可观测性和传统监控的区别
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了可观测性和传统监控的区别相关的知识,希望对你有一定的参考价值。
传统监控的问题排查方法
传统的监控系统主要用于收集和汇总一定时间间隔内的性能指标,运维同学需要依靠这些指标的变化趋势来分析系统的性能,基于过往的经验判断系统是否正常,哪里可能有问题;或者通过设定监控指标的阈值进行告警。
将这些指标以图表形式展现出来,各种各样图表的组合以及自定义的视图便构成了一个个仪表盘。我们通常会为每一个系统服务设置一个静态的仪表盘,通过它了解系统的运行状态。
当我们想使用仪表盘来进一步分析问题的时候,会受制于这些仪表盘的预设条件,只能查看预设的维度;如果想分析其他的维度,可能就进行不下去了。因为这个维度的标签很可能并没有提前被添加进来,也就不能提供数据的聚合了。
使用传统监控排查故障的局限性
随着容器化的趋势、容器编排平台(例如 Kubernetes)的兴起、系统架构向微服务的转变、混合持久化(多种数据库,消息队列)的普遍使用,同时服务网格的引入、自动弹性伸缩实例的流行,甚至是无服务器(Serverless)的出现以及无数相关的 SaaS 服务的涌现,要将这些不同的工具串在一起形成一个现代系统体系结构,可能意味着一个请求在到达你控制的代码时,已经执行了多次跳转。
在云原生系统中,进行调试最困难的不再是理解代码的运行方式,而是找到有问题的代码在系统中的位置。这时候,通过仪表盘来查看哪个节点或服务速度较慢是不太可能的,因为这些系统中的分布式请求经常在不同的节点中循环,要在这些系统中找到性能瓶颈非常具有挑战性。当某个组件或者服务变慢了,一切都变慢了。
云原生系统通常作为平台运行,代码可能存在于你甚至无法控制的系统中(比如云上的云原生服务或是 PaaS 资源)。
每个请求都有可能跨越任意数量的服务和机器,这让与这些请求相关的几十个指标产生分裂,如果我们想推断在这个过程中各种请求跳转发生了什么,就必须将这些相关的指标都连接起来。而如果继续通过传统的设定阈值的方式进行故障定位,除非你能提前了解可能会在哪些节点出现问题,否则你将完全不知道故障是如何发生的,甚至都没法设定相关的阈值。
传统监控只能解决 Known-Unknowns 的问题
由于业务架构微服务化,加上日益普及的敏捷开发模式,业务的迭代速度变得非常快,这会导致仪表盘中配置的各种指标随着时间快速失效。结果就是,以往的告警和经验模式逐渐失去作用。每次出现故障,复盘的结果就是再增加一些指标或是一些告警,然而这些告警将来可能再也不会被触发。
依赖传统的监控系统,解决的是 Known-Unknowns 的问题(即你能够感知、但是不理解的问题)。比如说 CPU 使用率达到 90% 触发了告警,但却不清楚是什么原因导致了 CPU 的使用率如此之高。对于越来越多第一次发生的事情,你不可能知道这些本来你就不知道的情况,即 Unknown-Unknowns(即你既不理解、也没有感知的问题)。
随着系统复杂性的不断增加,系统性能问题的背后,涉及越来越繁多的相关性和可能性,很多问题超出了任何个人或团队能够直观理解的范畴,所以是时候引入突破这种被动和限制性的工具和方法了。
可观测性与传统监控的区别
