Apache Metron从入门到落灰
Posted 马鹏飞
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Apache Metron从入门到落灰相关的知识,希望对你有一定的参考价值。
之前在安全方面有大数据处理方面需求,所以调研了几款处理引擎框架,就看到Apache Metron了,结果发现网上没几个文章写这个的。。。。
其中涉及到的组件会比较多,有部署软件用的Ambari(也可以用cdh)、zookeeper、Storm、HADOOP、KAFKA和数据处理的Nifi
先贴一些看下来总结的流程
Metron数据处理流程
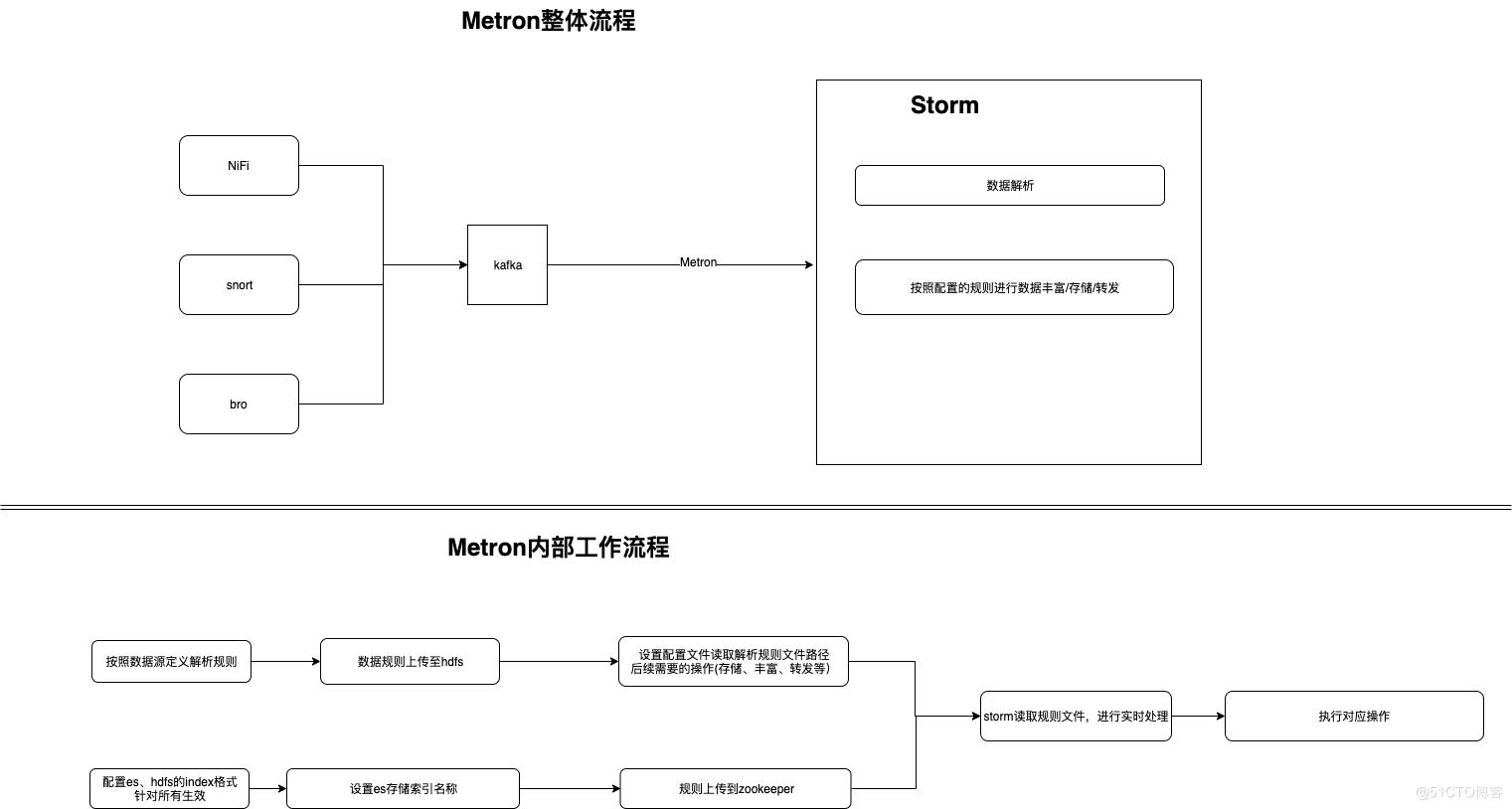
1.Metron介绍
Metron是一种多功能的安全遥测数据捕获、流分析和威胁响应平台,最早由Cisco公司的开源大数据系统安全框架项目OpenSOC迁移为Metron项目,现已晋升为Apache顶级项目。Metron提供的功能包括:日志的聚合、对网络包全面捕获的索引和存储、高级行为分析及数据浓缩,并可以将当前的威胁情报信息应用到安全遥测中。从概念上可划分为四个组件:数据捕获与摄取、实时数据处理、受保证的数据持久化和存储、用于驱动监控和风险报警服务的机器学习模型。
2.Metron架构及功能
作为一个大数据安全分析平台,Metron集合了众多优秀的开源架构和软件,因此具备非常强大的功能如下:
可扩展的接收器和分析器能够监视任何遥测数据源;
OpenSOC具备很强的扩展性,且支持各种遥测数据流;
支持对遥测数据流的异常检测和基于规则的实时报警;
通过预设时间使用Hadoop存储遥测收集的数据流;
支持使用ElasticSearch实现自动化实时索引遥测数据流;
支持通过Hive使用SQL查询Hadoop中的数据;
兼容ODBC/JDBC并且继承已有的分析工具;
支持自动生成报告、异常报警;
支持原数据包的抓取、存储和重组;
支持数据驱动的安全模型;
Metron中使用了多个开源架构,存储上基于Hadoop HDFS,实时处理实用Storm,实时索引查找借助ElasticSearch,除此之外还有一些其他的框架,整体如下图所示:

上图从左至右代表平台由下到上的层次,分别是数据源层—>数据采集层—>消息系统层—>实时处理层—>存储层—>分析处理层,下面我们分别就每一层的功能和实现的开源模块做一个简单的介绍。
数据源层:主要设定大数据分析平台的数据来源,基本有两个部分,一类是通过网络路由、网关等设备获取的数据包,将这些数据流量以副本的形式传递给上层的PCAP模块;另一个类则是通过部署遥测(Telemetry)传感器,从系统日志、HTTP流量、文件系统和其他用户/系统行为中获取到的日志信息;这些信息传递给上层的Flume模块;
数据收集层:该层主要收集初步处理获取的大量数据,一方面利用PCAP机制收集数据包,一方面利用Flume框架来收集大量的日志信息。 Flume是遵循Apache授权的开源项目,主要用于高可用、高可靠、分布式海量日志数据的收集、聚合和传输。Flume支持定制数据发送方,即可以定制获取何种类型的源数据,如支持console\\RPC\\text(文件)\\tail(Unix tail)\\syslog\\exec等。此外Flume还提供对数据进行简单处理,之后写到定制的数据接收方。(即,日志传输两端皆可自定义)。
消息系统层: 数据收集层将捕获的数据包和海量日志信息提交给了消息系统层,该层主要对这些数据包和日志包装为消息队列,可以便于上层Storm的实时处理。这里主要的软件是开源的Kafka,这主要用于日志处理的分布式消息队列,关注用户行为(登录、注销、文件操作等)和系统运行日志(CPU、内存、网络、进程信息等)。
实时处理层:下层处理形成的消息队列交由本层实时处理,OpenSOC使用了著名的Storm框架。Storm 是一个开源的在线流分析系统,可以方便地在一个集群中编写扩展复杂的实时计算,其用于实时处理就好比hadoop用于批处理。所谓实时,是指Storm保证每个消息都会得到处理,而且速度很快,比如在一个小集群中,Storm 每秒可以处理数以百万计的信息,而且用户可以使用任意语言进行mapreduce模型的开发。相较于hadoop,Storm 具有更高的容错性、更好的水平扩展以及快速可靠的消息处理优势,因此在实际中也得到了广泛的应用。
存储层:这个层的主要任务就是有效合理地将前面获得的数据存储到文件系统中。对于结构化数据,OpenSOC使用Hive 来实现;对于非结构化数据,则使用ElasticSearch 来实现。 Hive 是一个基于hadoop的数据仓库,其特点是可以将SQL语句与hadoop架构无缝对接,将SQL语句转换成mapreduce任务,从而实现了在hadoop集群上进行大数据的存储、查询与分析。 ElasticSearch是一个NoSQL搜索引擎,使用JSON通过HTTP来索引数据,可以这样理解,ElasticSearch可以帮助我们更方便地索引查询非结构化数据。 除了上面提到的两类,底层是基于Hadoop 的集群,利用Hbase 数据库来存储PCAP表。
分析处理层:在完成数据的收集、存储、查询之后,接下来就是对数据的分析工作,这里的分析工具可以使用R语言或Python编写,使用了PowerPivot(PP)和Tableau(TB)两类分析工具。其中PP工具是一组应用程序和服务,以极高的性能处理大型数据集;而TB则是一款企业智能化软件,主要用于提供数据分析,比如可视化、关联性分析等,所有的工作都基于浏览器进行。
部署Metron时各个开源软件和模块有一定的版本要求,具体如下:
Apache Flume 1.4.0版本及以上;
Apache Kafka 0.8.1版本及以上;
Apache Storm 0.9版本及以上;
Apache Hadoop 2.x系列版本均可;
Apache Hive 12版本以上,建议13版本;
Apache Hbase 0.94版本及以上;
ElasticSearch 1.1版本及以上;
