flink sql 知其所以然| sql api 类型系统
Posted antigeneral
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了flink sql 知其所以然| sql api 类型系统相关的知识,希望对你有一定的参考价值。
1.序篇-先说结论
感谢您的关注 + 点赞 + 再看,对博主的肯定,会督促博主持续的输出更多的优质实战内容!!!

 大数据羊说
用数据提升美好事物发生的概率~
公众号
大数据羊说
用数据提升美好事物发生的概率~
公众号
protobuf 作为目前各大公司中最广泛使用的高效的协议数据交换格式工具库,会大量作为流式数据传输的序列化方式,所以在 flink sql 中如果能实现 protobuf 的 format 会非常有用(目前社区已经有对应的实现,不过目前还没有 merge,预计在 1.14 系列版本中能 release)。
这一节原本是介绍 flink sql 中怎么自定义实现 protobuf format 类型,但是 format 的实现过程中涉及到了 flink sql 类型系统的知识,所以此节先讲解 flink sql 类型系统的内容作为铺垫。以帮助能更好的理解 flink sql 的类型系统。
flink sql 类型系统并不是一开始就是目前这样的 LogicalType 体系,其最开始也是复用了 datastream 的 TypeInformation,后来才由 TypeInformation 转变为了 LogicalType,因此本节分为以下几个小节,来说明 flink sql api 类型的转变原因、过程以及新类型系统设计。
- 背景篇
- 目标篇-预期效果是什么
- 框架设计篇-具体方案实现
- 总结篇
