进击的反爬机制
Posted 天存信息
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了进击的反爬机制相关的知识,希望对你有一定的参考价值。
爬 虫 & 反爬虫
反爬方与爬虫方相互博弈,不断制造爬取难度,或一定程度上阻止了爬虫行为。爬虫方也在不断更新技术,来对抗种种反爬限制。
对抗过程
初始状态下,网站提供网站服务,未部署任何反爬措施。
ROUND 1
爬虫方启动爬虫程序 (实验环境中使用 scrapy 爬取) 成功爬取网页内容。
反爬方发现有爬虫程序在对网站进行爬取,在分析日志中访问请求的 user-agent 后,加载 iWall3 Web应用防火墙模块,编写并加载防护规则 anti-crawlers-match-user-agents.json 如下:
{
"info": {
"title": "UA Crawlers list"
},
"rules": [
{
"meta": {
"phase": 2,
"desc": "https://github.com/coreruleset/coreruleset/blob/v3.3/dev/rules/crawlers-user-agents.data"
},
"if": {
"variable": [
"REQUEST_HEADERS",
"REQUEST_BODY",
"REQUEST_FILENAME"
],
"transform": "lowercase",
"operator": "contain",
"pattern": [
"80legs",
"black widow",
"blackwindow",
"prowebwalker",
"pymills-spider",
"ahrefsBot",
"piplbot",
"grapeshotcrawler/2.0",
"grapefx",
"searchmetricsbot",
"semrushbot",
"rogerbot",
"mj12bot",
"owlin bot",
"lingewoud-550-spyder",
"wappalyzer",
"scrapy"
]
},
"then": [
"IP.bad_ua_count@20=IP.bad_ua_count+1",
"if": "IP.bad_ua_count > 3",
"then": {
"action": "deny",
"log": "Too frequnt access from crawlers."
}
]
}
]
