实验1:熟悉常用的Linux操作和Hadoop操作
Posted 是小猪猪哦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实验1:熟悉常用的Linux操作和Hadoop操作相关的知识,希望对你有一定的参考价值。
注:完整实验报告word文件在末尾
—————————————————————————————————
"大数据技术原理与应用"课程实验报告
题目:实验1:熟悉常用的Linux操作和Hadoop操作 姓名:朱小凡 日期:2022/3/11
1、实验环境:
设备名称 LAPTOP-9KJS8HO6
处理器 Intel® Core™ i5-10300H CPU @ 2.50GHz 2.50 GHz
机带 RAM 16.0 GB (15.8 GB 可用)
主机操作系统 Windows 10 家庭中文版
虚拟机操作系统 ubuntukylin-16.04
系统类型 64 位操作系统, 基于 x64 的处理器
笔和触控 没有可用于此显示器的笔或触控输入
2、实验内容与完成情况:
- 安装Linux虚拟机
<!-- -->
- 安装Virtual Box成功

- 安装ubuntukylin-16.04成功

-
熟悉常用Linux命令
- cd命令:切换目录
(1)切换到目录/usr/local
cd /usr/local
(2)切换到当前目录的上一级目录
cd …
- 切换到当前登录Linux系统的用户的自己的主文件夹
cd ~

- ls命令:查看文件和目录
<!-- -->
- 查看目录/usr下的所有文件和目录
cd /usr
ls

- mkdir命令:新建目录
<!-- -->
- 进入/tmp目录,创建一个名为a的目录,并查看/tmp目录下已经存在哪些目录
cd /tmp
mkdir a
ls --al

- 进入/tmp目录,创建目录a1/a2/a3/a4
cd /tmp
mkdir --p a1/a2/a3/a4

- rmdir命令:删除空的目录
<!-- -->
- 将上面创建的目录a(在"/tmp"目录下面)删除。
cd /tmp
rmdir a

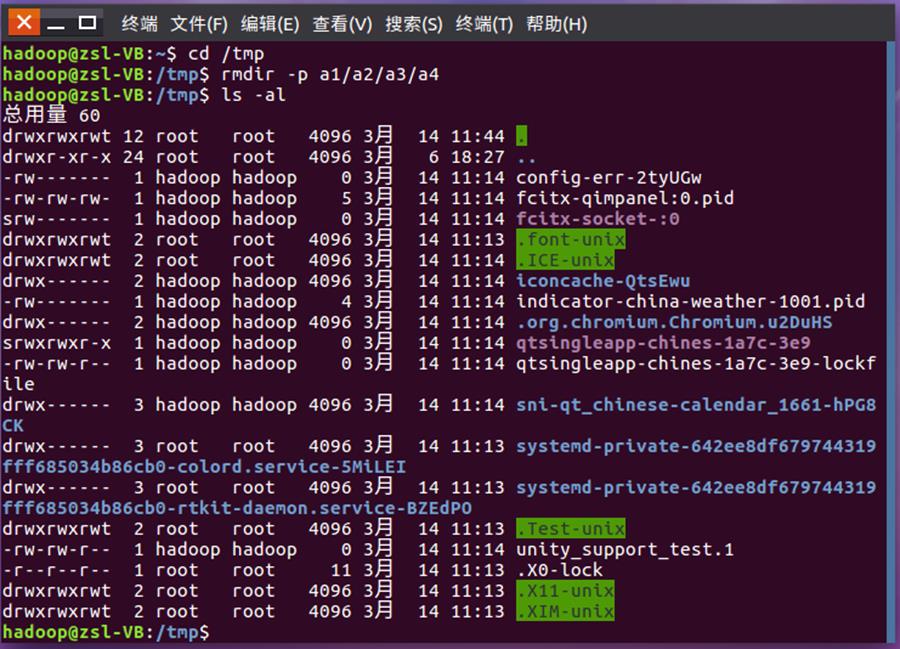
- 删除上面创建的目录a1/a2/a3/a4,然后查看/tmp目录下面存在哪些目录。
cd /tmp
rmdir --p a1/a2/a3/a4
ls -al
- cp命令:复制文件或目录
<!-- -->
- 将当前用户的主文件夹下的文件.bashrc复制到目录/usr下,并重命名为bashrc1
sudo cp ~/.bashrc /usr/bashrc1

