2023爬虫学习笔记 -- 获取cookies并访问个人书架
Posted web安全工具库
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2023爬虫学习笔记 -- 获取cookies并访问个人书架相关的知识,希望对你有一定的参考价值。
一、访问目标网站
浏览器=webdriver.Chrome(r'./chromedriver')
目标网址='https://www.XXXcom'
浏览器.get(目标网址)二、点击登录按钮,弹出登录框
登录框=浏览器.find_element("xpath",'//*[@id="header_login_user"]/a[1]')
登录框.click()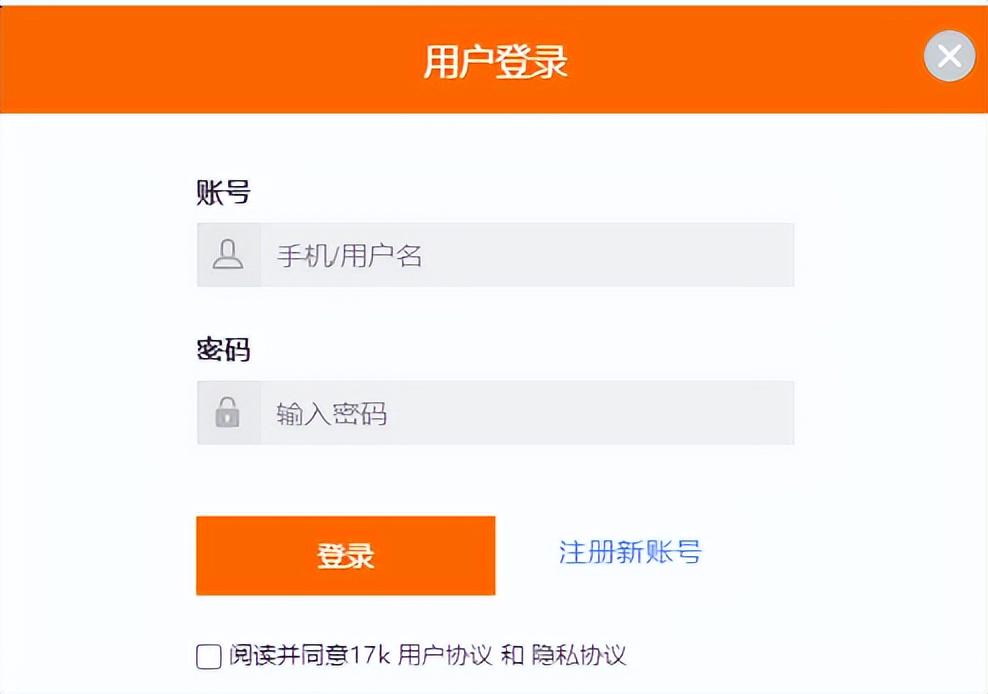
三、切换到用户登录窗口
登录窗口=浏览器.find_element("xpath",'/html/body/div[20]/div/div[1]/iframe')
浏览器.switch_to.frame(登录窗口)四、输入用户名和密码
用户名=浏览器.find_element("xpath",'/html/body/form/dl/dd[2]/input')
用户名.send_keys("15836353612")
密码=浏览器.find_element("xpath",'/html/body/form/dl/dd[3]/input')
密码.send_keys("17kcom")五、点击阅读协议并点击登录按钮
协议框=浏览器.find_element("xpath",'//*[@id="protocol"]')
协议框.click()
sleep(1)
登录按钮=浏览器.find_element("xpath",'/html/body/form/dl/dd[5]/input')
登录按钮.click()六、获取cookies,并重组cookies
cookies=浏览器.get_cookies()
dic=
for cook in cookies:
dic[cook['name']]=cook['value']七、获取书架内容
书架地址='https://useCCCCCcom/www/bookshelf/'
头=
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36",
网页内容=requests.get(书架地址,headers=头,cookies=dic)
网页内容.encoding="utf8"
print(网页内容.text)
八、附源码
浏览器=webdriver.Chrome(r'./chromedriver')
目标网址='https://wwwXXXXX.com'
浏览器.get(目标网址)
sleep(1)
登录框=浏览器.find_element("xpath",'//*[@id="header_login_user"]/a[1]')
登录框.click()
sleep(1)
登录窗口=浏览器.find_element("xpath",'/html/body/div[20]/div/div[1]/iframe')
浏览器.switch_to.frame(登录窗口)
sleep(1)
用户名=浏览器.find_element("xpath",'/html/body/form/dl/dd[2]/input')
用户名.send_keys("15836353612")
sleep(1)
密码=浏览器.find_element("xpath",'/html/body/form/dl/dd[3]/input')
密码.send_keys("17kcom")
sleep(1)
协议框=浏览器.find_element("xpath",'//*[@id="protocol"]')
协议框.click()
sleep(1)
登录按钮=浏览器.find_element("xpath",'/html/body/form/dl/dd[5]/input')
登录按钮.click()
sleep(1)
cookies=浏览器.get_cookies()
dic=
for cook in cookies:
dic[cook['name']]=cook['value']
书架地址='https://user.XXXXXcom/www/bookshelf/'
头=
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36",
网页内容=requests.get(书架地址,headers=头,cookies=dic)
网页内容.encoding="utf8"
print(网页内容.text)以上是关于2023爬虫学习笔记 -- 获取cookies并访问个人书架的主要内容,如果未能解决你的问题,请参考以下文章