}爬虫方再次爬取网页,发现超过一定阈值后,后续爬虫请求被阻止:
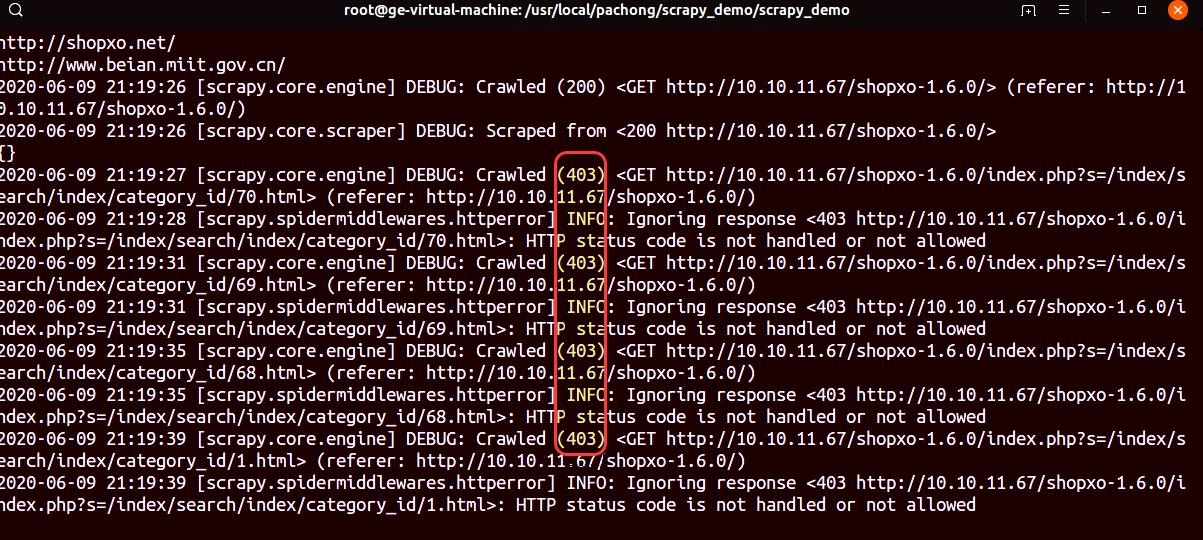
反爬方防护成功。
ROUND 2
爬虫方在初次交锋中 user-agent 被识别,这一次则使用随机的 user-agent (scrapy 使用 random_user_agent 配置),成功爬取网页内容。如下图:
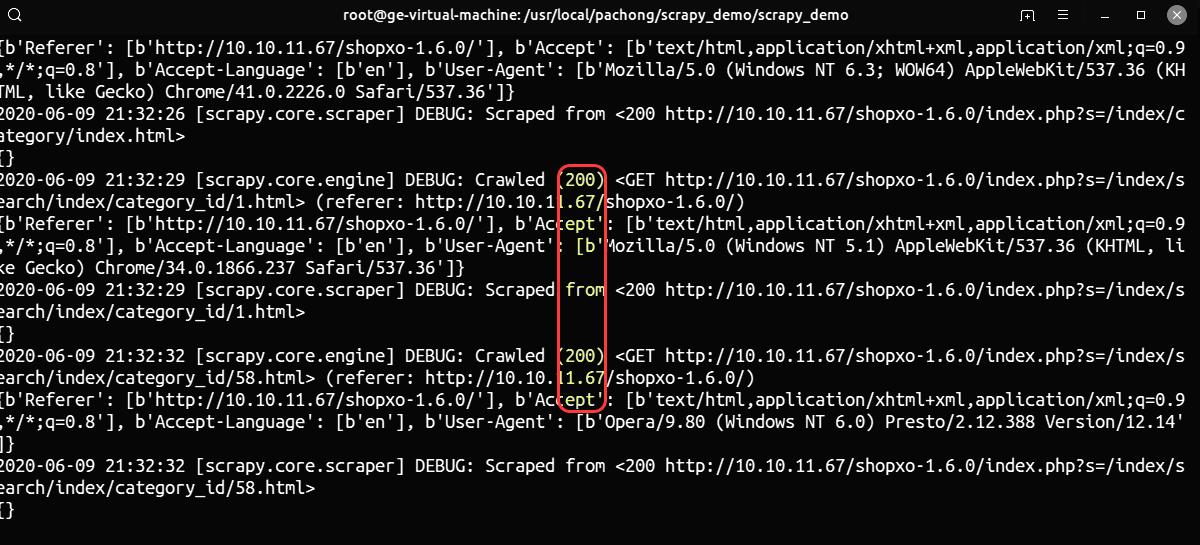
反爬方利用 user_agent 防护的措施失效后,可根据“爬虫 (同一个 IP 地址) 在短时间内会访问多个不同应用 (如 url)”的逻辑,编写并加载防护规则 anti-crawlers-limit-user-access-different-application.json 如下:
{
"rules": [
{
"meta": {
"phase": 2,
"function": "当IP.urls字段中不包含当前访问的请求名,则进行设置操作加判断操作。如果是参数代表不同应用修改即可。",
"function": "设置操作包括给原有的IP.urls字段append新的请求名,并给IP.urls_count加1;",
"function": "判断操作是判断IP.urls_count是否大于5(代表10秒内访问了不同的url,不同的url代表不同的功能),",
"function": "若是则deny,否则放行。"
},
"if": [
{
"or": [
"REQUEST_FILENAME == \'/shopxo-1.6.0/index.php\' && @ARGS.s == \'/index/user/reginfo.html\'",
"REQUEST_FILENAME == \'/shopxo-1.6.0/index.php\' && @ARGS.s == \'/index/user/logininfo.html\'",
"REQUEST_FILENAME == \'/shopxo-1.6.0/index.php\' && @ARGS.s == \'/index/category/index.html\'",
"REQUEST_FILENAME == \'/shopxo-1.6.0/index.php\' && contain(@ARGS.s, \'/index/search/index/category_id\')",
"REQUEST_FILENAME == \'/shopxo-1.6.0/index.php\' && contain(@ARGS.s, \'/index/article/index/id\')",