- 在目录/tmp下新建目录test,再把这个目录复制到/usr目录下
cd /tmp
mkdir test
sudo cp --r /tmp/test /usr

- mv命令:移动文件和目录,或重命名
<!-- -->
- 将/usr目录下的文件bashrc1移动到/usr/tesl目录下
sudo mv /usr/bashrc1 /usr/test

- 将/usr目录下的test目录重命名为test2
sudo mv /usr/test /usr/test2

- rm命令:移除文件或目录
<!-- -->
- 将/usr/test2目录下的bashrc1文件删除
sudo rm /usr/test2/bashrc1

- 将/usr目录下的test2目录删除
sudo rm --R /usr/test2

- cat命令:查看文件内容
查看当前用户主文件夹下的.bashrc文件内容
cat ~/.bashrc

- tac命令:反向查看文件内容
反向查看当前用户主文件夹下的.bashrc文件内容
tac ~/.bashrc

- more命令:一页一页翻动查看
翻页查看当前用户主文件夹下的.bashrc文件的内容
more ~/.bashrc

- head命令:取出前面几行
<!-- -->
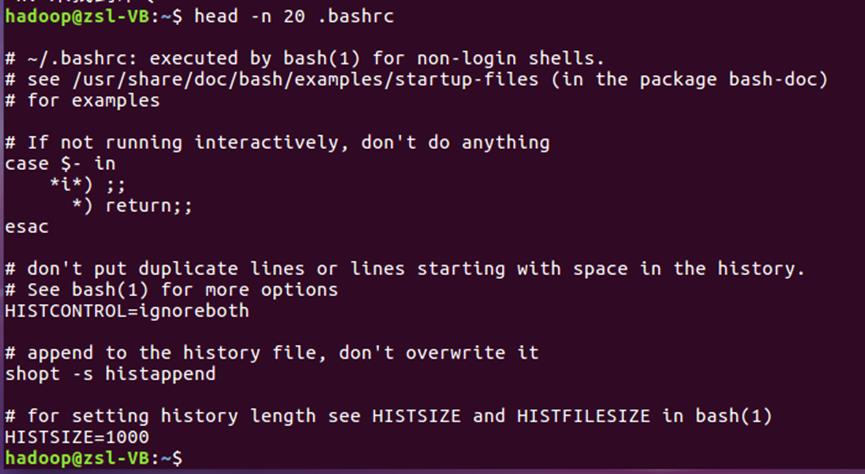
- 查看当前用户主文件夹下.bashrc文件的内容的前20行
head --n 20 ~/.bashrc
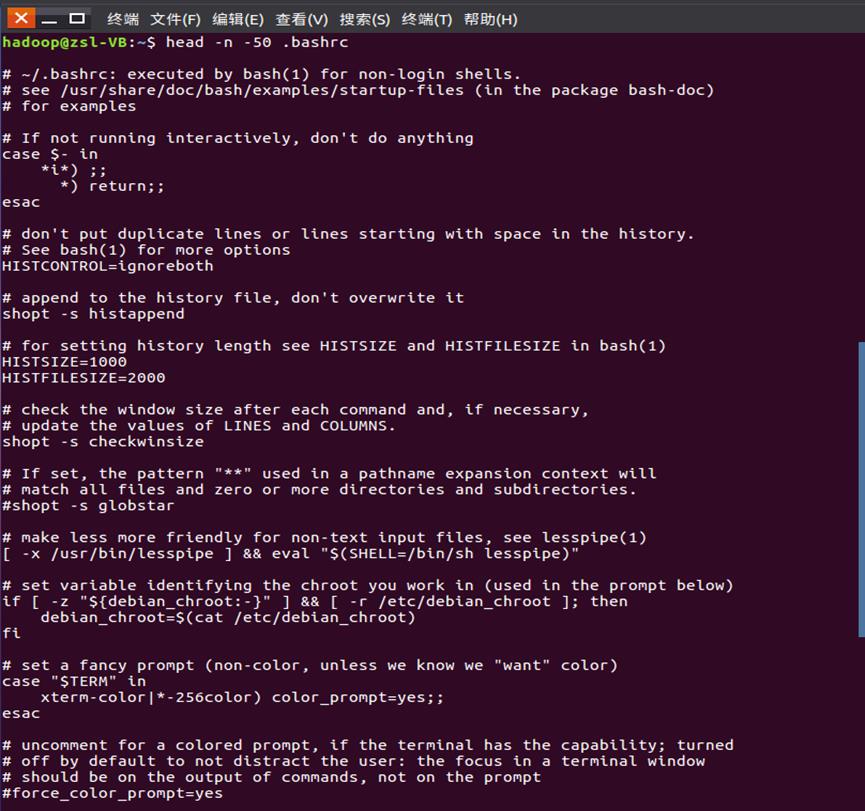
- 查看当前用户主文件夹下.bashrc文件的内容,后面50行不显示,只显示前面几行
head -n -50 ~/.bashrc
- tail命令:取出后面几行
<!-- -->
- 查看当前用户主文件夹下.bashrc文件内容的最后20行
tail -n 20 ~/.bashrc

