ArrayList 从源码角度剖析底层原理
Posted SH的全栈笔记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ArrayList 从源码角度剖析底层原理相关的知识,希望对你有一定的参考价值。
对于 ArrayList 来说,我们平常用的最多的方法应该就是 add 和 remove 了,本文就主要通过这两个基础的方法入手,通过源码来看看 ArrayList 的底层原理。
add
默认添加元素
这个应该是平常用的最多的方法了,其用法如下。
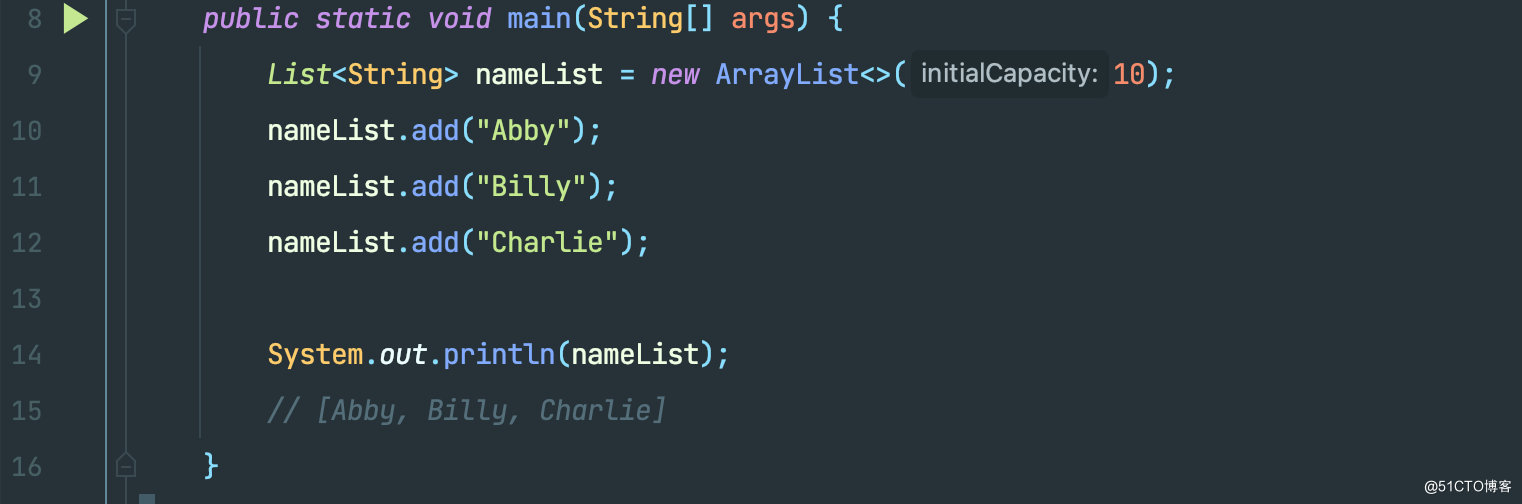
接下来我们就来看看 add 方法的底层源码。

ensureCapacityInternal 作用为:保证在不停的往 ArrayList 插入数据时,数组不会越界,并且实现自动扩容。

这里的 minCapacaity 的值,实际上就是在调用完当前这次 add 操作之后,数组中元素的数量
此外,可以看到将函数 calculateCapacity 的返回值作为了 ensureExplicitCapacity 的输入。
calculateCapacity 做了什么,用大白话来说是,如果当前数组是空的,则直接返回 数组默认长度(10) 和 minCapacity 的最大值,否则就直接返回 minCapacity 。