"REQUEST_FILENAME == \'/shopxo-1.6.0/index.php\' && contain(@ARGS.s, \'/index/goods/index/id\')"
]
},
{
"not": {
"variable": "IP.args_s",
"operator": "contain",
"pattern": "\';\' .. ${@ARGS.s} .. \';\'"
}
}
],
"then": [
"IP.args_s@10=IP.args_s .. \';\' .. @ARGS.s .. \';\'",
"IP.args_s_count@10 = IP.args_s_count+1",
"if": "IP.args_s_count > 5",
"then": {
"action": "deny",
"log": true
}
]
}
]
}超过一定阈值后,后续爬虫请求被阻止:
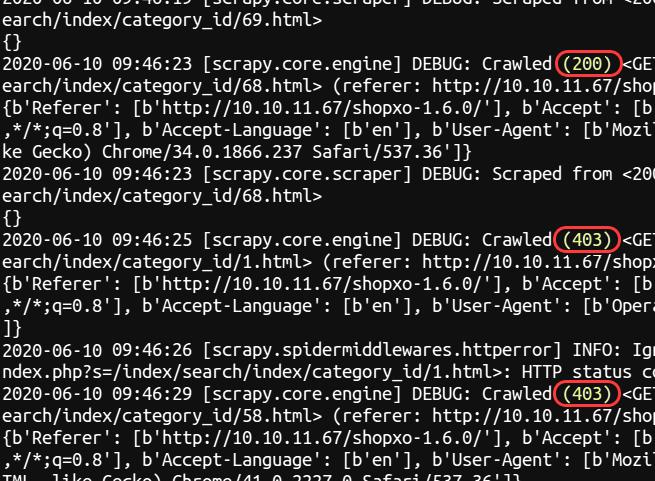
反爬方防护成功。
ROUND 3
爬虫方由于在上一回合中使用同一 IP 地址且访问速度过快,导致反爬方可以依此特性设置防护。故改为使用 IP 代理池 (scrapy 使用 IP 代理池),成功爬取网页内容。Proxy_ip 的设置如下所示:
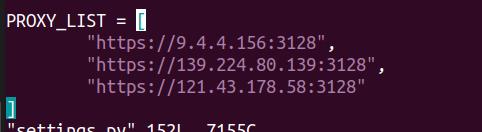
反爬方更新防护措施,相应地在页面中增加“蜜罐页面链接”。一旦爬虫程序访问“蜜罐页面链接”就会被拦截。编写并加载防护规则 anti-crawlers-add-honeypot-page.json 如下:
{
"rules": [
{
"meta": {
"phase": 3,
"function": "当访问/shopxo-1.6.0/idnex.php时,在<a href ...>标签下面增加一个标签(含有假的链接)"
},
"if": [
"REQUEST_METHOD == \'GET\'",
"REQUEST_FILENAME == \'/shopxo-1.6.0/\'",
"#ARGS == 0"
],
"then": {
"execution": [
{
"directive": "alterResponseBody",
"op": "string",
"target": "<div class=\\"navigation-button am-show-sm-only\\">",
