小布助手在面向中文短文本的实体链指比赛中的实践应用
Posted OPPO小布助手
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了小布助手在面向中文短文本的实体链指比赛中的实践应用相关的知识,希望对你有一定的参考价值。
背景介绍
实体链指是指对于给定的一个文本(如搜索 Query、微博、对话内容、文章、视频、图片的标题等),将其中的实体与给定知识库中对应的实体进行关联。实体链指一般有两种任务设计方式:Pipeline 式和端到端式。
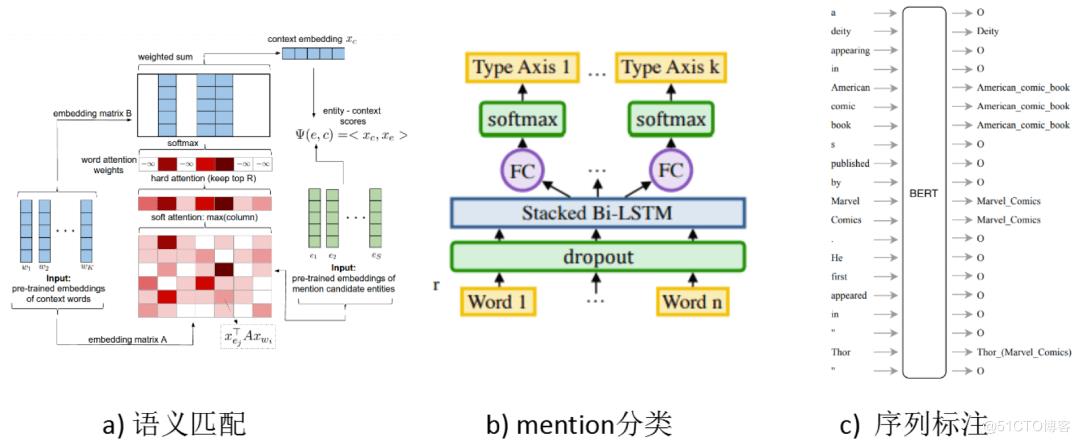 任务抽象方式
任务抽象方式
赛题说明
百度飞桨举办的 千言数据集:面向中文短文本的实体链指任务给出了中文短文本、短文本中的 mention 以及对应位置,需要预测文本中 mention 对应实体在给定知识库中的 id,如果在知识库中没有对应实体即 NIL,需要再给出实体类别。
训练集数据共 7W 条,query 平均长度 22,包含 26W 个 mention,每个 mention 有 6.3 个候选实体,被链接到的 NIL 实体有 3W 个,其中 1.6W 在知识库中有同名实体。可以发现有三个特点:
-
文本长度短,上下文信息有限
-
候选实体数量多
-
NIL 数量多,占比超过了 10%
模型方案
这次比赛已经给出了 mention 信息,我们只需要考虑两个任务:实体消歧和 NIL 分类。任务的关键有以下几点:如何设计输入样本、如何设计模型结构、NIL 实体如何与其他实体一起排序、如何挖掘更丰富和多维度的特征等。
样本构造
我们选取了 ERNIE、RoBERTa 等预训练语言模型进行语义特征抽取,将需要链指的文本和实体描述信息用[SEP]符号拼接,作为模型的输入。
