非平衡数据(imbalanced data)的简单介绍
Posted PythonEducation
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了非平衡数据(imbalanced data)的简单介绍相关的知识,希望对你有一定的参考价值。
不平衡分类是指分类预测建模问题,其中每个类标签的训练数据集中的示例数量不平衡。也就是说,类分布不等于或接近等于,而是有偏差或偏斜。
不平衡分类问题是分类问题的一个示例,其中已知类中的示例分布有偏差或偏斜。分布可以从轻微的偏差到严重的不平衡,其中少数类中有一个示例,而多数类中有数百、数千或数百万个示例。
不平衡的分类对预测建模提出了挑战,因为大多数用于分类的机器学习算法都是围绕每个类的示例数量相等的假设设计的。这会导致模型的预测性能不佳,特别是对于少数类。这是一个问题,因为通常少数类更重要,因此问题对少数类的分类错误比多数类更敏感。我们将这些类型的问题称为“不平衡分类”而不是“不平衡分类”。不平衡是指已经平衡但现在不再平衡的类分布,而不平衡是指本质上不平衡的类分布。

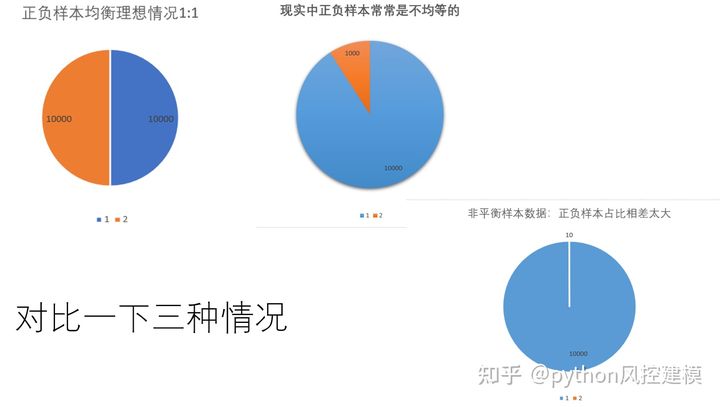
理想数据集正负样本是均等的,这有利于机器学习模型训练。
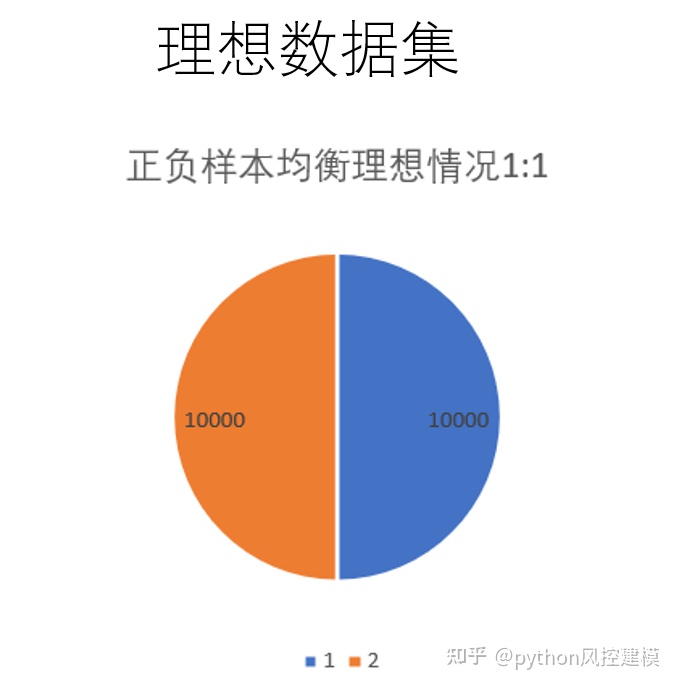
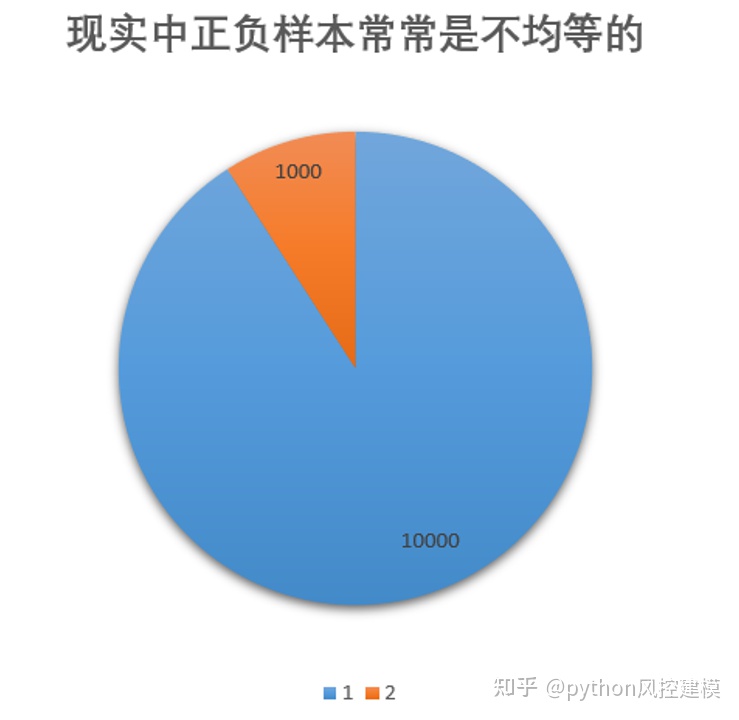
现实中正负样本常常不均等,而且正负样本比例相差甚大,如下图橘红色样本仅占10%左右。
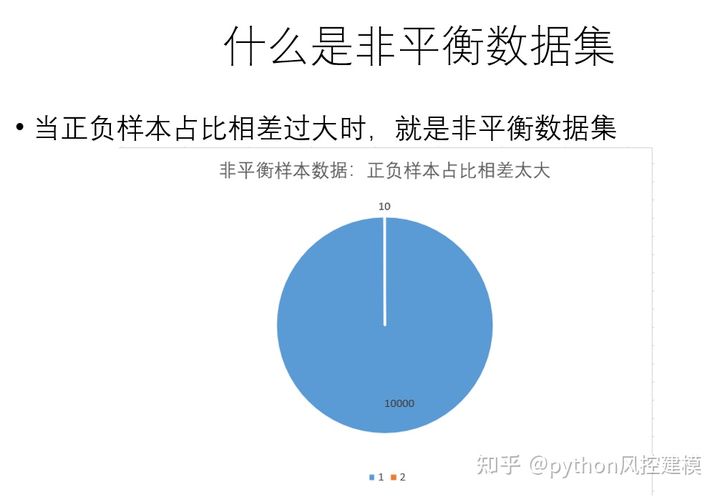
什么是非平衡数据集?当正负样本占比相差过大时,就是非平衡数据集。如下图负面样本仅占0.001,属于典型非平衡数据集。
