分布式共识算法随笔 —— 从 Quorum 到 Paxos
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式共识算法随笔 —— 从 Quorum 到 Paxos相关的知识,希望对你有一定的参考价值。
分布式共识算法随笔 —— 从 Quorum 到 Paxos
概览: 为什么需要共识算法?
复制(Replication) 是一种通过将同一份数据在复制在多个服务器上来提高系统可用性和扩展写吞吐的策略, 。常见的复制策略有主从架构(Leader/Follower), 多主架构(Multi-Leader) 和 无主架构(LeaderLess)[1]。在无主架构模式下,需要保证多个节点写入数据的一致(即共识(consensus))。如, 某个无主架构包含 Server1, Server2, Server3 三个服务器, 当前状态为 x=nil,并发同时向他们分别发起 x=1, x=2, x=3 请求,最终一定会得到一个确定的值(而不会产生分歧)。这个值可以是写入成功的 x=1, x=2 或 x=3,也可以是未发起写入操作前的 x=nil。

状态机(State Machine) 常用于维护不同服务器之间的数据同步状态[2]。只要保证各个服务器之间的状态机状态一致,则它们的数据集就是一样的。状态机通常由 Write-Ahead-Log(WAL 日志) 实现,这些日志记录了一系列有序的命令。每个服务器将会按照 WAL 日志的内容,按序执行这些命令。
因此, 只要这些服务器的 WAL 日志保持一致,则它们最终的状态机就是一致的,那么他们最终的数据集也就是一致的。通常, WAL 日志一旦写入,都是不可变的。因为一旦 WAL 写入, 很可能它已经应用到了状态机。如果要变更该日志, 意味着需要从状态机内回滚该操作。而回滚这一条 WAL 日志的操作,很可能需要先将后续的 WAL 日志都回滚, 这样的成本往往是很高的。(如果引入了共识模块, 情况将会变得更加糟糕。)
通过在每个服务器加入实现 WAL 日志保持一致性的共识模块(Consensus Module),我们就可以让所有的服务器的数据保持一致。各个服务器的共识模块通过和其他服务器的共识模块之间的通信,对并发写入的数据达成共识,确保最终写入的 WAL 日志顺序和命令(日志内容)都是一样的[3][4] 。下图出自参考文献[4] (本文未注明来源的图均为原创)。

为了保证所有的 WAL 日志的顺序和日志内容都是一样的,共识模块只需要依次对单个日志 ID(有的地方也被称为日志槽(Log Slot)[5]) 达成共识, 最终就会使得整个 WAL 日志都是达成共识的, 从而使得所有服务器的整个数据集都是一致的。
如下图, server1 和 server3 在第五条 WAL 日志处, 同时分别发起 x=3 和 y=2 的写操作。共识模块就“第五条WAL日志是什么”发起协商,最终的共识可以是 “第五条WAL日志是 x=3”, “第五条WAL日志是 y=2” 或“第五条WAL日志未达成一致, 依旧可以写入新值” 。图中, 共识算法选择了 “y=2” 作为第五条 WAL 日志,这一条日志将不再被允许更改。后续各个服务器会使用单共识算法依次对第六条 第七条…日志的命令日志达成共识, 最终实现整个服务器的数据集都达成共识。

对单个数据达成共识并且不再允许更改的共识算法称之为单共识算法(Single Consensus Algorithm), 如上图中, 对“第五条WAL日志是什么”发起的共识算法。而分别对每个日志ID执行单共识算法的算法称之为多共识算法(Multi-Consensus Algorithm), 该算法通过简单地重复单共识算法实现对整个 WAL 日志的共识,从而实现所有服务器数据集的共识。(Single Consensus 和 Multi-Consensu 是我通过 paxos 和 multi-paxos [6] [7]推广而来。这不一定准确, 因此你只需要记得它们的对应关系即可)
因为多共识算法约等于多个单共识算法的集合, 因此本文后续仅重点介绍单共识算法。
在进入各种共识算法的介绍之前,我们还得了解下单共识算法的安全属性,这样才能明确我们需要达到的目标(系统需要始终保证其安全属性始终满足)。安全属性(Safety Property) 是指约束系统状态, 在系统运行中, 限制一些不可逆转的不好的事情发生(nothing bad happens)的属性。在系统正常运行过程中,需要始终保证满足安全属性。正式的定义可参考 [1] [8]。
根据上述内容, 我们可以简单地梳理出单共识算法需要满足的 Safety Property:
- 只有客户端提交的数据才能被服务端达成共识而选中。(防止异常数据产生)
- 当多个客户端并发写入时, 只能有一个 value 能被服务端选中。某个 value 一旦被服务端达成共识而选中, 它将不可被更改。(确保选中数据不会冲突, 不能被更改)
- 读请求只能“看见”服务端达成共识的 value。(防止脏读等情况)
探索: 单共识算法的可能性
从 Quorum 算法聊起
Quorum 算法的基本思想是: 假如有 n 个服务器, 每次写请求至少保证 w 个服务器写入成功, 每次读请求至少保证 r 个服务器返回成功。根据鸽巢原理, 只要保证 w + r > n, 则我们一定能读到最新的数据 。[1][9], 下图引用自参考文献 [1]