query 样本构造:query 样本输入时需要将 mention 的位置信息传入模型,让模型能判断 mention 在 query 中的具体位置,例如:“海绵宝宝:海绵宝宝和派大星努力工作,两人来到高速公路上!”中出现了两次海绵宝宝,分别链接到了动画片《海绵宝宝》和动画人物海绵宝宝,需要加以区分。为了解决这一问题我们通过引入标识符将位置信息传入,在 mention 两边加入统一的标识符“#”,样本如下:

实体描述样本构造:数据库中的实体包含了实体的标准说法 subject,实体的类型 type 和实体的一些相关 SPO 信息。构造样本时将 mention 字段和实体标准名用“-”拼接作为输入,强化标准名和 mention 是否相同这一特征。实体类型是消歧重要的信息,我们构造了“类型:实体类型”这种描述,提供实体类型信息,为了防止截断,将其放在实体标准名之后。SPO 信息只使用了属性值,这样可以使超过最大输入长度的样本数量减少 35%。

统计特征样本构造:数据和特征决定了模型的上界,为了丰富模型输入,将实体类型、实体长度、mention 长度、实体和 mention 的 Jaccard 相似度等特征进行 embedding 了之后,和模型输出的特征向量拼接。
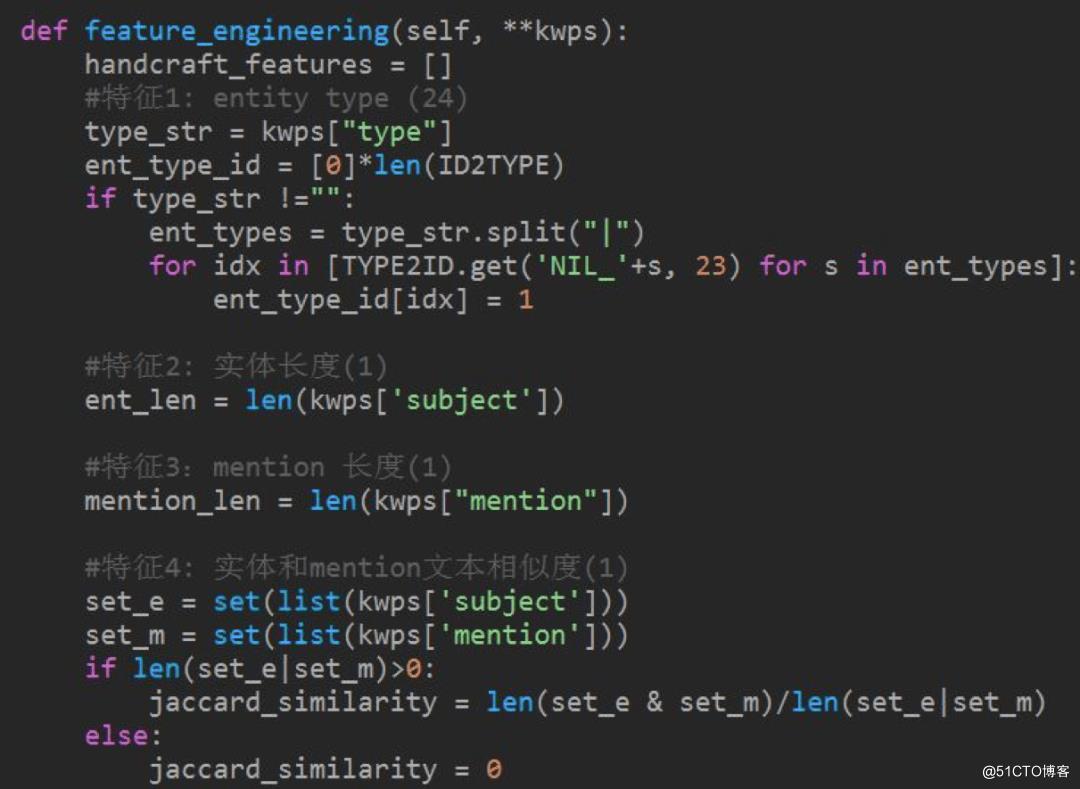
模型结构
实体消歧本质上是对候选实体进行排序的过程,使用 query 和实体信息作为输入,对候选实体进行排序,给出候选实体分数,选出 TOP1 实体。在排序学习中,有三种常见模式 pointwise,pairwise 和 listwise,对于实体消歧这种只需要 TOP1 的排序任务,并不需要考虑候选实体之间的顺关系,只考虑全局相关性,因此我们选取了 pointwise 方法。
