。
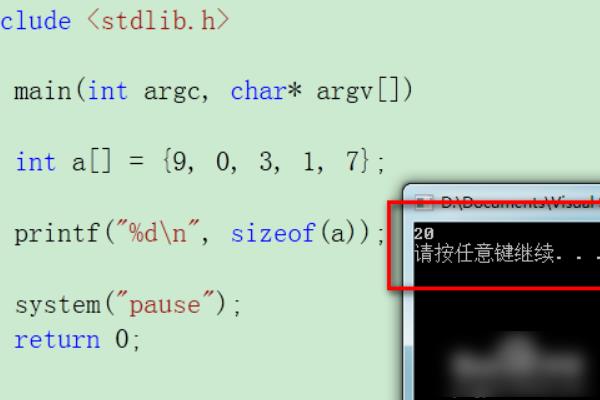
6、最后编译运行程序,便能输出数组的大小。
辛苦我一个,幸福千万人”的伟大思想,我决定将其尽可能详细的总结一下。
但当我总结的时候才发现,这个问题既可以简单,又可以复杂,所以本文有的地方并不
适合初学者,甚至都没有必要大作文章。但如果你想“知其然,更知其所以然”的话,
那么这篇文章对你或许有所帮助。
菜鸟我对C++的掌握尚未深入,其中不乏错误,欢迎各位指正啊
1. 定义:
sizeof是何方神圣sizeof乃C/C++中的一个操作符(operator)是也,简单的说其作
用就是返回一个对象或者类型所占的内存字节数。
MSDN上的解释为:
The sizeof keyword gives the amount of storage, in bytes, associated with a
variable or a type (including aggregate types).
This keyword returns a value of type size_t.
其返回值类型为size_t,在头文件stddef.h中定义。这是一个依赖于编译系统的值,一
般定义为
typedef unsigned int size_t;
世上编译器林林总总,但作为一个规范,它们都会保证char、signed char和unsigned
char的sizeof值为1,毕竟char是我们编程能用的最小数据类型。
2. 语法:
sizeof有三种语法形式,如下:
1) sizeof( object ); // sizeof( 对象 );
2) sizeof( type_name ); // sizeof( 类型 );
3) sizeof object; // sizeof 对象;
所以,
int i;
sizeof( i ); // ok
sizeof i; // ok
sizeof( int ); // ok
sizeof int; // error
既然写法3可以用写法1代替,为求形式统一以及减少我们大脑的负担,第3种写法,忘
掉它吧!
实际上,sizeof计算对象的大小也是转换成对对象类型的计算,也就是说,同种类型的
不同对象其sizeof值都是一致的。这里,对象可以进一步延伸至表达式,即sizeof可以
对一个表达式求值,编译器根据表达式的最终结果类型来确定大小,一般不会对表达式
进行计算。如:
sizeof( 2 );// 2的类型为int,所以等价于 sizeof( int );
sizeof( 2 + 3.14 ); // 3.14的类型为double,2也会被提升成double类型,所以等价
于 sizeof( double );
sizeof也可以对一个函数调用求值,其结果是函数返回类型的大小,函数并不会被调用
,我们来看一个完整的例子:
char foo()
printf("foo() has been called.\n");
return 'a';
int main()
size_t sz = sizeof( foo() ); // foo() 的返回值类型为char,所以sz = sizeof(
char ),foo()并不会被调用
printf("sizeof( foo() ) = %d\n", sz);
C99标准规定,函数、不能确定类型的表达式以及位域(bit-field)成员不能被计算s
izeof值,即下面这些写法都是错误的:
sizeof( foo );// error
void foo2()
sizeof( foo2() );// error
struct S
unsigned int f1 : 1;
unsigned int f2 : 5;
unsigned int f3 : 12;
;
sizeof( S.f1 );// error
3. sizeof的常量性
sizeof的计算发生在编译时刻,所以它可以被当作常量表达式使用,如:
char ary[ sizeof( int ) * 10 ]; // ok
最新的C99标准规定sizeof也可以在运行时刻进行计算,如下面的程序在Dev-C++中可以
正确执行:
int n;
n = 10; // n动态赋值
char ary[n]; // C99也支持数组的动态定义
printf("%d\n", sizeof(ary)); // ok. 输出10