熟悉 DataStream API 的同学都知道,DataStream API 的类型系统 TypeInformation 体系。所以初期 SQL API 的类型系统也是完全由 TypeInformation 实现的。但是随着 SQL API 的 feature 增强,用户越来越多的使用 SQL API 之后,发现 TypeInformation 作为 SQL API 的类型系统还是有一些缺陷的。
具体我们参考 Flip-37:https://cwiki.apache.org/confluence/display/FLINK/FLIP-37%3A+Rework+of+the+Table+API+Type+System。
Flip-65:https://cwiki.apache.org/confluence/display/FLINK/FLIP-65%3A+New+type+inference+for+Table+API+UDFs
issue:https://issues.apache.org/jira/browse/FLINK-12251
比如一些用户反馈有以下问题:
https://docs.google.com/document/d/1zKSY1z0lvtQdfOgwcLnCMSRHew3weeJ6QfQjSD0zWas/edit#heading=h.64s92ad5mb1
在 Flip-37 中介绍到:
1. TypeInformation 不能和 SQL 类型系统很好的集成,并且不同实现语言也会对其类型信息产生影响。
2. TypeInformation 与 SQL 类型系统不一致。
3. 不能为 DECIMAL 等定义精度和小数位数。
4. 不支持 CHAR/VARCHAR 之间的差异(FLINK-10257、FLINK-9559)。
5. 物理类型和逻辑类型是紧密耦合的。
flink sql 类型系统设计文档:https://docs.google.com/document/d/1a9HUb6OaBIoj9IRfbILcMFPrOL7ALeZ3rVI66dvA2_U/edit#heading=h.5qoorezffk0t
2.1.序列化器受执行环境影响