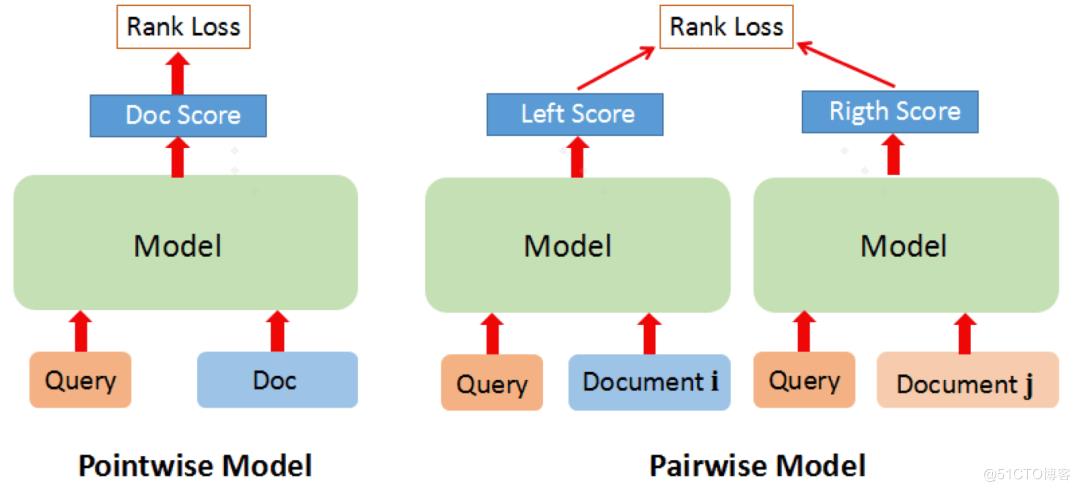 排序学习模型示意
排序学习模型示意
实体分类任务和实体链指任务看起来没有直接联系,但是 Shuang Chen [2] 提出当可以预测出 mention 的类型时,消歧就相当容易。因此我们设计了多任务模型框架,同时进行排序和分类,两个任务共享模型参数,一起训练,损失函数一起优化,通过共享排序任务和分类任务的信息,模型可以有更好的表现,多任务损失函数如下。

最终我们模型结构如下,将 query 和实体描述拼接,输入预训练语言模型,将 CLS、mention 开始和结束位置的向量拼接作为特征向量。排序任务将特征向量输入全连接层,然后经过 tanh 最终输出[-1,1]区间的分数,分数越高代表越有可能是目标实体。分类任务将特征向量输入全链接层,经过 softmax 层输出各个分类的得分。
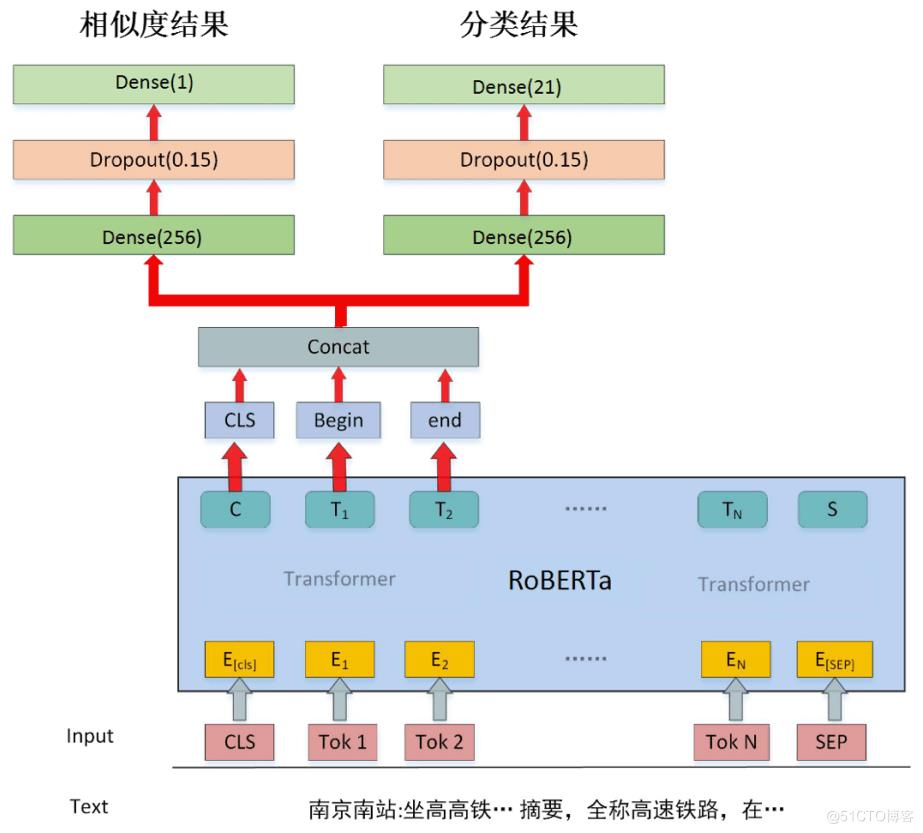 实体链指和分类模型结构
实体链指和分类模型结构
模型优化
数据清洗
基于置信学习数据清理:分析数据集我们发现,数据之中存在部分标注错误,根据 Northcutt [6] 置信学习的思想,我们在原始数据上用 n-flod 方式训练了 5 个模型,用这些模型预测原始训练集的标签,然后融合 5 个模型输出的标签作为真实标签,再从原始训练集中清理真实标签与原标签不一致的样本,根据经验清理的样本数量最好不大于 10%。
NIL 实体排序方式实验
实体消歧过程中 NIL 实体如何和其他实体一起排序,是单独作为一个分类任务,还是将 NIL 转换为特定类型的实体参与排序,针对这个问题,我们设计了三种方案:
-
方案 1:只对知识库中存在的实体进行排序,当 top1 的 score 小于阈值时,认为是 NIL 实体;
-
方案 2:构造 NIL 实体样本“mention-mention,类型:未知类型”,例如:“英雄三国-英雄三国,类型:未知类型”,表示该实体是一个未知实体。预测和训练时,所有 mention 候选实体中增加一个未知实体,参与排序;
-
方案 3:将所有候选实体拼接,和 query 样本一起输入模型进行分类,判断是不是 NIL 实体,理论上这样可以带来更多全局信息。考虑到训练速度,我们先用 1)中的方案进行排序,然后将 top3 的实体描述拼接,训练一个分类模型。
对抗训练
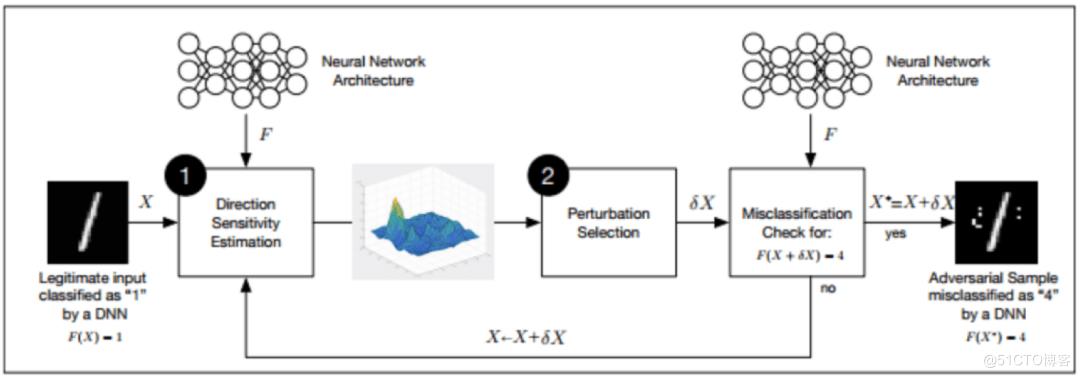 对抗训练流程示意
对抗训练流程示意
对抗训练是指在模型的训练过程中构建对抗样本,参与模型训练的方法。正常训练过程中,如果梯度方向陡峭,那么很小的扰动都会产生很大的影响。为了防止这种扰动,对抗训练在模型训练的过程中使用带扰动的对抗样本进行攻击,从而提升模型的鲁棒性。我们实验了 FGM 和 PGD 两种生成对抗样本的方式。
 对抗样本生成代码
对抗样本生成代码
实验结果分析
模型可解释性
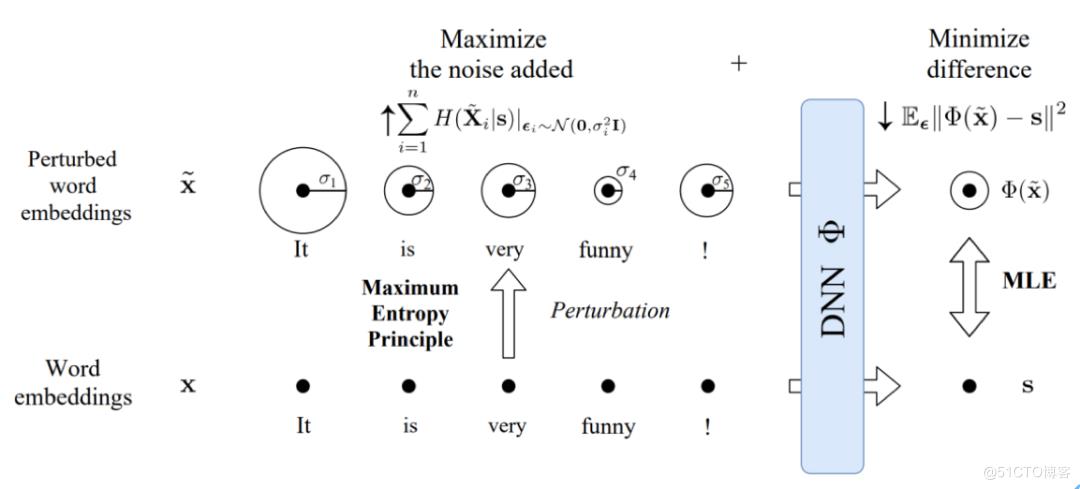 可解释性建模示意
可解释性建模示意
在训练完模型后,我们首先会想要知道模型学到了哪些特征。C Guan [7] 提出了一种基于互信息的可视化方法,这种方法相较其他可视化方法,具有普适性和一贯性的特点,即解释指标有明确的意义,同时又能比较神经元之间、层与层之间和模型与模型之间的差异。