mysql 5.6版本及以上;
Metron安装1-Ambari
| 测试环境信息: |
ip | 主机名 | 角色 | 额外装的软件 |
|---|---|---|---|---|
| node6 | 10.0.81.201 | Ambari server+Metron UI+zookeeper+Storm+HADOOP+KAFKA | ||
| node7 | 10.0.81.202 | Ambari Agent+Metron Agent+zookeeper+Storm+HADOOP+KAFKA | Nifi(任意选的一台机器) | |
| node8 | 10.0.81.203 | Ambari Agent+Metron Agent+zookeeper+Storm+HADOOP+KAFKA | ||
| node9 | 10.0.81.204 | ES节点(数据节点,给的磁盘大点) |
一、基础系统环境准备
1、安装基础依赖(所有节点)
yum install epel-release -y
yum update -y
yum -y install gcc vim fish # fish可以不装
yum install git wget curl rpm tar unzip scp bzip2 wget createrepo yum-utils ntp python-pip psutils python-psutil ntp libffi-devel gcc openssl-devel -y
pip install --upgrade pip
pip install requests2、系统调整
系统安全级别调整
ulimit -n 32768
ulimit -u 65536
echo -e "* - nofile 32768\\n* - nproc 65536" >> /etc/security/limits.conf
#### 禁用IPV6
sysctl -w net.ipv6.conf.all.disable_ipv6=1
sysctl -w net.ipv6.conf.default.disable_ipv6=1
echo -e "\\n# Disable IPv6\\nnet.ipv6.conf.all.disable_ipv6 = 1\\nnet.ipv6.conf.default.disable_ipv6 = 1" >> /etc/sysctl.conf
#### 关闭大叶内存
编辑/etc/default/grub文件
##### Change the line:
GRUB_CMDLINE_LINUX="crashkernel=auto rd.lvm.lv=cl/root rd.lvm.lv=cl/swap rhgb quiet"
##### To:
GRUB_CMDLINE_LINUX="crashkernel=auto rd.lvm.lv=cl/root rd.lvm.lv=cl/swap rhgb quiet transparent_hugepage=never"
改完执行:
grub2-mkconfig -o /boot/grub2/grub.cfg
#关闭防火墙
systemctl enable ntpd
systemctl start ntpd
iptables -P INPUT ACCEPT
iptables -P FORWARD ACCEPT
iptables -P OUTPUT ACCEPT
iptables -t nat -F
iptables -t mangle -F
iptables -F
iptables -X
iptables-save > /etc/sysconfig/iptables
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
sed -i \'s/SELINUX=enforcing/SELINUX=disabled/g\' /etc/selinux/config3、设置3台Ambari节点互相免密登录
ssh-keygen -t rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
node6上面:
scp ~/.ssh/id_rsa.pub node6:/tmp/id_rsa6.pub
scp ~/.ssh/id_rsa.pub node7:/tmp/id_rsa6.pub
scp ~/.ssh/id_rsa.pub node8:/tmp/id_rsa6.pub
node7上面:
scp ~/.ssh/id_rsa.pub node6:/tmp/id_rsa7.pub
scp ~/.ssh/id_rsa.pub node7:/tmp/id_rsa7.pub
scp ~/.ssh/id_rsa.pub node8:/tmp/id_rsa7.pub
node8上面:
scp ~/.ssh/id_rsa.pub node6:/tmp/id_rsa8.pub
scp ~/.ssh/id_rsa.pub node7:/tmp/id_rsa8.pub
scp ~/.ssh/id_rsa.pub node8:/tmp/id_rsa8.pub
node4上面:
scp ~/.ssh/id_rsa.pub node6:/tmp/id_rsa4.pub
scp ~/.ssh/id_rsa.pub node7:/tmp/id_rsa4.pub
scp ~/.ssh/id_rsa.pub node8:/tmp/id_rsa4.pub
scp ~/.ssh/id_rsa.pub node9:/tmp/id_rsa4.pub
4、添加主机名映射到/etc/hosts
echo "10.0.81.201 node6" > /etc/hosts
echo "10.0.81.202 node7" >> /etc/hosts
echo "10.0.81.203 node8" >> /etc/hosts
echo "127.0.0.1 localhost" >> /etc/hosts5、重启服务器