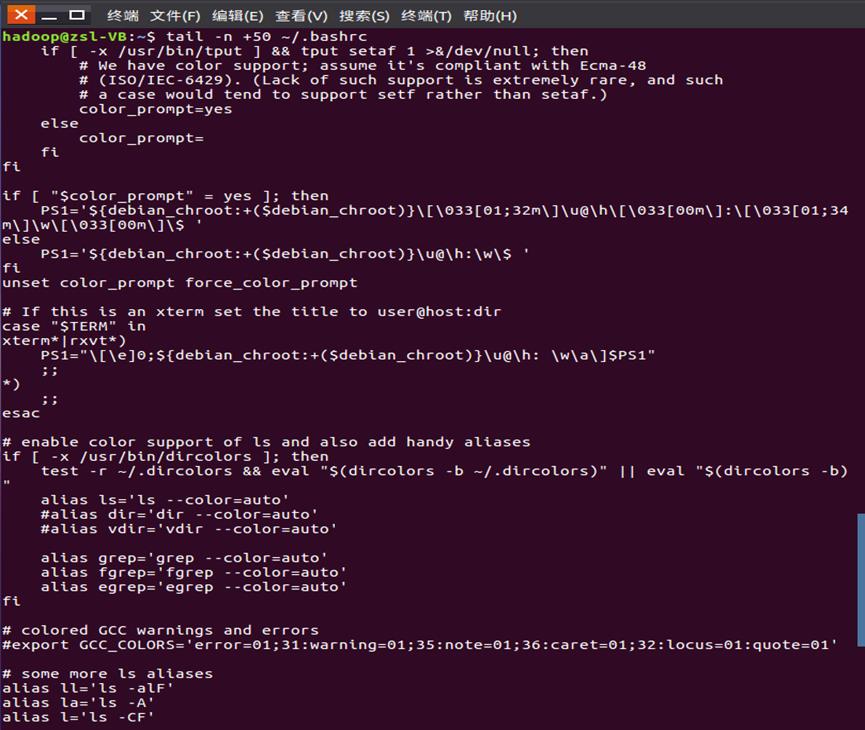
- 查看当前用户主文件夹下.bashrc文件的内容,并且只列出50行以后的数据
tail -n +50 ~/.bashrc
- touch命令:修改文件时间或创建新文件
<!-- -->
- 在/tmp目录下创建一个空文件hello,并查看文件时间
cd /tmp
touch hello
ls -l hello

- 修改hello文件,将文件时间调整为5天前
touch -d “5 days ago” hello

- chown命令:修改文件所有者权限
将hello文件所有者改为root账号,并查看属性
sudo chown root /tmp/hello
ls -l /tmp/hello

- find命令:文件查找
找出主文件夹下文件名为.bashrc的文件
find ~/.bashrc

- tar命令:压缩命令
<!-- -->
- 在根目录"/“下新建文件夹test,然后在根目录”/"下打包成test.tar.gz
sudo mkdir /test
sudo tar -zcv -f /test.tar.gz test