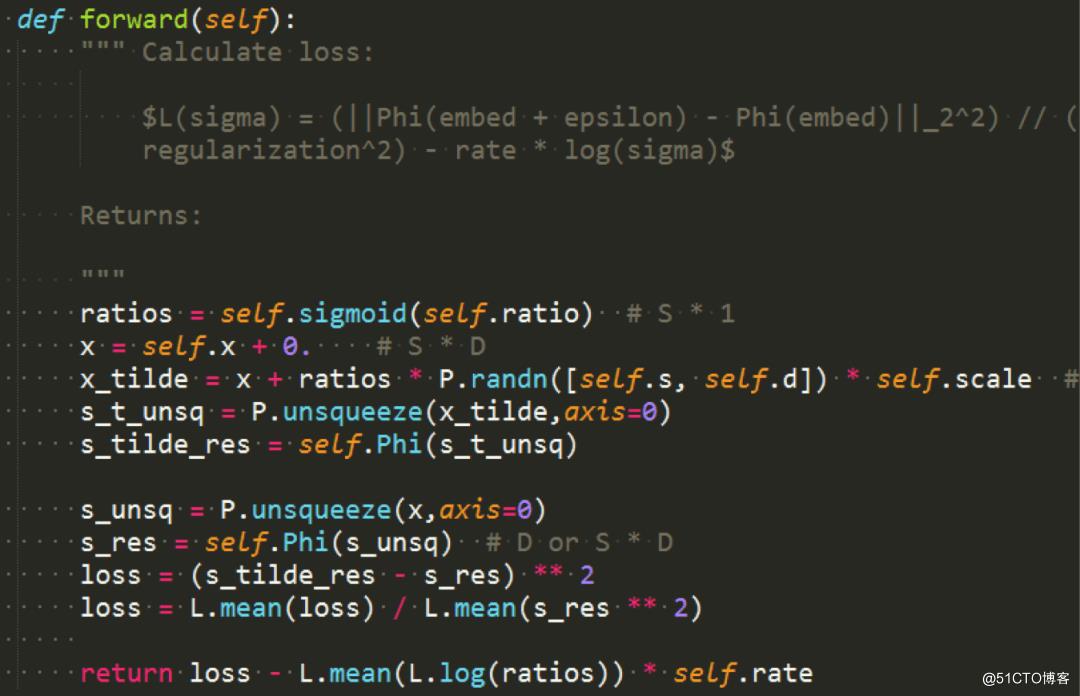 可解释性建模代码
可解释性建模代码
为了了解模型到底关注哪些输入特征,我们基于 Paddle2.0 复现了该算法,对各个词的重要程度进行了可视化,颜色越深重要程度越高。通过可视化发现,模型倾向于关注实体的类型和用来区分实体的片段,例如示例 1 吃得慢、食物、吃法、火腿肠,示例 2 中的珊迪、海绵宝宝、开关电源品牌。示例 3 种的人物、种族、梦三国等,可以看到多任务模型关注的特征都是对消歧有帮助的。

实验结果分析
相关实验中参数配置如下:ERNIE 和 BERT 的模型 batch size 为 64,初始学习率为 5e-5,max_seq_length 为 256,RoBERTa-Large 的模型 batch size 为 32,初始学习率为 1e-5,max_seq_length 为 256,均采用了基于指数衰减的学习率衰减策略。
对比不同预训练模型和置信度学习的结果,发现模型效果 RoBERTa-Large > ERNIE+置信度学习>ERNIE>BERT。可以看到 ERNIE 专门针对中文数据进行了任务优化,确实比 BERT 的效果更好,但是 ERNIE(12 层)和 RoBERTa-Large(24 层)的对比说明了一寸长一寸强,更多的参数可以有更好的表现。
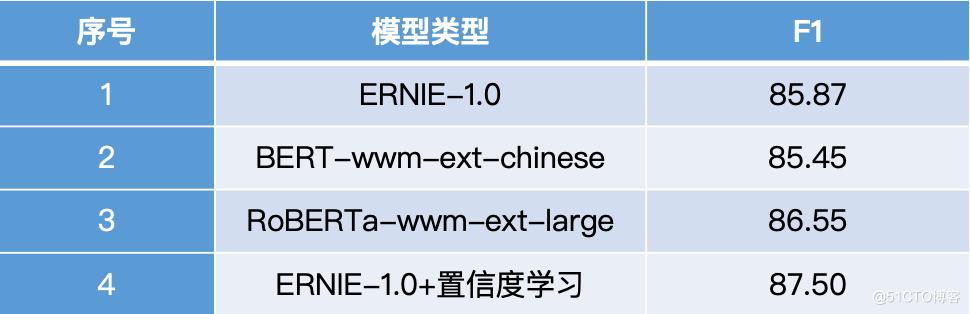 表1 预训练模型对比
表1 预训练模型对比
对比单任务和多任务时,我们使用了基于 ERNIE 的模型。通过对比多任务和单任务的模型效果,我们发现多任务不但流程简单,而且效果也比单任务联合好。排序时模型需要借助类型信息判断 mention 与候选实体是否一致;NIL 分类时能学习到知识库中其他候选实体的信息,所以两个任务共享参数可以使模型提取到两个任务的共性,提升模型效果。