二、安装基础软件
1、安装java8
yum install java-1.8.0-openjdk java-1.8.0-openjdk-devel -y
export JAVA_HOME=$(readlink -f /usr/bin/java | sed "s_/jre/bin/java__")
echo \'export JAVA_HOME=$(readlink -f /usr/bin/java | sed "s_/jre/bin/java__")\' > /etc/profile.d/java_18.sh
chmod +x /etc/profile.d/java_18.sh
source /etc/profile.d/java_18.sh2、安装maven(单独的es节点可以不用装)
wget http://archive.apache.org/dist/maven/maven-3/3.3.9/binaries/apache-maven-3.3.9-bin.tar.gz
tar -zxf apache-maven-3.3.9-bin.tar.gz
mv apache-maven-3.3.9 /opt
PATH=/opt/apache-maven-3.3.9/bin:$PATH
echo \'export PATH=/opt/apache-maven-3.3.9/bin:$PATH\' > /etc/profile.d/maven.sh
chmod +x /etc/profile.d/maven.sh
echo "export MAVEN_HOME=/opt/apache-maven-3.3.9" >> /etc/profile
echo "export PATH=\\$MAVEN_HOME/bin/:\\$PATH" >> /etc/profile
source /etc/profile
mvn -v3、安装并启用docker(Ambari节点上)
yum install docker-io -y
systemctl start docker4、安装npm(Metron UI服务器上)
yum install npm -y5、安装mysql server(在Ambari UI节点上)
yum install mariadb-server -y启动并初始化mysql
systemctl start mariadb
systemctl enable mariadb
systemctl status mariadb
mysql_secure_installation在所有节点上安装 JAVA MYSQL 连接器
yum install mysql-connector-java -y三、构建Metron
1、下载Metron
cd /opt
git clone https://github.com/apache/metron
cd metron
git checkout Metron_0.4.1
#构建Metron With HDP 2.5
cd metron
mvn clean package -DskipTests -T 2C -P HDP-2.5.0.0,mpack
cd metron-deployment/packaging/docker/rpm-docker
mvn clean install -DskipTests -PHDP-2.5.0.02、复制下载的文件构建本地源
ssh root@node2 mkdir /localrepo
scp /localrepo/*rpm root@node2:/localrepo/
ssh root@node2 createrepo /localrepo3、获取和Hadoop服务创建logrotate脚本
wget -O /etc/logrotate.d/metron-ambari https://raw.githubusercontent.com/apache/metron/master/metron-deployment/roles/ambari_common/templates/metron-hadoop-logrotate.yml
sed -i \'s/^ {{ hadoop_logrotate_frequency }}.*$/ daily/\' /etc/logrotate.d/metron-ambari
sed -i \'s/^ rotate {{ hadoop_logrotate_retention }}.*$/ rotate 30/\' /etc/logrotate.d/metron-ambari
chmod 0644 /etc/logrotate.d/metron-ambari四、安装Ambari2.4 With HDP 2.5
1、关掉python证书验证(Centos7上才需要,Centos6不需要)
sed -i \'s/verify=platform_default/verify=disable/\' /etc/python/cert-verification.cfg
2、下载并安装Ambari Server
wget -nv http://public-repo-1.hortonworks.com/ambari/centos7/2.x/updates/2.4.3.0/ambari.repo -O /etc/yum.repos.d/ambari.repo
yum install ambari-server -y
ambari-server setup -s
ambari-server install-mpack --mpack=/root/metron/metron-deployment/packaging/ambari/metron-mpack/target/metron_mpack-0.4.1.0.tar.gz --verbose
ambari-server start
不出意外已经可以访问ambari-server的ui了,在http://ambari-server-ip:8080/ 默认用户名密码 admin/admin贴一段网站原文介绍ambari可以做的事儿 展开源码