通过查看和分析高维度和高基数数据,发现埋藏在复杂系统架构中的隐藏问题,而且不需要事先预测问题可能发生在哪里,以及问题发生的模式,这是可观测性和监控的第一个区别。
可观测性和监控的第二个区别是,关注的维度不一样。监控更加关注基础设施的资源情况。将一切整合起来的可观测性就和原来的监控不同了:可观测平台瞄准的恰恰是应用软件本身。可观测性的目标是保障应用软件的可靠性和稳定性,解决的是应用软件在运行时的调试问题。
对于应用程序代码,最重要的指标是用户的体验。底层系统可能基本上是健康的,但用户请求仍然可能因为多种原因而失败。
可观测性和监控的第三个区别,体现在数据收集的全面性(不仅仅是指标数据)和关联性上。
构建自身系统完整的可观测性需要的能力非常广泛,一般情况下,对于大部分企业来说,这是一个包括数据收集、集成、展示在内的综合性系统工程。它可能涵盖的技术从底层操作系统,到各种语言环境网络协议,甚至还涉及前端用户访问数据,eBPF,Profiling 等等,这是一个非常庞大的知识结构。而且,仅仅收集数据也是不够的,利用数据所提供的可视化、交互性来真正意义上让可观测性落地才是核心。
可观测性强调的是从应用和业务维度,用各种数据垂直且实时地描述这个应用的全貌,它采用的不是传统的分层逻辑,不是用不同的独立的监控系统分开关注每一层的情况(例如基础设施、中间件、数据库、应用服务端代码、客户端等等)。
可观测性提供了一种不同的诊断方法,它能够帮助你研究任何系统,无论这个系统多么复杂,不需要依靠经验或“直觉”。有了可观测性工具,我们不再只能依赖团队中最有经验的工程师,而是可以全面收集和关联数据,通过探索性的问题来询问系统和应用,通过数据分析和发现来进一步开放式地查询和下钻,直到找到问题或故障的根本原因。
可观测性 — Overview
目录
文章目录
云原生可观测性的背景
在云原生时代,基础设施与 Application 的构建和部署都发生了极大变化,例如:架构微服务化、运行时环境容器化、业务系统依赖关系复杂化,运行实例生命周期短等等。随着 Cloud Native Application 得规模不断扩大,复杂度愈来愈高,而其中潜藏的问题和风险也随之增多。

所以,云原生时代的监控要求可以进行实时动态的调整,而传统预先配置再监控的方式已经无法适应云原生的场景。在这个背景下,2018 年 CNCF 社区引入了云原生可观测性(Observability)这一理念。
可观测性概念最早由 Apple 工程师 Cindy Sridharan 提出,作为监控的进一步延伸,可观测性与监控的区别可以总结为:“监控告诉我们系统的哪些部分是工作的,而可观测性告诉我们哪里为什么不工作了。”
谷歌给出可观测性的核心价值很简单 —— 快速排障(Troubleshooting)。
可观测性是云原生场景必不可少的一环,关系到云原生实践能否在生产环境顺利实施。
云原生可观测性与传统监控的区别
云原生可观测性由传统监控演进而来。但传统监控是面向运维的,从系统外部视角去观察系统的运行状态;而云原生可观测性是从系统内部出发,基于 “白盒化” 的思路去监测系统内部的运行情况。
可观测性贯穿了 Application 从开发诞生到下线消亡的整个生命周期,包括开发、测试、上线、部署、发布。通过分析 Application 的 Metrics(指标)、Traces(链路)、Logs(日志)等数据,构建完整的观测模型,从而实现故障诊断、根因分析和快速恢复。