简单起见, 下面都令 w = r = ⌊n⌋ + 1, 即读写都至少保证大部分服务器返回成功, 才认为操作成功。
-
时间戳(timestamp) 为了区分 r 个服务器返回的数据谁的版本最新, 我们需要定义数据写入的时间戳, 以区分数据的写入顺序。定义时间戳
timestamp := <clientID, version>。其中, clientID 表示发起该写请求的客户端的 ID。版本号 version 表示该数据(预期)在服务器中的版本号。 timestamp 的比较算法如下:
-
写请求流程
- 客户端(ID 记为 clientID)向服务端广播 get version 请求获取最新的版本号 version。
- 当大多数服务端已返回, 记它们的最大版本号为 latest_version。客户端发起写入请求 x=a, 请求的时间戳为 <clientID, latest_version+1>。
- 服务端接收到写请求后,比较上次写入操作的时间戳 last_timestamp 和本次写请求的时间戳 timestamp:
- 如果 last_timestamp 小于 timestamp,, 则执行写操作(在当前服务器写入 x=a, 令 last_timestamp = timestamp), 并向客户端返回“操作执行成功, 当前版本号为 timestamp.version, 当前 x 的值为 a”。
- 否则, 向客户端返回“执行失败,当前版本号为 last_timestamp.version, 当前 x 的值”
- 客户端接受到大部分服务端返回执行成功, 则该写请求已执行成功(服务端已达成共识)。
- 否则:
- 如果大多数服务端返回 x 的当前值为 a 或 nil(因为 timestamp 过期导致写入操作失败), 则令版本号为返回版本号的最大值加一, 并再次发起 x=a 的写请求操作(回到第 2 步)。
- 否则, 数据冲突, 写入失败。
下图展示了客户端 C1, C2 同时向服务端 S1, S2, S3 发起写请求的场景。其中, C1 发起写操作 x = 1, C2 发起写操作 x = 2。最终服务端达成共识,成功写入 x = 2。

- 读请求流程
- 客户端向服务端广播读请求
- 当大多数服务端已返回数据, 将 timestamp 最新的数据作为最终结果返回。
下图展示了客户端 C1 同时向服务端 S1, S2, S3 发起读请求, C2 发起 x=2 的写请求的场景。C1 最终读取到的数据为 x = 2。

- Corner Case: 如下图,客户端 C1, C2 同时向服务端 S1, S2, S3 发起写请求的场景。其中, C1 发起写操作 x = 1, C2 发起写操作 x = 2。
- 图中点 A 时刻到点 D 时刻之间,用户读取到的数据可能是 x=2(用户读取 S1,S2 或 S1,S3),也可能是 x=nil(用户读取 S2, S3)。这违背了第三条 Safety Property(只有被选中的 value 才能被 “看见”)。
- 图中点 D 时刻到点 B 时刻之间, 用户可能读取到 x=2(用户读取 S1,S2 或 S1,S3),或 x=1(用户读取 S2, S3)。这同样违背了第三条 Safety Property。
- 点 B 时刻到点 C 时刻之间, 用户读到的数据为 x=1。但在点 C 时刻之后, 用户读到的数据却变为了 x=2。而这两个数据均是服务端达成的共识(值唯一),因此, 违背了第二条 Safety Property(只能有一个 value 能被服务端选中。某个 value 一旦被服务端达成共识而选中, 它将不可被更)。

- Corner Case 的处理
-
点 A 时刻到点 D 时刻之间: 将读操作逻辑以大多数server返回的值为最终的结果值(而不是 latest version 的 value)。这样在 A->D 读到的数据为 (2, nil, nil), 大多数的值为 nil, 因此结果始终为 nil。(x = 2 并未达成共识, 因此无法被读取)。
-
点 D 时刻到点 B 时刻之间: 服务端在每次接收到 get version 操作后, 都将自身的 version 加一并返回, 同时限制过期的 version 的写入。(仅接受 version 号和自身相同的 write 请求)。但这么一来就会出现图中 S3 先接受了 C1 的写请求(x=1), 再接收到 C2 的 get version 请求。而 S1, S2 则正好相反的情况。这种情况下, 可能会出现下图的点 D 时刻到点 C 时刻之间, 业务读取到的数据为 (2, nil, 1), 不存在大多数派的数据, 服务端未达成共识, 可以认为当前的共识为 x=nil。