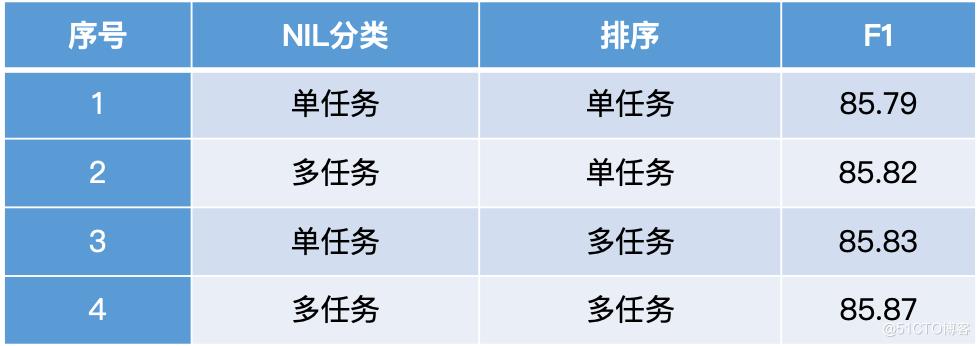 表2 单任务和多任务对比
表2 单任务和多任务对比
从模型 1、2、3 可以看到对抗学习是一种通用的模型优化方法,在各种模型上都有明显提升,但是 FGM 和最强一阶对抗方式 PGD 实体链指任务上差距并不明显。
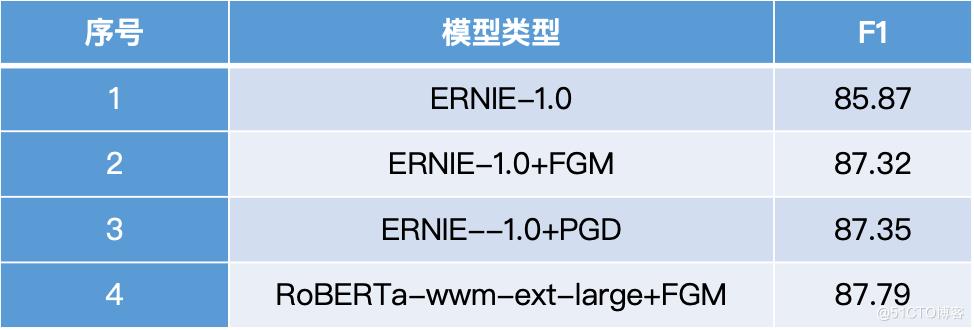 表3 对抗学习效果
表3 对抗学习效果
NIL 不同方式参与排序的实验中,我们发现使用构造 NIL 样本参与匹配和对排序 TOP1 的 score 卡阈值这两种方式结果差别不大,AUC 分别为 0.97 和 0.96,训练 NIL 分类器的 AUC 仅为 0.94,猜测是因为对候选实体进行 top3 采样时,已经有了误差积累。
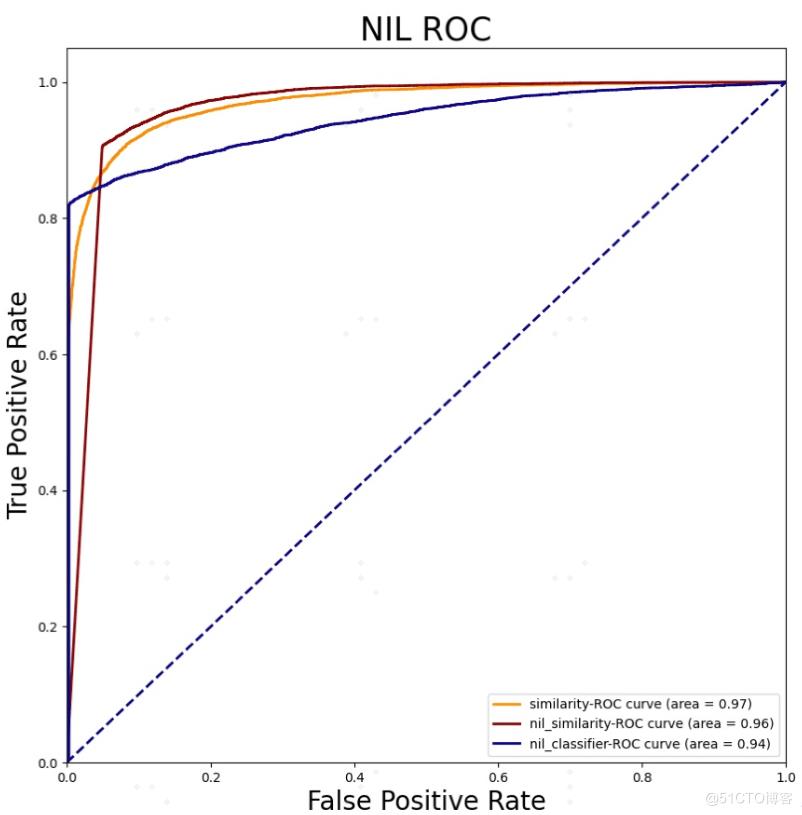 NIL不同方式参与排序的ROC曲线
NIL不同方式参与排序的ROC曲线
通过将表现好的模型进行融合我们在 dev 测试集上的 F1 达到了 88.7,在 A 榜数据集 F1 达到 88.63,在 B 榜数据集 F1 达到 91.20,最终排名第二。
小布助手的探索
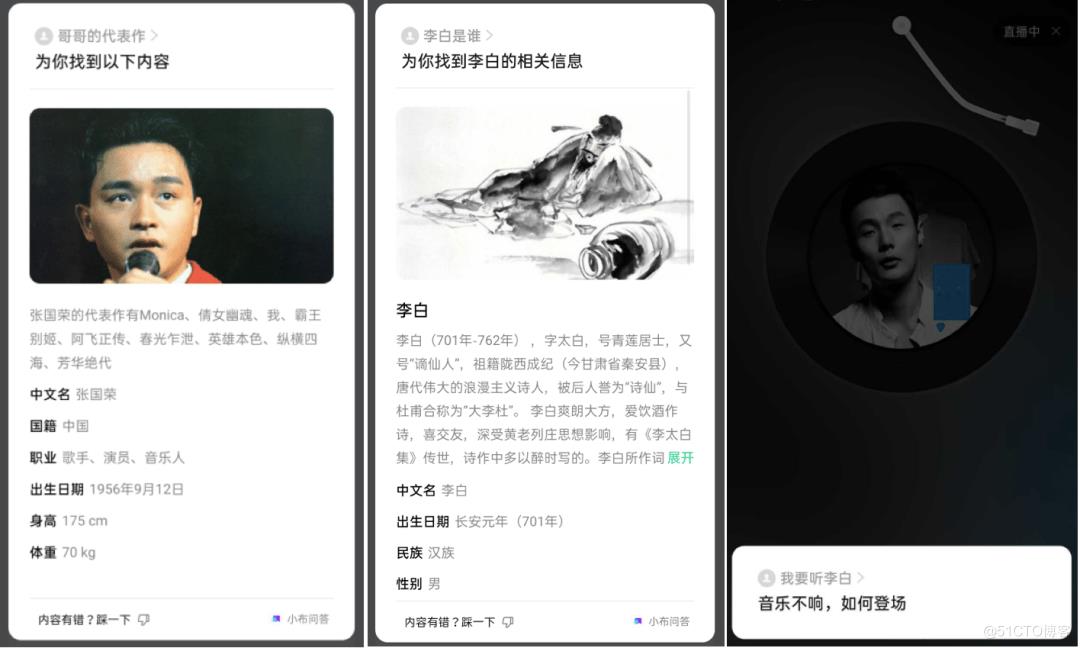
小布助手每天处理千万级别的用户问题,其中涉及实体词的 query 高达 30%。这些由不同人发出的真实对话里,既包含千人千面的主观表达,更包含大量的创新词汇,多义词,同义词,同时也经常会面对“李白是谁”、“我要听《李白》”这类 mention 有歧义的问题。
