Logistic回归
Posted mmい
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Logistic回归相关的知识,希望对你有一定的参考价值。
写在前头,平日里自以为对逻辑回归的理论推导什么的了解很透彻,核心思想也就是一个梯度下降算法而已,实现起来却花了我一整天,具体困扰我的是对于各种矩阵操作的不熟悉以及对于代码结构的设计不当造成的;下面详细展开我的实现啦,多练多练才能真正理清算法的真正漏洞<( ̄ˇ ̄)/
读取数据集
- 因为逻辑回归中有大量的矩阵运算,因此我将返回的数据类型设置为矩阵
np.mat,当然你也可以使用np.array;但是array在进行矩阵相乘时要使用np.dot(a,b),直接a*b是矩阵元素乘积;使用matrix时a*b是矩阵乘法。这是二者的差别,matrix本来就是用来做矩阵运算的数据类型,因此这里用这个最合适不过了。
''''''
import numpy as np
from numpy import mat
def createDataSet(filename):
f = open(filename)
dataSet = []
labels = []
for line in f.readlines():
data = [float(data) for data in line.strip().split()]
'''在样本的第一列添加一个属性值恒为1,这样系数和偏差可以合并为w'''
dataSet.append(data[:-1])
labels.append([data[-1]])
'''下面这个方法是将两个矩阵合并,按列合并,前提是二者行数相等'''
dataSet = np.column_stack((np.ones((len(dataSet),1)),dataSet))
return mat(dataSet),mat(labels)
dataSet,labels = createDataSet("train.txt")- 函数的返回值是两个矩阵,
dataSet是训练集大小100*3,训练集本来只有两个属性,但是加了一个X0=1常值属性因此有三个属性,总共100个样本。labels是类标签,类别为0和1,大小为100*1的列向量。
梯度下降
关于线性分类器的梯度下降的公式都如下:左边是梯度下降的伪代码(每次遍历所有样本计算梯度),右边是随机梯度下降的伪代码(每次使用一个样本计算梯度)。这里的h(x)就是样本属于1的概率,是将样本特征乘以一个回归系数然后代入到Sigmod函数中得到的一个介于0和1之间的值;在线性回归中公式也是这样,不过线性回归中y是样本真实值,h(x)为样本x的预测值,是特征与回归系数的乘积;

梯度下降:在设计之初并没有想好要传入这么多的参数,直到慢慢修正过程中才发现设置参数真是一门学问,合理的参数设置能给算法带来很好的扩展性,也可以使用户使用起来更方便,比如这里后面的几个参数都是逻辑回归中的超参数,它有默认值,也可以允许用户自己设置。
- 前三个参数是用户必须传入的参数,分别表示样本集dataSet、样本标签labels、初始权重w;
- 其它参数均有默认值(在使用Logistic函数时会传入这些参数的默认值),分别是学习率alpha,最大迭代次数maxIter、分类界定classifyPint(当预测概率大于classifyPint我们将其划分为类1),梯度更新阈值threshold(当两次梯度更新的规模很小时,认为算法收敛了);
def GD(dataSet, labels, w, alpha, maxIter, classifyPint, threshold):
update = 1 # 存储每次权重更新的规模,初始化为1
loss = [] #存储每次损失值:负对数损失函数
ones = np.ones((len(dataSet),1))
while(maxIter>0 and update>threshold):
'''每次更新权重后计算一下当前的损失函数值'''
loss.append(np.sum(labels.T*np.log(ones+np.exp(-dataSet*w))+(ones-labels).T*np.log(ones+np.exp(dataSet*w))))
'''对每一个特征乘以一个回归系数再带入到Sigmod函数中即得到样本类别为1的概率'''
hs = 1 / (1.0 + np.exp(-dataSet*w)) #所有样本的预测概率
'''更新权重'''
delta = alpha*dataSet.T*(labels-hs) #所有样本产生的梯度
w += delta
update = abs(np.sum(delta))
maxIter -= 1
'''将概率值大于classifyPint的样本分类为1'''
pres = hs>classifyPint
'''计算分类精度'''
accuracy = np.sum(pres==labels)/float(len(dataSet))
print maxIter,w,accuracy
return w,accuracy,loss- 随机梯度下降:遍历样本每次使用一个样本来更新权重,当样本很大的时候有可能没有扫描完所有样本就收敛了,当然一般情况是多次扫描样本集的。
def SGD(dataSet, labels, w, alpha, maxIter, classifyPint, threshold):
update = 1
loss = []
ones = np.ones((len(dataSet),1))
while(maxIter>0):
flag = False
for data,label in zip(dataSet,labels):