-
点 B 时刻到点 C 时刻之间(x=1)以及点 C 时刻之后(x=2): 2 的解决方案, 同时也能解决该问题。
以上处理 Corner Case 的逻辑已经可以管中窥豹,看到一些 paxos 算法的雏形了。我们先按下不表,先看下如何改造 两阶段提交(2PC) 算法实现单一致性算法。
改造 2PC(Two Phase Commit) 算法
2PC(Two-Phase Commit) 是一种用于解决多个服务器如何就同一分布式事务达成一致的方法。在 2PC 中,多个服务器分别处理用于执行同一个写入操作的不同子请求(比如某个写请求需要处理不同服务器上的 partition 的数据)。它们必须同时成功地将写入提交(committed),否则就会同时失败并回滚(aborted)。[1] [14]
我们可以将同一个写请求通过 2PC 实现的事务在不同的服务器上执行一遍,实现 replication 功能。该方式能够保证不同服务器上的数据要么同时写入, 要么同时回滚,从而使得服务器间对该数据达成共识。
用上述方式实现的共识算法虽然扩展了服务器的读性能, 但是一旦某个服务器崩溃,所有的写请求都会失败(2PC 需要保证所有的服务器都执行成功)。这将导致集群的可用性大幅降低。
为了提高集群的可用性,我们引入上文的 Quorum 算法改造 2PC 算法,以实现读性能高可用的同步扩展。
2PC 算法有两个角色,一个是发起事务操作的客户端 TM(transaction manager), 一个是处理事务的服务器 RM(resource manager)。 2PC 单一致性算法保证 TM 提交的写操作在 RM 集群达成共识。
- 写请求流程
- TM 将写请求的 prepare 消息广播给各个 RM。
- RM 接收到 prepare 请求后(相当于加了写锁),
- RM 前处于 preparing 状态,且 prepare 请求和 RM 中 preparing 的请求不一致,则请求冲突,返回 prepare 失败。
- 当前已有提交的值,且 prepare 请求写入的值和 RM 中已提交的值不一致,则请求冲突,返回 prepare 失败。
- 否则, 保存 prepare 信息, 将 RM 状态置为 preparing, 返回 prepare 成功。
- 当TM 接收到大多数 RM 返回 prepare 失败,则向 RM 广播 abort 消息,写操作执行失败。 若大多数 RM 都返回 prepare 执行成功, 则向所有 RM 广播 commit 操作。写操作执行成功。
- RM 接收到 commit 请求后,写入数据,并将 RM 恢复初始状态。
- RM 接受到 abort 请求后,并将 RM 恢复初始状态。
下图展示了 TM1, TM2 并发发起写操作, TM1 写入成功, 而 TM2 回滚的场景。

- 读操作流程
- TM 向 RM 广播读请求
- 当大多数 RM 返回数据作为最终结果返回,如果不存在多数派数据, 则表示 RM 并未达成共识, 返回 nil。
下图展示了 TM1 发起写操作 x=1, TM2 同时发起读操作 read x 的场景。TM2 最终读取到的数据为 x=1。

- Corner Case
-
上图中, 如果 TM1 在点 A 时刻到点 B 时刻崩溃,其他 TM 虽然可以处理其他 key 的数据,但是 x 已经处于 prepare x=1 状态,其他 TM 只能发起 x=1 操作(而不能做其他处理)。如下图,TM2 发起 x=2 写操作失败,但是它发起 x=1 写操作成功。

-
如下图,如果存在三个 TM 对一个相同的 key 分别在三个不同的 RM prepare 了不同的 value, 则这个 key 将永远无法达成一致。

- Corner Case 的处理
- 点 A 时刻到点 B 时刻 TM1 崩溃: 后续的 prepare 可以覆盖前面的 prepare,但是需要通过 timestamp 来确定**因果顺序(casual order)**。
- Corner Case 2 也可由 Corner Case 1 的解决方案解决处理。
解密: paxos 算法“略解”
paxos 算法共有两个角色: 负责发起写请求的 proposer 和负责达成共识的 acceptor。[5] [6] [7] [10] [11]
- 写操作流程
- proposer 指定一个 proposal number n, 向所有 acceptor 广播 prepare(n, key) 请求。其中 proposal number 的定义与 Quorum 算法提到的 timestamp 一致。
- acceptor 会将当前接收到的最大的 proposal number 记作 promise_number, acceptor 将会拒绝接受所有小于 promise_number 的 propose/prepare 请求。
- acceptor 接收到 prepare(n,key) 请求后, 如果 promise_numver < n, 则令 promise_number = n。向 proposer 返回当前 acceptor 已接收的 proposal number 和 value, promise_number。
- 当大多数 acceptor 都已成功接受 prepare 请求(promise_number = proposal_number):
- 如果响应均没有返回 accept proposal,则 proposer 发起 propose(n, key, value) 请求。
- 否则,令 value 等于响应中 accepted proposal number 最大的 accepted proposal value ,并发起 propose(n, key, value) 请求。
- 如果大多数 acceptor 都已拒绝 prepare 请求(promise_number > proposal_number),则令 n.version 等于 acceptor 返回的最大的 promise_number.version+1, 再次发起 prepare(n) 请求。
- 响应 propose(n, key, value) 请求:
- 如果 acceptor 的 promise_number 小于等于 n,则接受该值, 并且将 promise_number 置为 n,返回 promise_number
- 否则, 拒绝该 propose。返回 promise_number。
- 如果大多数已返回,且大多数 propose 被拒绝, 则令 n.version 等于 acceptor 返回的最大的 promise_number.version+1, 再次发起 prepare(n) 请求。否则, 大多数返回的 promise number 和 prepare 一致,value 已经写入成功。