不平衡分类的挑战
汇总对比一下理想数据分布情况和正负样本不均情况。类别分布的不平衡会因问题而异。
一个分类问题可能有点偏,比如有轻微的不平衡。或者,分类问题可能存在严重的不平衡,对于给定的训练数据集,一个类中可能有数百或数千个示例,而另一类中可能有数十个示例。
- 轻微失衡。一个不平衡的分类问题,其中示例的分布在训练数据集中有少量不均匀(例如 4:6)。
- 严重失衡。一个不平衡的分类问题,其中示例的分布在训练数据集中大量不均匀(例如 1:100 或更多)。
当代大多数关于类别失衡的数据集都集中在1:4到1:100的失衡比例上。[…] 在欺诈检测或化学信息学等实际应用中,我们可能会处理不平衡比范围为 1:1000 到 1:5000 的问题。
下面是非平衡数据点状图分布
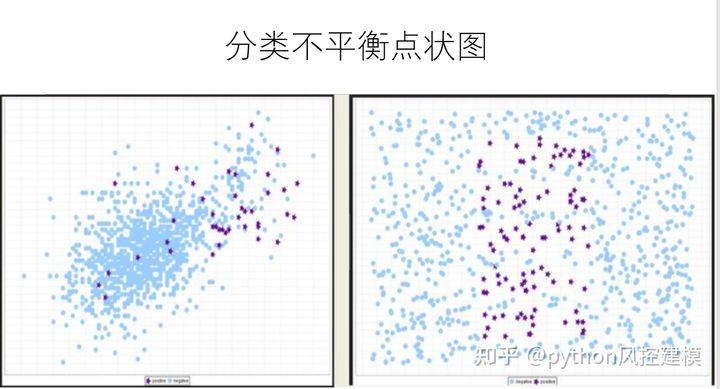
非平衡数据集在现实生活中有非常多应用。常见下述情况:
- 欺诈识别
- 医疗诊断
- 石油泄漏侦查
- 索赔预测
- 默认预测
- 面部识别
- 流失预测
- 垃圾邮件检测
- 异常检测
- 异常值检测
- ***检测
- 转换预测

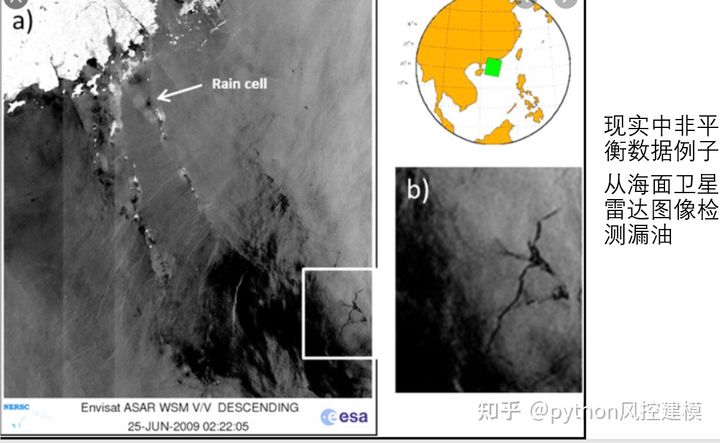
非平衡数据例子1:从海面卫星雷达图像检测漏油
如下图,石油泄漏面积仅占海洋区域非常小比例,难以发现,属于经典非平衡数据例子
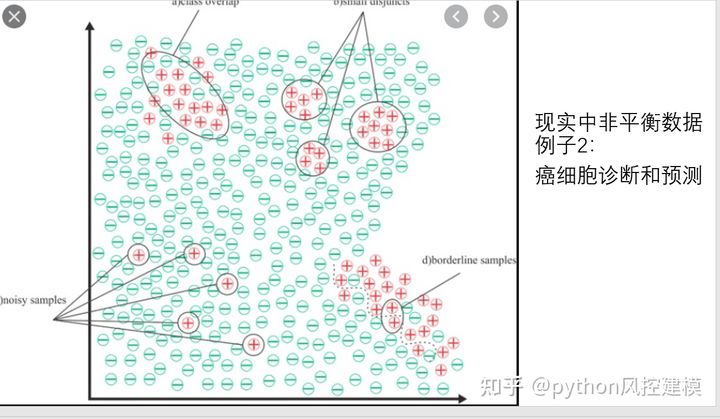
非平衡数据例子2:癌细胞诊断和预测
癌细胞仅占正常细胞非常小比例,也属于经典非平衡数据处理例子。
非平衡数据例子3:反欺诈
1.交易支付诈骗
2.电信诈骗
3.职工诈骗,欺诈群体一般占总人群2%