接下里是 ensureExplicitCapacity ,源码如下:
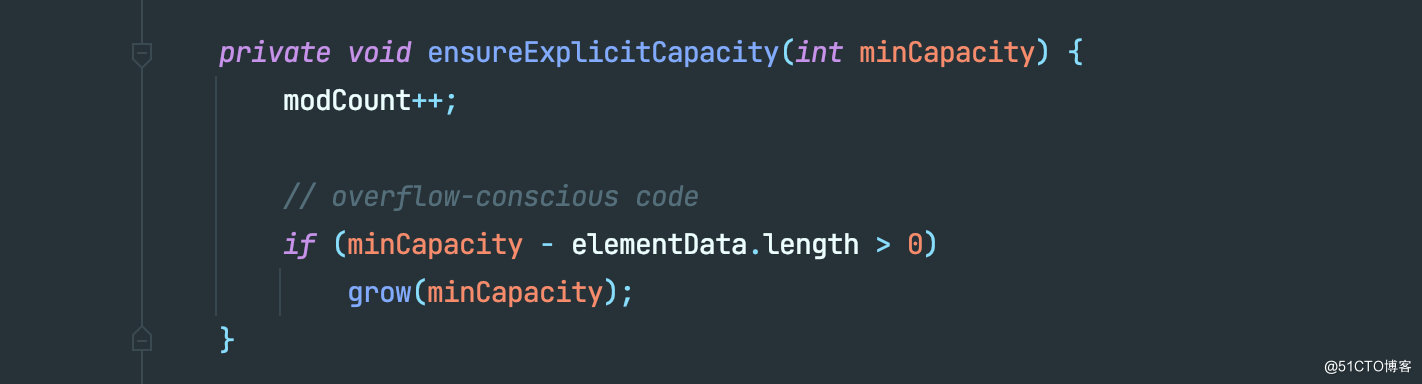
modCount 表示该 ArrayList 被更改过多少次,这里的更改不只是新增,删除也是一种更改。通过上面的了解我们知道,如果当前数组内的元素个数是小于数组长度的,则 minCapacity 的值一定是小于 elementData.length 的。
相反,如果数组内的元素个数已经和数组长度相等了,则 0>0 一定是 false ,此时就会调用 grow 函数来进行数组扩容。

核心逻辑很简单,新的数组长度 = 旧数组长度 + 旧数组长度/2。
所以通过这里的源码我们验证,ArrayList 的扩容是每次扩容 1.5 倍。但是这里会有一个疑问,因为上文提到扩容时 minCapacity 的值和数组长度应该是相等的,所以 新数组长度 - minCapacity 应该永远大于0才对,为什么会有小于0的情况?
答案是 addAll 。
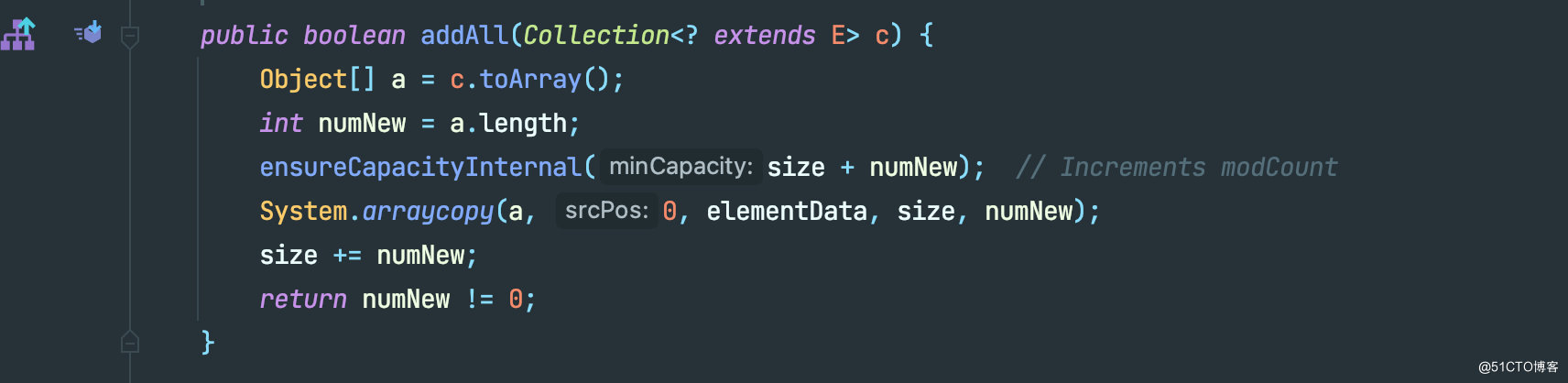
可以看到,add 和 addAll 底层都会调用 ensureCapacityInternal 。add 是往数组中添单个元素,而 addAll 则是往数组中添加整个数组。假设 addAll 我们传进了一个很大的值,举个例子,ArrayList 的默认数组长度为 10 ,扩容一次之后长度为 15 ,假设我们传入的数组元素有 10 个,那么即使扩容一次还是不足以放下所有的元素,因为 15 < 20。