"substitute": "<div class=\\"navigation-button am-show-sm-only\\"> <a rel="nofollow" href=\\"http://10.10.11.67/shopxo-1.6.0/index.php?s=/index/user/fake_logininfo.html\\"></a>",
"ignore_case": false
}
]
}
},
{
"meta": {
"phase": 1,
"function": "当爬虫进行页面爬取时,就会访问到假的链接时,进行阻止"
},
"if": [
"REQUEST_FILENAME == \'/shopxo-1.6.0/index.php\'",
"@ARGS.s == \'/index/user/fake_logininfo.html\'"
],
"then": {
"action": "deny"
}
}
]
}网站加载此规则后,爬虫程序有些请求会被拦截,效果如图:
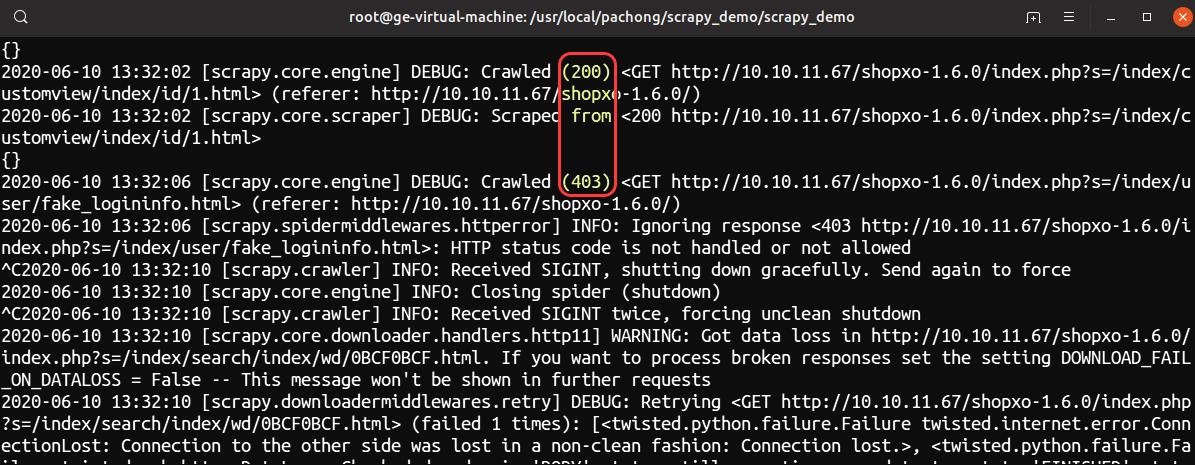
反爬方防护成功。
ROUND 4
爬虫方在前面的攻防对抗中,爬虫程序进行全局爬取会访问到“蜜罐页面链接”。为避开蜜罐,爬虫方使用 Selenium + WebDriver 对网站进行访问,成功爬取网页内容。
反爬方为应对新的爬虫手段,尝试在前端做“插桩”操作,并判断返回的 WebDriver 属性,编写并加载防护规则 anti-crawlers-check-is-selenium-chromedriver.json 如下:
{
"rules": [
{
"function": "1.当访问GET /shopxo-1.6.0/index.php?s=/index/user/reginfo.html 时,修改</head>为",
"function": "<script>const ret = window.navigator.webdriver;$.get(\\"http://[这块写上host即可]/shopxo-1.6.0/index.php/send_result.js\\"+$ret, function(data, status){});</script></head>",
"meta": {
"phase": 3
},
"if": [
"REQUEST_FILENAME == \'/shopxo-1.6.0/index.php\'",
"@ARGS.s == \'/index/user/reginfo.html\'"