所以,云原生可观测性不仅包含了传统监控的能力,更多的是面向业务,强调将业务全过程透明化的理念。


可观测性的维度
基础设施层
从基础设施层来看,这里的可观测性与传统的主机监控有一些相似和重合的地方,比如:计算、存储、网络等主机资源的监控,对进程、磁盘 IO、网络流量等系统指标的监控等。
对于云原生的可观测性,这些传统的监控指标依然存在,但是考虑到云原生中采用的容器、服务网格、微服务等新技术、新架构,其可观测性又会有新的需求和挑战。例如,在资源层面要实现 CPU、内存等在容器、Pod、Service、Tenant 等不同层的识别和映射;在进程的监控上要能够精准识别到容器,甚至还要细化到进程的系统调用、内核功能调用等层面;在网络上,除了主机物理网络之外,还要包括 Pod 之间的虚拟化网络,甚至是应用之间的 Mesh 网络流量的观测。
业务层
从应用层来看,在微服务架构下,主机上的应用变得异常复杂,这既包括应用本身的平均延时、应用间的 API 调用链、调用参数等,还包括应用所承载的业务信息,比如业务调用逻辑、参数等信息。
可观测性系统的技术栈
可观测性的数据结构类型
当前,主流的可观测性系统主要基于 Metrics(指标)、Tracing(链路)、Logging(日志)三大数据类型构建,基本涵盖了一个 Application 所能产生的大部分可观测性数据,足以让开发运维人员洞察 Application 的运行状态。
- Metrics:主要用于监控告警(Monitoring & Alert)场景,通常存储在时序数据库。
- Tracing:主要用于业务依赖调研链的链路追踪(Tracing)场景,通常存储在日志数据库。
- Logging:主要用于日志审计(Logging)场景,通常存储在日志数据库。
2017 年,Peter Bourgon 在参加了 Distributed Tracing Summit 后发表的一篇博文,简要地介绍了 Metrics、Tracing、Logging 三者的定义和关系。这三种数据在可观测性中都有各自的发挥空间,每种数据都没办法完全被其他数据代替。

可观测性的系统组件
在 CNCF Landscape 中,可观测性的相关产品被分为 Monitoring(监控告警)、Tracing(链路追踪)、Logging(日志审计)三大类,这些产品有开源的,也有商业的,比如:
- Monitoring:Prometheus、Cortex、Zabbix、Grafana、Sysdig 等。
- Tracing:Jaeger、zipkin、SkyWalking、OpenTracing、OpenCensus 等。
- Logging:Loki、ELK、Fluentd、Splunk 等。

CNCF OpenTelemetry
利用上述 Monitoring、Tracing、Logging 三大类产品的组合,用户可以比较快速的搭建出一个可观测性系统。但是,针对 Metrics、Traces、Logs 三大类数据格式,用户往往需要搭建三套独立的系统,并且内部涉及的组件更多,维护成本很高。
中国信通院《可观测性技术发展白皮书》指出,可观测平台能力的构建,需要具备统一数据模型、统一数据处理、统一数据分析、数据编排、数据展示的能力。