所以才会出现 newCapacity(扩容之后的数组长度) < minCapacity(执行完当前操作之后的数组内元素数量) 的情况,所以当这种情况出现之后,就会直接将 minCapacity 的值赋给 newCapacity 。
除此之外,还会有个极端的情况,假设 addAll 往里面塞入了 Integer.MAX_VALUE 个元素呢?这就是 hugeCapacity 函数要处理的逻辑了。首先如果溢出了就直接抛出 OOM 异常,其次会保证其容量不会超过 Integer.MAX_VALUE。
最后是真正执行扩容的操作,调用了 java.util 包里的 Arrays.copyOf 方法。从上图可以看出,这个方法中传入了两个参数,分别是存放元素的数组、新的数组长度,举个例子:
int[] elementData = {1, 2, 3, 4, 5};
int[] newElementData = Arrays.copyOf(elementData, 10);
System.out.println(newElementData); // [1 2 3 4 5 0 0 0 0 0]数组扩容完成之后,就会将本次 add 的元素写入 elementData 的末尾了,elementData[size++] = e 。
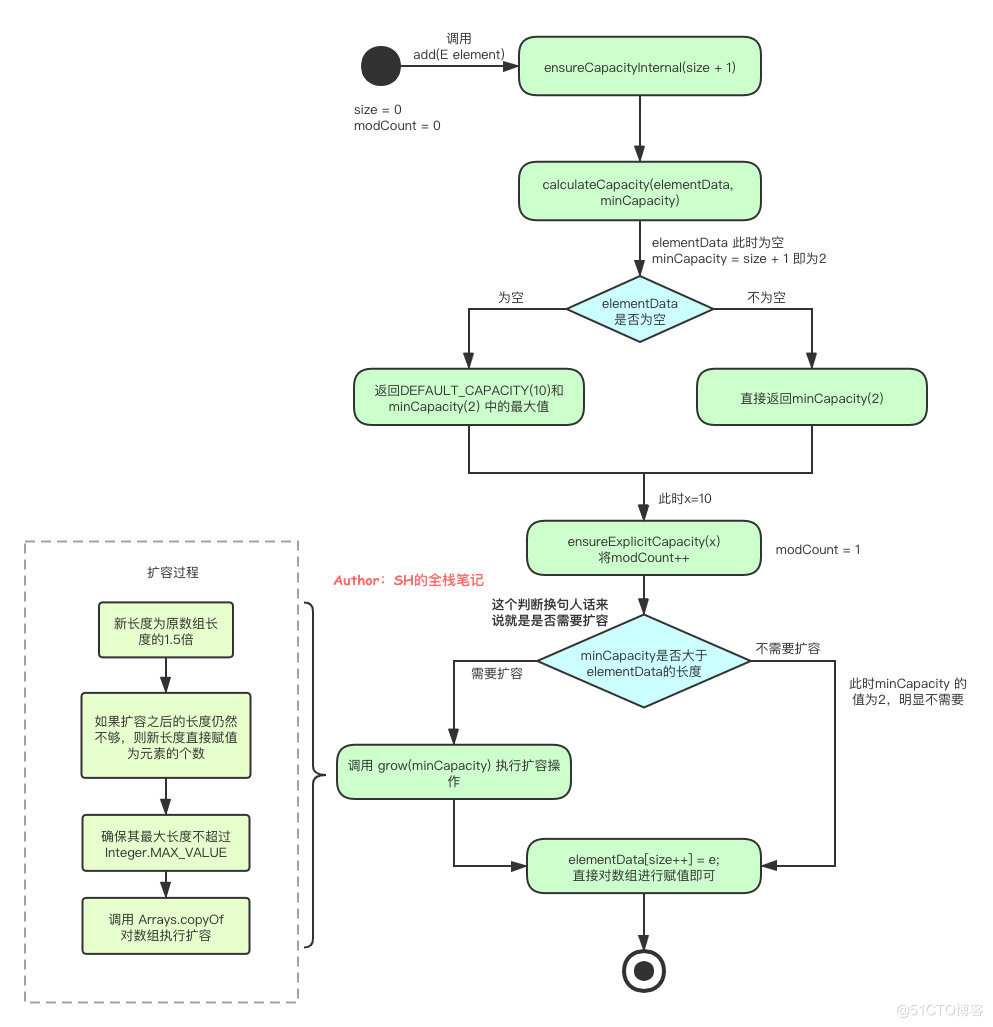
接下来我们用流程图来总结一下 add 操作的整个核心流程。
指定添加元素的位置
了解完了 add 和 addAll,我们趁热打铁,来看看可以指定元素位置的 add ,其接受两个参数,分别是:
- 新元素在数组中的下标
- 新元素本身
这里和最开始的 add 就有些不同了,之前的 add 方法会将元素放在数组的末尾,而 add(int index, E element) 则会将元素插入到数组中指定的位置,接下来从源码层面看看。
首先,由于这个方法允许用户传入数组下标,所以首先要做的事情就是检查传入的数组下标是否合法,如果不合法则会直接抛出 IndexOutOfBoundsException 异常。

很简单的判断,下标 index 不能小于0,并且不能超过数组中的元素个数,举个例子:
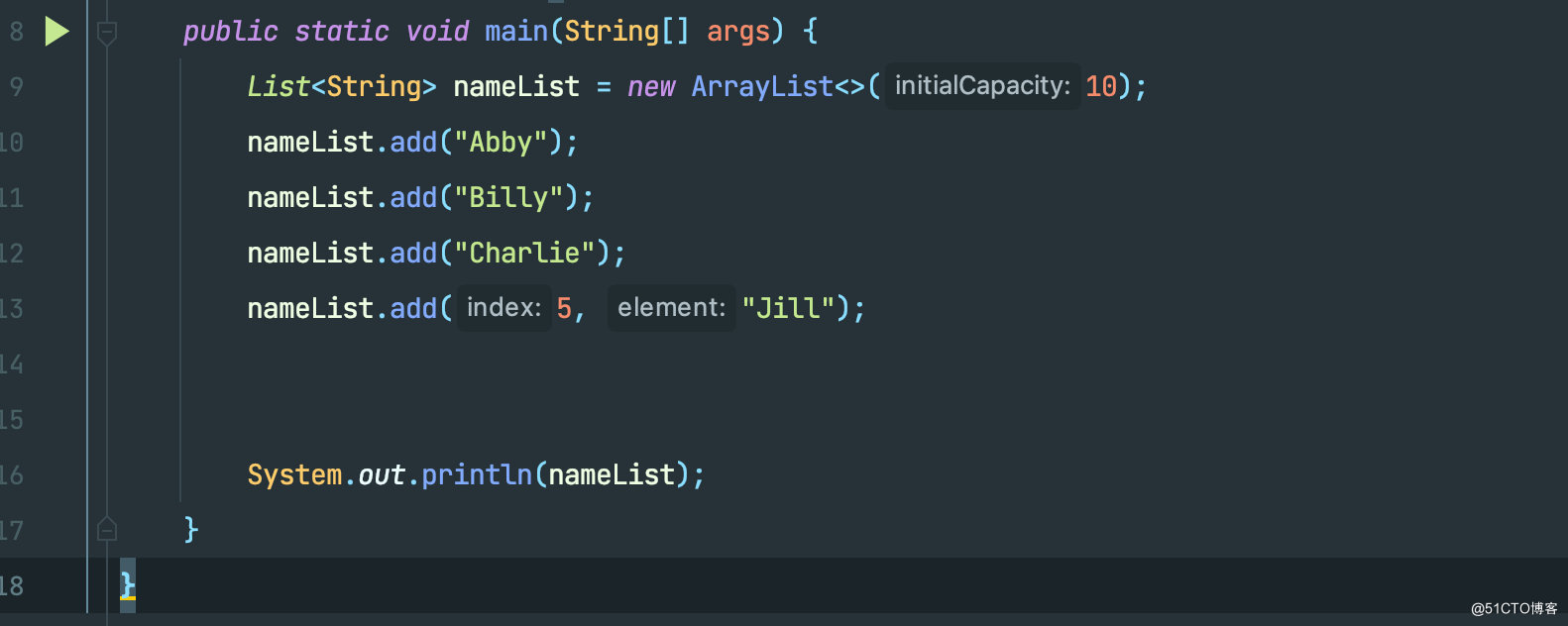
像上图这种情况,调用 add(int index, E element) 之前,数组内有3个元素,即使底层数组的长度为10 ,但是数组下标如果传入5,是会抛出 IndexOutOfBoundsException 异常的。在上图这种情况,index 的值最大只能为3才不会报错,因为 index(下标为3) > size(3个元素) 肯定不为 true 。