],
"then": {
"execution": [
{
"directive": "alterResponseBody",
"op": "string",
"target": "var __user_id__ = 0;",
"substitute": "var __user_id__ = 0; var ret = window.navigator.webdriver;var url_ret=\\"http://10.10.11.67/shopxo-1.6.0/index.php/send_result.js?ret=\\"+ret; var httpRequest = new XMLHttpRequest(); httpRequest.open(\'GET\', url_ret); httpRequest.send(); ",
"ignore_case": false
}
]
}
},
{
"meta": {
"phase": 1,
"function": "当访问send_result.js时,获取到ARGS.ret,查看是否是true,若是则deny"
},
"if": [
"REQUEST_FILENAME == \'/shopxo-1.6.0/index.php/send_result.js\'",
"@ARGS.ret != \'false\'"
],
"then": {
"verdict": {
"action": "deny",
"log": "client is chromedriver!",
"continued": {
"subject": "REAL_IP",
"action": "deny",
"duration": 36000,
"log": "${REAL_IP.__id} in blocking"
}
}
}
}
]
}网站加载本规则后,爬虫请求被拦截,且被持续拦截。
反爬方防护成功。
ROUND 5
爬虫方在上一轮对抗中,因使用 Selenium + WebDriver 会将 WebDriver 属性设为真,对方可据此属性值对爬虫进行拦截。采用如下设置即可修改 WebDriver 的值:
Object.defineProperties(window.navigator,{webdriver:{get:()=>false}})爬虫方每次使用 Selenium + WebDriver 进行爬取前,预先执行一下这段 js 代码,即可成功爬取网页内容。
反爬方对应的防护规则因 WebDriver 值被人为更改而失效,继而尝试增加字体反爬规则。