怎么理解不同语言的环境会对类型信息产生影响,直接来看一下下面这个例子(基于 flink 1.8):
import org.apache.flink.table.functions.TableFunction
case class SimpleUser(name: String, age: Int)
class TableFunc0 extends TableFunction[SimpleUser] {
// make sure input element\'s format is "<string>#<int>"
def eval(user: String): Unit = {
if (user.contains("#")) {
val splits = user.split("#")
collect(SimpleUser(splits(0), splits(1).toInt))
}
}
}
TableFunc0 出参(SimpleUser)的 TypeInformation 不仅取决于出参本身,还取决于使用的表环境,而且最终的序列化器也是不同的,这里以 java 环境和 scala 环境做比较:
2.1.1.java 环境
在 java 环境中,使用 org.apache.flink.table.api.java.StreamTableEnvironment#registerFunction 注册函数。
Java 类型提取是通过基于反射的 TypeExtractor 提取 TypeInformation。
示例代码如下(基于 flink 1.8 版本):
public class JavaEnvTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment sEnv = StreamExecutionEnvironment.getExecutionEnvironment();
// create a TableEnvironment for streaming queries
StreamTableEnvironment sTableEnv = StreamTableEnvironment.create(sEnv);
sTableEnv.registerFunction("table1", new TableFunc0());
TableSqlFunction tableSqlFunction =
(TableSqlFunction) sTableEnv
.getFunctionCatalog()
.getSqlOperatorTable()
.getOperatorList()
.get(170);
TypeSerializer<?> t = tableSqlFunction.getRowTypeInfo().createSerializer(sEnv.getConfig());
sEnv.execute();
}
}
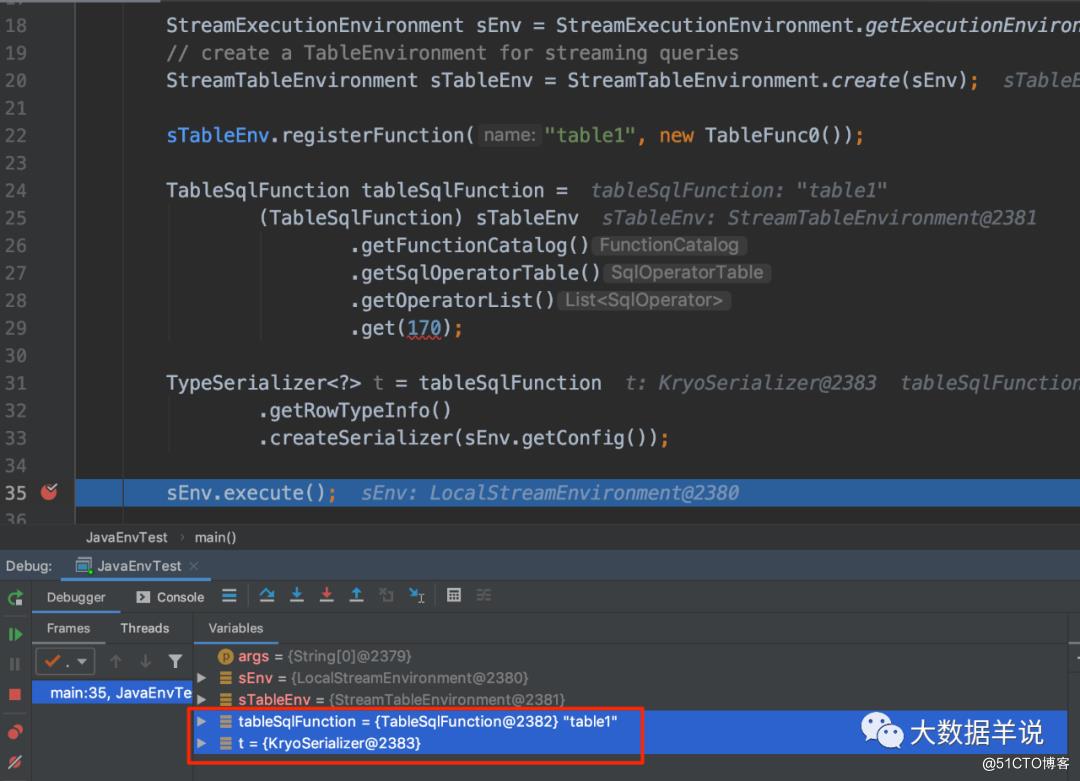
1
java 环境,可以看到,最终使用的是 Kryo 序列化器。
2.1.2.scala 环境
在 scala 环境中,使用 org.apache.flink.table.api.scala.StreamTableEnvironment#registerFunction 注册函数。
使用 Scala 类型提取堆栈并通过使用 Scala 宏提取 TypeInformation。
示例代码如下(基于 flink 1.8 版本):
object ScalaEnv {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
// create a TableEnvironment
val tableEnv = StreamTableEnvironment.create(env)
tableEnv.registerFunction("hashCode", new TableFunc0())
val config = env.getConfig