但在没有完全实现C99标准的编译器中就行不通了,上面的代码在VC6中就通不过编译。
所以我们最好还是认为sizeof是在编译期执行的,这样不会带来错误,让程序的可移植
性强些。
4. 基本数据类型的sizeof
这里的基本数据类型指short、int、long、float、double这样的简单内置数据类型,
由于它们都是和系统相关的,所以在不同的系统下取值可能不同,这务必引起我们的注
意,尽量不要在这方面给自己程序的移植造成麻烦。
一般的,在32位编译环境中,sizeof(int)的取值为4。
5. 指针变量的sizeof
学过数据结构的你应该知道指针是一个很重要的概念,它记录了另一个对象的地址。既
然是来存放地址的,那么它当然等于计算机内部地址总线的宽度。所以在32位计算机中
,一个指针变量的返回值必定是4(注意结果是以字节为单位),可以预计,在将来的6
4位系统中指针变量的sizeof结果为8。
char* pc = "abc";
int* pi;
string* ps;
char** ppc = &pc;
void (*pf)();// 函数指针
sizeof( pc ); // 结果为4
sizeof( pi ); // 结果为4
sizeof( ps ); // 结果为4
sizeof( ppc ); // 结果为4
sizeof( pf );// 结果为4
指针变量的sizeof值与指针所指的对象没有任何关系,正是由于所有的指针变量所占内
存大小相等,所以MFC消息处理函数使用两个参数WPARAM、LPARAM就能传递各种复杂的消
息结构(使用指向结构体的指针)。
6. 数组的sizeof
数组的sizeof值等于数组所占用的内存字节数,如:
char a1[] = "abc";
int a2[3];
sizeof( a1 ); // 结果为4,字符 末尾还存在一个NULL终止符
sizeof( a2 ); // 结果为3*4=12(依赖于int)
一些朋友刚开始时把sizeof当作了求数组元素的个数,现在,你应该知道这是不对的,
那么应该怎么求数组元素的个数呢Easy,通常有下面两种写法:
int c1 = sizeof( a1 ) / sizeof( char ); // 总长度/单个元素的长度
int c2 = sizeof( a1 ) / sizeof( a1[0] ); // 总长度/第一个元素的长度
写到这里,提一问,下面的c3,c4值应该是多少呢
void foo3(char a3[3])
int c3 = sizeof( a3 ); // c3 ==
void foo4(char a4[])
int c4 = sizeof( a4 ); // c4 ==
也许当你试图回答c4的值时已经意识到c3答错了,是的,c3!=3。这里函数参数a3已不
再是数组类型,而是蜕变成指针,相当于char* a3,为什么仔细想想就不难明白,我
们调用函数foo1时,程序会在栈上分配一个大小为3的数组吗不会!数组是“传址”的
,调用者只需将实参的地址传递过去,所以a3自然为指针类型(char*),c3的值也就为
4。
7. 结构体的sizeof
这是初学者问得最多的一个问题,所以这里有必要多费点笔墨。让我们先看一个结构体
:
struct S1
char c;
int i;
;
问sizeof(s1)等于多少聪明的你开始思考了,char占1个字节,int占4个字节,那么
加起来就应该是5。是这样吗你在你机器上试过了吗也许你是对的,但很可能你是错
的!VC6中按默认设置得到的结果为8。
Why为什么受伤的总是我
请不要沮丧,我们来好好琢磨一下sizeof的定义——sizeof的结果等于对象或者类型所
占的内存字节数,好吧,那就让我们来看看S1的内存分配情况:
S1 s1 = 'a', 0xFFFFFFFF ;
定义上面的变量后,加上断点,运行程序,观察s1所在的内存,你发现了什么
以我的VC6.0为例,s1的地址为0x0012FF78,其数据内容如下:
0012FF78: 61 CC CC CC FF FF FF FF
发现了什么怎么中间夹杂了3个字节的CC看看MSDN上的说明:
When applied to a structure type or variable, sizeof returns the actual siz
e, which may include padding bytes inserted for alignment.