 小布助手实体链指流程
小布助手实体链指流程
小布助手的技术积累不仅帮助我们在比赛中名列前茅,而且已经帮用户解决“哥哥的代表作”、“李白是谁”、“我要听《李白》”等常见而语音助手又极易误解的用户问题。黑格尔说过:人是靠思想站立起来的。思考赋予人类尊严,驱动文明不断向前。小布助手汇聚无数背后英雄的思想,也在默默努力,然后用有趣贴心有灵魂惊艳所有人。
赛后感想
工欲善其事,必先利其器,本次比赛使用了飞桨 2.0 框架进行训练,动态图模式下程序可即时执行并输出结果,提高了编码效率。借助百度的 PaddleNLP 工具包,可以无缝切换 ERNIE、BRART、RoBERTa 等预训练模型,非常适合比赛时快速实验。
PaddleNLP 工具包链接:https://github.com/PaddlePaddle/PaddleNLP
这次比赛的赛题也很值得探索,实体消歧和分类两个任务如何有机结合,可以做很多尝试。一个实体链指任务就有抽象成多种方式,足以见得兵无常势,水无常形,我们在解决算法问题时,要跳出思维定势,尝试从不同的角度去抽象问题,找到最佳的解决方案。
本项目链接:
除了实体链指任务,千言项目还有情感分析、阅读理解、开放域对话、文本相似度、语义解析、机器同传、信息抽取等方向持续打榜中。
传送门:
参考文献
[1]Deep Joint Entity Disambiguation with Local Neural Attention. Octavian-Eugen Ganea, Thomas Hofmann.
[2]Improving Entity Linking by Modeling Latent Entity Type Information,Shuang Chen, Jinpeng Wang, Feng Jiang, Chin-Yew Lin.
[3]End-to-End Neural Entity Linking. Nikolaos Kolitsas, Octavian-Eugen Ganea, Thomas Hofmann.
[4] Improving Entity Linking by Modeling Latent Entity Type Information. Shuang Chen, Jinpeng Wang, Feng Jiang, Chin-Yew Lin.
[5]Towards Deep Learning Models Resistant to Adversarial Attacks. A Madry, A Makelov, L Schmidt, D Tsipras.
[6]Confident Learning: Estimating Uncertainty in Dataset Labels. Curtis G. Northcutt, Lu Jiang, Isaac L. Chuang.
[7]Towards a Deep and Unified Understanding of Deep Neural Models in NLP. Chaoyu Guan, Xiting Wang, Quanshi Zhang, Runjin Chen, Di He, Xing Xie.
作者介绍
樊乘源
OPPO 小布助手 NLP 工程师
负责对话和知识图谱相关工作,研究方向包括意图分类、序列标注、关系抽取、实体链指等。
以上是关于小布助手在面向中文短文本的实体链指比赛中的实践应用的主要内容,如果未能解决你的问题,请参考以下文章