在银行,消费金融,金融科技公司做过反欺诈的朋友都知道,真实场景中欺诈客户常常在
2%左右,甚至更低。风控模型对于捕捉欺诈客户非常吃力,因为模型训练数据时就会遇到坏客户占比太低的难题。

机器学习领域有的很多解决非平衡数据的方法,我罗列了一些常用的方法,包括
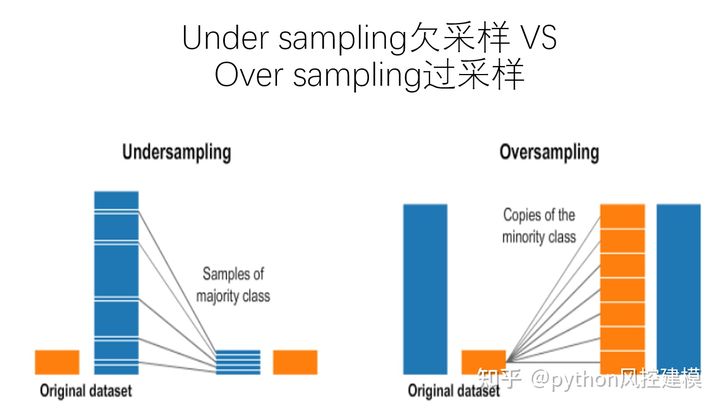
Under sampling欠采样
Over sampling过采样
SMOTE(synthetic minority over0sampling technique)非直接对少数类进行重采样,而是设计算法来人工合成一些新的少数样本。实际测试中,此方法效果较好
class_weight参数调整
其它算法解决方案

数据分析中的过采样和欠采样是用于调整数据集的类分布(即所表示的不同类/类别之间的比率)的技术。这些术语用于统计抽样、调查设计方法和机器学习。过采样和欠采样是相反且大致等效的技术。过采样和欠采样原理如下图:
SMOTE

有多种方法可用于对典型分类问题中使用的数据集进行过采样(使用分类算法对一组图像进行分类,给定一组带标签的训练图像)。最常见的技术被称为 SMOTE:合成少数过采样技术。[4]为了说明这种技术是如何工作的,考虑一些训练数据,其中有s 个样本,以及数据特征空间中的f 个特征。请注意,为简单起见,这些特征是连续的。例如,考虑用于分类的鸟类数据集。我们想要对其进行过采样的少数类的特征空间可以是喙长、翼展和重量(都是连续的)。为了过采样,从数据集中取一个样本,并考虑它的k 个最近邻(在特征空间中)。要创建合成数据点,请获取这k 个邻居之一与当前数据点之间的向量。将此向量乘以介于 0 和 1 之间的随机数x。将其添加到当前数据点以创建新的合成数据点。