完成了校验之后,还是会调用上面聊到过的 ensureCapacityInternal 方法,根据需要,来对底层的数组进行扩容。然后调用 System.arraycopy 方法,这个方法比较关键,也比较难理解,所以我就简单一句话把它的作用概括了——将制定下标后的元素全部往后移动一位。

System.arraycopy 接收 4 个参数,分别是:
- 原数组
- 原数组中的起始下标
- 目标数组
- 目标数组中的起始下标
光看参数,不结合例子,其实很难理解,我这里举个简单的例子。
假设现在数组里有元素 [1 2 3] ,然后此时我调用方法 add(1, 4) ,表明我想要将元素 4 插入到数组下标为 1 的位置,那么此时 index 的值为1,size 的值为 3。
System.arraycopy 的方法就会变成 System.arraycopy(elementData, 1, elementData, 2, 2),也就是将 elementData 从下标 1 开始的两个元素(也就是 2 和 3),拷贝到 elementData 的从下标 2 开始的地方。
可能还是有点绕,说人话就是执行完后,elementData 就变成了 [1 2 2 3],然后再对 elementData 进行赋值,将下标为 1 的元素改为本次需要 add 的元素。再说句人话就变成了 [1 4 2 3]。
所以综上来看,没有什么黑魔法,主要需要了解的就是两个关键的函数,分别是 Arrays.copy 和 System.arraycopy 。我们需要把这两个封装好的函数的作用给记住。
- Arrays.copy 数组扩容
- System.arraycopy 将数组中某个下标之后元素全部往后移动一位
remove
了解数据怎么来,接下来我们来看一下数据是怎么被移除的。首先我们来看最常用的两种:
- 按照下标移除
- 根据元素移除
根据下标移除
首先是根据下标移除
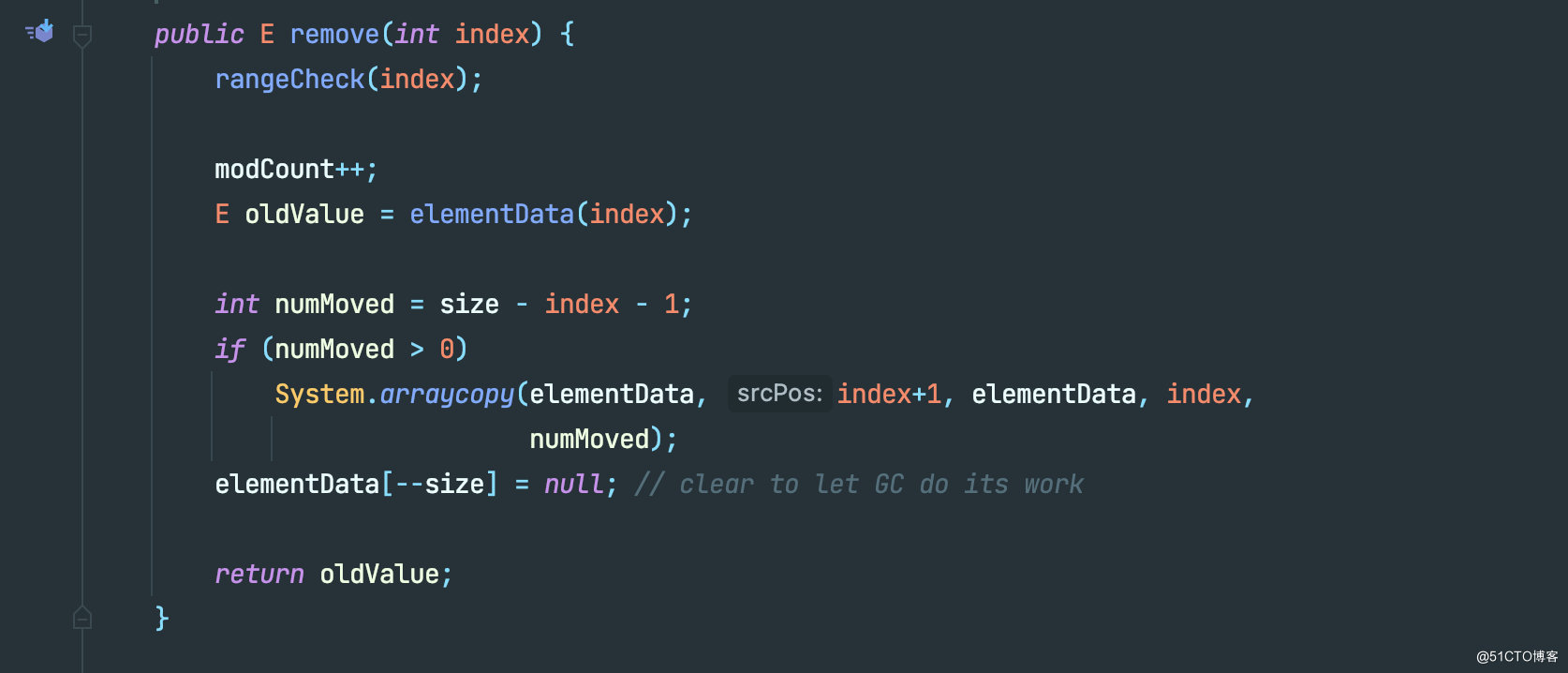
这里也会先检查传入的 index 是否合法,但是这里的 index 和 add 中调用的 rangeCheck 还有点区别。add 中的 rangeCheckForAdd 会判断 index 是否为负数,而 remove 中的 rangeCheck 则只会判断 index 是否 >= 数组中的元素个数。
那如果此时传入的 index 真的是负数怎么办?其实是会抛出 ArrayIndexOutOfBoundsException ,因为remove 方法上加了 Range 注解。

完成后,还是会更新 modCount 的值,这也验证了我们上面提到的 modCount 代表的更改中也包含了删除。
接下来会计算一个 numMoved ,代表需要被移动的元素数量。add 一个元素,对应的下标的元素都需要往后顺移一位,remove 同理,删除了某个位置的元素后,其后面对应的所有的元素都需要往前顺移一位,就像这样:
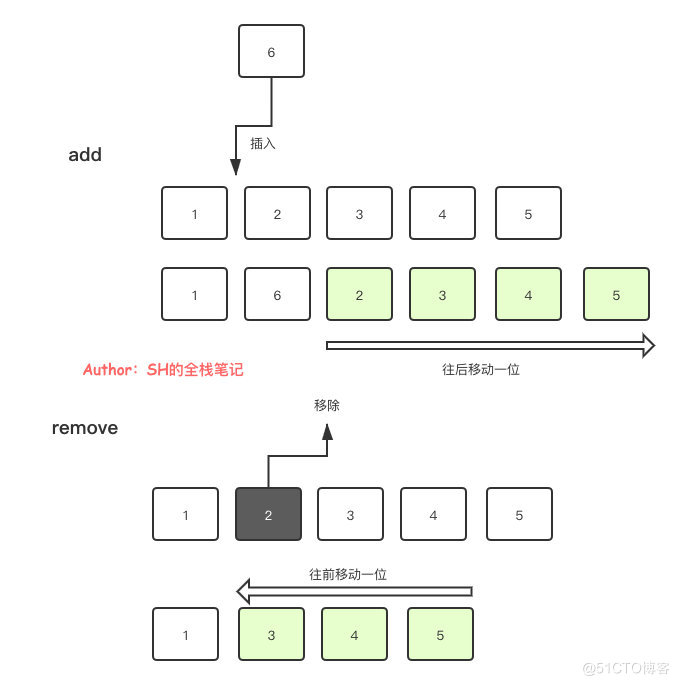
知道了需要移动多少个元素之后,我们的 System.arraycopy 就又可以登场了。完成了元素的移动之后,数组的末尾必然会空出来一个元素,直接将其设置为 null 然后交给 GC 回收即可,最后把被移除的值返回。
根据值移除
举个例子,根据值移除就长下面这样这样。

废话不多说,直接看核心源码
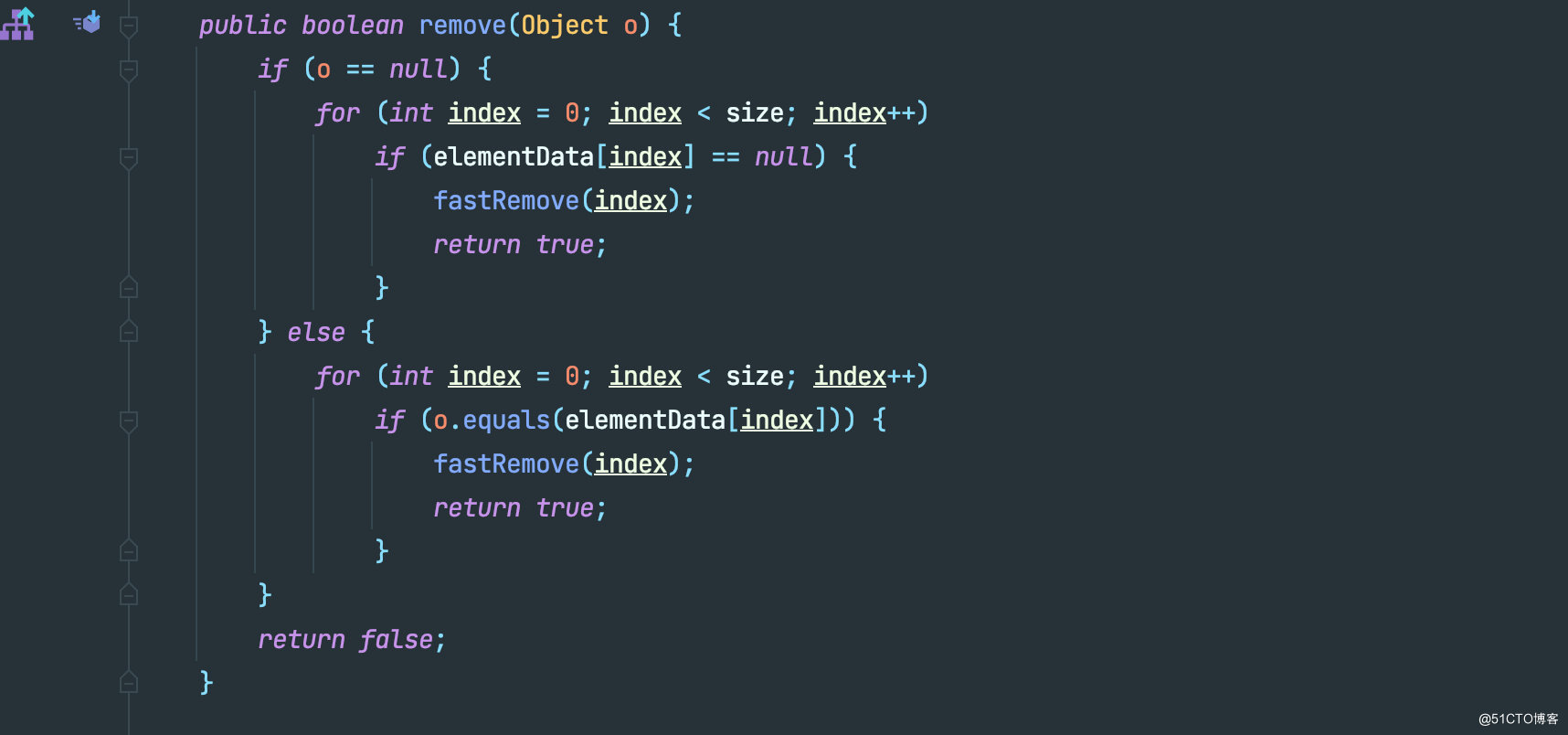
完了,第二行就给整懵了,移除一个 null 是什么鬼?还要循环去移除?
实际上,ArrayList 允许我们传 null 值进去,再举个例子。
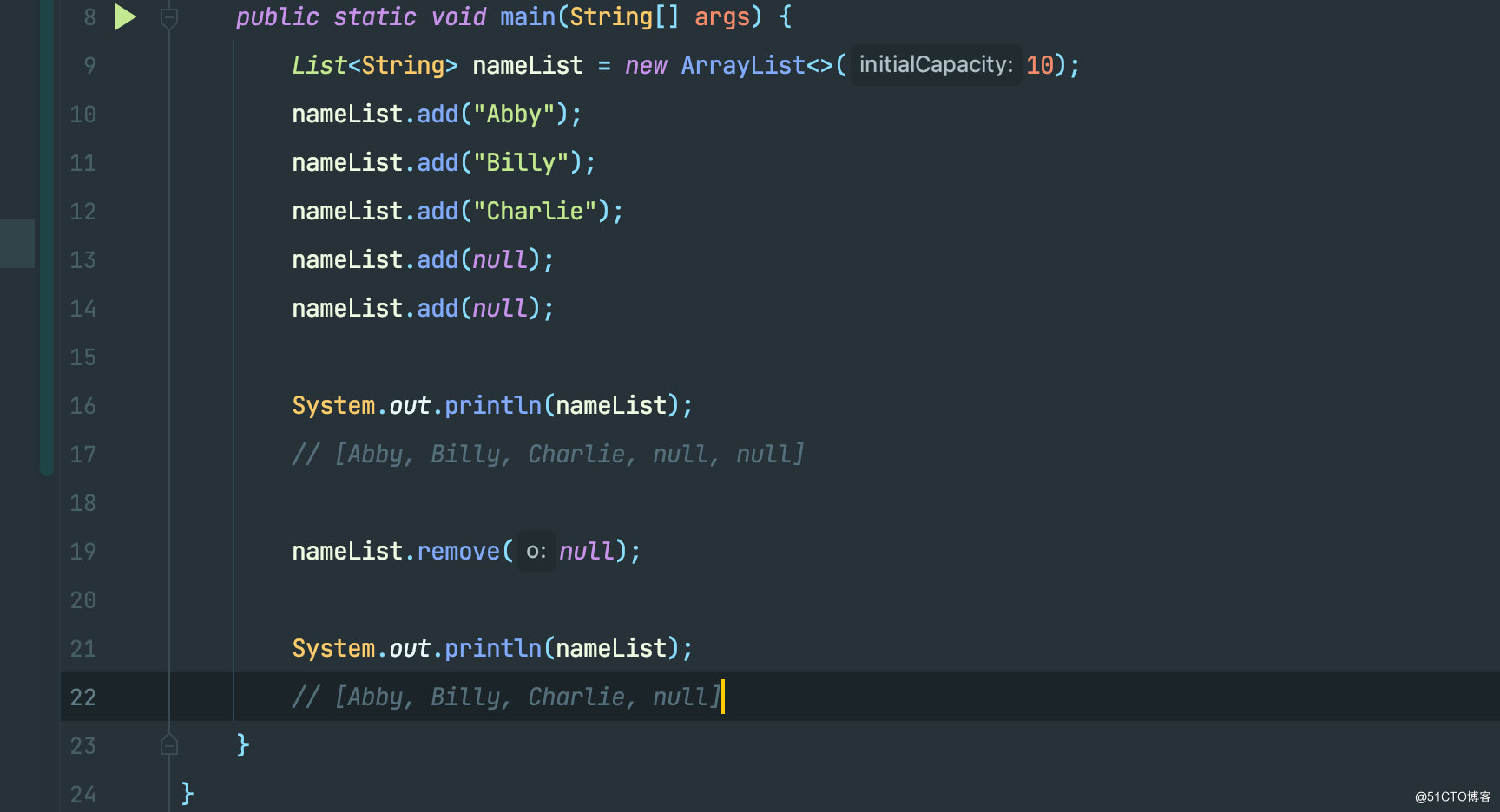
看完这个例子,应该就能够明白为什么要做 o == null 的判断了。如果传入的是 null ,ArrayList 会对底层的数组进行遍历,并移除匹配到的第一个值为 null 的元素。
如果值不为 null 也是同理,如果数组中有多个一样的值,ArrayList 也会对其进行遍历,并且移除匹配到的第一个值。通过源码可以看到,无论值是否为 null ,其都会调用真正的删除元素方法 fastRemove ,干的事情就跟 remove 做的几乎一样。
他们的唯一的区别在于,按照下标移除,会返回被移除的元素;按照值移除只会返回是否移除成功。