规则背景是,在爬虫与反爬示例中,字体文件会产生一个 *.woff 的请求:
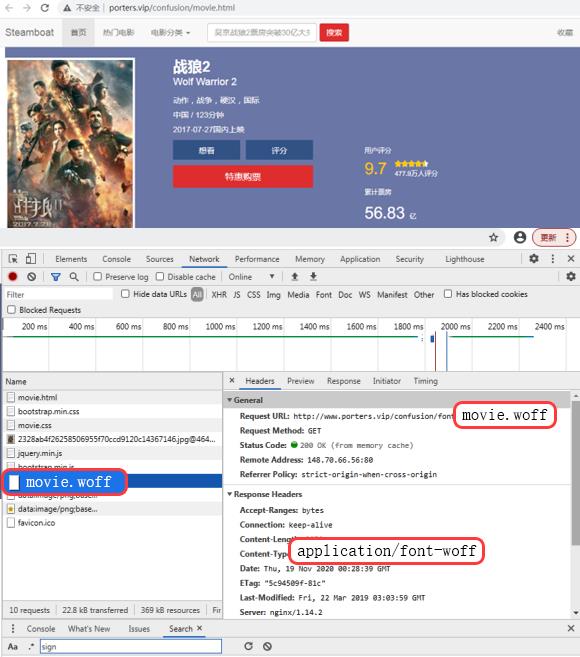
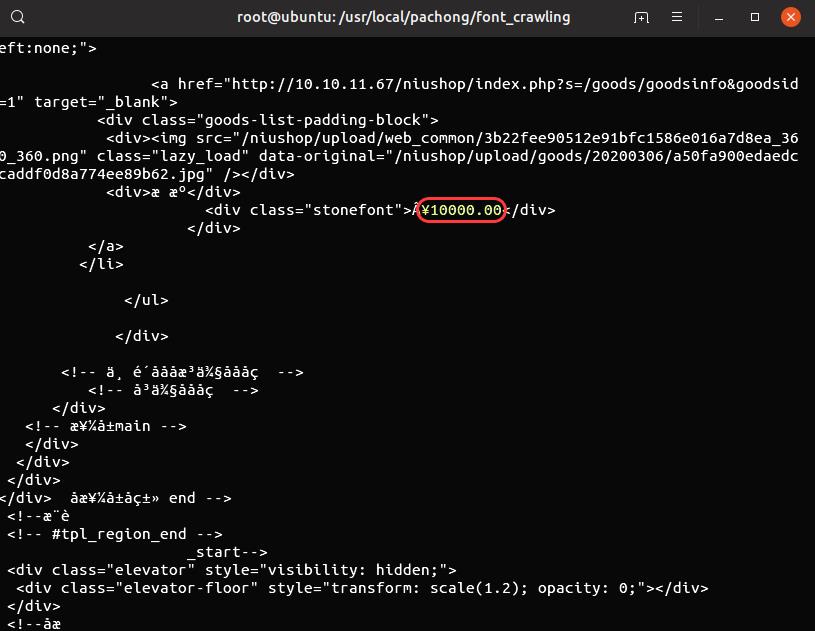
以测试页面 niushop 项目首页为例,对价格进行字体反爬处理:
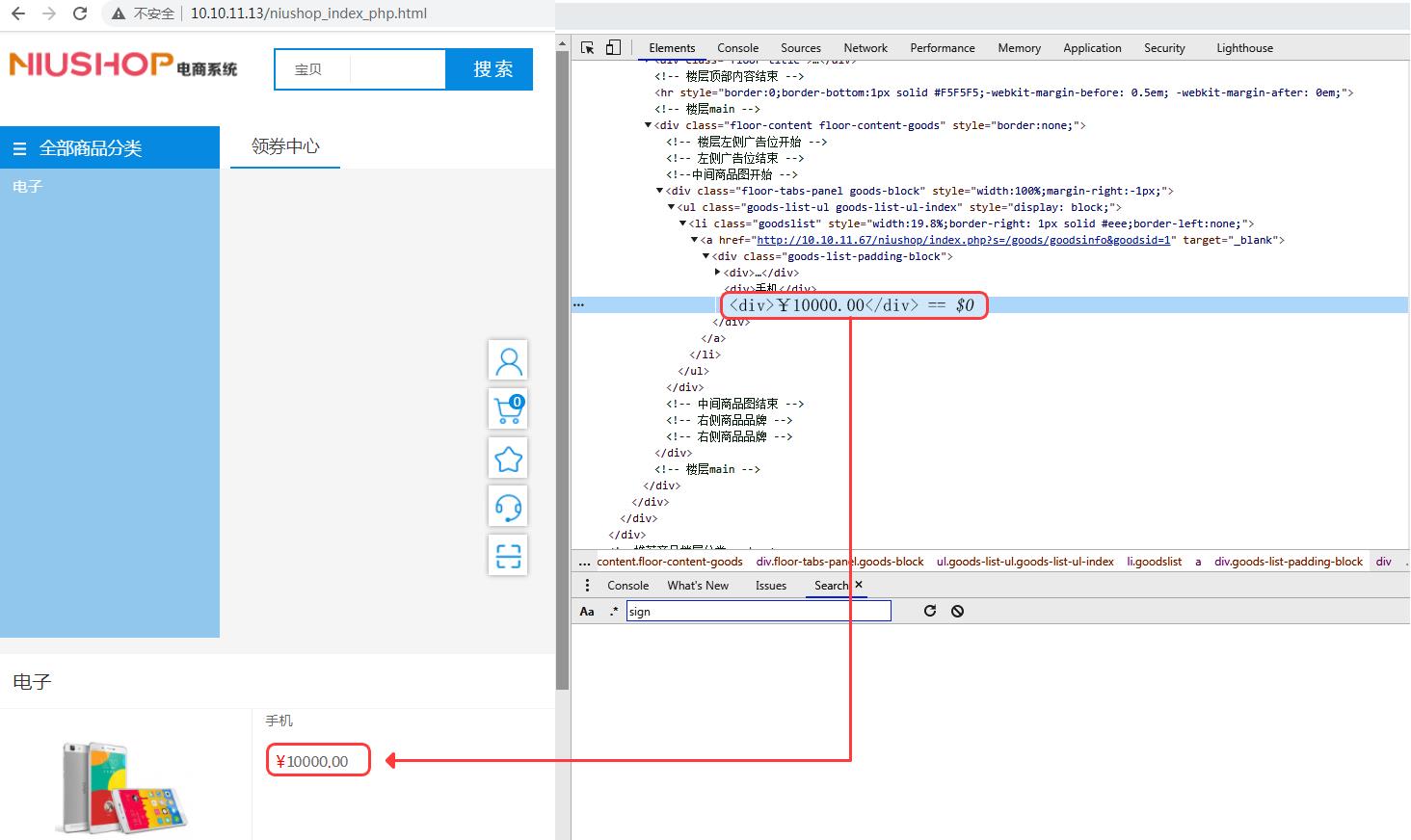
规则如下:
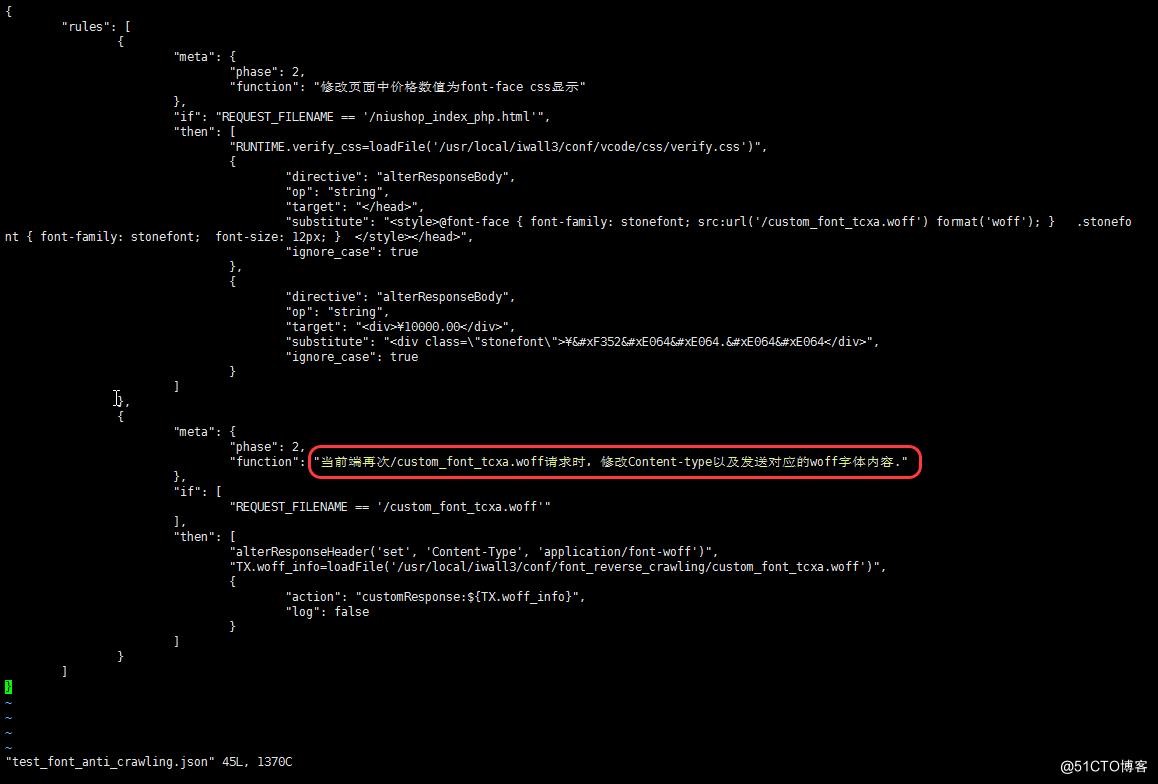
网站加载此规则后,爬虫方获取的价格显示为乱码。
反爬方防护成功 (价格信息)。
ROUND 6
爬虫方受制于字体反爬规则,爬取价格信息时得到的是乱码。于是,在网站字体文件不变的情况下,直接解析固定的 woff 文件——
使用 Python 下 fontTool 库的 ttLib 包,破解反爬的代码文件与效果如下:

爬虫方成功获取网页信息 (准确的价格信息)。
反爬方升级字体反爬规则,以应对爬虫方借字体文件对乱码所做的还原,升级思路是“字体信息不换,动态更换字符编码”——
1. 使用 fontCreator 软件对字体文件进行编码和位置的修改,并产生多个“编码各不相同”、“字体顺序各不相同”和“位置各不相同”的 woff 文件:
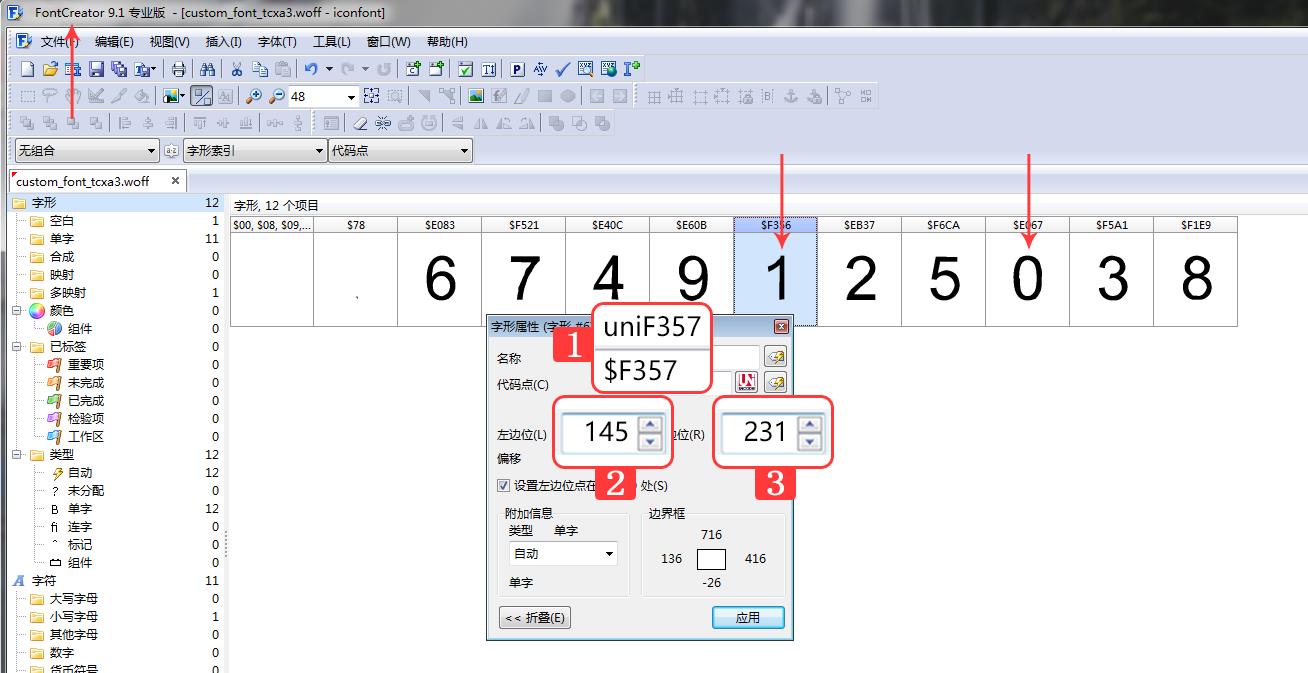
2. 在规则中随机调用这些字体文件。这里生成了 5 个随机 woff 文件 (实际字体坐标点信息不变),在生产环境甚至可以制作 1000 个或更多。规则如下:
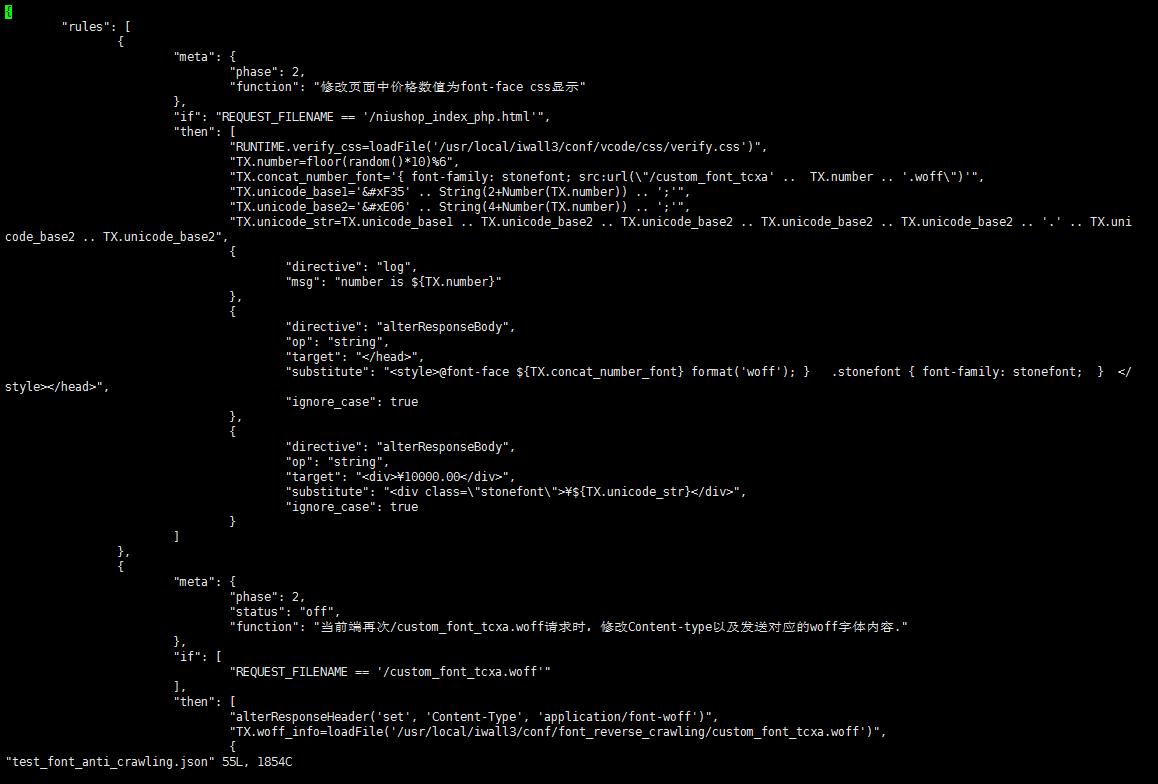
3. 效果是,多次请求获取到不同的 woff,且价格数值显示正常:

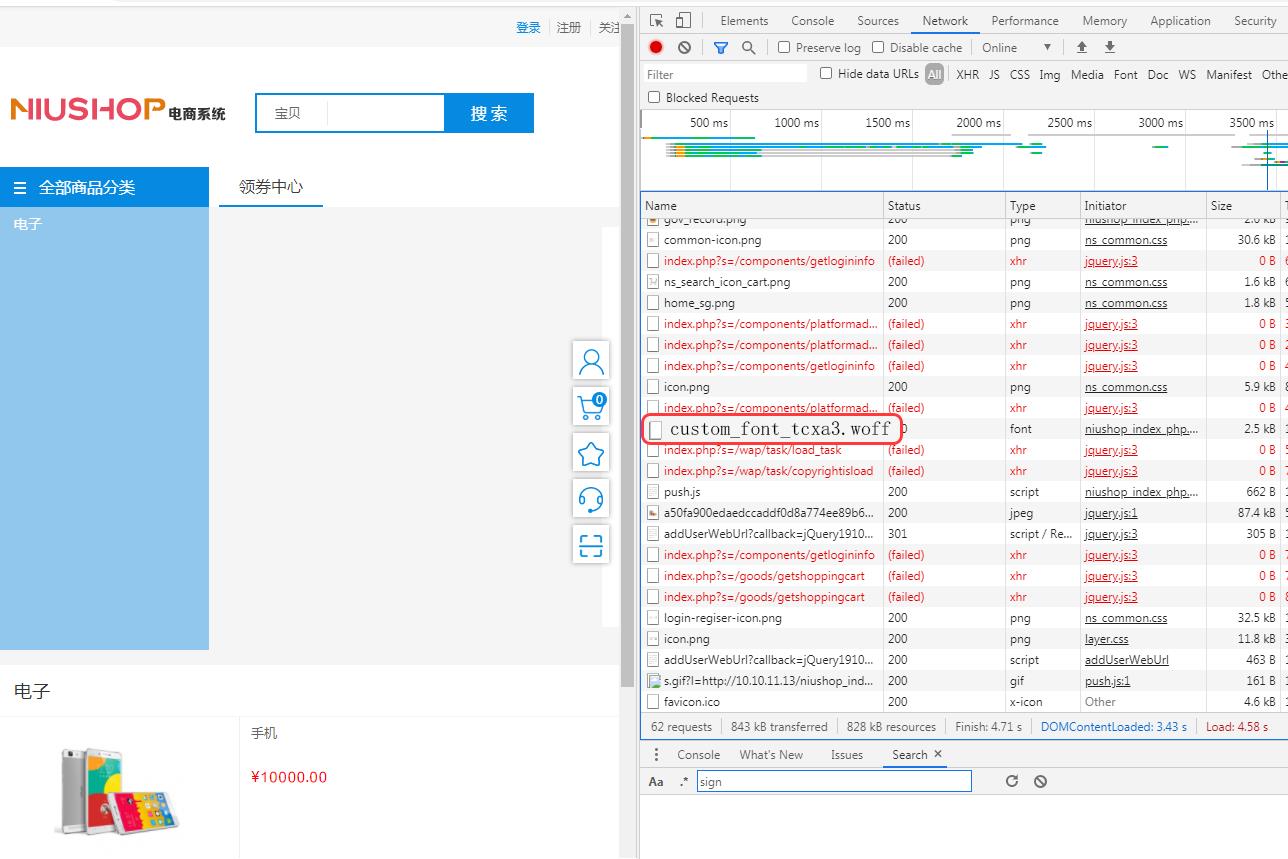
这一措施是利用随机 woff 文件增加爬虫难度。对爬虫方来说,由于 woff 文件中的对应关系变为随机,原先的爬虫程序失效。
反爬方防护成功 (价格信息)。
ROUND 7
爬虫方因防守方升级字体反爬规则,而原有脚本需要对每一个 woff 进行信息映射。如果运行原有脚本,会出现错误的价格数值,测试结果如下:
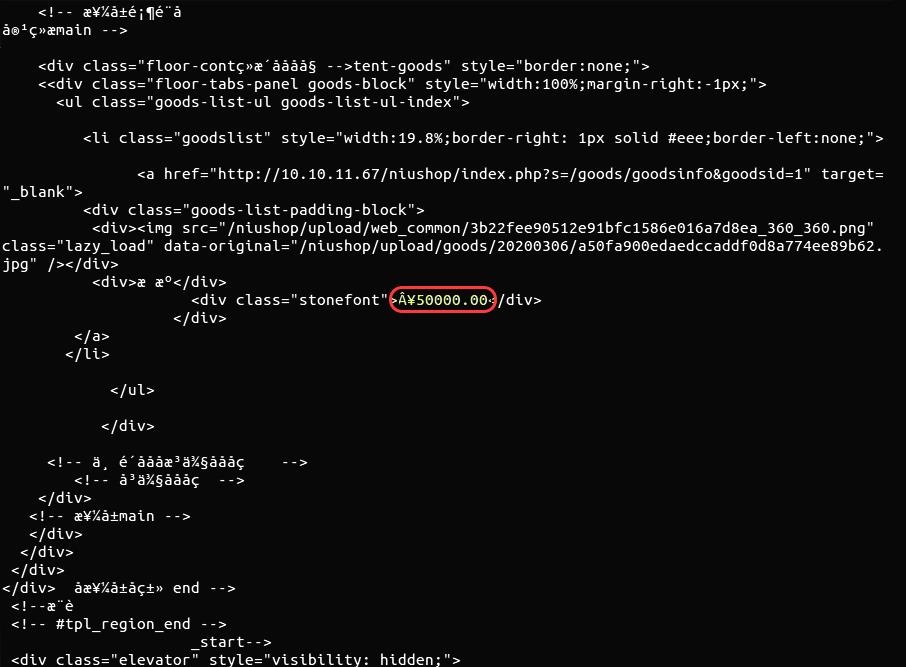
攻击方需加码升级爬虫脚本,根据“同一个字符其字体关键点的坐标是不变的”的逻辑爬取网页。爬取的代码文件如下:
多次访问验证效果,可以获取原有价格数值:
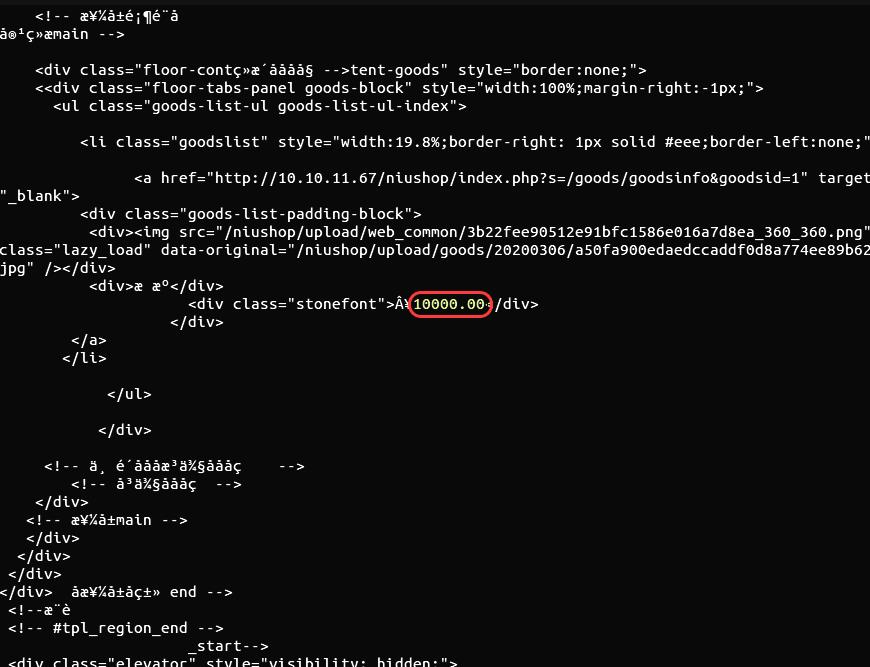