#设置集群名称
#选择版本
#选择安装哪些节点(前边免密登录一定要设置好),会安装ambari-agent
#节点安装成功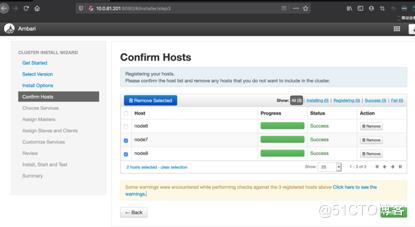
#选择要安装的组件(Metron必须要安装的组件:HDFS、Zookeeper、Storm、Metron、KAFKA、Elasticsearch)
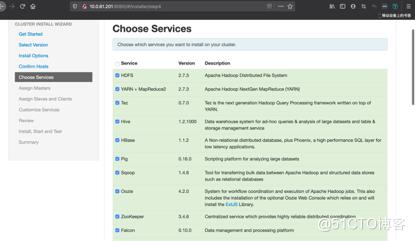
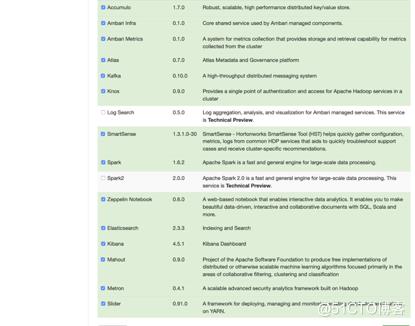
#确认每个组件都装在哪些节点以及对应的角色设置
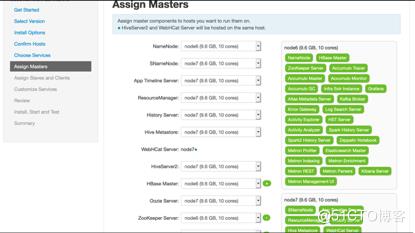
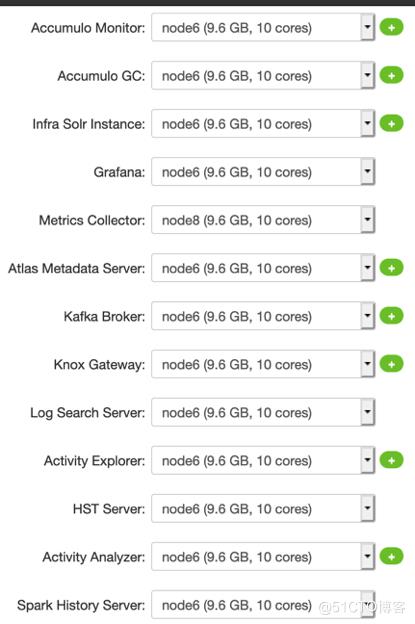
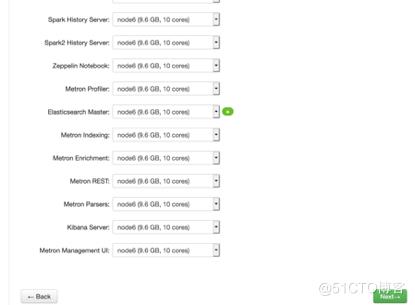
#配置客户端及角色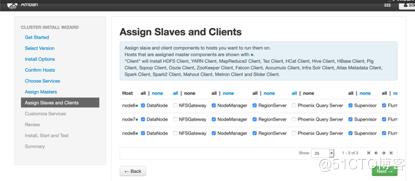
#每个组件配置文件确认,有问题的进行调整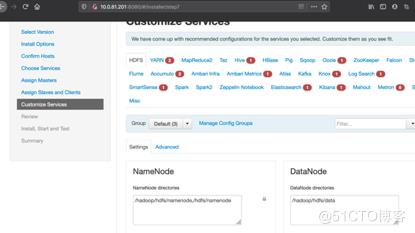
至此,通过Ambari安装这些集群组件以及完成
3、Metron安装2-Metron初始化
一、Metron服务配置
1、数据库初始化
创建数据库并允许访问
mysql -u root -p1
CREATE USER \'metron\'@\'localhost\' IDENTIFIED BY \'metron\';
CREATE DATABASE IF NOT EXISTS metronrest;
GRANT ALL PRIVILEGES ON metronrest.* TO \'metron\'@\'localhost\';
quit
设置Metron REST的账号(否则登录不了)
mysql -u root -p1
use metronrest;
insert into users (username, password, enabled) values (\'admin\', \'admin\',1);
insert into authorities (username, authority) values (\'admin\', \'ROLE_USER\');
设置Metron Mysql jdbc Driver路径
cd $METRON_HOME/lib
wget https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-5.1.45.tar.gz
tar xf mysql-connector-java-5.1.45.tar.gz2、确保REST这几个都设置了
Metron JDBC client path: /usr/share/java/mysql-connector-java.jar
Metron JDBC Driver: com.mysql.jdbc.Driver
Metron JDBC password: <DB PASSWORD>
Metron JDBC platform: mysql
Metron JDBC URL: jdbc:mysql://127.0.0.1:3306/<DB NAME>
Metron JDBC username: <DB USERNAME>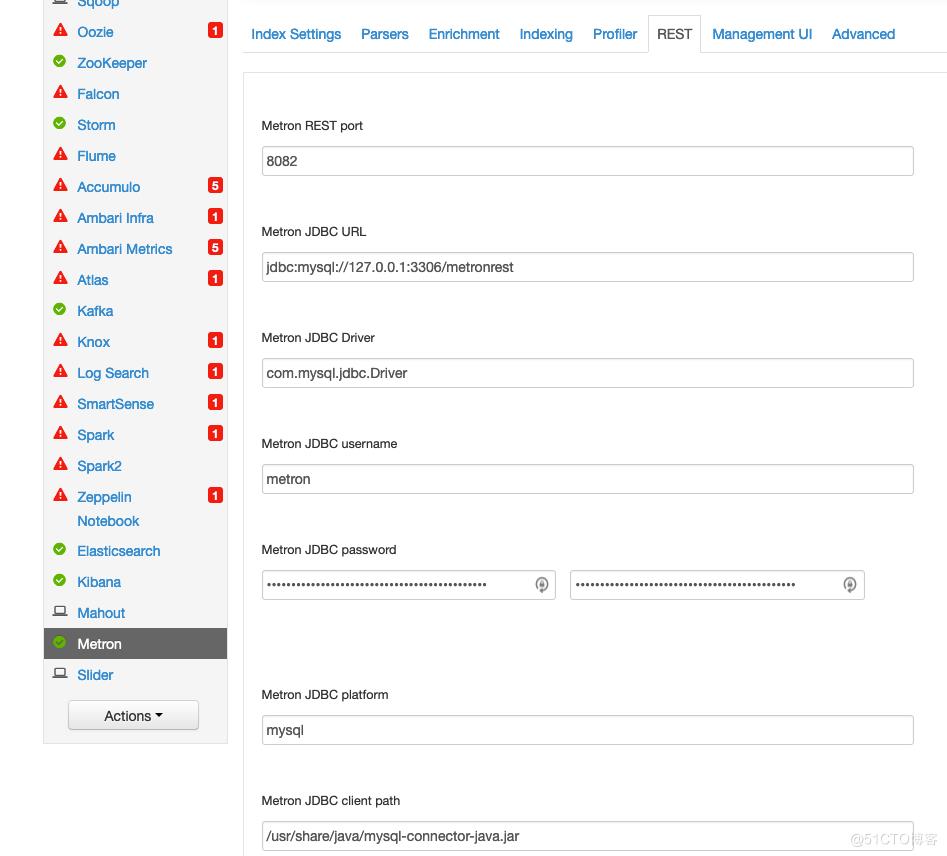
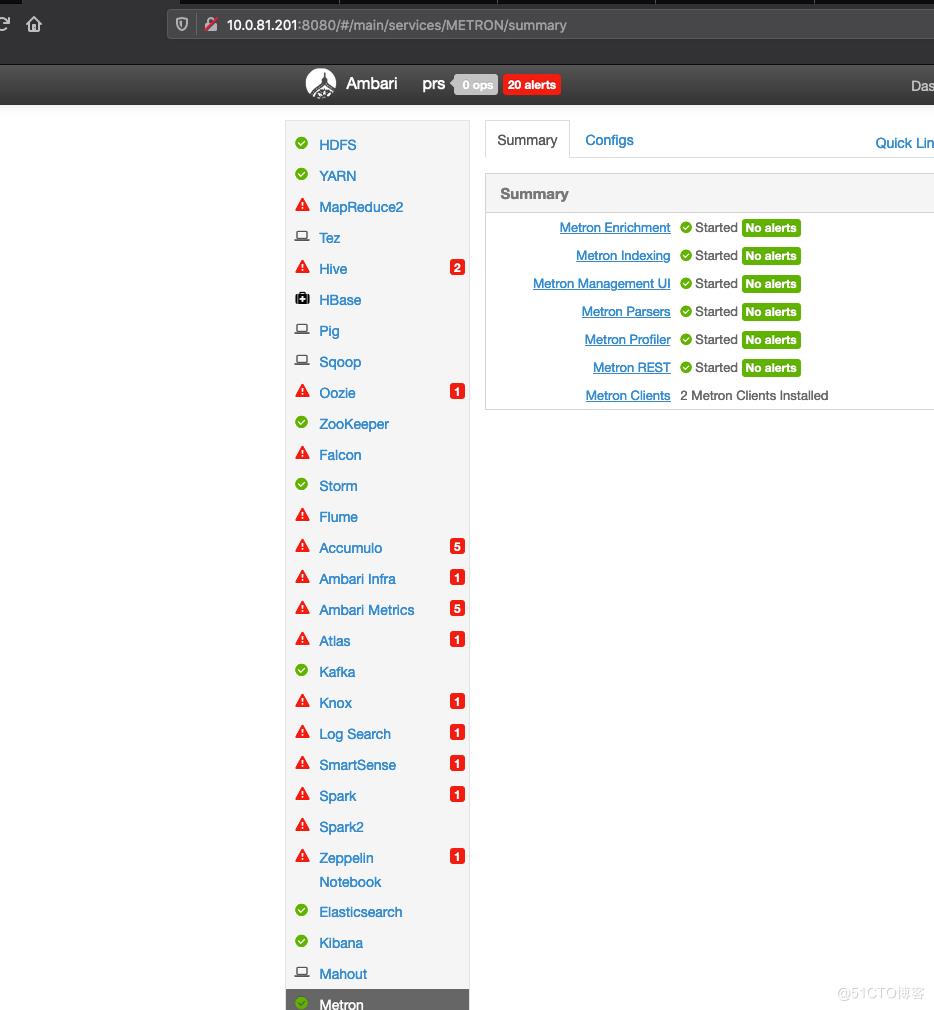
3、启动相关服务(注意启动顺序 Zookeeper->HDFS->KAFKA->Storm->Elasticsearch→Metron)
4、访问相关页面
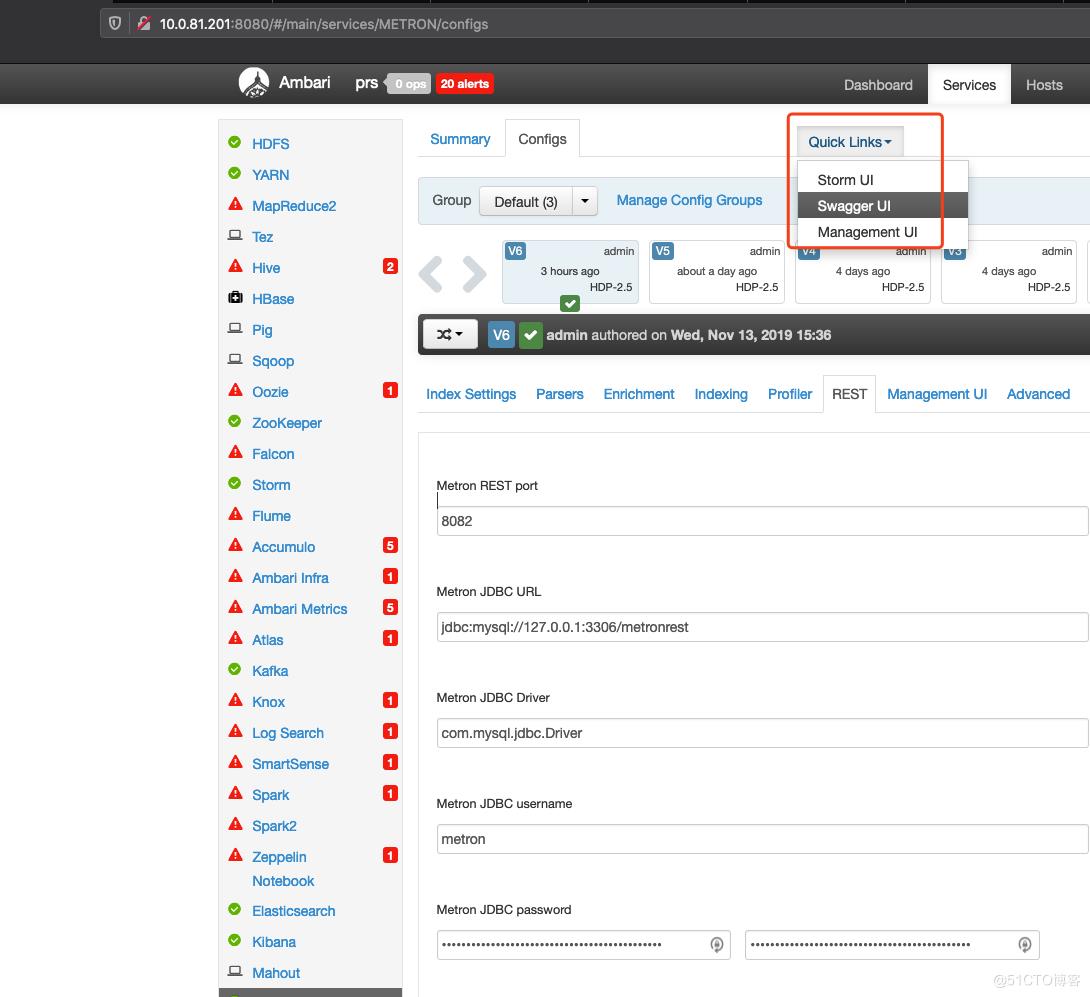
确保metron ,storm这几个页面都能正常访问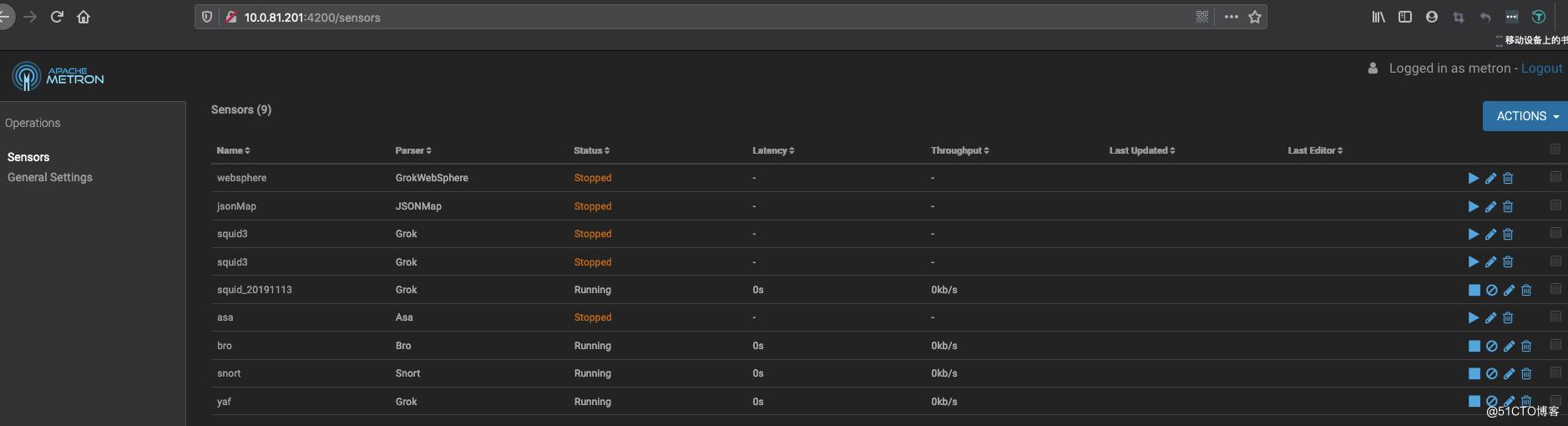
至此,Metron安装已经完成了
4、Metron安装3-通过Nifi接入squid的log
实现的效果是squid中产生的access log通过Nifi实时输出到kafka,然后Metron从kafka取到数据后进行解析,存储、丰富
一、kafka增加topic(在任意一台kafka server上执行)
新建kafka topic
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --zookeeper 127.0.0.1:2181 --create --topic squid-20191113 --partitions 1 --replication-factor 1
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --zookeeper 127.0.0.1:2181 --list二、安装Nifi(任意一个客户端)
Download NiFi.
cd /usr/lib
wget http://public-repo-1.hortonworks.com/HDF/centos6/1.x/updates/1.2.0.0/HDF-1.2.0.0-91.tar.gz
tar -zxvf HDF-1.2.0.0-91.tar.gz
Edit the NiFi configuration to update the port of the NiFi web app: nifi.web.http.port=8089
cd HDF-1.2.0.0/nifi
vi conf/nifi.properties
//update nifi.web.http.port to 8089
Install NiFi as service.
bin/nifi.sh install nifi
Start the NiFi Service.