val function = new TableFunc0()
registerFunction(config, function)
// execute
env.execute()
}
def registerFunction[T: TypeInformation](config: ExecutionConfig, tf: TableFunction[T]): Unit = {
val typeInfo: TypeInformation[_] = if (tf.getResultType != null) {
tf.getResultType
} else {
implicitly[TypeInformation[T]]
}
val ty = typeInfo.createSerializer(config)
}
}
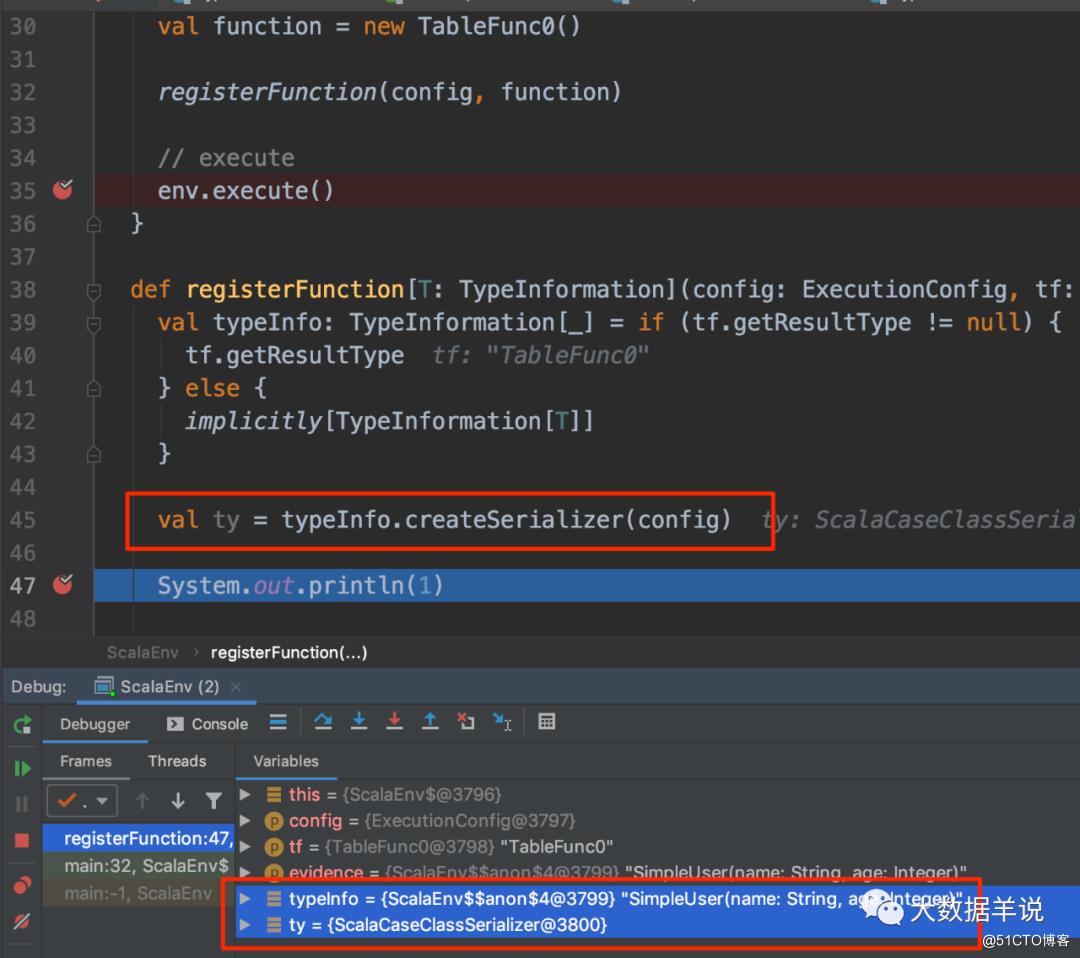
2
scala 环境,最终使用的是 Case Class 序列化器。
但是逻辑上同一个 sql 的 model 的序列化方式只应该与 model 本身有关,不应该与不同语言的 env 有关。不同的 env 的 model 序列化器都应该相同。
2.2.类型系统不一致
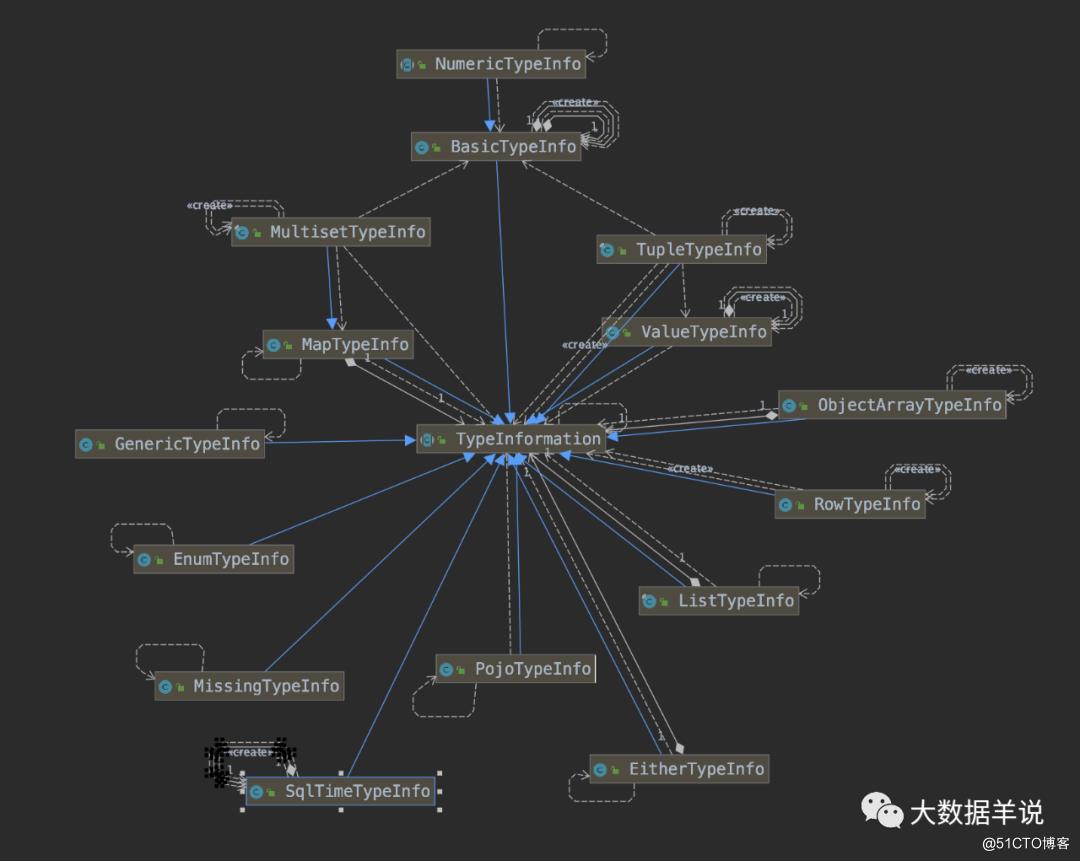
SQL 类型系统与 TypeInformation 系统不一致。如下图
TypeInformation 类型系统的组成,熟悉 datastream 的同学应该都见过:
但是标准的 sql 类型系统的组成应该是由如下组成这样:
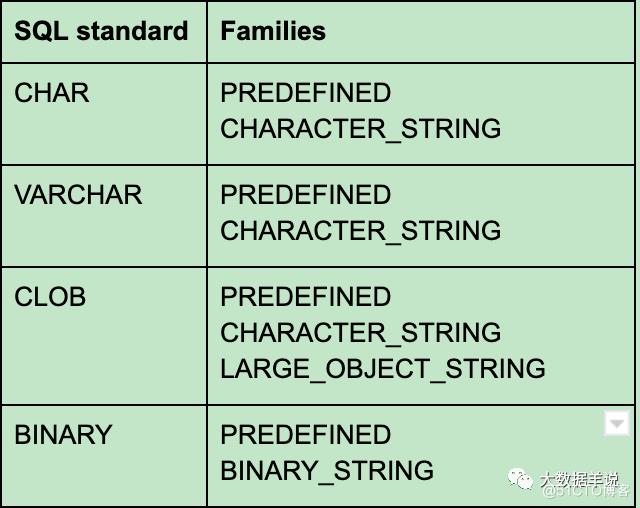
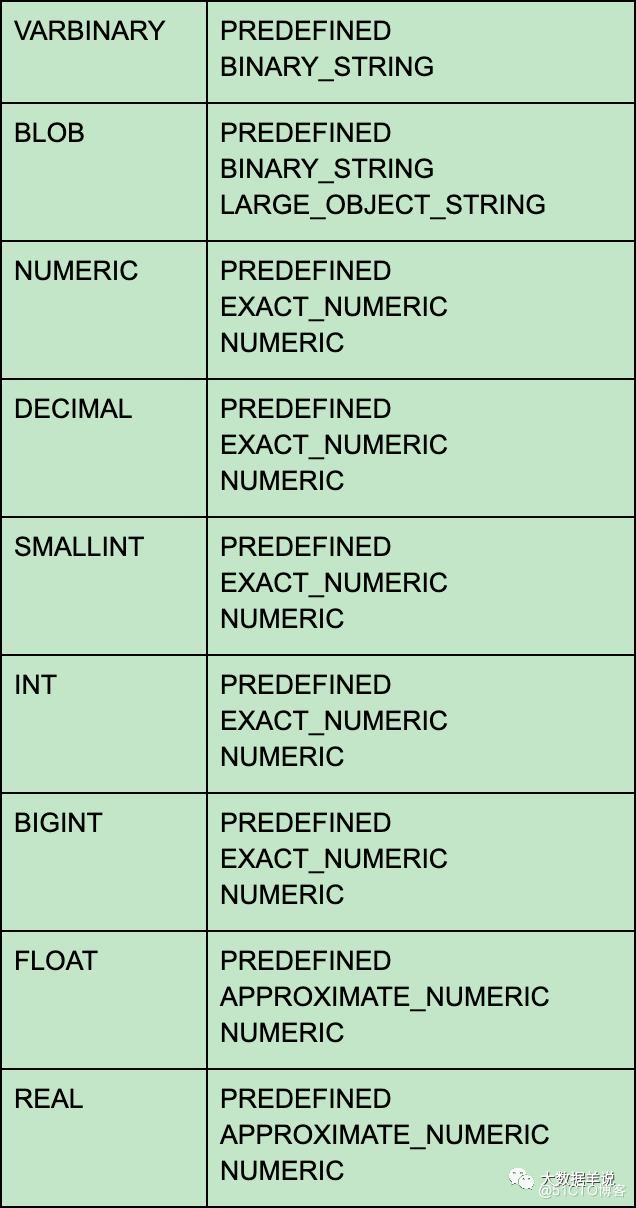
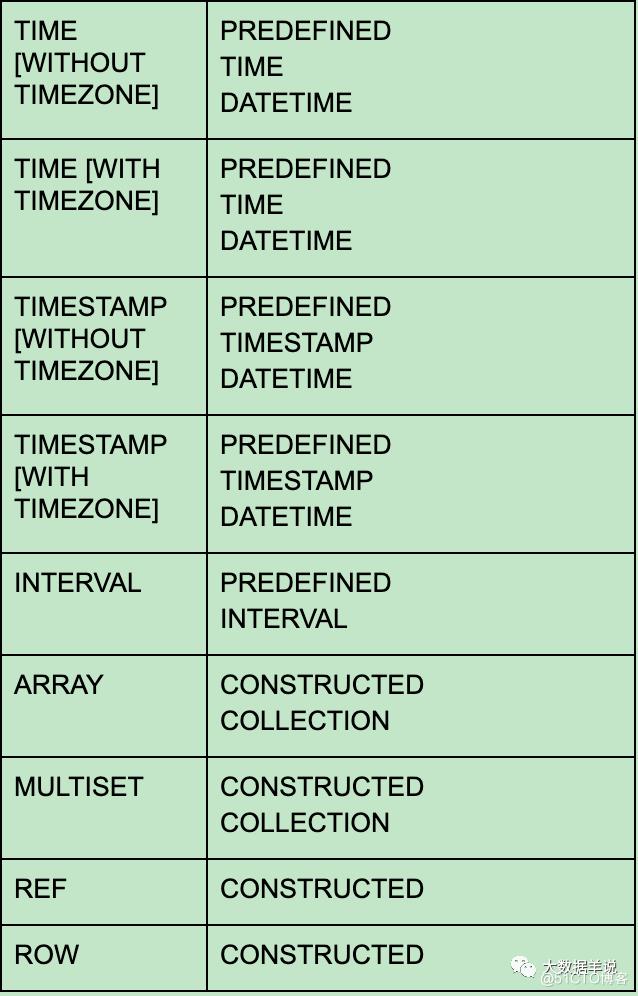
可见 TypeInformation 类型系统与标准 SQL 类型系统的对应关系是不太一致的,这也就导致了 flink sql 与 TypeInformation 不能很好的集成。