此时,爬虫方可以成功获取网页信息 (准确的价格信息)。
反爬方由于升级后的字体反爬规则被破解,需要继续升级规则。思路:在已有的动态编码的基础上,追加一个动态字体坐标 (以不影响页面字体显示为前提,微调字体的坐标点,类似于验证码中字体的扭曲变形)。通过微调字体形状 (反映在坐标点上),网站可以做出 1000+ 种字体文件,本文测试中设置出 20 种 (0-19) 字体文件用于随机。
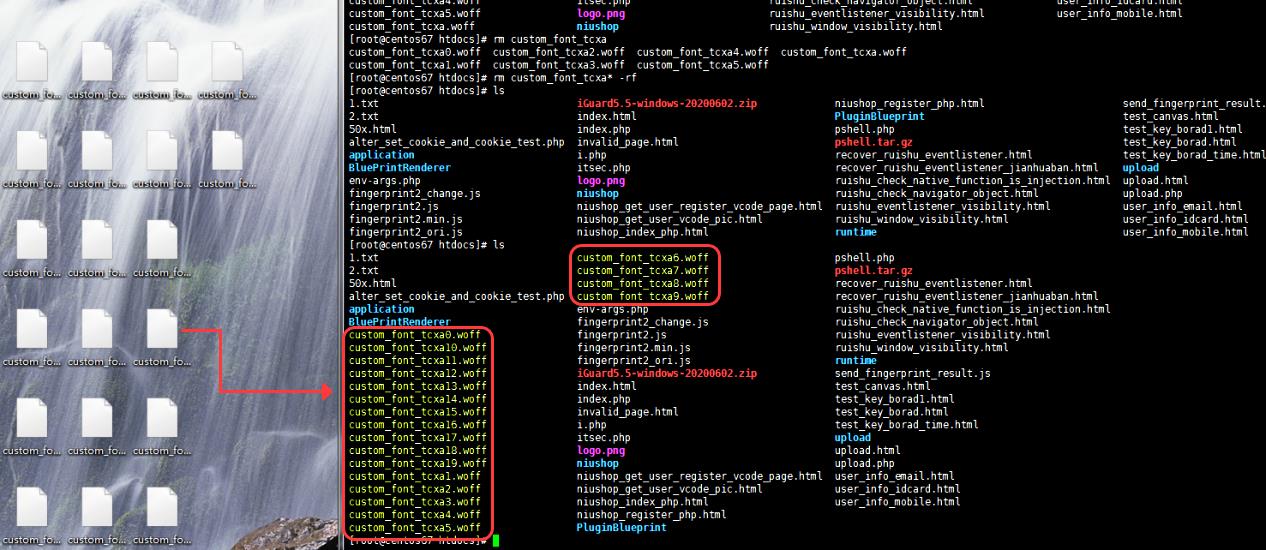
部署后访问页面,价格信息可以正常显示。而爬虫方由于字体本身信息被微调,脚本再次失效。
反爬方防护成功 (价格信息)。
ROUND 8
爬虫方针对字体爬虫脚本的失效,可以发展出两种破解方案:一个是 OCR 技术 (Optical Character Recognition,光学字符识别),另一个是 KNN 算法 (K 近邻分类 K-Nearest Neighbor Classification)。
此处使用 KNN 算法尝试破解。
1. 测试文件地址:


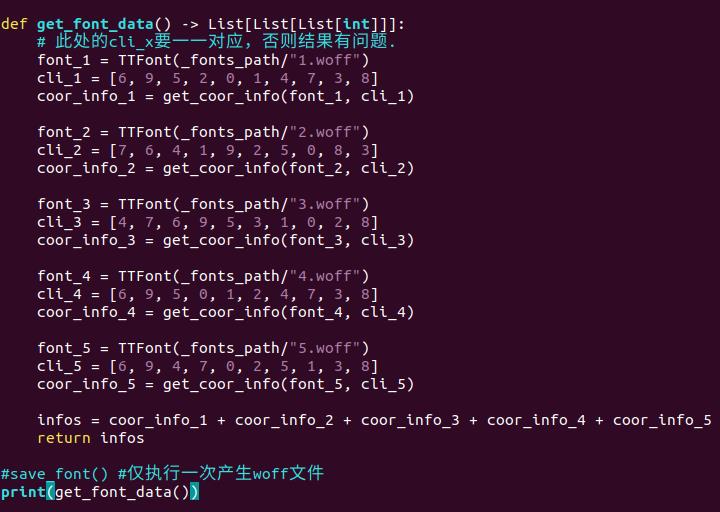
2. 首先,font.py 脚本从网站中下载 5 个随机 woff 文件,存储到 fonts 目录中,并修改 font.py 脚本中所代表的字体值 (根据下载的 woff 文件在 fontCreator 中的顺序修改),如下:
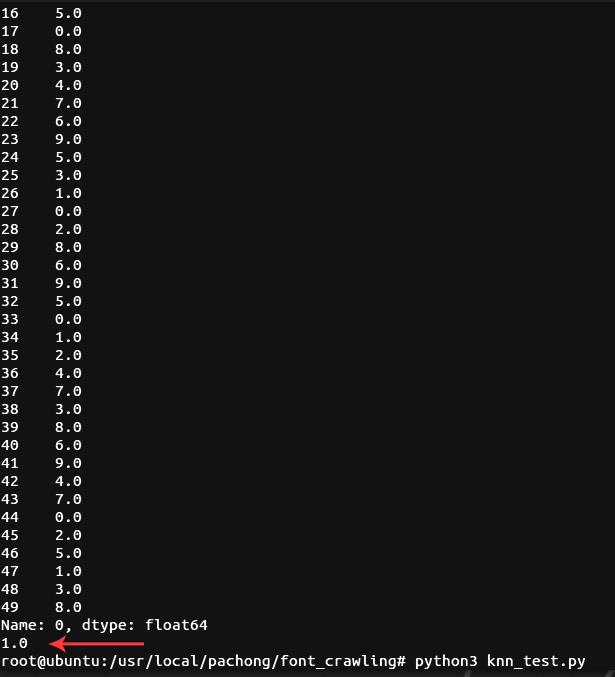
3. 而后,执行 python3 knn_test.py,看到预测率为 100%,如图:
4. 接下来,预测并替换原响应内容,得到正确内容:
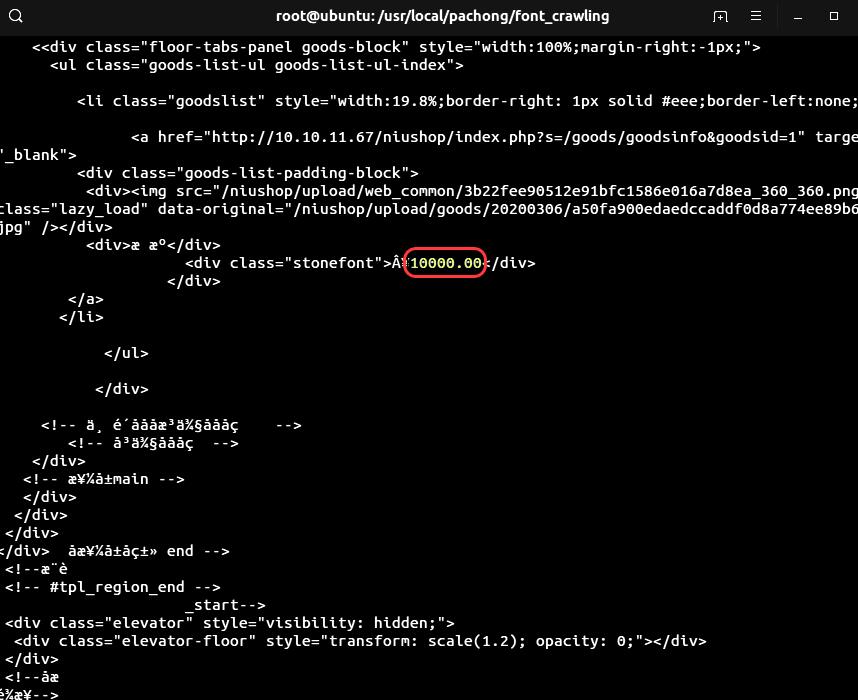
可以看到,爬虫方成功获取了信息。
反爬方字体反爬规则对 KNN 算法失效。此时,在字体上的反爬措施也已经走到尽头。防守需转换阵地,对相关网页内容进行 js 混淆,使用 javascript-Obfuscator 开源项目进行加密测试。
在本文的测试环境下,通过 cli 命令对 handle_init_js.js 文件进行混淆:
javascript-obfuscator/bin/javascript-obfuscator handle_init_js.js -o a_out.js --compact false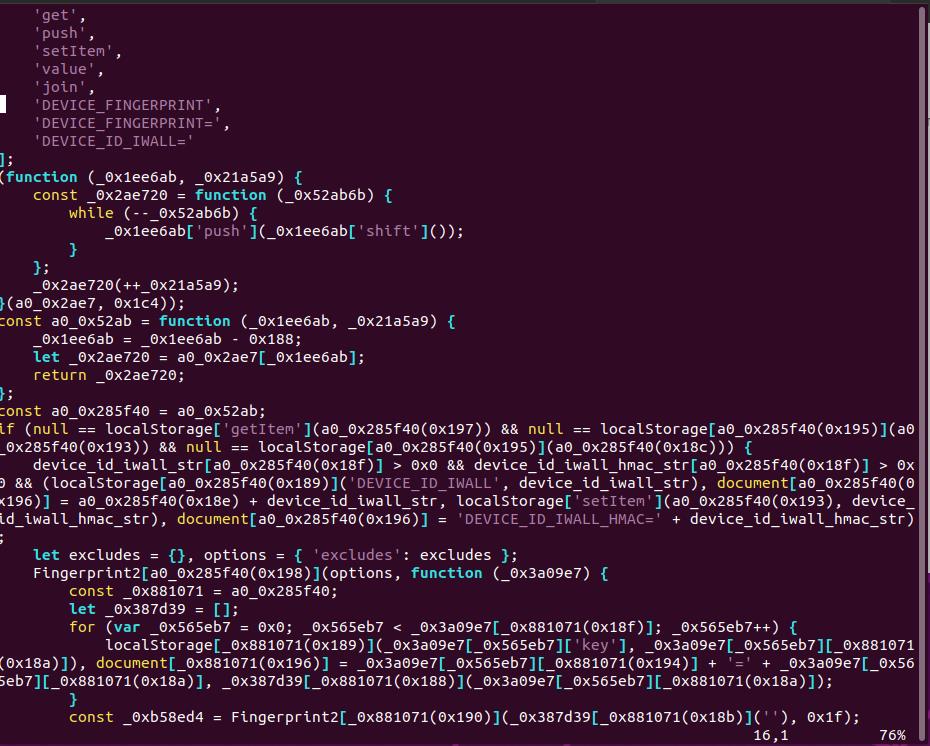