原来如此,这就是传说中的字节对齐啊!一个重要的话题出现了。
为什么需要字节对齐计算机组成原理教导我们这样有助于加快计算机的取数速度,否
则就得多花指令周期了。为此,编译器默认会对结构体进行处理(实际上其它地方的数
据变量也是如此),让宽度为2的基本数据类型(short等)都位于能被2整除的地址上,
让宽度为4的基本数据类型(int等)都位于能被4整除的地址上,以此类推。这样,两个
数中间就可能需要加入填充字节,所以整个结构体的sizeof值就增长了。
让我们交换一下S1中char与int的位置:
struct S2
int i;
char c;
;
看看sizeof(S2)的结果为多少,怎么还是8再看看内存,原来成员c后面仍然有3个填
充字节,这又是为什么啊别着急,下面总结规律。
字节对齐的细节和编译器实现相关,但一般而言,满足三个准则:
1) 结构体变量的首地址能够被其最宽基本类型成员的大小所整除;
2) 结构体每个成员相对于结构体首地址的偏移量(offset)都是成员大小的整数倍,
如有需要编译器会在成员之间加上填充字节(internal adding);
3) 结构体的总大小为结构体最宽基本类型成员大小的整数倍,如有需要编译器会在最
末一个成员之后加上填充字节(trailing padding)。
对于上面的准则,有几点需要说明:
1) 前面不是说结构体成员的地址是其大小的整数倍,怎么又说到偏移量了呢因为有
了第1点存在,所以我们就可以只考虑成员的偏移量,这样思考起来简单。想想为什么。
结构体某个成员相对于结构体首地址的偏移量可以通过宏offsetof()来获得,这个宏也
在stddef.h中定义,如下:
#define offsetof(s,m) (size_t)&(((s *)0)->m)
例如,想要获得S2中c的偏移量,方法为
size_t pos = offsetof(S2, c);// pos等于4
2) 基本类型是指前面提到的像char、short、int、float、double这样的内置数据类型
,这里所说的“数据宽度”就是指其sizeof的大小。由于结构体的成员可以是复合类型
,比如另外一个结构体,所以在寻找最宽基本类型成员时,应当包括复合类型成员的子
成员,而不是把复合成员看成是一个整体。但在确定复合类型成员的偏移位置时则是将
复合类型作为整体看待。
这里叙述起来有点拗口,思考起来也有点挠头,还是让我们看看例子吧(具体数值仍以
VC6为例,以后不再说明):
struct S3
char c1;
S1 s;
char c2
;
S1的最宽简单成员的类型为int,S3在考虑最宽简单类型成员时是将S1“打散”看的,
所以S3的最宽简单类型为int,这样,通过S3定义的变量,其存储空间首地址需要被4整
除,整个sizeof(S3)的值也应该被4整除。
c1的偏移量为0,s的偏移量呢这时s是一个整体,它作为结构体变量也满足前面三个
准则,所以其大小为8,偏移量为4,c1与s之间便需要3个填充字节,而c2与s之间就不需
要了,所以c2的偏移量为12,算上c2的大小为13,13是不能被4整除的,这样末尾还得补
上3个填充字节。最后得到sizeof(S3)的值为16。
通过上面的叙述,我们可以得到一个公式:
结构体的大小等于最后一个成员的偏移量加上其大小再加上末尾的填充字节数目,即:
sizeof( struct ) = offsetof( last item ) + sizeof( last item ) + sizeof( tr
ailing padding )
到这里,朋友们应该对结构体的sizeof有了一个全新的认识,但不要高兴得太早,有
一个影响sizeof的重要参量还未被提及,那便是编译器的pack指令。它是用来调整结构
体对齐方式的,不同编译器名称和用法略有不同,VC6中通过#pragma pack实现,也可以
直接修改/Zp编译开关。#pragma pack的基本用法为:#pragma pack( n ),n为字节对齐
数,其取值为1、2、4、8、16,默认是8,如果这个值比结构体成员的sizeof值小,那么
该成员的偏移量应该以此值为准,即是说,结构体成员的偏移量应该取二者的最小值,
公式如下:
offsetof( item ) = min( n, sizeof( item ) )
再看示例:
#pragma pack(push) // 将当前pack设置压栈保存
#pragma pack(2)// 必须在结构体定义之前使用
struct S1
char c;
int i;
;
struct S3
char c1;
S1 s;
char c2
;
#pragma pack(pop) // 恢复先前的pack设置
计算sizeof(S1)时,min(2, sizeof(i))的值为2,所以i的偏移量为2,加上sizeof(i)
等于6,能够被2整除,所以整个S1的大小为6。
同样,对于sizeof(S3),s的偏移量为2,c2的偏移量为8,加上sizeof(c2)等于9,不能
被2整除,添加一个填充字节,所以sizeof(S3)等于10。
现在,朋友们可以轻松的出一口气了,:)
还有一点要注意,“空结构体”(不含数据成员)的大小不为0,而是1。试想一个“不
占空间”的变量如何被取地址、两个不同的“空结构体”变量又如何得以区分呢于是