- 把上面的test.tar.gz压缩包,解压缩到/tmp目录
sudo tar -zxv -f /test.tar.gz -C /tmp

- grep命令:查找字符串
从~/.bashrc文件中查找字符串"examples"
grep examples ~/.bashrc

- 配置环境变量
(1)命令:
sudo vim ~/.bashrc
文件的末尾追加下面内容:
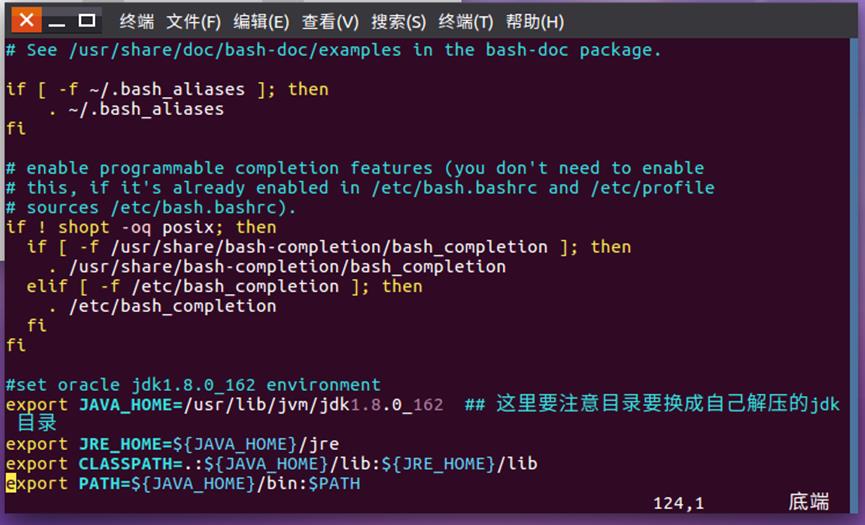
#set oracle jdk environment
export JAVA_HOME=/usr/lib/jvm/jdk1.7.0_60 ##
这里要注意目录要换成自己解压的jdk 目录export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.😒JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$JAVA_HOME/bin:$PATH
使环境变量马上生效
source ~/.bashrc
(2)查看JAVA_HOME变量的值
echo $JAVA_HOME

- 进行Hadoop伪分布式安装
访问Hadoop官网(https://hadoop.apache.org/),下载Hadoop安装文件hadoop-3.1.3.tar.gz。在Linux虚拟机环境下完成Hadoop伪分布式环境的搭建,并运行Hadoop自带的WordCount实例检测是否运行正常。具体安装方法可以参考网络资料,也可以参考本书官网的"教材配套大数据软件安装和编程实践指南"。
答:(1)配置core-site.xml 和 hdfs-site.xml
(2)配置完成后,执行 NameNode 的格式化:
cd /usr/local/hadoop
./bin/hdfs namenode --format
(3)接着开启 NameNode 和 DataNode 守护进程:
cd /usr/local/hadoop
./sbin/start-dfs.sh #start-dfs.sh是个完整的可执行文件,中间没有空格
(4)启动完成后,可以通过命令 jps 来判断是否成功启动.
(5)运行Hadoop自带的WordCount实例
例如:统计/usr/local/hadoop/目录下的LICENSE.txt文件中各个单词出现的次数
命令:./bin/hadoop jar
./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount
input output
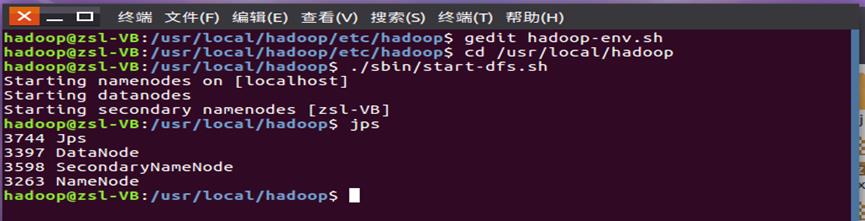
图3.1伪分布式安装成功
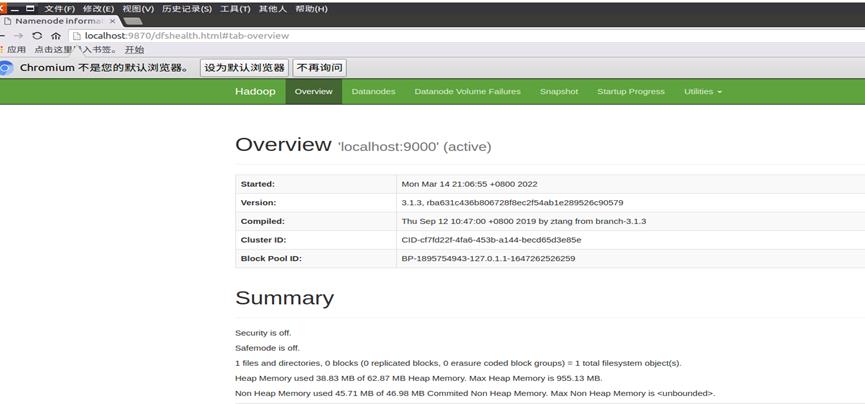
图3.2 访问 Web 界面