loss.append(np.sum(labels.T*np.log(ones+np.exp(-dataSet*w))+(ones-labels).T*np.log(ones+np.exp(dataSet*w))))
h = 1 / (1.0 + np.exp(-data*w)) #单个样本的预测概率
'''使用一个样本的梯度更新权重'''
delta = alpha*data.T*(label-h) #单个样本产生的梯度
w += delta
update = abs(np.sum(delta))
if(update<threshold):
flag = True #退出双层循环的标志
break
if(flag==True):
break
maxIter -= 1
hs = 1 / (1.0 + np.exp(-dataSet*w))
pres = hs>classifyPint
accuracy = np.sum(pres==labels)/float(len(dataSet))
print maxIter,w,accuracy
return w,accuracy,loss 训练Logistic分类器
- 这里体现了一个很好的程序设计思想,我将优化器SGD和GD写成了函数,然后将其作为参数传入到Logistic方法中,这样一来我增加新的优化函数不会影响Logistic方法,只需要让用户知道solver可选的参数即可;为了比较SGD和GD的效果,我使用RandomState对象来生成随机数,使得两次的实验的随机数相同,并且实验可重复。
from numpy.random import RandomState
def Logistic(dataSet, labels, alpha=0.001, maxIter=1000, classifyPint=0.5, threshold=1e-10, solver=SGD):
attriNum = dataSet.shape[1] #属性的个数
r = RandomState(1234567890)
w = r.randn(attriNum,1) #定义权重为列向量便于后面计算矩阵乘法
return solver(dataSet, labels, w, alpha, maxIter, classifyPint, threshold)- 训练一下看看:可以发现这两个优化算法得到的解不同,因为我们采用的迭代方式不同,并且我并没有让它无限迭代下去,所以最终的解只是一个近似最优解。实际上我们应该关注损失函数的变化,因为我们这个梯度下降其实是在最小化损失函数。
w1,accuracy1,loss1 = Logistic(dataSet, labels, solver=GD)
print w1,accuracy1
'''
[[ 5.51163083]
[ 0.59169304]
[-0.79270655]] 0.97
'''
w2,accuracy2,loss2 = Logistic(dataSet, labels, solver=SGD)
print w2,accuracy2
'''
[[ 5.51581901]
[ 0.59087146]
[-0.79906018]] 0.97
'''损失值对比
- 我设置的迭代次数为1000,GD是迭代了1000次,所以len(loss1)=1000,但是SGD迭代一次需要遍历所有的样本,所用实际迭代了100000次,len(loss2)=100000,详细的损失值变化曲线如下:
import matplotlib.pyplot as plt
plt.subplot(311)
plt.plot(range(0,1000),loss1,'r--',label='GD')
plt.plot(range(0,1000),loss2[0:1000],'g--',label='SGD')
plt.axis([0, 1000, 0, 900])
plt.xlabel('Iteration')
plt.ylabel('Loss')
plt.grid()
plt.legend()
plt.subplot(312)
plt.plot(range(0,1000),loss1,'r--',label='GD')
plt.axis([0, 1000, 0, 900])
plt.xlabel('Iteration')
plt.ylabel('Loss')
plt.grid()
plt.legend()
plt.subplot(313)
plt.plot(range(0,100000),loss2,'g--',label='SGD')
plt.axis([0, 100000, 0, 900])
plt.xlabel('Iteration')
plt.ylabel('Loss')
plt.grid()
plt.legend()
plt.show()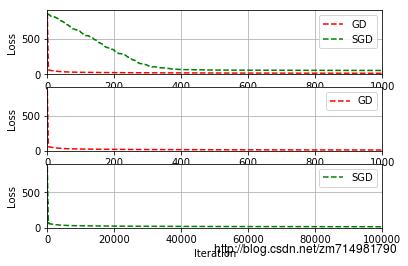
- 发现SGD在迭代400次后得到和GD相近的损失函数,此时GD扫描了数据集400次,而SGD扫描了数据集4次(扫描一次迭代100次,因为样本有100个),可以发现SGD更节省时间,所以我们通常使用的是SGD,还有一种改进的随机梯度下降算法叫小批量的随机梯度,一次使用小批量的数据集来更新权重,是SGD和GD的一个折中选择;在深度学习中训练神经网络时我通常使用32或者64的batch来训练我的模型;batch越小训练越快,但容易动荡,因为梯度容易受噪音的影响而偏离方向;batch越大训练越慢,但很稳定,但是每次都是朝着最小化目标函数的方向更新权重。
绘制分界线
- 首先生成测试样本:先看个例子,如何生成给定范围内的一系列坐标点
t1 = np.linspace(0, 2, 3) # array([ 0., 1., 2.])
