canal1.1.5 配置kafka
Posted 醉舞斜陽
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了canal1.1.5 配置kafka相关的知识,希望对你有一定的参考价值。
1. 简介:
canal [kə\'næl],译意为水道/管道/沟渠,主要用途是基于 mysql 数据库增量日志解析,提供增量数据订阅和消费
早期阿里巴巴因为杭州和美国双机房部署,存在跨机房同步的业务需求,实现方式主要是基于业务 trigger 获取增量变更。从 2010 年开始,业务逐步尝试数据库
志解析获取增量变更进行同步,由此衍生出了大量的数据库增量订阅和消费业务。
基于日志增量订阅和消费的业务包括
1.数据库镜像
2.数据库实时备份
3.索引构建和实时维护(拆分异构索引、倒排索引等)
4.业务 cache 刷新
5.带业务逻辑的增量数据处理
1.1 官网地址
https://github.com/alibaba/canal
2.架构
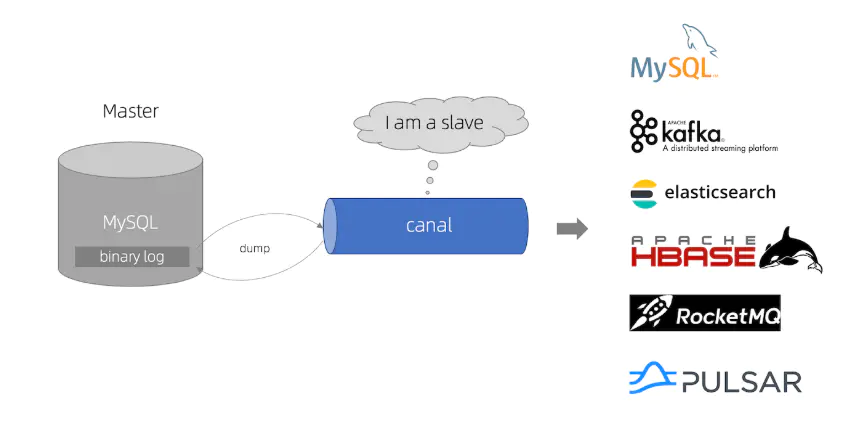
canal.png
3.canal 工作原理
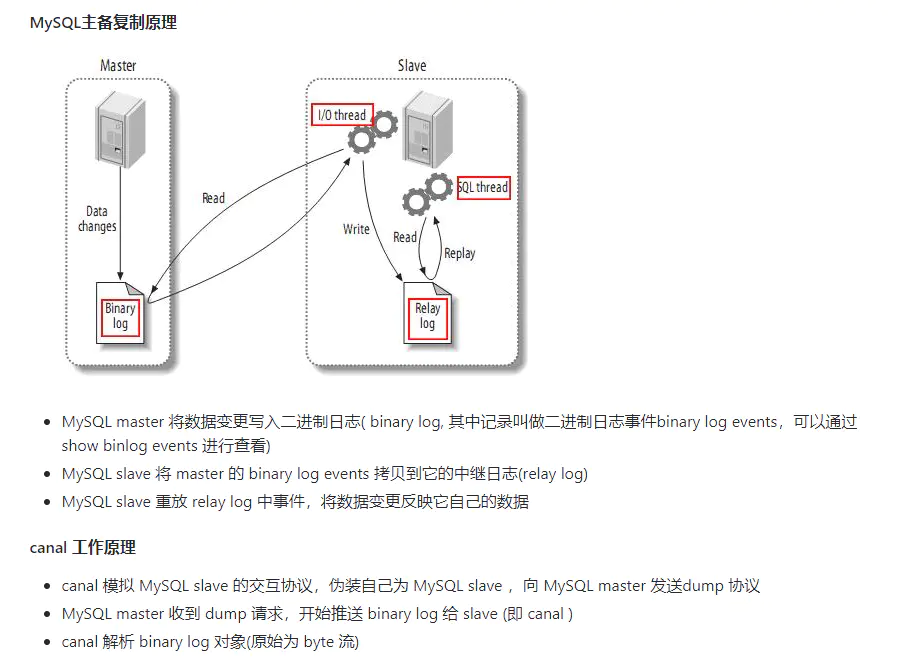
canal 工作原理.png
4 canal 部署所需要的组件
搭建一套可以用的组件需要部署MySQL、Zookeeper、Kafka和Canal四个中间件的实例
5. mysql 安装省略(参考博客上的安装即可)
5.1 为canal -admin 创建用户
CREATE USER canaladmin IDENTIFIED BY \'Canaladmin%123\';
GRANT ALL ON canal_manager.* TO \'canaladmin\'@\'%\';
FLUSH PRIVILEGES;
5.1 为canal 创建用户:
CREATE USER canal IDENTIFIED BY \'Canal%123\';
GRANT ALL PRIVILEGES ON *.* TO \'canal\'@\'%\' ;
FLUSH PRIVILEGES;
5.3 mysql 的配置:
打开mysql 的配置文件:
vi /etc/my.cnf
server-id=1
log-bin=mysql-bin
binlog-format=ROW
binlog-ignore-db=information_schema
binlog-ignore-db=mysql
binlog-ignore-db=performance_schema
binlog-ignore-db=sys
log-bin用于指定binlog日志文件名前缀,默认存储在/var/lib/mysql 目录下。
server-id用于标识唯一的数据库,不能和别的服务器重复,建议使用ip的最后一段,默认值也不可以。
binlog-ignore-db:表示同步的时候忽略的数据库。
binlog-do-db:指定需要同步的数据库(如果没有此项,表示同步所有的库)。
6. canal 安装
下载地址:
https://github.com/alibaba/canal/releases

6.1 下载解压安装
[root@dbos-bigdata-test005 canal]# ll
total 8
drwxr-xr-x 6 root root 4096 Oct 11 16:37 admin
drwxr-xr-x 7 root root 4096 Oct 11 16:38 deployer
[root@dbos-bigdata-test005 canal]# pwd
/data/canal
[root@dbos-bigdata-test005 canal]#
6.2 配置环境变量
#set default jdk1.8 env
export JAVA_HOME=/usr/java/jdk1.8.0_181-cloudera
export JRE_HOME=/usr/java/jdk1.8.0_181-cloudera/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export HADOOP_CONF_DIR=/etc/hadoop/conf
export HADOOP_CLASSPATH=`hadoop classpath`
export HBASE_CONF_DIR=/etc/hbase/conf
export FLINK_HOME=/opt/flink
export HIVE_HOME=/opt/cloudera/parcels/CDH-6.3.0-配canal instance同步报错:java.lang.ArrayIndexOutOfBoundsException: 1