service nifi start
Go to the NiFi Web: http://$NIFI_HOST:8089/nifi/三、安装squid
sudo yum install squid
sudo service squid start
生成的访问日志都会存在:/var/log/squid
手动生成访问记录:
squidclient -h 127.0.0.1 "http://www.aliexpress.com/af/shoes.html?ltype=wholesale&d=y&origin=n&isViewCP=y&catId=0&initiative_id=SB_20160622082445&SearchText=shoes"
squidclient -h 127.0.0.1 "http://www.help.1and1.co.uk/domains-c40986/transfer-domains-c79878"
squidclient -h 127.0.0.1 "http://www.pravda.ru/science/"
squidclient -h 127.0.0.1 "http://www.brightsideofthesun.com/2016/6/25/12027078/anatomy-of-a-deal-phoenix-suns-pick-bender-chriss"
squidclient -h 127.0.0.1 "https://www.microsoftstore.com/store/msusa/en_US/pdp/Microsoft-Band-2-Charging-Stand/productID.329506400"
squidclient -h 127.0.0.1 "https://tfl.gov.uk/plan-a-journey/"
squidclient -h 127.0.0.1 "https://www.facebook.com/Africa-Bike-Week-1550200608567001/"
squidclient -h 127.0.0.1 "http://www.ebay.com/itm/02-Infiniti-QX4-Rear-spoiler-Air-deflector-Nissan-Pathfinder-/172240020293?fits=Make%3AInfiniti%7CModel%3AQX4&hash=item281a4e2345:g:iMkAAOSwoBtW4Iwx&vxp=mtr"
squidclient -h 127.0.0.1 "http://www.recruit.jp/corporate/english/company/index.html"
squidclient -h 127.0.0.1 "http://www.lada.ru/en/cars/4x4/3dv/about.html"
squidclient -h 127.0.0.1 "http://www.help.1and1.co.uk/domains-c40986/transfer-domains-c79878"
squidclient -h 127.0.0.1 "http://www.aliexpress.com/af/shoes.html?ltype=wholesale&d=y&origin=n&isViewCP=y&catId=0&initiative_id=SB_20160622082445&SearchText=shoes"四、配置Nifi数据到Metron(输出到kafka)
拖两个process到主界面,分别右击configuration进行配置
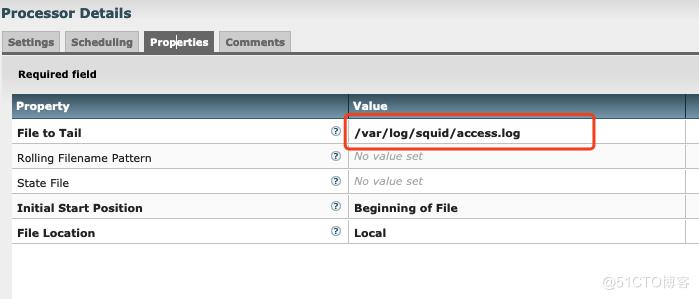
第一个类别GetFIle,用来从/var/log/squid/access.log实时获取数据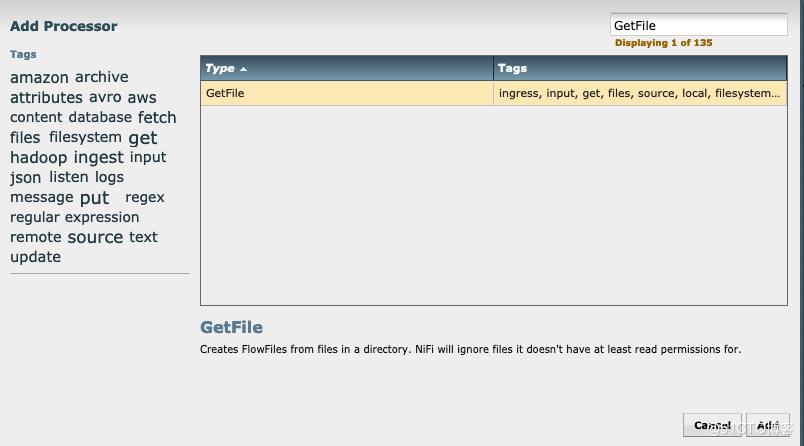
第二个类别PutKafka,用于输出到kafka
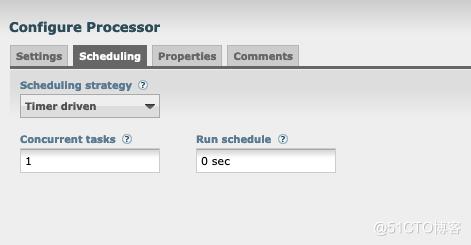
可以手动访问几条数据测试,然后到kakfa端看看有没有数据
手动往kafka塞数据方法:
cat /var/log/squid/access_new.log | ./kafka-console-producer.sh --broker-list node6:6667 --topicid_20191113
获取数据方法:
/usr/hdp/current/kafka-broker/bin/kafka-console-consumer.sh --topic squid_20191113 --bootstrap-server node6:6667 --new-consumer
#到这里 NIfi配置已经完成了,确保kafka中有数据
五、配置Metron处理数据(都是在Metron Server上执行的)
1、配置解析规则
找一条/var/log/squid/access.log中的数据样例,然后配置对应的grok解析规则,可以在http://grokconstructor.appspot.com/do/match 验证规则是不是能匹配成功
#新建解析规则并上传到HDFS上,这个SQUID_20191113 可以自定义,但是要和后面的名字一样
echo "SQUID_20191113 %{NUMBER:timestamp}.*%{INT:elapsed} %{IP:ip_src_address} %{WORD:action}/%{NUMBER:code} %{NUMBER:bytes} %{WORD:method} %{NOTSPACE:url}.*%{IP:ip_dst_addr}" >> /tmp/squid_20191113
# 查看dhfs上的文件列表
hdfs dfs -ls /apps/metron/patterns/
# 上传解析文件到hdfs上
su - hdfs
hdfs dfs -put -f /tmp/squid_20191113 /apps/metron/patterns/
exit
#确认dhfs上的文件列表已经有squid_20191113了