-
读操作流程: 与上一部分 2PC 的读操作流程一致。
-
live lock: paxos 算法在 prepare 阶段很容易出现 live lock 的情况,如图 Proposer1 和 Proposer2 反复的刷新 promise_number, 却谁都无法抢占先机。 一般有两种处理手段: 其一, Proposer 利用选主算法(可以是一次 paxos)+lease策略, 让集群中始终只有一个 Proposer 处于激活状态[11] [13]。其二, 每次可以随机等待一段时间, 再重试, 减少冲突发生的概率。[4]

附录: 伪代码
Quorum
-
写请求

-
写响应

-
读请求

2PC(Two Phase Commit)
-
写请求

-
写响应

-
读请求

Paxos
-
写请求

-
写响应

-
读请求

参考文献
- [0] 本文所有绘图均使用 draw.io 绘制
- [1] Designing Data-Intensive Applications - by Martin Kleppmann
- [2] Implementing fault-tolerant services using the state machine approach: a tutorial
- [3] In Search of an Understandable Consensus Algorithm(Extended Version)
- [4] CONSENSUS: BRIDGING THEORY AND PRACTICE
- [5] Paxos Made Moderately Complex
- [6] Paxos Made Live - An Engineering Perspective
- [7] The Part-Time Parliament
- [8] DEFINING LIVENESS - Bowen ALPERN and Fred B. SCHNEIDER
- [9] Quorum Consensus - web.mit.edu/6.033
- [10] Paxos lecture (Raft user study)
- [11] Paxos Made Simple
- [12] How to Build a Highly Available System Using Consensus
- [13] Leases: An Efficient Fault-Tolerant Mechanism for Distributed File Cache Consistency
- [14] Consensus on Transaction Commit
共识专栏Quorum机制与PBFT
实用性拜占庭容错算法(Practical Byzantine Fault Tolerance,PBFT),是一种在信道可靠的情况下解决拜占庭将军问题的实用方法。拜占庭将军问题最早由Leslie Lamport等人在1982年发表的论文[1]提出,论文中证明了在将军总数n大于3f,背叛者为f或者更少时,忠诚的将军可以达成命令上的一致,即3f+1<=n,算法复杂度为O(n^(f+1))。随后Miguel Castro和Barbara Liskov在1999年发表的论文[2]中首次提出PBFT算法,该算法容错数量也满足3f+1<=n,算法复杂度降低到了O(n^2)。
如果对于PBFT共识算法有所了解,对节点总数n与容错上限f的关系可能会比较熟悉:在系统内最多存在f个错误节点的前提下,系统内总节点数量n应该满足n>3f,在推进共识过程中则需要收集一定数目的投票,才能完成认证过程。在本节当中,我们将首先讨论这些数值间关系该如何得出。
--Quorum机制--
在有冗余数据的分布式存储系统当中,冗余数据对象会在不同的机器之间存放多份拷贝。但是在同一时刻,一个数据对象的多份拷贝只能用于读或者写。为了保持数据冗余与一致性,需要对应的投票机制进行维持,这就是Quorum机制。区块链作为一种分布式系统,同样也需要该机制进行集群维护。
为了更好地理解Quorum机制,我们先来了解一种与之类似,但是更加极端的投票机制——WARO机制(Write All Read One)。使用WARO机制维护节点总数为n的集群时,节点执行写操作的“票数”应当为n,而读操作时的“票数”可以设置为1。也就是说,在执行写入时,需要保证全部节点完成写入操作才可视该操作为完成,否则会写入失败;相应地,在执行读操作时,只需要读取一个节点的状态,就可以对该系统状态进行确认。可以看到,在使用WARO机制的集群中,写操作的执行非常脆弱:只要有一个节点执行写入失败,那么这次操作就无法完成。不过,虽然牺牲了写操作健壮性,但是,在WARO机制下,对于该集群执行读操作会非常容易。
Quorum机制[3]就是对读写操作的折衷考虑,对于同一份数据对象的每一份拷贝,不会被超过两个访问对象读写,并且权衡读写时的集合大小要求。在一个分布式集群当中,每一份数据拷贝对象都被赋予了一票。假设:
-
系统中有V票,这就意味着一个数据对象有V份冗余拷贝;
-
对于每一个读操作,获得的票数必须不小于最小读票数R(read quorum)才可以成功读取;
-
对于每个写操作,获得的票数必须不小于最小写票数W(write quorum)才可以成功写入。
此时,为了维持集群一致性,V、R、W应满足不等关系,R+W>V且W>V/2。其中,R+W>V保证了一个数据不会被同时读或写。当一个写操作请求传入,它必须要获得W票,而剩下的数量是V-W不足R,因此不会再处理读请求。同理,当读请求已经获得了R票,写请求就无法被处理。W>V/2,保证了数据的串行修改,也就是说,一份数据的冗余拷贝不可能同时被两个写请求修改。
对于集群中的共识节点,在推进共识算法时,参与共识的节点会同时对集群进行读写操作。为了平衡读写操作对于集合大小的要求,每个节点的R与W取同样大小,记为Q。当集群中总共存在n个节点,并且其中最多出现f个错误节点的情况下,我们该如何计算n、f、Q之间的关系呢?接下来,我们将从最简单的CFT场景出发,逐步探索如何在BFT场景中得到这些数值取值之间的关系。
▲CFT
CFT(Crash Fault Tolerance),表示系统中的节点只会出现宕机(Crash)这种错误行为,任何节点不会主动发出错误消息。当我们在讨论共识算法可靠性时,通常会关注算法两种基本性质:活性(liveness)与安全性(safety)。在计算Q的大小时,同样也可以从这两个角度出发进行考虑。
对于活性与安全性,有一种比较直观的描述方式:
-
something eventually happens[4],某个事件最终会发生
-
something good eventually happens[4],这个最终会发生的事件合理
从活性角度出发,我们的集群需要能够持续运行下去,不会由于某些节点的错误导致无法继续共识。从安全性角度出发,我们的集群在共识推进的过程中,能够持续获得某个合理的结果,对于分布式系统来说,这种“合理”的结果,其最基本的要求就是集群整体状态的一致性。
于是,在CFT场景下,对于Q数值的确定就变得简单明确:
-
活性:由于我们需要保证集群能够持续运行,所以,在任何场景下都要保证有获取到Q票的可能性,从而为集合读写数据。由于集群中最多会有f个节点发生宕机,所以为了保证能获取到Q票,该值的大小需要满足:Q<=n-f。
-
安全性:由于我们需要保证集群不发生分歧,所以,按照Quorum机制的基本要求,需要满足在上一节当中提到的两个不等式,将Q作为最小读集合与最小写集合带入该组不等式,此时,Q满足不等关系,Q+Q>n且Q>n/2,因此,该值的大小需要满足:Q>n/2。
▲BFT
BFT(Byzantine Fault Tolerance),表示集群中的错误节点不仅可能会发生宕机,也可能存在恶意行为,即拜占庭(Byzantine)行为,例如主动进行状态分叉。在这种情况下,对于集群整体而言,只有n-f个节点的状态可靠,当我们收集到Q个投票时,其中也只有Q-f个投票来自可靠的节点。因此,在安全性方面,BFT场景下需要保证状态可靠的节点之间不会发生分歧,因此得到以下两种关系:
-
活性:依然只需要保证每时每刻都有获取Q票的可能性,因此,Q<=n-f。
-
安全性:对于全部保证正确的节点(总数n-f)不会发生分歧,此时,应当满足不等关系,(Q-f)+(Q-f)>n-f且(Q-f)>(n-f)/2,因此,此时Q的大小需要满足的关系为,Q>(n+f)/2。
▲节点总数与容错上限
对于节点总数n与容错上限f,在PBFT论文当中给出的解释[1]:由于存在f个节点可能发生宕机,因此我们至少需要在收到n-f条消息时进行响应,而对于我们收到的来自n-f个节点的消息,由于其中最多可能存在f条消息来自于不可靠的拜占庭节点,因此需要满足n-f-f>f,所以,n>3f。
简单来说,PBFT的作者从集群活性与安全性出发,得到了节点总数与容错上限之间的关系。上一节中,我们也是从活性与安全性角度,获得了n、f与Q的关系,在这里也可以用来推导n与f的关系:为了同时满足活性与安全性的要求,Q需要满足不等关系,Q<=n-f且Q>(n+f)/2,因此,可以得到n与f之间的不等关系,(n+f)/2<n-f,也就是n>3f。
(通过类似的方式,也可以得到CFT场景中n与f的关系,n>2f。)
--PBFT与RBFT --
在理解BFT场景中n、f、Q的关系后,接下来进入到PBFT的介绍。在此之前,简单提一下SMR(State Machine Replication)复制状态机[5]。在该模型当中,对于不同的状态机,如果从同样的初始状态出发,按照同样的顺序输入同样的指令集,那么它们得到的最终结果总会一致。对于共识算法而言,其只需要保证“按照同样的顺序输入同样的指令”,即可在各个状态机上获得同样的状态。而PBFT就是对指令执行顺序的共识。