图3.3 Hadoop自带实例WordCount统计结果(部分)
- 熟悉常用的Hadoop操作
<!-- -->
(1) 使用Hadoop用户登录Linux操作系统,启动Hadoop
(Hadoop的安装目录为"/usr/local/hadoop"),为Hadoop用户在HDFS中创建用户目录"/user/hadoop"。
答:./bin/hdfs dfs -mkdir -p /user/hadoop

(2) 接着在HDFS的目录"user/hadoop"下,创建test文件夹,并查看文件列表。
答:./bin/hdfs dfs -mkdir test
./bin/hdfs dfs -ls

(3) 将Linux操作系统本地的"~/.bashrc"文件上传到HDFS的test文件夹中,并查看test。
答:./bin/hdfs dfs -put ~/.bashrc test
./bin/hdfs dfs -ls test

(4) 将HDFS
test文件夹复制到Linux操作系统本地文件系统的"/usr/local/hadoop"目录下。
答:./bin/hdfs dfs -get test ./
ls

**
**
3、出现的问题:
- 最开始出现安装界面分辨率太小导致安装程序显示不完整

- Ubuntu安装完成后不能上网
3、开启 NameNode 和 DataNode 守护进程时提示ERROR: JAVA_HOME is not set
and could not be found.
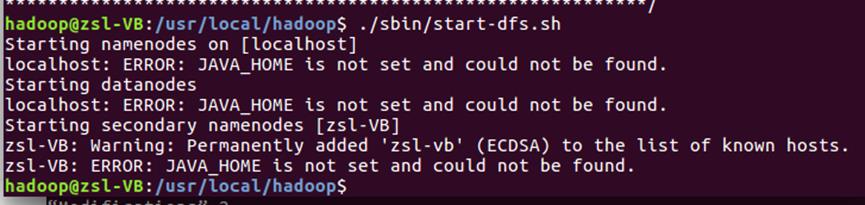
4、解决方案:
-
解决方法:先用WIN+鼠标挪动安装程序界面,找到安装按钮,完成安装后,点击VirtualBox菜单栏中的设备---->安装增强功能,然后重启虚拟机,在系统设置中可以选择调整分辨率。
-
解决方法:关闭虚拟机后,选择VirtualBox菜单栏中的设备—>网络,由于我的电脑内置有多个网卡,所以需要查看当前主机的网络连接,选择正确的网卡名称,比如有线网卡Realtek
PCIe GbE Family Controller和无线网卡MediaTek Wi-Fi 6 MT7921 Wireless
LAN Card。如图所示:

3、到hadoop的安装目录修改配置文件"/usr/local/hadoop/etc/hadoop/hadoop-env.sh",在里面找到"export
JAVA_HOME=$JAVA_HOME"这行,然后,把它修改成JAVA安装路径的具体地址,比如,“export
JAVA_HOME=/usr/lib/jvm/jdk1.8.0_162”,然后,再次启动Hadoop。
完整实验报告下载地址:
以上是关于实验1:熟悉常用的Linux操作和Hadoop操作的主要内容,如果未能解决你的问题,请参考以下文章