,“空结构体”变量也得被存储,这样编译器也就只能为其分配一个字节的空间用于占
位了。如下:
struct S5 ;
sizeof( S5 ); // 结果为1
8. 含位域结构体的sizeof
前面已经说过,位域成员不能单独被取sizeof值,我们这里要讨论的是含有位域的结构
体的sizeof,只是考虑到其特殊性而将其专门列了出来。
C99规定int、unsigned int和bool可以作为位域类型,但编译器几乎都对此作了扩展,
允许其它类型类型的存在。
使用位域的主要目的是压缩存储,其大致规则为:
1) 如果相邻位域字段的类型相同,且其位宽之和小于类型的sizeof大小,则后面的字
段将紧邻前一个字段存储,直到不能容纳为止;
2) 如果相邻位域字段的类型相同,但其位宽之和大于类型的sizeof大小,则后面的字
段将从新的存储单元开始,其偏移量为其类型大小的整数倍;
3) 如果相邻的位域字段的类型不同,则各编译器的具体实现有差异,VC6采取不压缩方
式,Dev-C++采取压缩方式;
4) 如果位域字段之间穿插着非位域字段,则不进行压缩;
5) 整个结构体的总大小为最宽基本类型成员大小的整数倍。
还是让我们来看看例子。
示例1:
struct BF1
char f1 : 3;
char f2 : 4;
char f3 : 5;
;
其内存布局为:
|_f1__|__f2__|_|____f3___|____|
|_|_|_|_|_|_|_|_|_|_|_|_|_|_|_|_|
0 3 7 8 1316
位域类型为char,第1个字节仅能容纳下f1和f2,所以f2被压缩到第1个字节中,而f3只
能从下一个字节开始。因此sizeof(BF1)的结果为2。
示例2:
struct BF2
char f1 : 3;
short f2 : 4;
char f3 : 5;
;
由于相邻位域类型不同,在VC6中其sizeof为6,在Dev-C++中为2。
示例3:
struct BF3
char f1 : 3;
char f2;
char f3 : 5;
;
非位域字段穿插在其中,不会产生压缩,在VC6和Dev-C++中得到的大小均为3。
9. 联合体的sizeof
结构体在内存组织上是顺序式的,联合体则是重叠式,各成员共享一段内存,所以整个
联合体的sizeof也就是每个成员sizeof的最大值。结构体的成员也可以是复合类型,这
里,复合类型成员是被作为整体考虑的。
所以,下面例子中,U的sizeof值等于sizeof(s)。
union U
int i;
char c;
S1 s;
;本回答被提问者和网友采纳 参考技术B
sizeof是计算对象所占的字节个数,通常用来查看变量或结构体等所占的字节个数。
比如:
int a;sizeof(a); // 计算变量a所占的字节数,等价于sizeof(int)
struct
int num;
char name[];
int age;
person;
sizeof(person); // 计算整个结构所占的字节总数 参考技术C C语言中的sizeof是一个很有意思的关键字,经常有人用不对,搞不清不是什么。我以前也有用错的时候,现在写一写,也算是提醒一下自己吧。反正现在来看,还在搞sizeof是什么意思,怎么用正确,还是有点搞笑,都经常用的东西,没有理解透彻,就差的太远了。
一 sizeof是什么
sizeof是C语言的一种单目操作符,如C语言的其他操作符++、--等,sizeof操作符以字节形式给出了其操作数的存储大小。操作数可以是一个表达式或括在括号内的类型名。这个操作数不好理解对吧?后面慢慢看就明白了。sizeof的返回值是size_t,在64位机器下,被定义为long unsigned int。
二 sizeof如何使用
1、用于数据类型
使用形式: sizeof(type)。其中type如int 、double等。 例如sizeof(int)、sizeof(char*)、sizeof(double)。这个时候sizeof后面的类型必须用括号()包起来,不包起来是错误的,通过不了编译。其中sizeof(void*)在64位下是8,而sizeof(void)是1。其实,在C语言中sizeof(函数),
如sizeof(main),结果也是1。但是在C++中,sizeof(void)和sizeof(函数)都是非法的,通过不了编译,后面C++就不说了,现在讲C嘛。其实sizeof(函数),sizeof(void)虽然是1,但是是不正确的使用方式。
2、用于变量
使用形式: sizeof(var)或sizeof var。当操作基本数据类型的时候,在我64位电脑的结果如下
作用是:计算常量、变量、数据类型 在内存中占用的字节数
三、用sizeof计算常量在内存中占用的字节数
sizeof(1) 计算常量 1 在内存中占用的字节数 4
1 默认的事一个10进制的整数(int) 4
sizeof(2.3f); 计算 float类型的常量在内存中占用的字节数 4
sizeof(2.3); 计算 double 类型的常量在内存中占用的字节数 8
sizeof('a'); 计算 'a' 字符常量 在内存中占用的字节数 1 4? 参考技术D sizeof()
()内加一个字符串或一个字符串数组
这样运算结果就是这个字符串的长度
以上是关于求教c语言中fgets的用法的主要内容,如果未能解决你的问题,请参考以下文章