由于网页信息做了 js 混淆处理,爬虫方需要先解密混淆的 js 代码。如果爬虫方无法解密混淆后的 js 代码,则网站反爬防护成功。
ROUND 9
爬虫方一旦其一步步吃透了混淆后的 js 代码,同样可以成功爬取网页信息。
反爬方需继续改变应对策略,增设图片反爬规则。
这里有两种方式:
方式一:将敏感文字信息以图片形式显示,并设置图片加扰等措施。效果和规则如下:
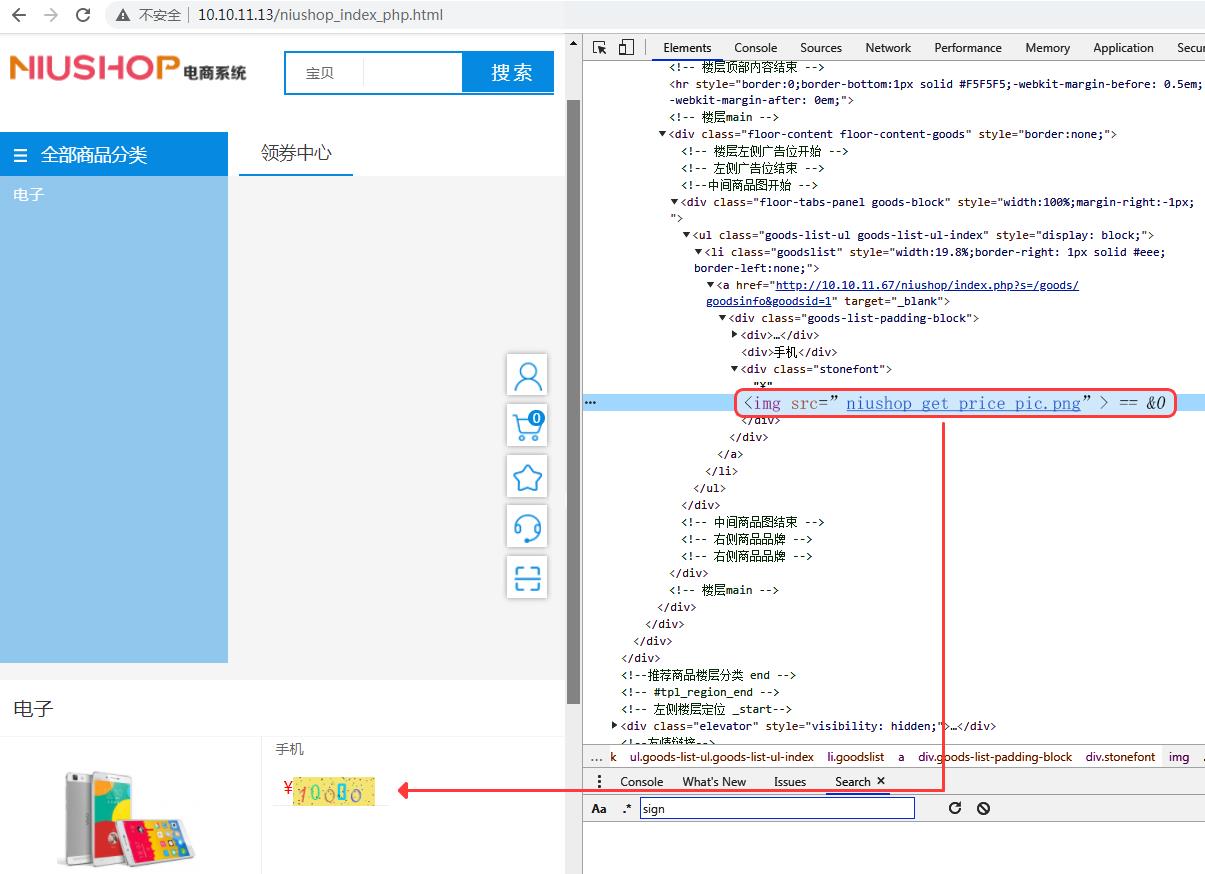
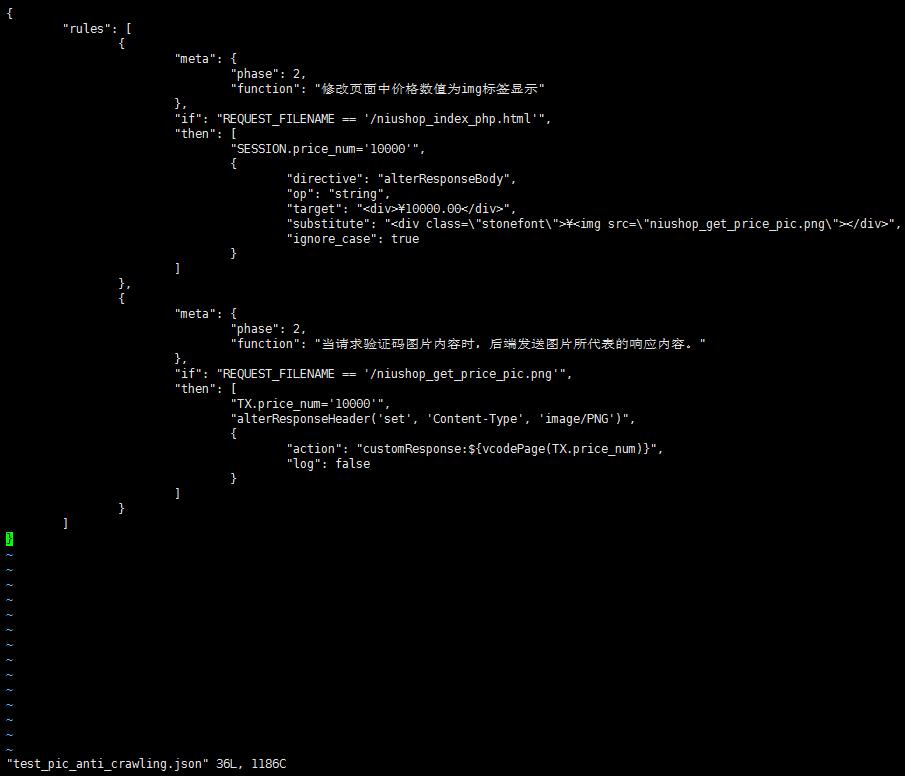
方式二:svg 图片与 css 样式偏移显示结合,进行反爬。效果和规则如下:
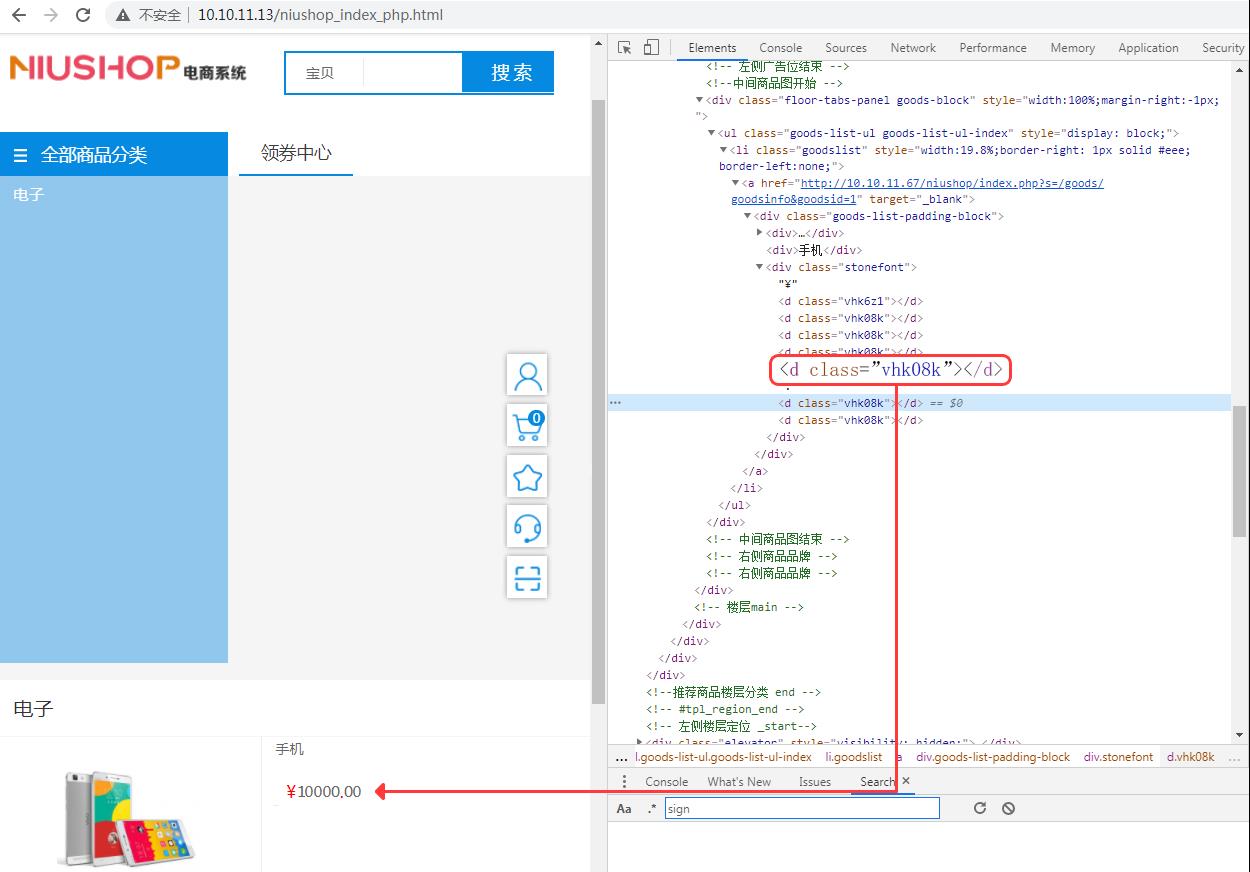
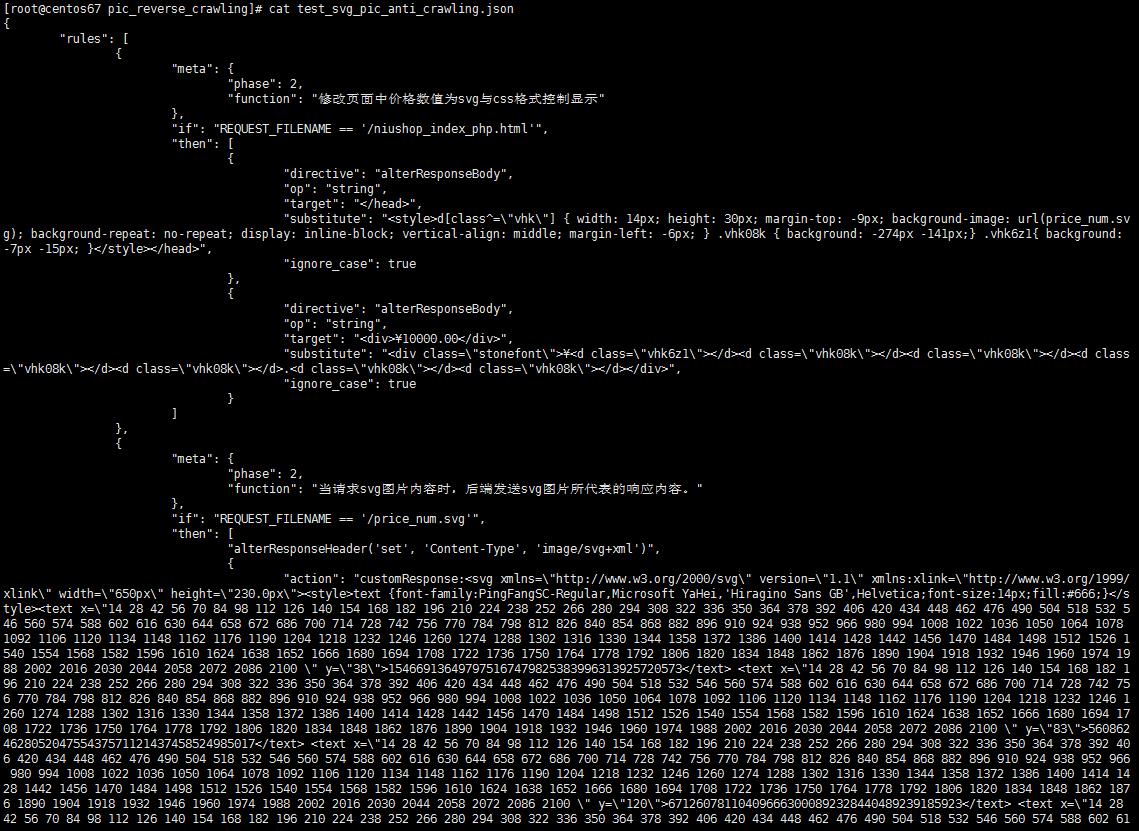
由于价格以图片显示,能爬取的只有图片链接和 html 标签信息,并不能直接获取价格信息。在爬虫方难以进一步做图片识别的情况下,可视为对网站进行了成功的反爬防护。
ROUND 10
爬虫方:上回合里,价格以图片方式呈现,爬虫方无法直接获取价格信息,故需要使用 OCR 技术来获取图片中的内容。
以 Tessarect(c++) 开源项目为例 (地址),安装命令为:
./autogen.sh && ./configure && make && make install && ldconfig
git clone https://github.com/tesseract-ocr/tessdata.git
export TESSDATA_PREFIX=/usr/local/pachong/ocr/tesseract/tessdata/测试如图所示:
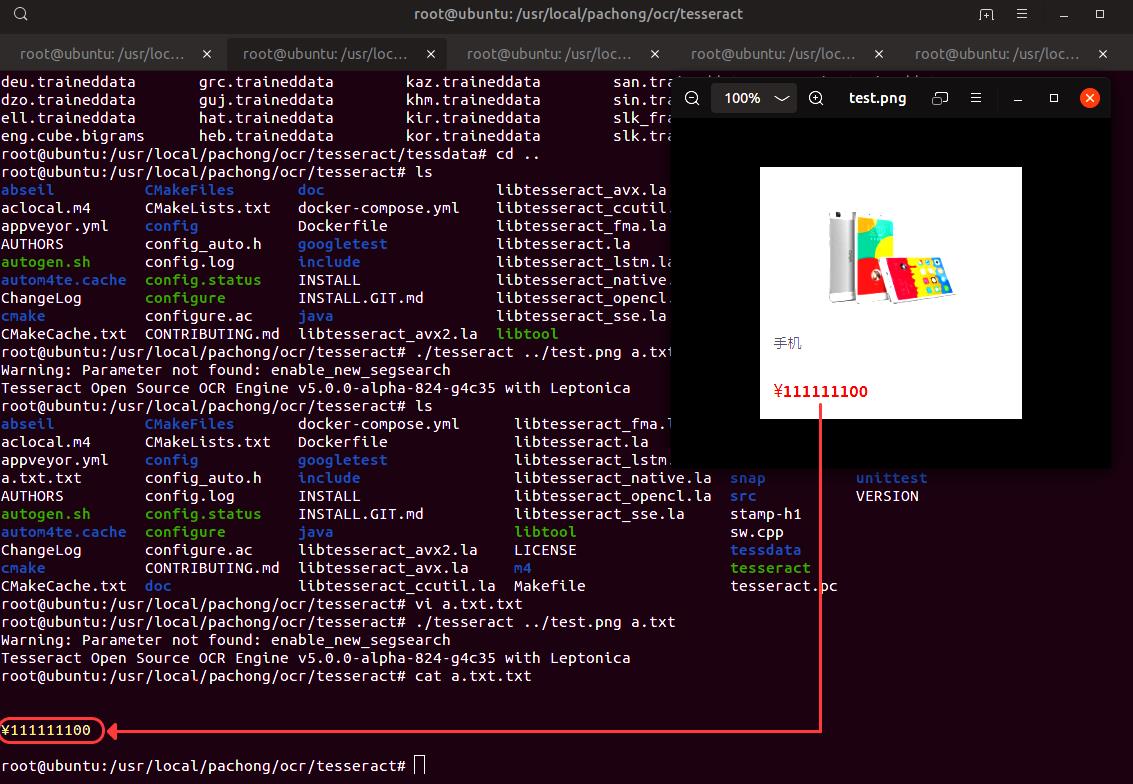
可以看到,图片内容被准确识别出来,爬虫成功获取到了价格信息。
反爬方:网页终究是提供信息供用户阅览的,当爬虫方使用 OCR 技术进行图片识别的时候,网站暂时是没有更好的办法进行反爬防护的。当然,还可以继续跟爬虫方在图片显示技术上进行对抗,譬如使用图片水印对原信息进行处理。网页终究是要呈现信息给用户的,当走到爬虫方使用 OCR 技术进行图片识别这一步时,网站暂时是没有更好的办法进一步反爬的。当然,还可以继续跟爬虫方在图片显示技术上进行对抗,譬如使用图片水印对原信息进行处理。
(张戈 | 天存信息)
以上是关于进击的反爬机制的主要内容,如果未能解决你的问题,请参考以下文章
python爬虫---CrawlSpider实现的全站数据的爬取,分布式,增量式,所有的反爬机制