那么,PBFT是如何保证指令执行顺序的一致性呢?PBFT集群为主从结构,由主节点提出提案,并通过集群中各个节点间的交互进行验证,从而使得每个正确节点遵循同样的顺序对指令集进行执行。在这个交互过程中,就需要使用Quorum机制保证集群整体状态的一致性。下面我们将对PBFT进行详细介绍。
▲两阶段共识
相比较常见的“三阶段“概念(pre-preapre、prepare、commit),将PBFT视为一种两阶段共识协议或许更能体现每个阶段的目的:提案阶段(pre-prepare与prepare)和提交阶段(commit)。在每个阶段中,各个节点都需要收集来自Q个节点一致的投票后,才会进入到下一个阶段。为了更方便讨论,这里将讨论节点总数为3f+1时的场景,此时,读写集票数Q为2f+1。
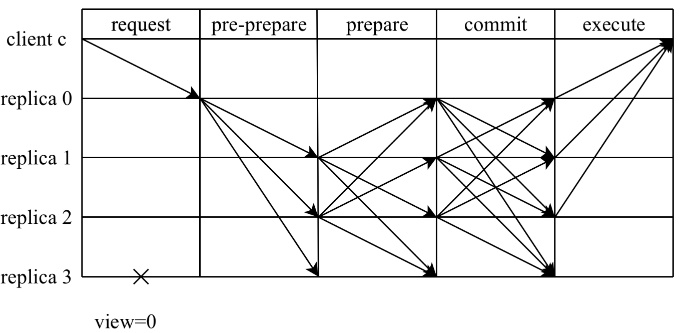
1) 提案阶段
在该阶段中,由主节点发送pre-prepare发起共识,由从节点发送prepare对主节点的提案进行确认。主节点在收到客户端的请求后,会主动向其它节点广播pre-prepare消息<pre-prepare, v, n, D(m)>
-
v为当前视图
-
n为主节点分配的请求序号
-
D(m)为消息摘要
-
m为消息本身
从节点在收到pre-prepare消息之后,会对该消息进行合法性验证,若通过验证,那么该节点就会进入pre-prepared状态,表示该请求在从节点处通过合法性验证。否则,从节点会拒绝该请求,并触发视图切换流程。当从节点进入到pre-prepared状态后,会向其它节点广播prepare消息<prepare, v, n, D(m), i>,
-
i为当前节点标识序号
其他节点收到消息后,如果该请求已经在当前节点进入pre-prepared状态,并且收到2f条来自不同节点对应的prepare消息(包含自身),从而进入到prepared状态,提案阶段完成。此时,有2f+1个节点认可将序号n分配给消息m,这就意味着,该共识集群已经将序号n分配给消息m。
2) 提交阶段
当请求在当前节点进入prepared状态后,本节点会向其它节点广播commit消息<commit, v, n, i>。如果该请求已经在当前节点达到prepared状态,并且收到2f+1条来自不同节点对应的commit消息(包含自身),那么该请求就会进入到committed状态,并可以进行执行。此时,有2f+1个节点已经得知共识集群已经将序号n分配给消息m。执行完毕后,节点会将执行结果反馈给客户端进行后续判断。
▲检查点机制
PBFT共识算法在运行过程中,会产生大量的共识数据,因此需要执行合理的垃圾回收机制,及时清理多余的共识数据。为了达成这个目的,PBFT算法设计了checkpoint流程,用于进行垃圾回收。
checkpoint即检查点,这是检查集群是否进入稳定状态的流程。在进行检查时,节点广播checkpoint消息<checkpoint, n, d, i>
-
n为当前请求序号
-
d为消息执行后获得的摘要
-
i为当前节点表示
当节点收到来自不同节点的2f+1条有相同<n,d>的checkpoint消息后,即可认为,当前集群对于序号n进入了稳定检查点(stable checkpoint)。此时,将不再需要stable checkpoint之前的共识数据,可以对其进行清理。不过,如果为了进行垃圾回收而频繁执行checkpoint,那么将会对系统运行带来明显负担。所以,PBFT为checkpoint流程设计了执行间隔,设定每执行k个请求后,节点就主动发起一次checkpoint,来获取最新的stable checkpoint。
除此之外,PBFT引入了高低水位(high/low watermarks)的概念,用于辅助进行垃圾回收。在共识进行的过程中,由于节点之间的性能差距,可能会出现节点间运行速率差异过大的情况。部分节点执行的序号可能会领先于其他节点,导致于领先节点的共识数据长时间得不到清理,造成内存占用过大的问题,而高低水位的作用就是对集群整体的运行速率进行限制,从而限制了节点的共识数据大小。
高低水位系统中,低水位记为h,通常指的是最近一次的stable checkpoint对应的高度。高水位记为H,计算方式为H=h+L,L代表了共识缓存数据的最大限度,通常为checkpoint间隔K的整数倍。当节点产生的checkpoint达到到stable checkpoint状态时,节点将更新低水位h。在执行到最高水位H时,如果低水位h没有被更新,节点会暂停执行序号更大的请求,等待其他节点的执行,待低水位h更新后重新开始执行更大序号的请求。
▲视图变更
当主节点超时无响应或者从节点集体认为主节点是问题节点时,就会触发视图变更(view-change)。视图变更完成后,视图编号将会加1,随之主节点也会切换到下一个节点。如图所示,节点0发生异常触发视图变更流程,变更完成后,节点1成为新的主节点。