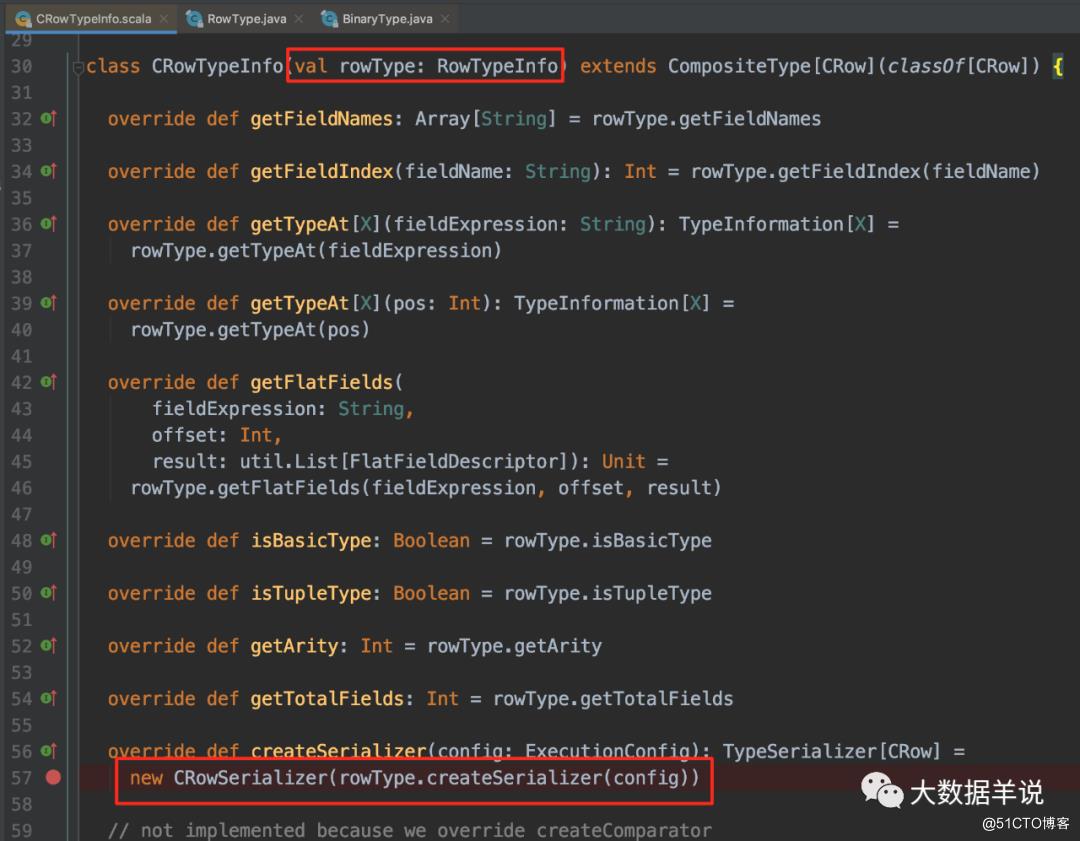
2.3.TypeInformation 类型信息与序列化器绑定
如图 TypeInformation 的具体实现类需要实现 TypeInformation<T>#createSerializer,来指定类型信息的具体序列化器。

3
举例,旧类型系统中,flink sql api 中是使用 CRow 进行的内部数据的流转, CRowTypeInfo 如下图,其序列化器固定为 CRowSerializer:
19
再来一个例子, ListTypeInfo 的序列化器固定为 ListSerializer。
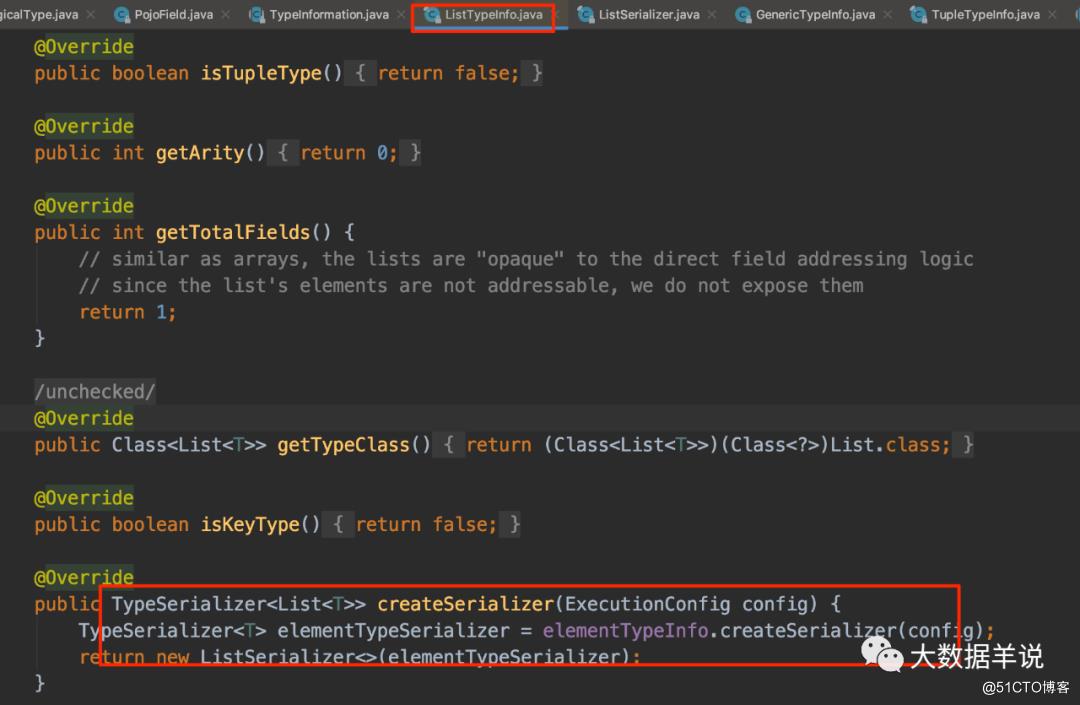
4
可以看到 TypeInformation 的类型体系中,一种 TypeInformation 就和一个 TypeSerializer 是绑定的。
博主体感比较深的是:
1. 统一以及标准化 SQL 类型系统
2. 逻辑类型与物理类型解耦
然后来看看 flink 是怎么做这件事情的,下面的代码都基于 flink 1.13.1。
先从最终最上层的角度出发,看看 flink sql 程序运行时数据载体的变化。
1.old planner:
内部数据流的基本数据类型:CRow = Row + 标识(是否回撤数据)
类型信息:CRowTypeInfo,其类型系统使用的完全也是 TypeInformation 那一套
序列化器:CRowSerializer = RowSerializer + 标识序列化
2.blink planner:
内部数据流的基本数据类型:RowData
类型信息:RowType,基于 LogicalType
序列化器:RowDataSerializer
4.1.统一以及标准化 SQL 类型系统
先来重温下,SQL 标准类型:
然后开看看,flink sql 的类型系统设计,代码位于 flink-table-common 模块:
新的类型系统是基于 LogicalTypeFamily,LogicalTypeRoot,LogicalType 进行实现的:
LogicalTypeFamily:
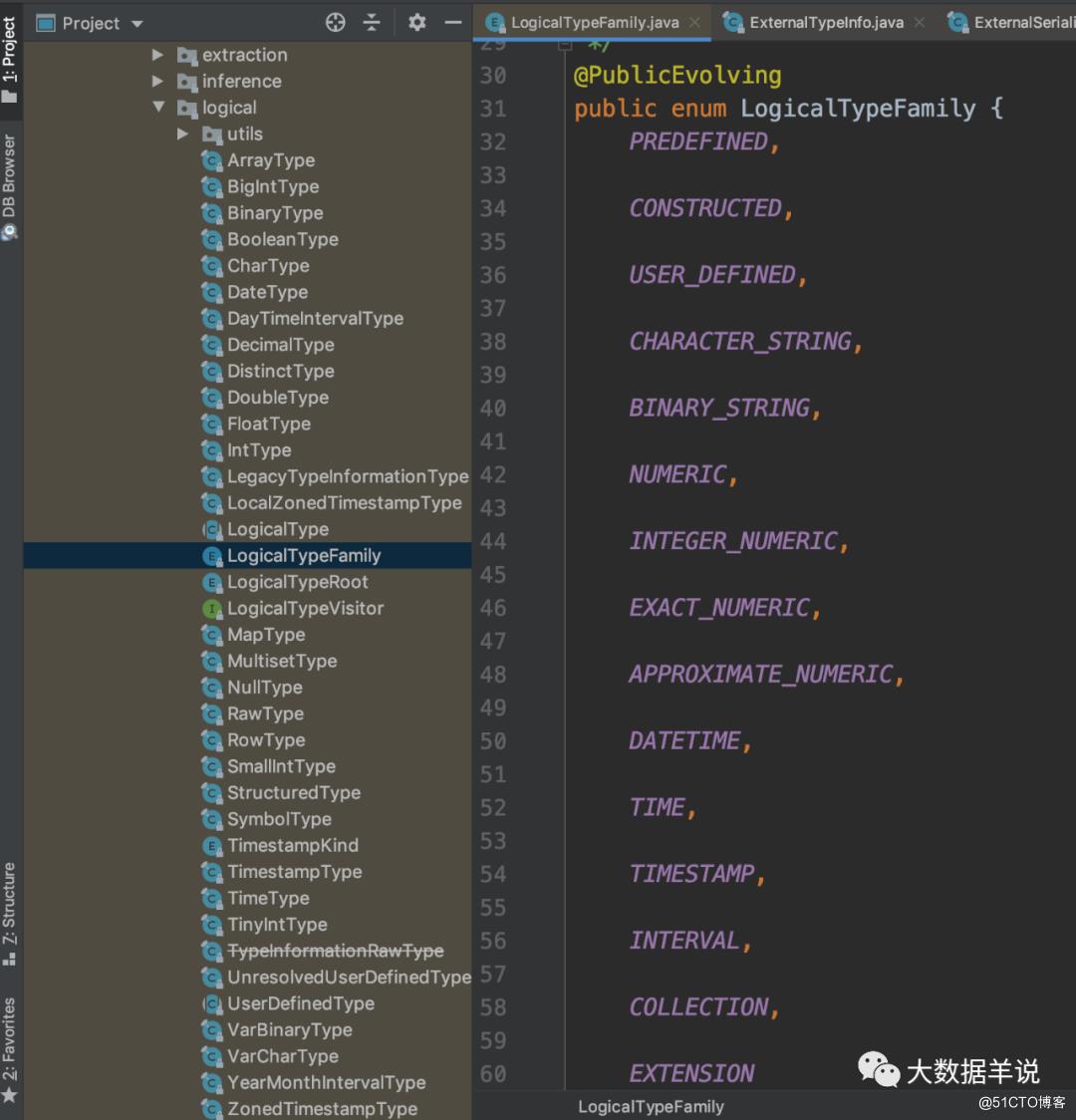
LogicalTypeRoot:
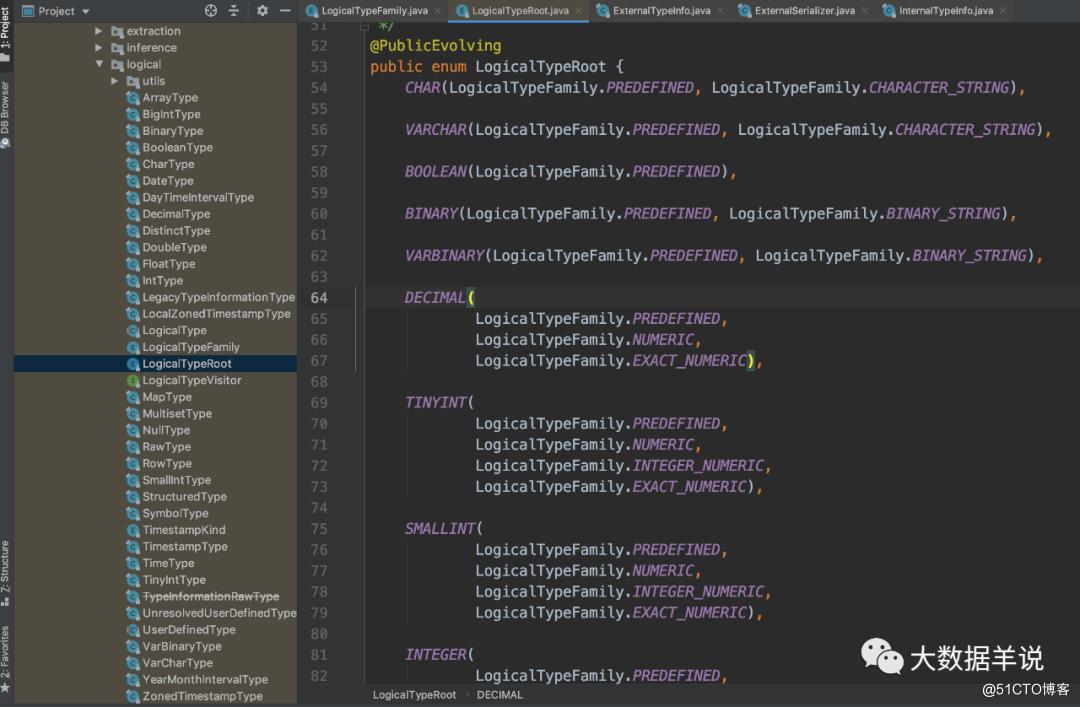
LogicalType:
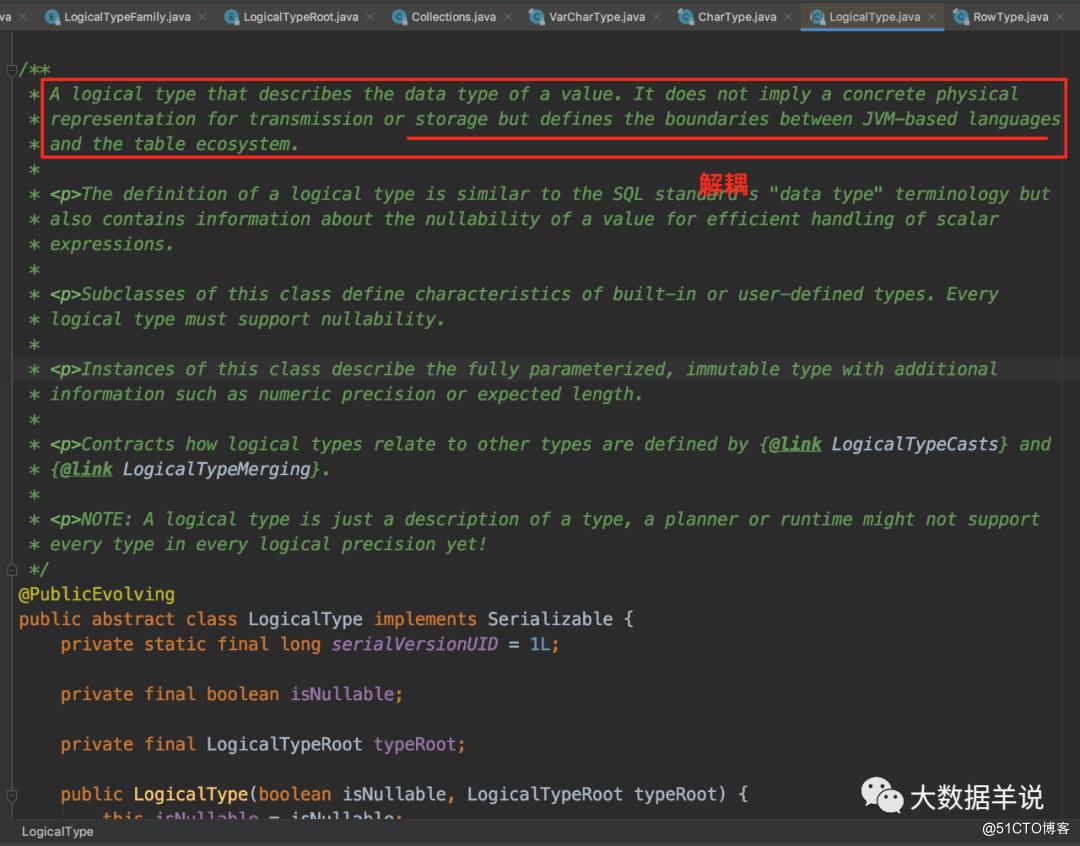
具体 LogicalType 的各类实现类如下图所示:
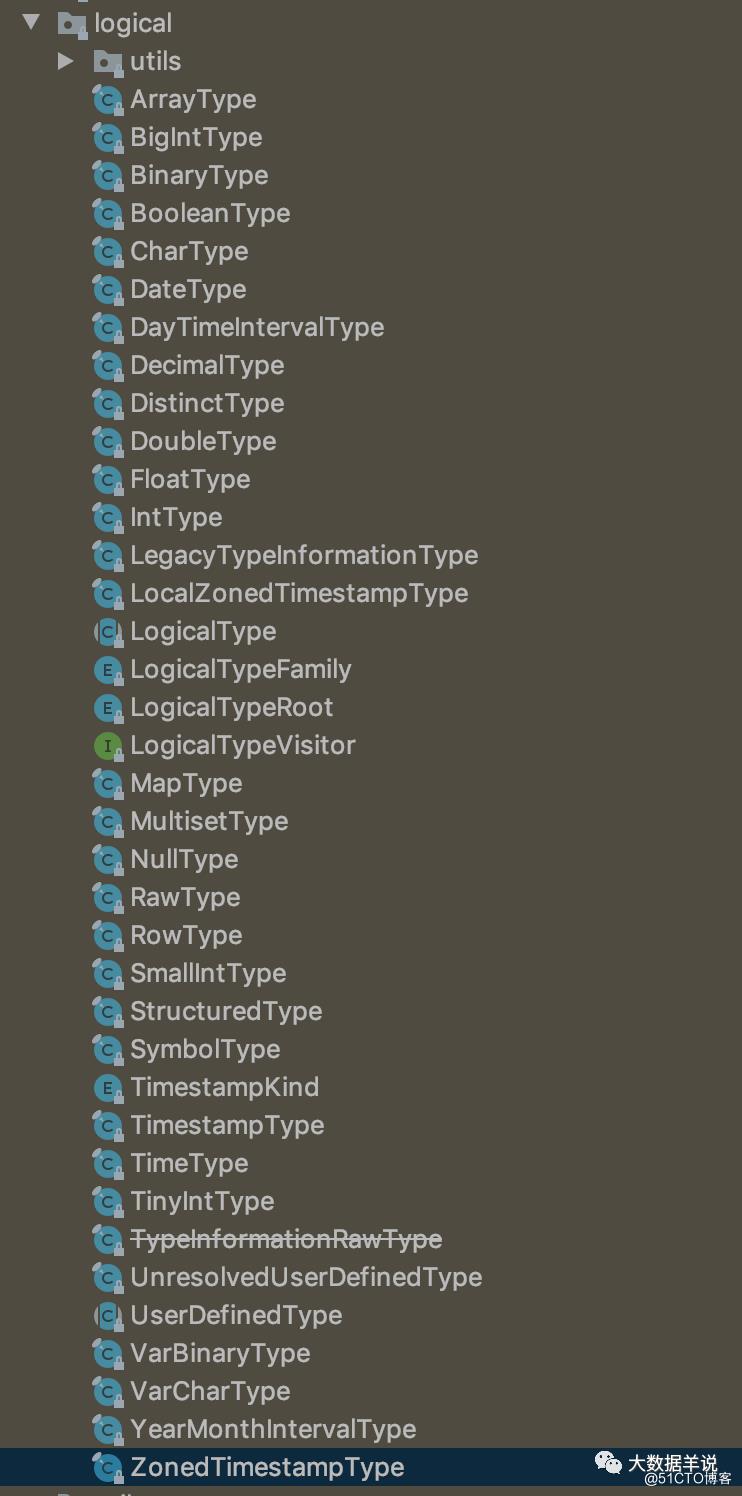
12
可以发现其设计(枚举信息、实现等)都是与 SQL 标准进行了对齐的。
具体类型详情可以参考官方文档,这里不过多赘述。https://ci.apache.org/projects/flink/flink-docs-release-1.13/docs/dev/table/types/
4.2.逻辑类型与物理类型解耦
解耦这部分的实现比较好理解,博主通过两种方式来解释其解耦方式:
4.2.1.看看解耦的具体实现
博主画了一张图来比较下 TypeInformation 与 LogicalType,如下图。
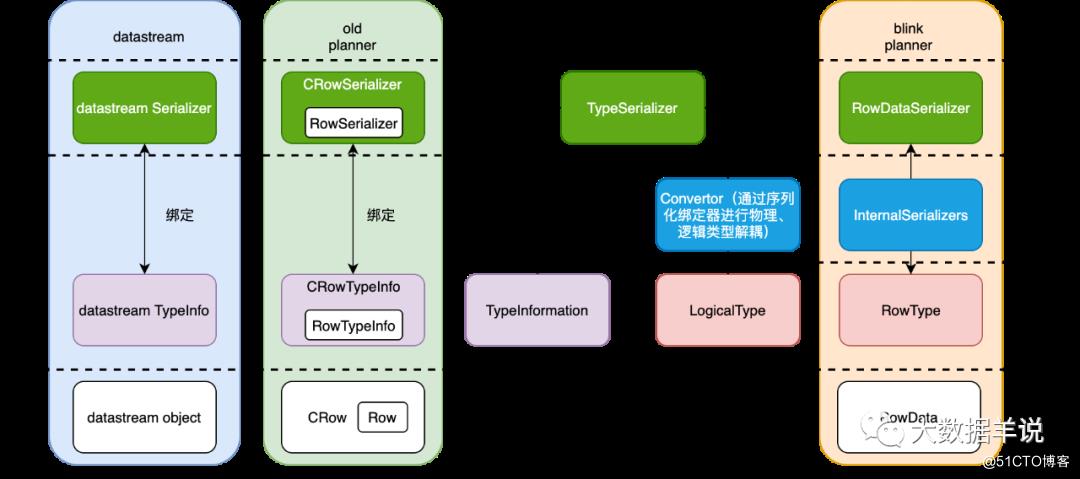
20
- datastream\\old planner:如左图所示,都是基于
TypeInformation体系,一种TypeInformation就和一个TypeSerializer是绑定的。 - blink planner:如右图所示,都是基于
LogicalType体系,但是与TypeSerializer通过中间的一层映射层进行解耦,这层映射层是 blink planner 独有的,当然如果你也能自定义一个 planner,你也可以自定义对应的映射方式。