hdfs dfs -ls /apps/metron/patterns/2、设置Metron解析拓扑
#新建配置文件
/usr/metron/0.4.1/config/zookeeper/parsers/squid_20191113.json
{
"parserClassName": "org.apache.metron.parsers.GrokParser", #设置解析引擎,可以选Grok或者java
"sensorTopic": "squid_20191113", #指定kafka中的topic名字,和第四步对应
"parserConfig": {
"grokPath": "/apps/metron/patterns/squid_20191113",
"patternLabel": "SQUID_20191113", # 指定匹配的名字,和上一步/tmp/squid_20191113中的名字要对应
"timestampField": "timestamp"
},
"fieldTransformations" : [
{
"transformation" : "STELLAR"
,"output" : [ "full_hostname", "domain_without_subdomains" ]
,"config" : {
"full_hostname" : "URL_TO_HOST(url)"
,"domain_without_subdomains" : "DOMAIN_REMOVE_SUBDOMAINS(full_hostname)"
}
}
]
}
3、设置索引类型和批量大小
#如果不需要存hdfs和solr可以不用加对应的部分
/usr/metron/0.4.1/config/zookeeper/indexing/squid_20191113.json
{
"hdfs" : {
"index": "squid_20191113",
"batchSize": 5,
"enabled" : true
},
"elasticsearch" : {
"index": "squid_20191113",
"batchSize": 5,
"enabled" : true
},
"solr" : {
"index": "squid_20191113",
"batchSize": 5,
"enabled" : true
}
}4、设置全局参数,对所有规则生效
cat /usr/metron/0.4.1/config/zookeeper/global.json
{
"es.clustername": "metron",
"es.ip": "node9:9300",
"es.date.format": "yyyy.MM.dd.HH",
"parser.error.topic": "indexing",
"update.hbase.table": "metron_update",
"update.hbase.cf": "t"
}
5、上传配置到zookeeper
/usr/metron/0.4.1/bin/zk_load_configs.sh --mode PUSH -i /usr/metron/0.4.1/config/zookeeper -z 127.0.0.1:2181
6、验证
/usr/metron/0.4.1/bin/zk_load_configs.sh -m DUMP -z 127.0.0.1:2181
#配置es字段模板,在es服务器上执行(这里是2.x的,根据实际情况可能不一样) 展开源码
7、 启动解析器
/usr/metron/0.4.1/bin/start_parser_topology.sh -k 127.0.0.1:6667 -z 127.0.0.1:2181 -s squid_20191113
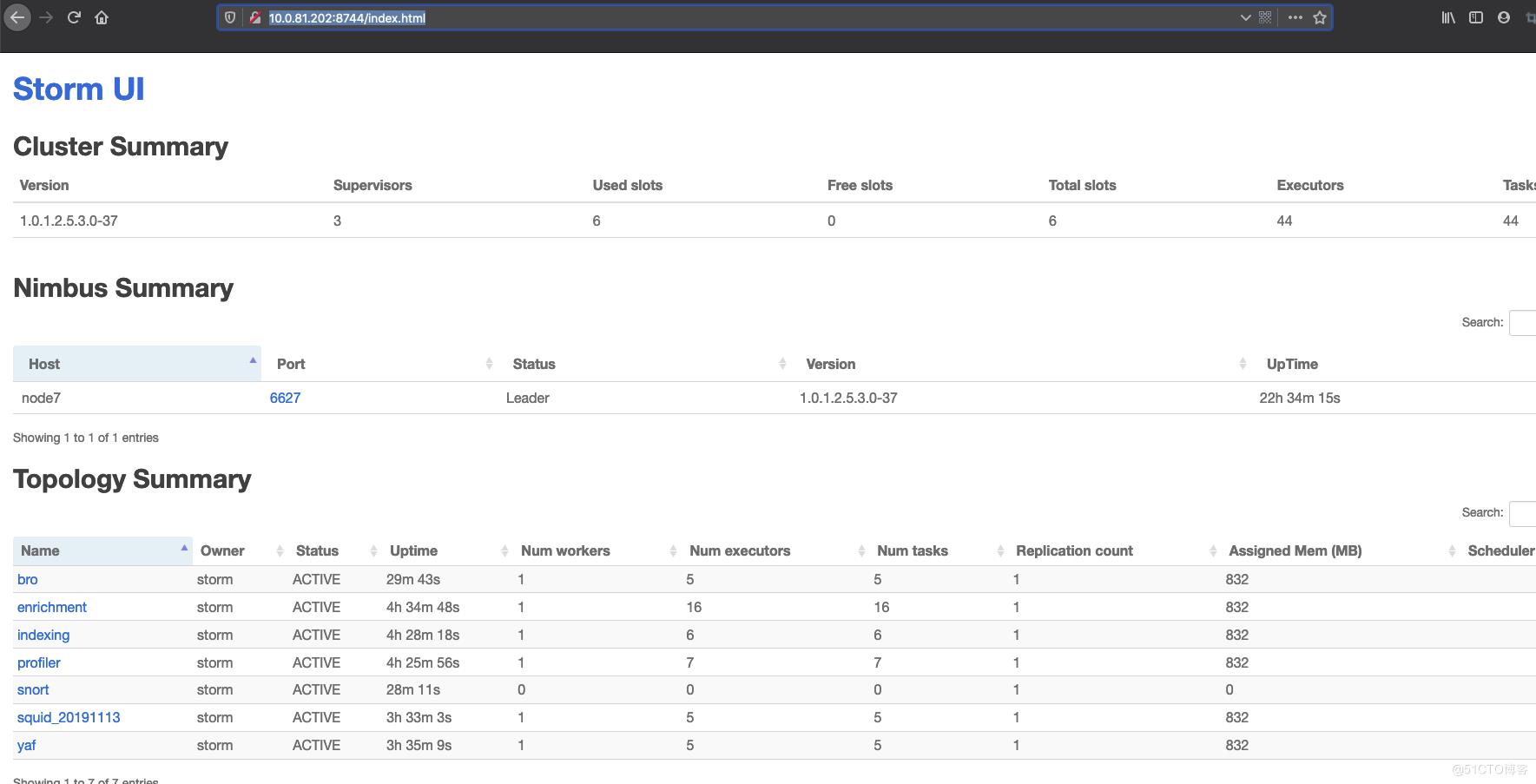
8、验证是否工作正常
http://10.0.81.202:8744/index.html
打开storm ui可以看到新的任务已经被加进来了,(如果发现新加进来的task的Num Workers为0,说明资源不够,可以点到其他的task里面kill掉)
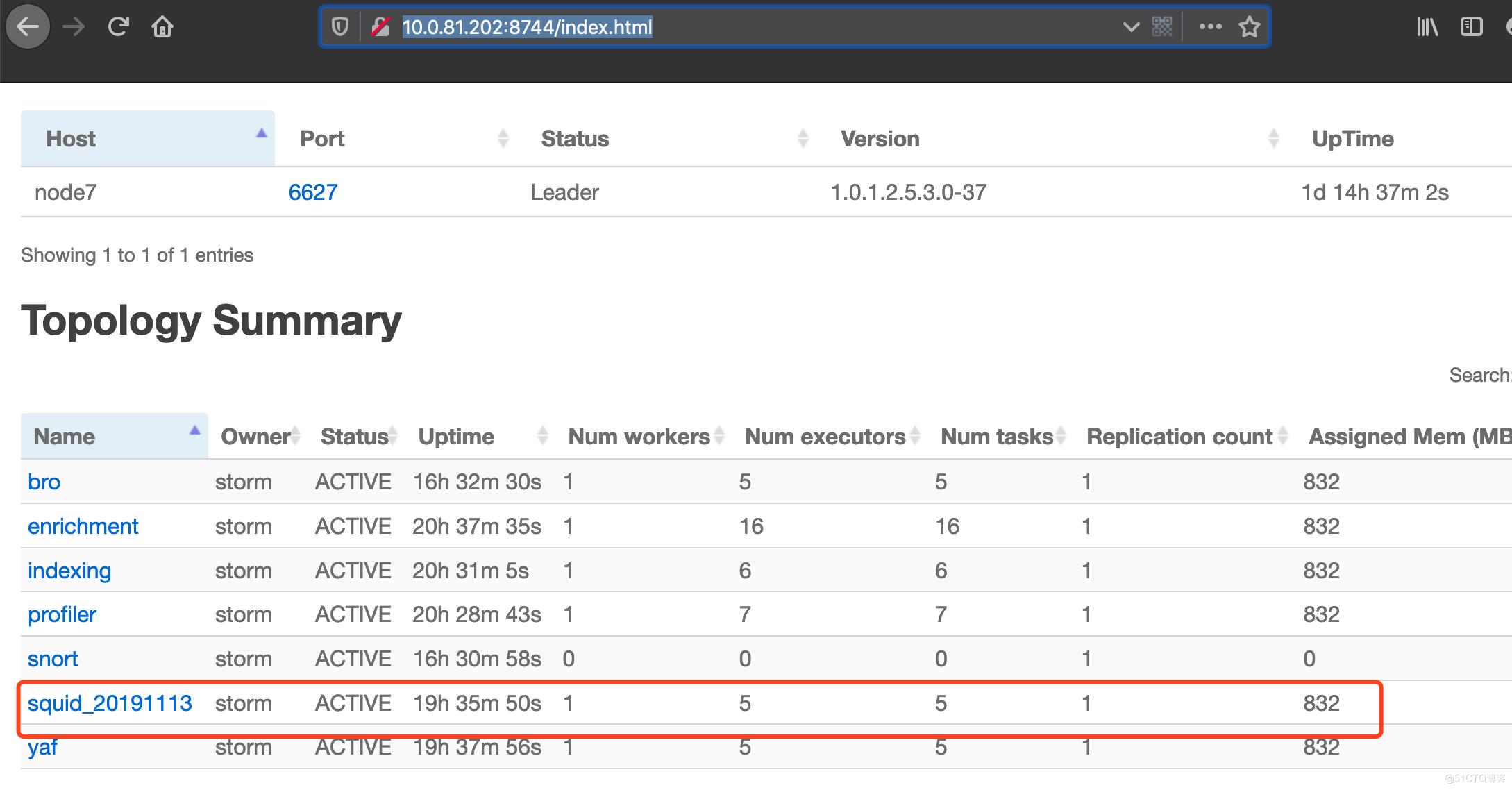
可以看到具体task的处理情况
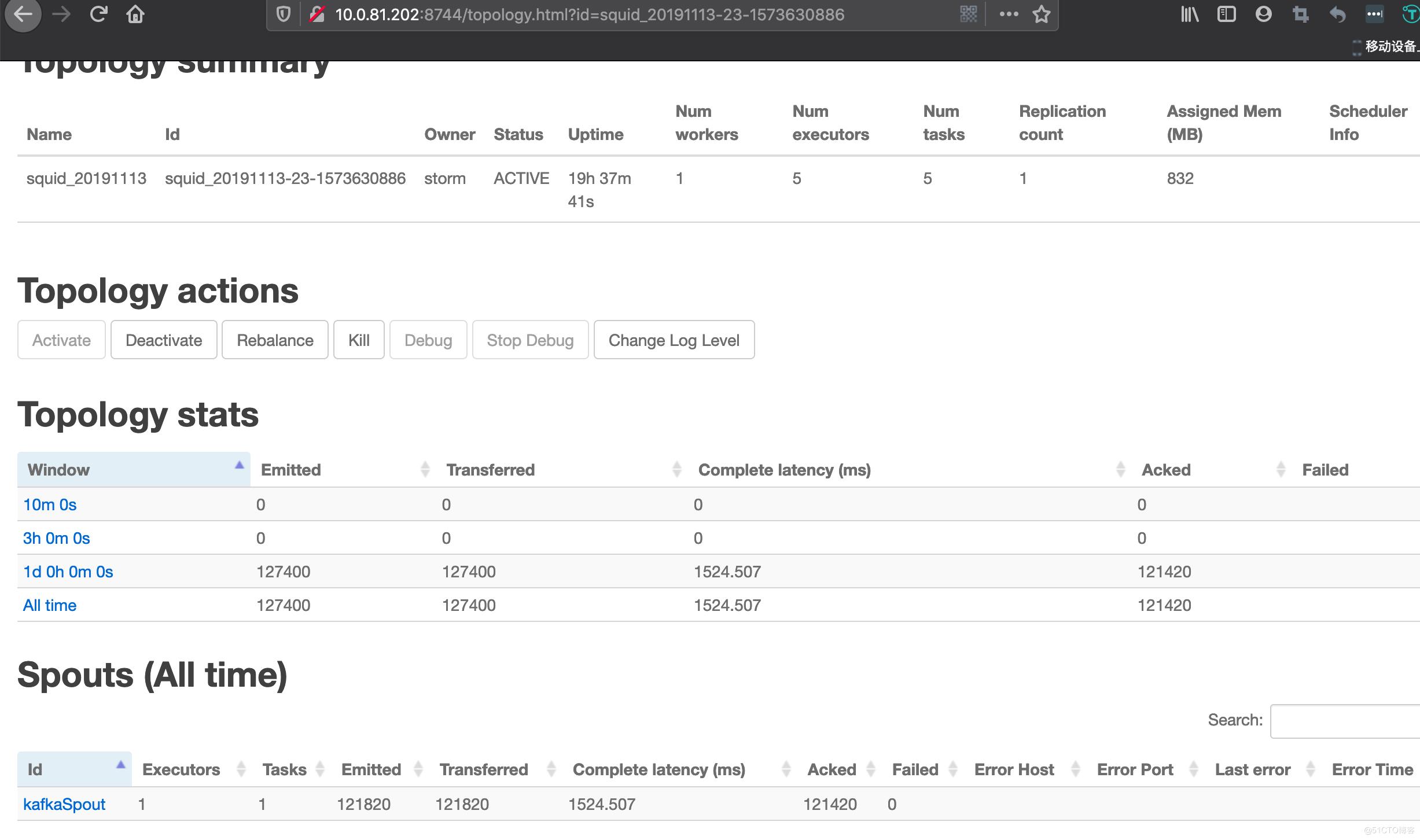
验证es入库:
如果看到有好多error_index 说明对应的数据grok的规则不能匹配,拿出来具体数据再跟grok的规则去网站上验证就知道了,然后修改对应的规则进行兼容
curl -XGET \'http://10.0.81.204:9200/_cat/indices?pretty\'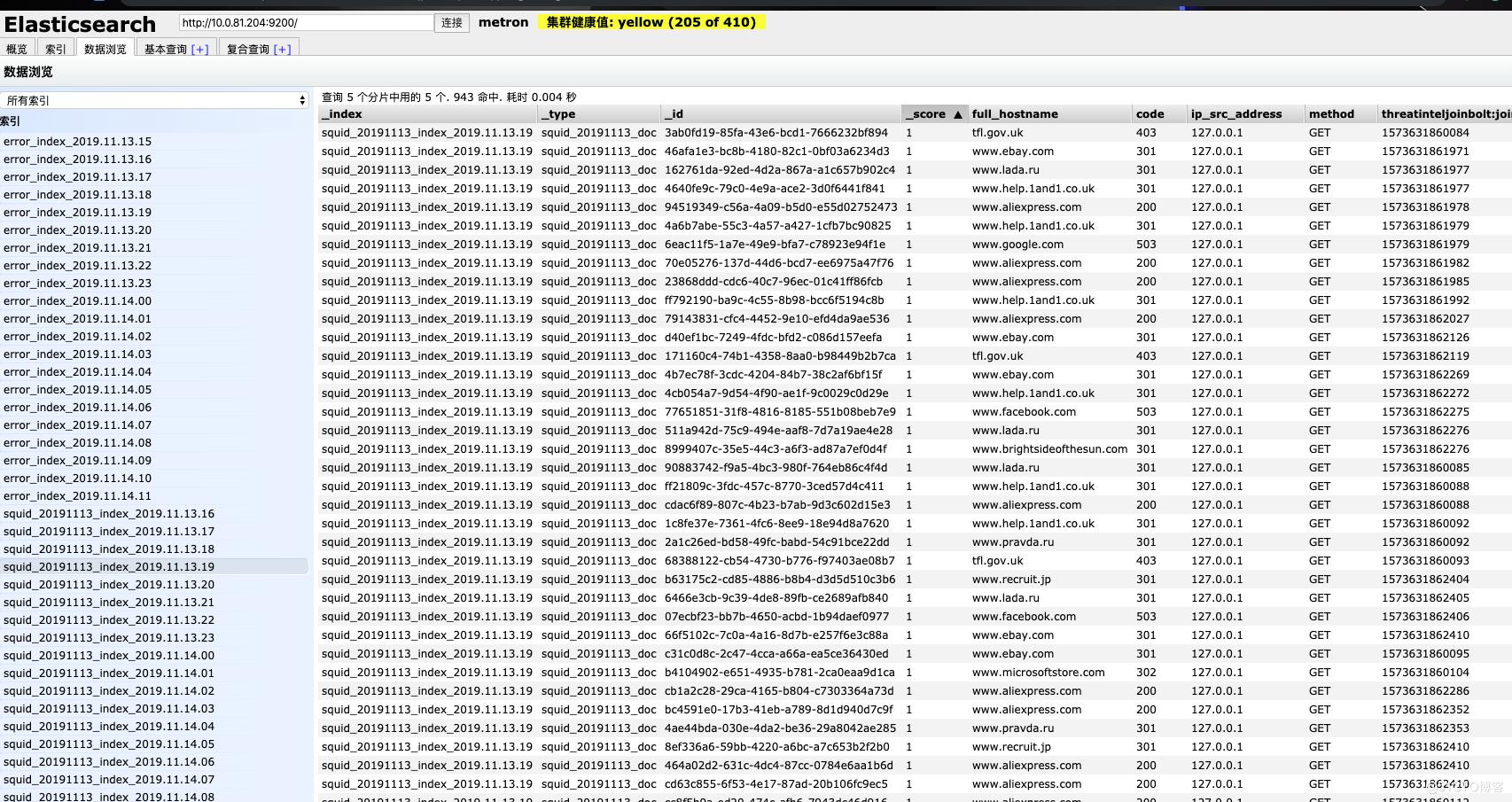
要配置Metron的Dashboard可以:
https://cwiki.apache.org/confluence/display/METRON/Enhancing+Metron+Dashboard
效果图:
https://cwiki.apache.org/confluence/display/METRON/Metron+Dashboard
六、构建Metron Dashboard
在kibana上构建效果图
1、settings中选择indices
2、在Visualize中按照想要的条件构建图
可以多选几个条件,选择不同的图案,分布保存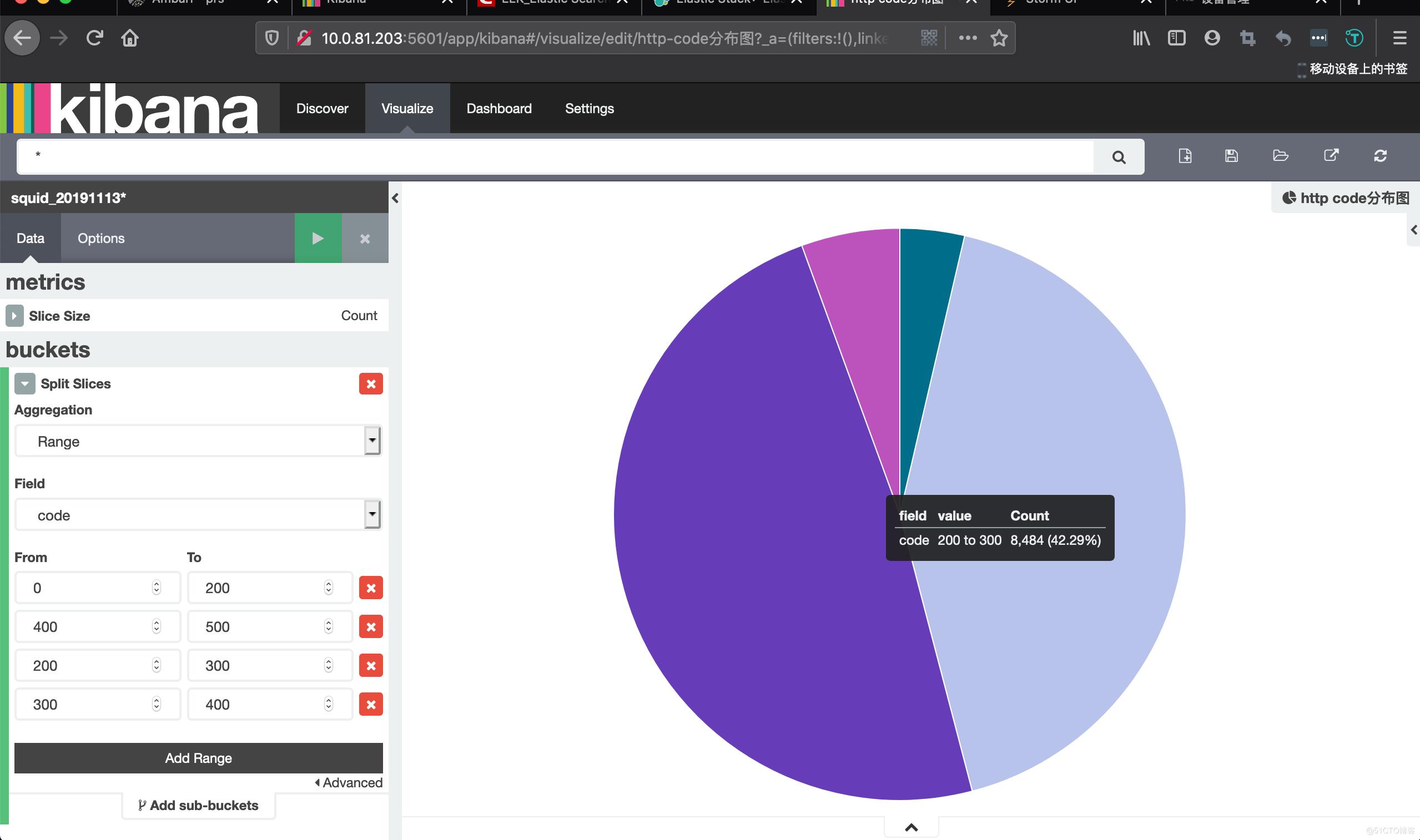
3、Dashboard中新建视图,可以将Visualize中的多个图形,展示在一起,形成一个视图
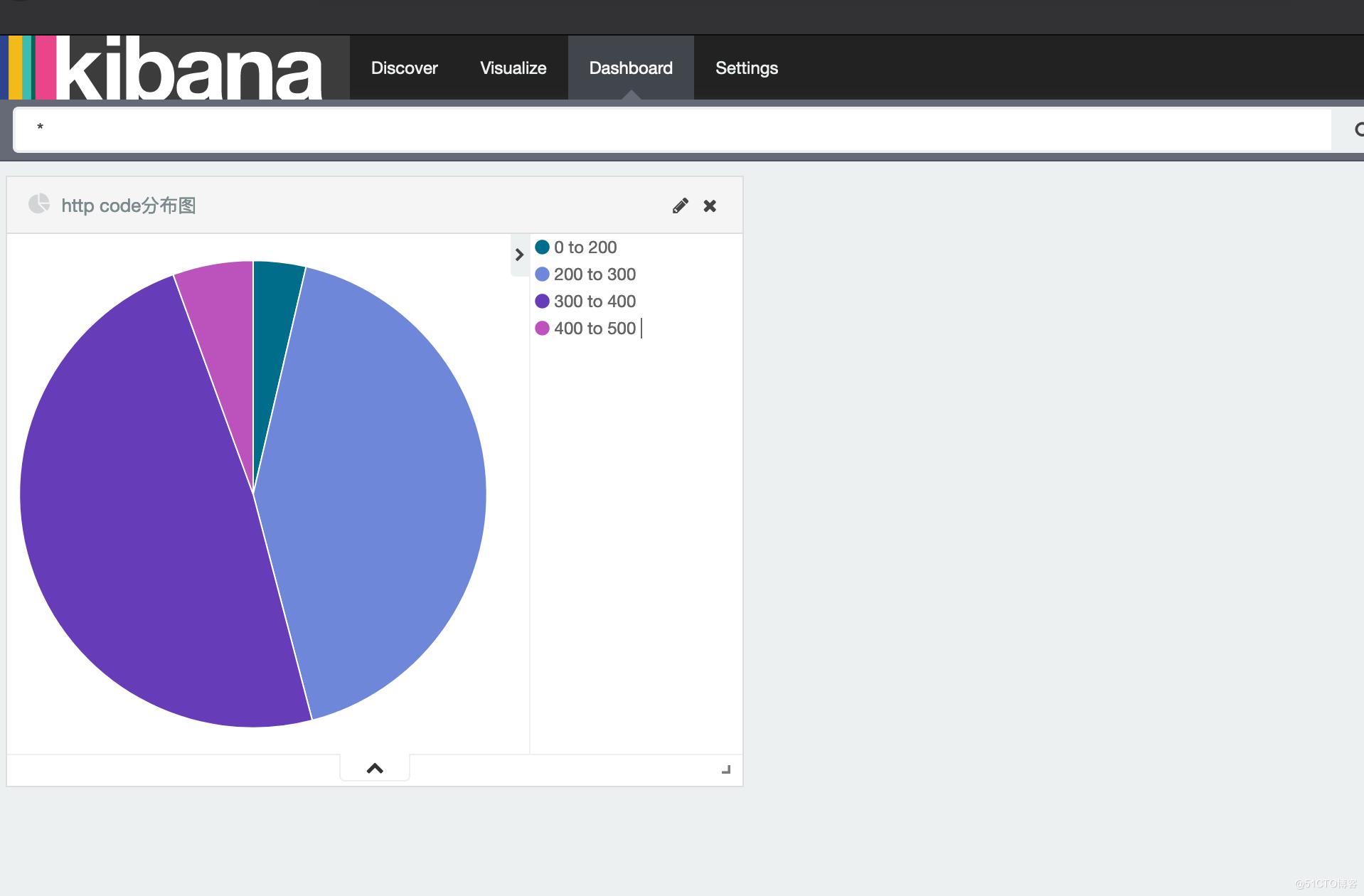
关键配置文件的路径
定义es server地址,格式
/usr/metron/0.4.1/config/zookeeper/global.json
{
"es.clustername": "metron",
"es.ip": "node9:9300",
"es.date.format": "yyyy.MM.dd.HH",