如果看不懂smote术语解释没关系,我用可视化图解smote原理。
如下图,红色数据是minority class,即占比较小的数据集,一共只有4个。
绿色数据是majority class,即占比较大的数据集,一共13个。
为了训练模型时解决非平衡数据问题,我们使用smote方法。
(备注:属于解读
具有丰富示例的类称为主要类或多数类,而示例很少(通常只有一个)的类称为次要类或少数类。
- 多数类:具有许多示例的不平衡分类预测建模问题中的类(或多个类)。
- 少数类:不平衡分类预测建模问题中的类,样本很少。
)
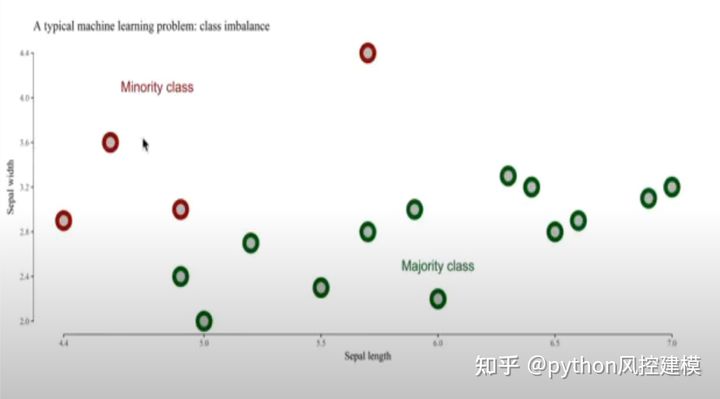
我们通过向量方法链接四个红色点,新的数据(创造的伪数据)就会出现在红色点链接的线上。
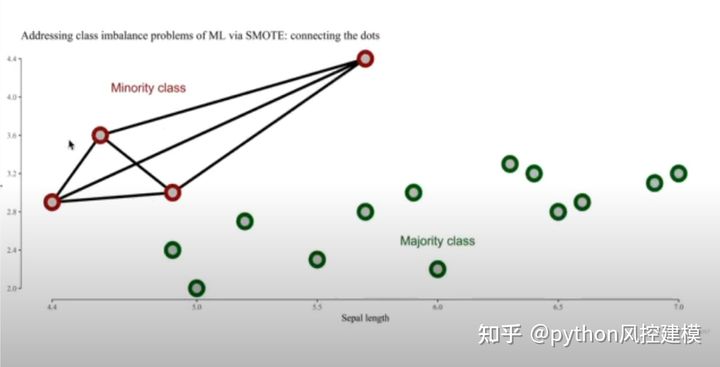
大家看,新创造的8个点出现在红色点链接的线上。这样红色数据集就有12个,蓝色数据集有13个,基本是5:5平衡了。
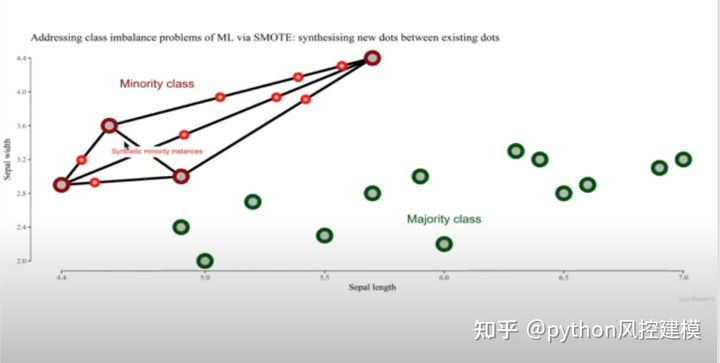
通过上述smote方法,我们解决了非平衡数据问题。
ADASYN
ADASYN是smote方法升级版。自适应合成采样方法或 ADASYN 算法建立在SMOTE方法的基础上,通过将分类边界的重要性转移到那些困难的少数类。ADASYN 根据学习难度对不同的少数类示例使用加权分布,其中为更难学习的少数类示例生成更多合成数据。
增强技术
数据分析中的数据增强是用于通过添加对现有数据或从现有数据新创建的合成数据稍加修改的副本来增加数据量的技术。它充当正则化器,有助于在训练机器学习模型时减少过度拟合。
非平衡数据处理副作用