针对这个问题,CNCF 推出了 OpenTelemetry 项目。该项目雄心勃勃,旨在统一 Metrics、Logs、Traces 三种数据,实现可观测性大一统。
OpenTelemetry 的诞生给云原生可观测性带来革命性的进步,包括:
- 统一协议:OpenTelemetry 带来了 Metrics、Traces、Logs(规划中)的统一标准,三者都有相同的元数据结构,可以轻松实现互相关联。
- 统一 Agent:使用一个 Agent 即可完成所有可观察性数据的采集和传输,不需要为每个系统都部署各种各样的 Agent,大大降低了系统的资源占用,使整体可观察性系统的架构也变的更加简单。
- 云原生友好:OpenTelemetry 诞生在 CNCF,对于各类的云原生下的系统支持更加友好,此外目前众多云厂商已经宣布支持 OpenTelemetry,未来云上的使用会更加便捷。
- 厂商无关:此项目完全中立,不倾向于任何一家厂商,让大家可以有充分的自由来选择、更换适合自己的服务提供商,而不需要收到某些厂商的垄断或者绑定。
- 兼容性:OpenTelemetry 得到了 CNCF 下各种可观察性方案的支持,未来对于 OpenTracing、OpenCensus、Prometheus、Fluntd 等都会有非常好的兼容性,可以方便大家无缝迁移到 OpenTelemetry 方案上。
OpenTelemetry 最核心的功能是产生、收集可观测性数据,并支持传输到各种的分析软件中。整体的架构如下图所示,其中:
- OTel API/SDK:用于产生统一格式的可观测性数据。
- OTel Collector:用来接收这些可观测性数据,并支持把数据传输到各种类型的后端系统。
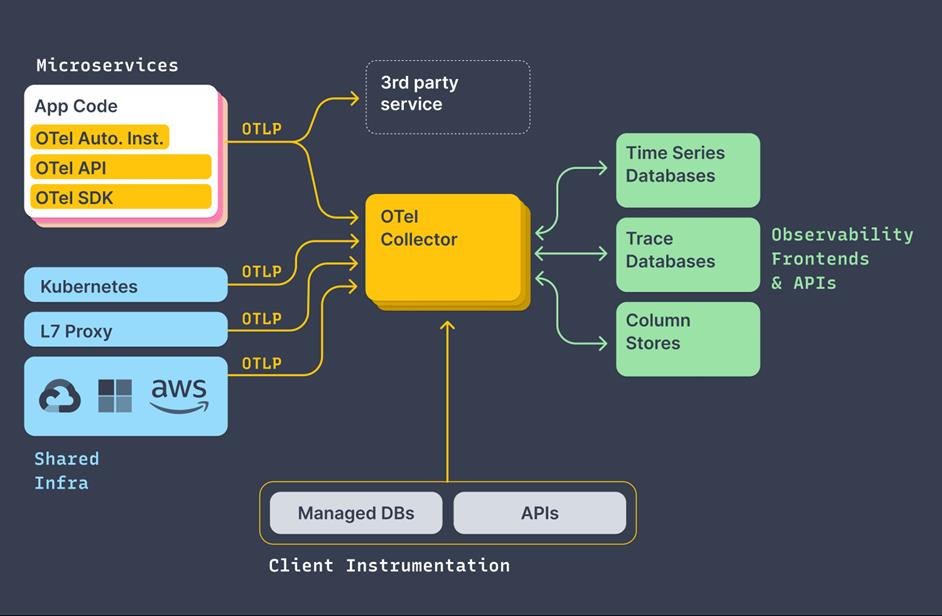
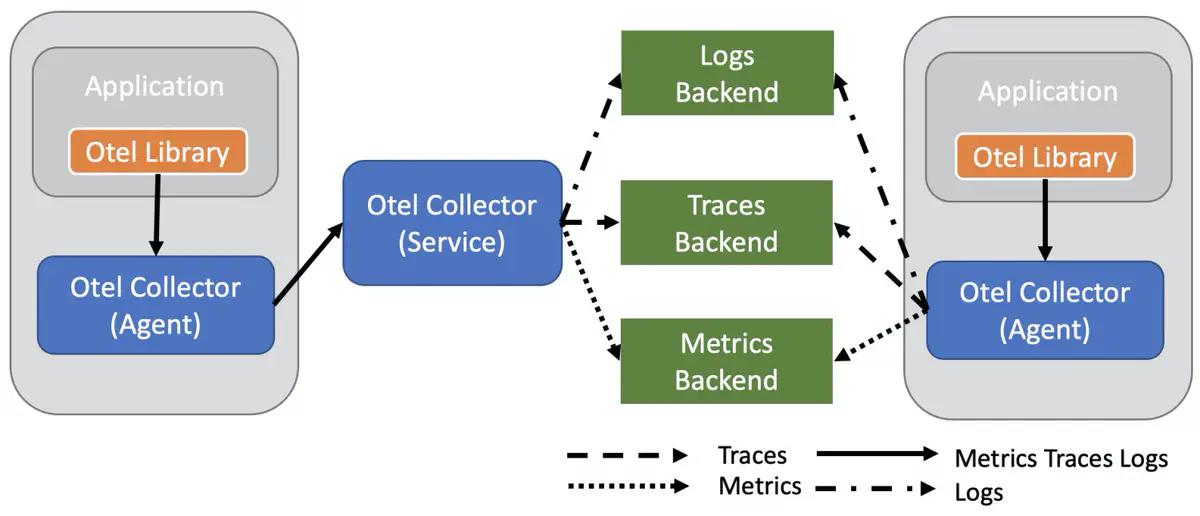
OpenTelemetry 定位是作为可观测性的基础设施,解决数据产生、采集、传输的问题。但是目前数据的存储与分析还是依赖各个后端系统,导致无法对全部数据进行统一展示与关联分析。
最理想的情况是能有一个后端引擎同时存储所有的 Metrics、Logs、Traces 数据,并进行统一的分析、关联、可视化。现在已经有一些厂商开始相关的尝试。比如 Grafana Labs 推出的 Loki,其主要设计理念来源于 Prometheus。通过 Loki, 用户可以像分析 Prometheus 指标一样分析日志,也可以基于相同的 Labels 来关联 Metrics 和 Logs 数据。
如下图所示,在同一个 Grafana 面板中,左右分别展示了相关的 Metrics 和 Logs,用户可以方便的对数据进行关联分析。

可观测性系统的应用场景
-
应用发布部署
-
全景监测
-
智能告警
-
性能诊断
-
等保 2.0 四级要求:尤其对应用可信提出了明确的动态验证需求,如何在不影响应用的功能、性能,保证用户体验的前提下,做到应用的动态可信验证成为重要的挑战。在云原生中,解决这个问题的核心在于准确地选择应用的可信度量对象,高性能地确定指标的度量值,以及收集和管理验证这些基准值,这些都是对云原生实现可观测的重要意义和应用价值。
以上是关于可观测性和传统监控的区别的主要内容,如果未能解决你的问题,请参考以下文章