"parser.error.topic": "indexing",
"update.hbase.table": "metron_update",
"update.hbase.cf": "t"
}
定义解析后存储地方(es,hbase等)
/usr/metron/0.4.1/config/zookeeper/indexing/squid.json
{
"elasticsearch": {
"index": "squid",
"batchSize": 1,
"enabled" : true
}
}
定义Storm worker数,kafka,zookeeper服务器地址,hdfs output相关
/usr/metron/0.4.1/config/elasticsearch.properties
定义解析拓扑,(先按照数据结构做个GrokParser,指定数据解析规则在hdfs中位置等信息)
/usr/metron/0.4.1/flux/squid/remote.yaml
storm grok解析关键源码位置:
storm log目录:
/var/log/storm/workers-artifacts
遇到的一些报错
1、Ambari 客户端安装失败:
确认:
1、确认是否可以相互免密登录
2、sed -i \'s/verify=platform_default/verify=disable/\' /etc/python/cert-verification.cfg2、Metron-rest 服务启动失败,报错:Caused by: java.lang.IllegalStateException: Cannot load driver class: com.mysql.jdbc.Driver
解决办法:
添加到指定路径下
cd $METRON_HOME/lib
wget https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-5.1.45.tar.gz
tar xf mysql-connector-java-5.1.45.tar.gz
添加jdbc路径
ambari界面->Metron->Config->Rest->Metron JDBC client path 设置为:
/usr/share/java/mysql-connector-java.jar
3、Metron rest 登录失败,/var/log/metron/metron-rest.log显示Access denied for user \'metron\'@\'localhost\' (using password: YES)
进入mysql确认: mysql数据库中是否允许metron用户登录
Mysql -uroot -p
Use mysql;
select Host,User,Password from user;
确认有这一行:
localhost | metron | *BD5EC8C0CA578DE3841DD23E25B399A2C432D635
4、ambari-metrics-monitor 安装失败
stderr:
Traceback (most recent call last):
File "/var/lib/ambari-agent/cache/common-services/AMBARI_METRICS/0.1.0/package/scripts/metrics_collector.py", line 148, in <module>
AmsCollector().execute()
File "/usr/lib/python2.6/site-packages/resource_management/libraries/script/script.py", line 285, in execute
method(env)
File "/var/lib/ambari-agent/cache/common-services/AMBARI_METRICS/0.1.0/package/scripts/metrics_collector.py", line 36, in install
self.install_packages(env)
File "/usr/lib/python2.6/site-packages/resource_management/libraries/script/script.py", line 576, in install_packages
retry_count=agent_stack_retry_count)
File "/usr/lib/python2.6/site-packages/resource_management/core/base.py", line 155, in __init__
self.env.run()
File "/usr/lib/python2.6/site-packages/resource_management/core/environment.py", line 160, in run
self.run_action(resource, action)
File "/usr/lib/python2.6/site-packages/resource_management/core/environment.py", line 124, in run_action
provider_action()
File "/usr/lib/python2.6/site-packages/resource_management/core/providers/package/__init__.py", line 54, in action_install
self.install_package(package_name, self.resource.use_repos, self.resource.skip_repos)
File "/usr/lib/python2.6/site-packages/resource_management/core/providers/package/yumrpm.py", line 51, in install_package