t2 = np.linspace(4, 5, 2) # array([ 4., 5.])
x1,x2=np.meshgrid(t1, t2)
'''
x1:
array([[ 0., 1., 2.],
[ 0., 1., 2.]])
x2:
array([[ 4., 4., 4.],
[ 5., 5., 5.]])
'''
x_test = np.stack((x1.flat, x2.flat), axis=1)
'''
array([[ 0., 4.],
[ 1., 4.],
[ 2., 4.],
[ 0., 5.],
[ 1., 5.],
[ 2., 5.]])
'''- 绘制分类线,不是分类平面,实际有两个属性x1和x2,第一个是我们增加的常数项:首先写出分类器函数,然后创建测试样本,得到它们的预测值,绘制到图上,再将真实的样本及其类别显示出来;
def classify(testX, w):
testX = np.column_stack((np.ones((len(testX),1)),testX))
hs = 1 / (1.0 + np.exp(-testX*w))
pres = hs>0.5
return pres
'''绘制逻辑函数的分界线'''
X_min = np.min(dataSet,axis=0)
X_max = np.max(dataSet,axis=0)
x1_min,x2_min = X_min[0,1],X_min[0,2]
x1_max,x2_max = X_max[0,1],X_max[0,2]
N, M = 500, 500 # 横纵各采样500个值
t1 = np.linspace(x1_min, x1_max, N)
t2 = np.linspace(x2_min, x2_max, M)
x1, x2 = np.meshgrid(t1, t2) # 生成网格采样点
x_test = np.mat(np.stack((x1.flat, x2.flat), axis=1)) # 生成测试点
y_test = classify(x_test,w1)
y_test = np.array(y_test.reshape(x1.shape)).astype(int) # 使之与输入的形状相同
# x1,x2,y_test相当于三维图里的x,y,z
plt.pcolormesh(x1, x2, y_test, cmap=plt.cm.Spectral, alpha=0.1)
'''将我们的训练集也画到图上'''
plt.scatter(np.array(dataSet[:,1]), np.array(dataSet[:,2]), c=np.array(labels), edgecolors='k', cmap=plt.cm.prism) # 样本的显示
plt.grid()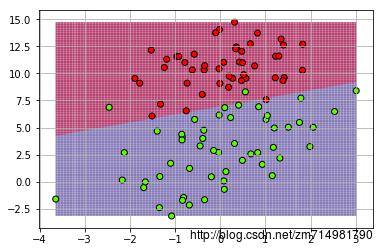
- 从上图可以很清晰的看到错分的三个点,额,代码写得有些乱,但大体想表达的都表达出来了。
总结
- 对于梯度下降其实还有很多技巧,比如迭代的过程中修改alpha的值以及随机梯度下降过程中不是顺序遍历样本集而是每次随机的选择一个样本来更新权重,不管怎样,对逻辑回归总算有个很深入的了解,毕竟我亲手code了它O(∩_∩)O
- 优点:计算代价不高,易于理解和实现
- 缺点:容易欠拟合,分类精度不高
- 适用数据类型:数值型和标称类型
- 补充一点,我在使用我写的算法测试其它数据时,发现精度很低,于是一点点调试,发现原来在计算
np.exp(-dataSet*w)时出现了inf也就是数据溢出了,这是我之前远远没有考虑的事情,所以我将数据集进行了归一化,就没有出现这个问题了。归一化后有两个好处:
- 提升模型的收敛速度;
- 归一化的另一好处是提高精度,这在涉及到一些距离计算的算法时效果显著,比如算法要计算欧氏距离,比如x2的取值范围比较小,涉及到距离计算时其对结果的影响远比x1带来的小,所以这就会造成精度的损失。所以归一化很有必要,他可以让各个特征对结果做出的贡献相同。
以上是关于Logistic回归的主要内容,如果未能解决你的问题,请参考以下文章