总结
所以,看完 ArrayList 的部分源码之后,我们就可以知道,ArrayList 的底层数据结构是数组。虽然对于用户来说 ArrayList 是个动态的数组,但是实际上底层是个定长数组,只是在必要的时候,对底层的数组进行扩容,每次扩容 1.5 倍。但是从源码也看出来了,扩容、删除都是有代价的,特别是在极端的情况,会需要将大量的元素进行移位。
所以我们得出结论,ArrayList 如果有频繁的随机插入、频繁的删除操作是会对其性能造成很大影响的, 总结来说,ArrayList 适合用于读多写少的场景。
了解完如何向一个数据结构中存取、移除数据,其实就已经能够顺理成章的理解跟其相关的很多事情了。
举个例子,indexOf 方法用于返回指定元素在数组中的下标,了解完 remove 中的遍历匹配,或者说你甚至可以直接靠直觉就应该想到,indexOf 不就是个 for 循环匹配吗?lastIndexOf 不就是个反向的 for 循环匹配吗?所以在这里再贴出源码除了让文章篇幅更长之外,没有任何意义。这个感兴趣的话可以找源码看一看。

以上是关于ArrayList 从源码角度剖析底层原理的主要内容,如果未能解决你的问题,请参考以下文章
ListSet集合系列之剖析HashSet存储原理(HashMap底层)
从源码角度认识 ArrayList ,LinkedList与 HashMap