self.checked_call_with_retries(cmd, sudo=True, logoutput=self.get_logoutput())
File "/usr/lib/python2.6/site-packages/resource_management/core/providers/package/__init__.py", line 86, in checked_call_with_retries
return self._call_with_retries(cmd, is_checked=True, **kwargs)
File "/usr/lib/python2.6/site-packages/resource_management/core/providers/package/__init__.py", line 98, in _call_with_retries
code, out = func(cmd, **kwargs)
File "/usr/lib/python2.6/site-packages/resource_management/core/shell.py", line 70, in inner
result = function(command, **kwargs)
File "/usr/lib/python2.6/site-packages/resource_management/core/shell.py", line 92, in checked_call
tries=tries, try_sleep=try_sleep)
File "/usr/lib/python2.6/site-packages/resource_management/core/shell.py", line 140, in _call_wrapper
result = _call(command, **kwargs_copy)
File "/usr/lib/python2.6/site-packages/resource_management/core/shell.py", line 293, in _call
raise ExecutionFailed(err_msg, code, out, err)
resource_management.core.exceptions.ExecutionFailed: Execution of \'/usr/bin/yum -d 0 -e 0 -y install ambari-metrics-monitor\' returned 1. Error: python-devel conflicts with python-2.7.5-58.el7.x86_64
You could try using --skip-broken to work around the problem
** Found 167 pre-existing rpmdb problem(s), \'yum check\' output follows:解决办法,
rpm -qa | grep python-2.7.5-16.el7.x86_64 | xargs rpm -e --nodeps
5、es入库失败,storm 中task一直在处理,但是es中没数据
报错信息:
MapperParsingException[Failed to parse mapping [squid_doc]: No handler for type [keyword] declared on field [source:type]]; nested: MapperParsingException[No handler for type [keyword] declared on field [source:type]];
at org.elasticsearch.cluster.metadata.MetaDataCreateIndexService$1.execute(MetaDataCreateIndexService.java:332)
at org.elasticsearch.cluster.ClusterStateUpdateTask.execute(ClusterStateUpdateTask.java:45)
at org.elasticsearch.cluster.service.InternalClusterService.runTasksForExecutor(InternalClusterService.java:458)
at org.elasticsearch.cluster.service.InternalClusterService$UpdateTask.run(InternalClusterService.java:762)
at org.elasticsearch.common.util.concurrent.PrioritizedEsThreadPoolExecutor$TieBreakingPrioritizedRunnable.runAndClean(PrioritizedEsThreadPoolExecutor.java:231)
at org.elasticsearch.common.util.concurrent.PrioritizedEsThreadPoolExecutor$TieBreakingPrioritizedRunnable.run(PrioritizedEsThreadPoolExecutor.java:194)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)原因:
是因为建立的模板字段类别跟预期不同导致的,
可以在es server上查看现有哪些模板:curl -XGET "http://127.0.0.1:9200/_template?v"
删除对应的模板: curl -XDELETE "http://127.0.0.1:9200/_template/squid*"
以上是关于Apache Metron从入门到落灰的主要内容,如果未能解决你的问题,请参考以下文章