当视图变更发生时,节点会主动进入到新视图v+1中,并广播view-change消息,请求进行主节点切换。此时,共识集群需要保证,在旧视图中已经完成共识的请求能够在新视图中得到保留。因此,在视图变更请求中,一般需要附加部分旧视图中的共识日志,节点广播的请求为<viewchange, v+1, h, C, P, Q, i>
-
i为发送者节点的身份标识
-
v+1表示请求进入的新视图
-
h为当前节点最近一次的稳定检查点的高度
-
C:当前节点已经执行过的检查点的集合,数据按照<n,d>的方式进行存储,表示当前节点已经执行过序号为n摘要为d的checkpoint检查,并发送过相应的共识消息。
-
P:在当前节点已经达成prepared状态的请求的集合,即,当前节点已经针对该请求收到了1条pre-prepare消息与2f条prepare消息。在集合P中,数据按照<n,d,v>的方式进行存储,表示在视图v中,摘要为d序号为n的请求已经进入了prepared状态。由于请求已经达成了prepared状态,说明至少有2f+1个节点拥有并且认可该请求,只差commit阶段即可完成一致性确认,因此,在新的视图中,这一部分消息可以直接使用原本的序号,无需分配新序号。
-
Q:在当前节点已经达成pre-prepared状态的请求的集合,即,当前节点已经针对该请求发送过对应的pre-prepare或prepare消息。在集合Q中,数据同样按照<n,d,v>的方式进行存储。由于请求已经进入pre-prepared状态,表示该请求已经被当前节点认可。
但是,视图v+1对应的新主节点P在收到其他节点发送的view-change消息后,无法确认view-change消息是否拜占庭节点发出的,也就无法保证一定使用正确的消息进行决策。PBFT通过view-change-ack消息让所有节点对所有它收到的view-change消息进行检查和确认,然后将确认的结果发送给P。主节点P统计view-change-ack消息,可以辨别哪些view-change是正确的,哪些是拜占庭节点发出的。
节点在对view-change消息进行确认时,会对其中的P、Q集合进行检查,要求集合中的请求消息小于等于视图v,若满足要求,就会发送view-change-ack消息<viewchange-ack, v+1, i, j, d>
-
i为发送ack消息的节点标识
-
j为要确认的view-change消息的发送者标识
-
d为要确认的view-change消息的摘要
不同于一般消息的广播,这里不再使用数字签名标识消息的发送方,而是采用会话密钥保证当前节点与主节点通信的可信,从而帮助主节点判定view-change消息的可信性。
新的主节点P维护了一个集合S,用来存放验证正确的view-change消息。当P获取到一条view-change消息以及合计2f-1条对应的view-change-ack消息时,就会将这条view-change消息加入到集合S。当集合S的大小达到2f+1时,证明有足够多的非拜占庭节点发起视图变更。主节点P会按照收到的view-change消息,产生new-view消息并广播,<new-view, v+1, V, X>
-
V:视图变更验证集合,按照<i,d>的方式进行存储,表示节点i发送的view-change消息摘要为d,均与集合S中的消息相对应,其他节点可以使用该集合中的摘要以及节点标识,确认本次视图变更的合法性。
-
X:包含稳定检查点以及选入新视图的请求。新的主节点P会按照集合中S的view-change消息进行计算,根据其中的C、P、Q集合,确定最大稳定检查点以及需要保留到新视图中的请求,并将其写入集合X中,具体选定过程相对繁琐,如果有兴趣,读者可以参阅原始论文[6]。
▲改进空间与RBFT
RBFT(Robust Byzantine Fault Tolerance),是趣链科技基于PBFT为企业级联盟链平台研发的高鲁棒性共识算法。相比较PBFT来说,我们在共识消息处理、节点状态恢复、集群动态维护等多方面进行了优化改良,使得RBFT共识算法能够应对更复杂多样的实际场景。
1) 交易池
包括RBFT在内,许多共识算法的工业实现中,都设计了独立的交易池模块。在收到交易后,将交易本身存放在交易池里,并通过交易池对交易进行共享,使得各个共识节点都能获得共享的交易。在共识的过程中,只需对交易哈希进行共识即可。
在处理较大交易时,交易池对于共识的稳定性有不错的提升。将交易池与共识算法本身进行解耦,也更方便通过交易池实现更多的功能特性,比如交易去重。
