如何正确的使用MongoDB并优化其性能
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何正确的使用MongoDB并优化其性能相关的知识,希望对你有一定的参考价值。
数据库性能对软件整体性能的影响是不言而喻的,那么,当我们使用MongoDB时改如何提高数据库性能呢?1.范式化与反范式化
在项目设计阶段,明确集合的用途是对性能调优非常重要的一步。
从性能优化的角度来看,集合的设计我们需要考虑的是集合中数据的常用操作,例如我们需要设计一个日志(log)集合,日志的查看频率不高,但写入频率却很高,那么我们就可以得到这个集合中常用的操作是更新(增删改)。如果我们要保存的是城市列表呢?显而易见,这个集合是一个查看频率很高,但写入频率很低的集合,那么常用的操作就是查询。
对于频繁更新和频繁查询的集合,我们最需要关注的重点是他们的范式化程度,在上篇范式化与反范式化的介绍中我们了解到,范式化与反范式化的合理运用对于性能的提高至关重要。然而这种设计的使用非常灵活,假设现在我们需要存储一篇图书及其作者,在MongoDB中的关联就可以体现为以下几种形式:
1.完全分离(范式化设计)
示例1:
View Code
"_id" : ObjectId("5124b5d86041c7dca81917"),
"title" : "如何使用MongoDB",
"author" : [
ObjectId("144b5d83041c7dca84416"),
ObjectId("144b5d83041c7dca84418"),
ObjectId("144b5d83041c7dca84420"),
]
我们将作者(comment) 的id数组作为一个字段添加到了图书中去。这样的设计方式是在非关系型数据库中常用的,也就是我们所说的范式化设计。在MongoDB中我们将与主键没有直接关系的图书单独提取到另一个集合,用存储主键的方式进行关联查询。当我们要查询文章和评论时需要先查询到所需的文章,再从文章中获取评论id,最后用获得的完整的文章及其评论。在这种情况下查询性能显然是不理想的。但当某位作者的信息需要修改时,范式化的维护优势就凸显出来了,我们无需考虑此作者关联的图书,直接进行修改此作者的字段即可。
2.完全内嵌(反范式化设计)
示例2:
View Code
"_id" : ObjectId("5124b5d86041c7dca81917"),
"title" : "如何使用MongoDB",
"author" : [
"name" : "丁磊"
"age" : 40,
"nationality" : "china",
,
"name" : "马云"
"age" : 49,
"nationality" : "china",
,
"name" : "张召忠"
"age" : 59,
"nationality" : "china",
,
]
在这个示例中我们将作者的字段完全嵌入到了图书中去,在查询的时候直接查询图书即可获得所对应作者的全部信息,但因一个作者可能有多本著作,当修改某位作者的信息时时,我们需要遍历所有图书以找到该作者,将其修改。
3.部分内嵌(折中方案)
示例3:
View Code
"_id" : ObjectId("5124b5d86041c7dca81917"),
"title" : "如何使用MongoDB",
"author" : [
"_id" : ObjectId("144b5d83041c7dca84416"),
"name" : "丁磊"
,
"_id" : ObjectId("144b5d83041c7dca84418"),
"name" : "马云"
,
"_id" : ObjectId("144b5d83041c7dca84420"),
"name" : "张召忠"
,
]
这次我们将作者字段中的最常用的一部分提取出来。当我们只需要获得图书和作者名时,无需再次进入作者集合进行查询,仅在图书集合查询即可获得。
这种方式是一种相对折中的方式,既保证了查询效率,也保证的更新效率。但这样的方式显然要比前两种较难以掌握,难点在于需要与实际业务进行结合来寻找合适的提取字段。如同示例3所述,名字显然不是一个经常修改的字段,这样的字段如果提取出来是没问题的,但如果提取出来的字段是一个经常修改的字段(比如age)的话,我们依旧在更新这个字段时需要大范围的寻找并依此进行更新。
在上面三个示例中,第一个示例的更新效率是最高的,但查询效率是最低的,而第二个示例的查询效率最高,但更新效率最低。所以在实际的工作中我们需要根据自己实际的需要来设计表中的字段,以获得最高的效率。
参考技术A
【概述】
1)内存是否充足.
2)(BTree 树)索引不命中所占百分比.
3)全局写入锁占用了机器多少时间。发生全局写入锁时,所有查询都将等待,直到锁解除.
4)等待处理的查询请求队列大小.
5)监测当前连接数.