LogicalType 只包含类型信息,关于具体的序列化器是在不同的 planner 中实现的。Blink Planner 是 InternalSerializers。
4.2.2.看看包的划分
其实我们也可以通过这些具体实现类的在 flink 中所在的包也可以看出其解耦方式。如图所示。
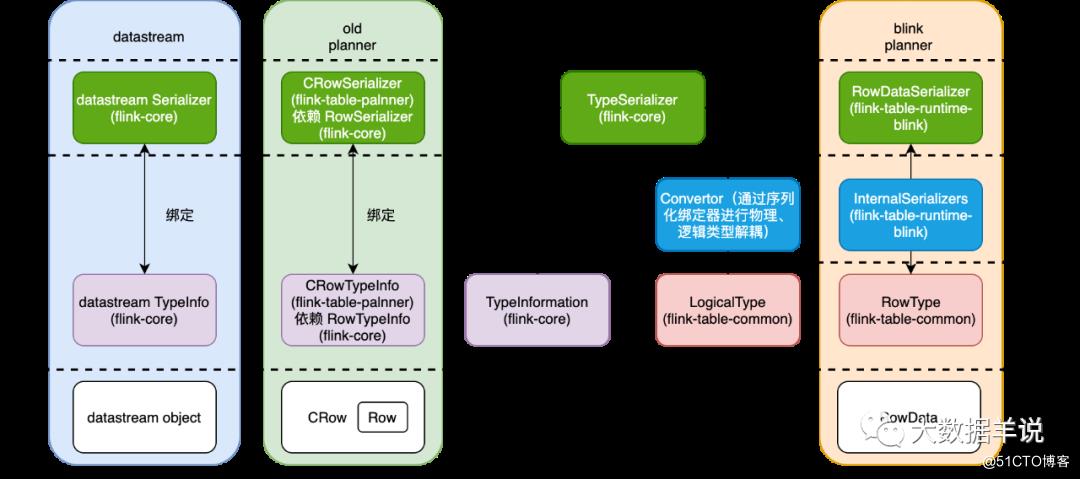 21
21
-
datastream\\old planner:如左图所示,其中的核心逻辑类型、序列化器都是在
flink-core中实现的。都是基于以及复用了TypeInformation体系。 -
blink planner:如右图所示,
LogicalType体系都是位于flink-table-common模块中,作为 sql 基础、标准的体系。而其中具体的序列化器是在flink-table-runtime-blink中的,可以说明不同的 planner 是有对应不同的实现的,从而实现了逻辑类型和物理序列化器的解耦。
本文主要介绍了 flink sql 类型系统的内容,从背景、目标以及最终的实现上做了一些思考和分析。
希望能抛砖引玉,让大家能在使用层面之上还能有一些更深层次的思考~
大数据羊说
用数据提升美好事物发生的概率~
公众号
往期推荐
flink sql 知其所以然(三)| 自定义 redis 数据汇表(附源码)
flink sql 知其所以然(二)| 自定义 redis 数据维表(附源码)
flink sql 知其所以然(一)| source\\sink 原理
更多 Flink 实时大数据分析相关技术博文,视频。后台回复 “flink” 获取。
点个赞+在看,感谢您的肯定 ????
以上是关于flink sql 知其所以然| sql api 类型系统的主要内容,如果未能解决你的问题,请参考以下文章
Flink SQL - 2.Table API & SQL 概述与常规 API
2021年大数据Flink(三十):Flink Table API & SQL 介绍