2) 主动恢复
在PBFT中,当节点借由checkpoint或view-change发现自身的低水位落后,即稳定检查点落后时,落后节点就会触发相应的恢复过程,以拉取该稳定检查点之前的数据。这样的落后恢复机制有一些不足:一方面,该恢复流程的触发是被动的,需要在checkpoint过程或者触发view-change完成时才能触发落后恢复;另一方面,对于落后节点来说,如果通过checkpoint发现自身稳定检查点落后时,落后节点只能恢复到最新的稳定检查点,而无法获得该检查点后落后的共识消息,可能一直无法真正参与到共识当中。
在RBFT中,我们设计了主动的节点恢复机制:一方面,该恢复机制可以主动触发,更快地帮助落后节点进行恢复;另一方面,在恢复到最新的稳定检查点基础之上,我们设计了水位间的恢复机制,从而使得落后节点能够获取到最新的共识消息,更快地参与到正常共识流程。
3) 集群动态维护
Raft作为一种广泛应用在工程中的共识算法,其重要优势之一,就是能够动态完成集群成员变更。而PBFT没有给出集群成员动态变更方案,在实际应用中存在不足。在RBFT中,我们设计了一种动态变更集群成员的方案,使得不需要停启集群整体的情况下,就可以对集群成员进行增删。
新增或删除节点时,由管理员向集群发交易创建操作节点的提案,并等待其他管理员投票,投票通过后由创建提案的管理员再次向集群发执行提案配置交易,执行时会更改集群配置。
对于共识部分,当处理执行提案配置交易时,集群中的节点将进入配置变更状态,不再打包其他交易。主节点将该交易单独打包生成配置包,并对该配置包进行共识。当该配置包完成共识,它将被执行并生成配置区块。为了保证改配置区块不可回滚,共识层将等待改配置包的执行结果,确定集群中已经对于该配置包所在高度形成稳定检查点,才会解除节点的配置状态,继续进行其他交易的打包。
对于集群不同的配置状态,我们通过世代(epoch)进行区分。不同世代拥有其独立的编号,该编号为单调递增的,每次执行完成一笔执行提案配置交易,将会对世代编号进行更新。对于集群中不同的节点,如果它们处于同一个世代下,则可以进行正常的信息交互。否则,节点之间只能进行状态恢复相关消息的交互。由于配置变更的信息已经被写入链上,因此,我们可以通过直接同步区块的方式为落后节点进行配置更新。通过上一节所说的主动恢复协议,世代落后的节点可以获取到最新的状态,并通过直接同步区块的方式恢复至最新的稳定检查点,同时完成节点世代与配置状态的恢复。
通过这样的动态变更集群成员的方式,使得集群配置维护更加可靠与便捷,并且可以为动态修改更多配置信息提供了可能。
作者简介
王广任
趣链科技基础平台部共识算法研究小组
参考文献
[1] Lamport L, Shostak R, Pease M. The Byzantine generals problem[M]//Concurrency: the Works of Leslie Lamport. 2019: 203-226.
[2] Castro M, Liskov B. Practical Byzantine fault tolerance[C]//OSDI.1999, 99(1999): 173-186.
[3] https://en.wikipedia.org/wiki/Quorum _ (distributed_computing)
[4] Owicki S, Lamport L. Proving liveness properties of concurrent programs[J]. ACM Transactions on Programming Languages and Systems (TOPLAS), 1982, 4(3): 455-495.
[5] Fred B. Schneider. Implementing fault-tolerant services using the state machine approach: A tutorial. ACM Comput. Surv., 22(4):299–319, 1990.
[6] Castro M, Liskov B. Practical Byzantine fault tolerance andproactive recovery[J]. ACM Transactions on Computer Systems (TOCS), 2002,20(4): 398-461.
以上是关于分布式共识算法随笔 —— 从 Quorum 到 Paxos的主要内容,如果未能解决你的问题,请参考以下文章