【MongoDb性能优化介绍】
A)MongoDb查询慢,性能不好的监测点。
mongostat:
A1)faults/s:每秒访问失败数,
即数据被交换出物理内存,放到SWAP。若过高(一般超过100),则意味着内存不足。
vmstat & iostat & iotop
[注]
si:每秒从磁盘读入虚拟内存的大小,若大于0,表示物理内存不足。
so:每秒虚拟内存写入磁盘的大小,若大于0,同上。
A2) idx miss %:BTree 树未命中的比例,即索引不命中所占百分比.
若过高,则意味着索引建立或使用不合理。
db.serverStatus()
indexCounters” :
“btree” :
“accesses” : 2821726, #索引被访问数
“hits” : 2821725, #索引命中数
“misses” : 1, #索引偏差数
“resets” : 0, #复位数
“missRatio” : 3.543930204420982e-7 #未命中率
A3)locked %:全局写入锁占用了机器多少时间.
当发生全局写入锁时,所有查询操作都将等待,直到写入锁解除。
若过高(一般超过50%),则意味着程序存在问题。
db.currentOp()
“inprog” : [ ],
“fsyncLock” : 1, #为1表示MongoDB的fsync进程(负责将写入改变同步到磁盘)不允许其他进程执行写数据操作
“info” : “use db.fsyncUnlock() to terminate the fsync write/snapshot lock”
A4)q r|w :等待处理的查询请求队列大小.
若过高,则意味着查询会过慢。
db.serverStatus()
“currentQueue” :
“total” : 1024, #当前需要执行的队列
“readers” : 256, #读队列
“writers” : 768 #写队列
A5)conn :当前连接数.
高并发下,若连接数上不去,则意味着Linux系统内核需要调优。
db.serverStatus()
“connections” :
“current” : 3, #当前连接数
“available” : 19997 #可用连接数
A6)连接数使用内存.
cat /proc/$(pidof mongod)/limits | grep stack | awk -F ‘size‘ ‘print int($NF)/1024‘
将连接数使用Linux栈内存设小,默认为10MB(10240)
shell> ulimit -s 1024
B)查看执行计划,并分析结果。
B1)优化器的设置。
db.setProfilingLevel(2);
0 – 不开启
1 – 记录慢命令 (默认为>100ms)
2 – 记录所有命令
info: #本命令的详细信息
reslen: #返回结果集的大小
nscanned: #本次查询扫描的记录数
nreturned: #本次查询实际返回的结果集
millis: #该命令执行耗时(毫秒)
B2)监控一个集合时一般关注的信息有哪些?.
集合 collect_x 未建立有效索引(建议考虑使用组合索引)
存在大量慢查询,均为collect_x读操作,且响应超过1秒
每次读操作均为全集合扫描,意味着耗用CPU(25% * 8核)
每次返回的记录字节数近1KB,建议过滤不必要的字段,提高传输效率。
B3)如何查询执行计划?
>db.Book.find(CharsCount: “200000”).hint(CharsCount:1 ).explain();
B4)分析查询计划。
分析案例1)
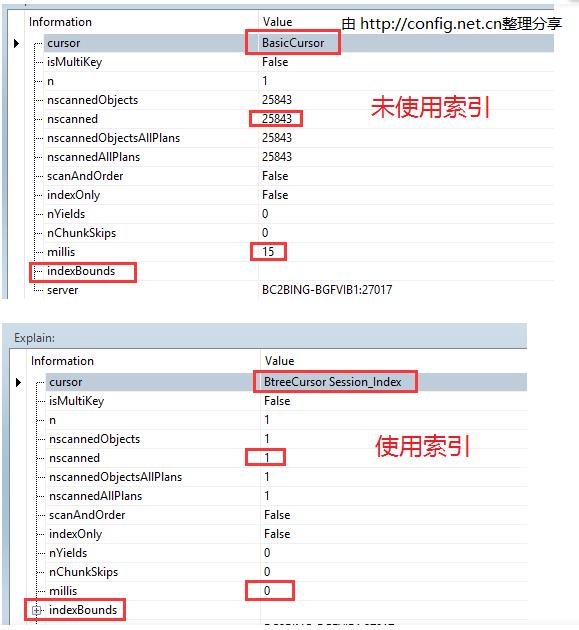
请点击输入图片描述
[注]
cursor: 返回游标类型(BasicCursor 或 BtreeCursor)
nscanned: 被扫描的文档数量
n: 返回的文档数量
millis: 耗时(毫秒)
indexBounds: 所使用的索引.
MongoDb整体性能优化
以上是关于如何正确的使用MongoDB并优化其性能的主要内容,如果未能解决你的问题,请参考以下文章