非平衡数据处理方法不是万能的,使用要非常小心,最好是机器学习经验丰富的朋友来处理较好。过采样,欠采样或smote方法都可能引起过拟合问题,这会导致模型过于具体。训练集的准确性很可能是很高的情况,但是新数据集的性能实际上却很差。
如果想了解真实非平衡数据处理案例和python脚本解决方案,欢迎学习《python金融风控评分卡模型和数据分析》课程:https://edu.51cto.com/sd/f2e9b
。此课程采用真实12万+信贷数据建模,并包含如何应用算法处理非平衡数据问题,并且显著提升模型性能,包括ks,auc,可谓一石二鸟。

不平衡数据学习不仅给数据研究界带来了重大的新挑战,而且在现实世界的数据密集型应用中提出了许多关键问题,从金融和生物医学数据分析等民用应用到安全和国防相关应用,如监控和军事数据分析。希望各位机器学习爱好者能关注此问题。
以上是关于非平衡数据(imbalanced data)的简单介绍的主要内容,如果未能解决你的问题,请参考以下文章
python使用imbalanced-learn的RepeatedEditedNearestNeighbours方法进行下采样处理数据不平衡问题
python使用imbalanced-learn的InstanceHardnessThreshold方法进行下采样处理数据不平衡问题
python使用imbalanced-learn的CondensedNearestNeighbour方法进行下采样处理数据不平衡问题
python使用imbalanced-learn的NeighbourhoodCleaningRule方法进行下采样处理数据不平衡问题
python使用imbalanced-learn的EditedNearestNeighbours方法进行下采样处理数据不平衡问题